深度学习500问——Chapter09:图像分割(3)
文章目录
9.8 PSPNet
9.9 DeepLab系列
9.9.1 DeepLabv1
9.9.2 DeepLabv2
9.9.3 DeeoLabv3
9.9.4 DeepLabv3+
9.8 PSPNet
场景解析对于无限制的开放词汇和不同场景来说是具有挑战性的。本文使用文中的 pyramid pooling module 实现基于不同区域的上下文集成,提出了PSPNet,实现利用上下文信息的能力来进行场景解析。
作者认为,FCN存在的主要问题是没有采取合适的策略来用全局的信息,本文的做法就是借鉴SPPNet来设计了PSPNet解决这个问题。
很多 State-of-the-art 的场景解析框架都是基于FCN的,基于CNN的方法能够增强动态物体的理解,但是在无限制词汇和不同场景中仍然面临挑战。举个例子,如下图:
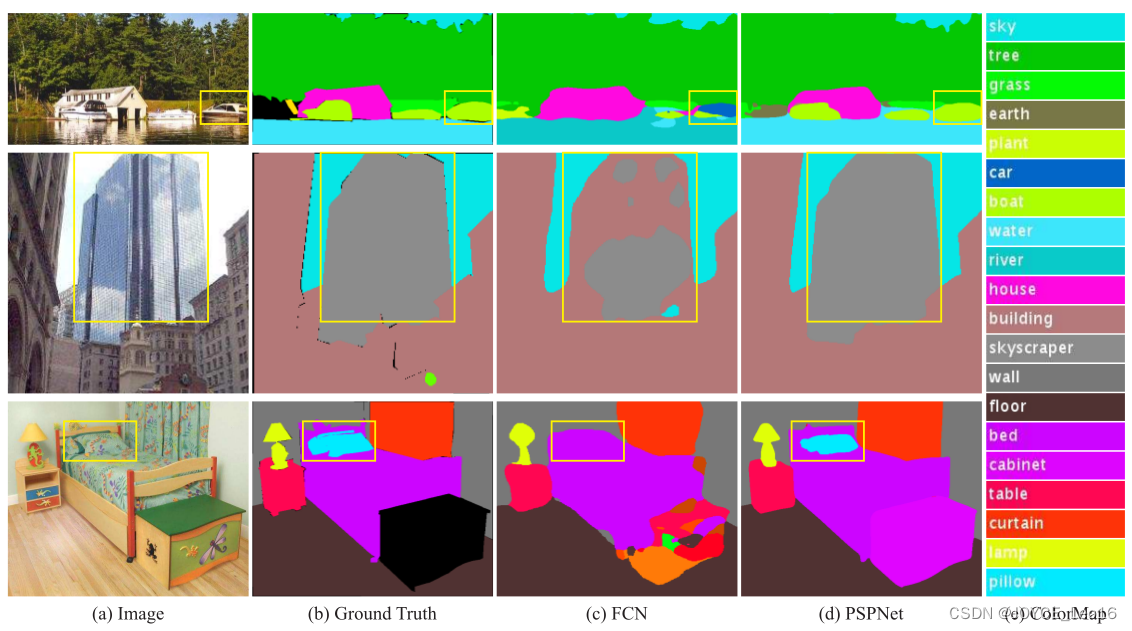
FCN认为右侧框中是汽车,但是实际上是船,如果参考上下文的先验知识,就会发现左边是一个船屋,进而推断框中是船。FCN存在的主要问题就是不能利用好全局的场景线索。
对于尤其复杂的场景理解,之前都是采用空间金字塔池化来做的,和之前方法不同(为什么不同,需要参考一下经典的金字塔算法),本文提出了 pyramid scene parsing network(PSPNet)。
本文的主要贡献如下:
(1)提出了PSPNet在基于FCN的框架中集成困难的上下文特征。
(2)通过基于深度监督误差开发了针对ResNet的高效优化策略。
(3)构建了一个用于state-of-the-art的场景解析和语义分割的实践系统(具体是什么?)
通过观察FCN的结果,发现了如下问题:
(1)关系不匹配(Mismatched Relationship)
(2)易混淆的类别(Confusion Categories)
(3)不显眼的类别(Inconspicuous Classes)
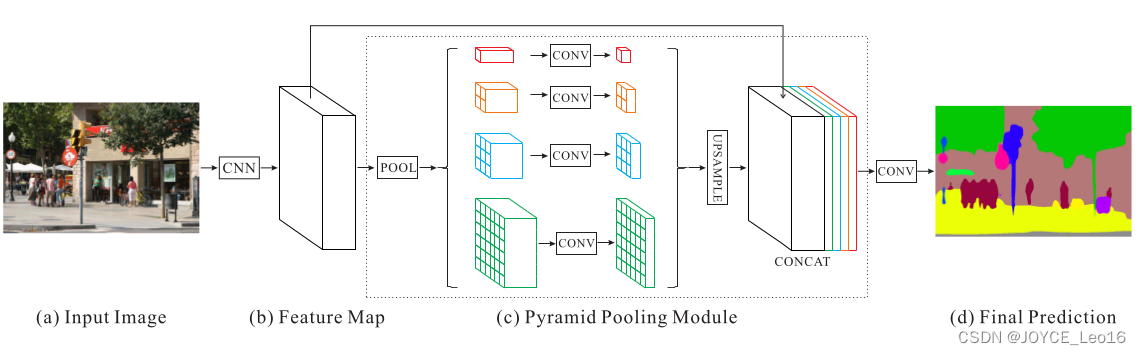
总结以上结果发现,以上问题部分或者全部上下文关系和全局信息有关系,因此本文提出了PSPNet,框架如下:
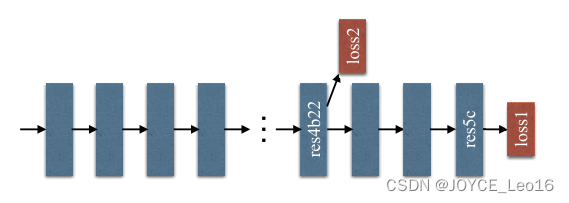
并且就加入额外的深度监督 Loss
9.9 DeepLab系列
9.9.1 DeepLabv1
DeepLab 是结合了深度卷积神经网络(DCNNs)和概率模型图(DenseCRFs)的方法。
在实验中发现了DCNNs做语义分割时精准度不够的问题,根本原因是DCNNs的高级特征的平移不变性,即高层次特征映射,根源于重复的池化和下采样。
针对信号下采样或池化降低分辨率,DeepLab是采用的 atrous(带孔)算法扩展感受野,获取更多的上下文信息。
分类器获取以对象中心的决策是需要空间变换的不变性,这天然地限制了DCNN的定位精度,DeepLab采用完全连接的条件随机场(CRF)提高模型捕获细节的能力。
除空洞卷积和CRFs之外,论文使用的tricks还有 Multi-Scale features。其实就是U-Net 和FPN的思想,在输入图像和前四个最大池化层的输出上附加了两层的MLP,第一层是 128 个 3x3的卷积,第二层是 128个 1x1 卷积。最终输出的特征与主干网络的最后一层特征图融合,特征图增加 5x128=640个通道。
实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
论文模型基于 VGG16,在 Titan GPU上运行速度达到了 8FPS,全连接CRF平均推断需要 0.5s,在PASCAL VOC-2012达到71.6% IOU accuracy。
9.9.2 DeepLabv2
DeepLabv2 是相对于DeepLabv1基础上的优化。DeepLabv1在三个方向努力解决,但是问题依然存在:特征分辨率的降低、物体存在多尺度,DCNN的平移不变性。
因DCNN连续池化和下采样造成分辨率降低,DeepLabv2在最后几个最大池化层中去除下采样,取而代之的是使用空洞卷积,以更高的采样密度计算特征映射。
物体存在多尺度的问题,DeepLabv1中是用多个MLP结合多尺度特征解决,虽然可以提供系统的性能,但是增加特征计算量和存储空间。
论文受到Spatial Pyramid Pooling(SPP)的启发,提出了一个类似的结构,在给定的输入上以不同采样率的空洞卷积进行采样,相当于以多个比例捕捉图像的上下文,称为ASPP(atrous spatial pyramid pooling)模块。
DCNN的分类不变性影响空间精度。DeepLabv2是采用全连接的CRF在增强模型捕捉细节的能力。
论文模型基于ResNet,在Nvidia Titan X GPU上运行速度达到了 8FPS,全连接 CRF平均推断需要 0.5s,在耗时方面和DeepLabv1无差异,但在PASCAL VOC-2012达到 79.7 nIOU。
9.9.3 DeeoLabv3
好的论文不止说明怎么做,还告诉为什么。DeepLab 延续到 DeepLabv3系列,依然是在空洞卷积做文章,但是探讨不同结构的方向。
DeepLabv3 论文比较了多种捕获多尺度信息的方式:
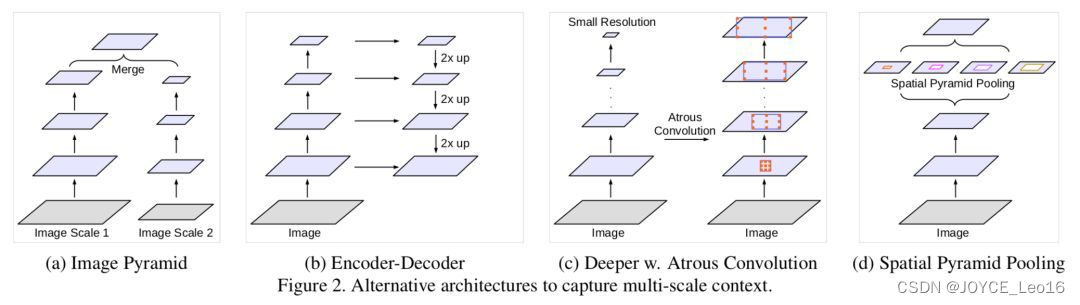
- Image Pyramid:将输入图片放缩成不同比例,分别应用在DCNN上,将预测结果融合得到最终输出。
- Encoder-Decoder:利用Decoder 阶段的多尺度特征,运用到Decoder阶段上恢复空间分辨率,代表工作有 FCN、SegNet、PSPNet等工作。
- Deeper w.Atrous Convolution:在原始模型的顶端增加额外的模块,例如DenseCRF,捕捉像素间长距离信息。
- Spatial Pyramid Pooling:空间金字塔池化具有不同采样率和多种视野的卷积核,能够以多尺度捕捉对象。
DeepLab1-v2都是使用带孔卷积提取密集特征来进行语义分割。但是为了解决分割对象的多尺度问题,DeepLabv3设计采用多比例的带孔卷积级联或并行来捕获多尺度背景。
此外,DeepLabv3将修改之前提出的带孔空间金字塔池化模块,该模块用于探索多尺度卷积特征,将全局背景基于图像层次进行编码获得特征,取得 state-of-art 性能,在PASCAL VOC-2012 达到 86.9 mIOU。
9.9.4 DeepLabv3+
语义分割关注的问题:
- 实例对象多尺度的问题。
- 因为深度网络存在 stride=2的层,会导致 feature 分辨率下降,从而导致预测精度降低,而造成的边界信息丢失问题。
deeplab v3新设计的 aspp结果解决了问题1,deeplab v3+ 主要目的在于解决问题2。
问题2可以使用空洞卷积替代更多的pooling层来获取分辨率更高的feature。但是feature分辨率更高会极大增加运算量。以deeplab v3使用的 resnet101为例,stride=16将造成后面9层feature变大,后面9层的计算量变为原来的 2*2=4倍大。stride=8则更恐怖,后面78层的计算量都会变大很多。
解决方案:1、编解码器结构;2、Modified Aligned Xception。
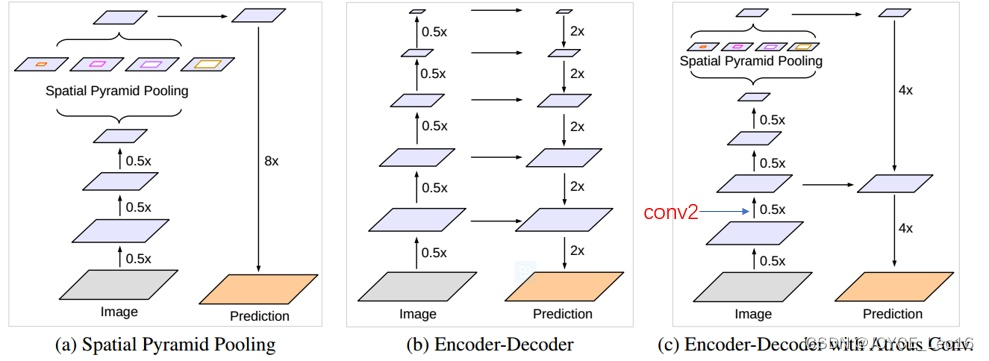
在deeplabv3的基础上加入解码器。A是 aspp 结构,其中 8x的上采样可以看作是一个解码器。B是编解码结构,它集合了高层和底层的特征。C就是本文采取的方法。
方法:
(1)Encoder-Decoder with Atrous Convolution
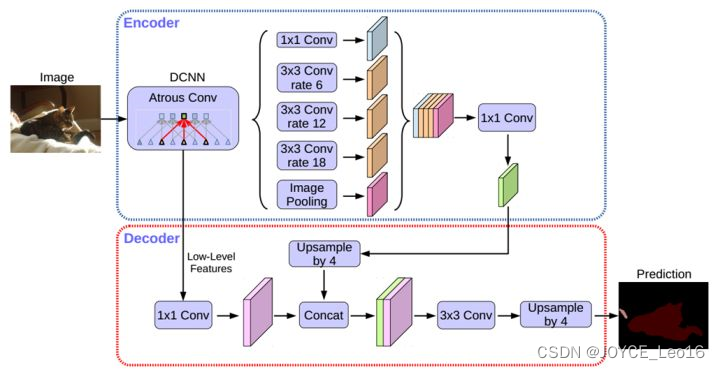
编码器采用 deeplabv3。
解码器部分:先从低层级选一个feature,将低层级的feature 用 1*1的卷积进行通道压缩(原本为256通道,或者512通道),目的在于减少底层级的比重。作者认为编码器得到的feature具有更丰富的信息,所以编码器的feature应该有更高的比重。这样做有利于训练。
再将编码器的输出上采样,使其分辨率与低层级feature一致。举个例子,如果采用 resnet conv2输出的feature,则这里要 *4上采样。将两种feature连接后,再进行一次 3*3 的卷积(细化作用),然后再次上采样就得到了像素级的预测。后面的实验结果表明这种结构载stride=16时既有很高的精度速度又很快。stride=8相对于来说只获得了一点点精度的提升,但增加了很多的计算量。
(2)Modified Aligned Xception
Xception 主要采用了deepwish seperable convolution 来替换原来的卷积层。简单的说就是这种结构能在更少参数更少计算量的情况下学到同样的信息。这边则是考虑将原来的 resnet-101骨架网换成 Xception。
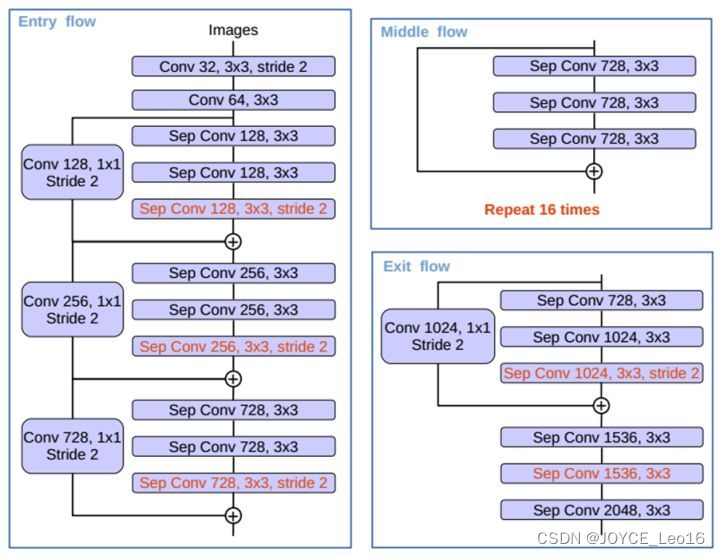
红色部分为修改:
更多层:重复8次改为16次(基于MSRA目标检测的工作)。
将原来简单的pool层改成了 stride为2 的deepwish seperable convolution。
额外的RELU层和归一化操作添加在每个 3 × 3 depthwise convolution之后(原来只在1 * 1卷积之后)。