机器学习(五) -- 监督学习(4) -- 集成学习方法-随机森林
系列文章目录及链接
上篇:机器学习(五) -- 监督学习(3) -- 决策树
下篇:机器学习(五) -- 监督学习(5) -- 线性回归1
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
一、集成学习简介
集成学习(Ensemble Method)不是一种学习器,是一种学习器结合方法。
1、什么是集成学习
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个学习器 ,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
其中每个单独的学习器,称为基学习器。(学习器=预估器=模型,在分类中也叫分类器)
2、机器学习的两大核心任务

欠拟合=高偏差
过拟合=高方差
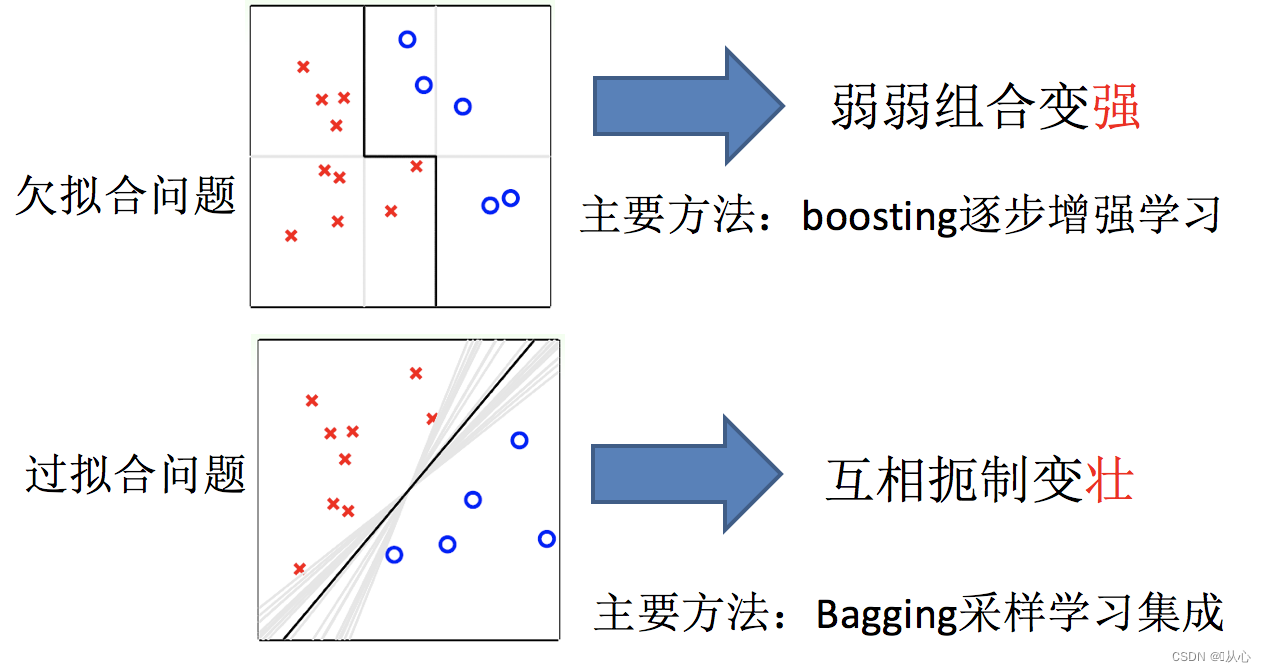
3、集成学习3种方法
将所有的基学习器是否是一个种类的分为同质和异质,异质的集成学习方法有Stacking。同质的按照基学习器是否存在依赖关系分为Bagging和Boosting。
Boosting:基学习器之间存在强依赖关系,一系列基学习器基本都需要串行生成
Bagging:基学习器之间不存在强依赖关系,一系列基学习器可以并行生成
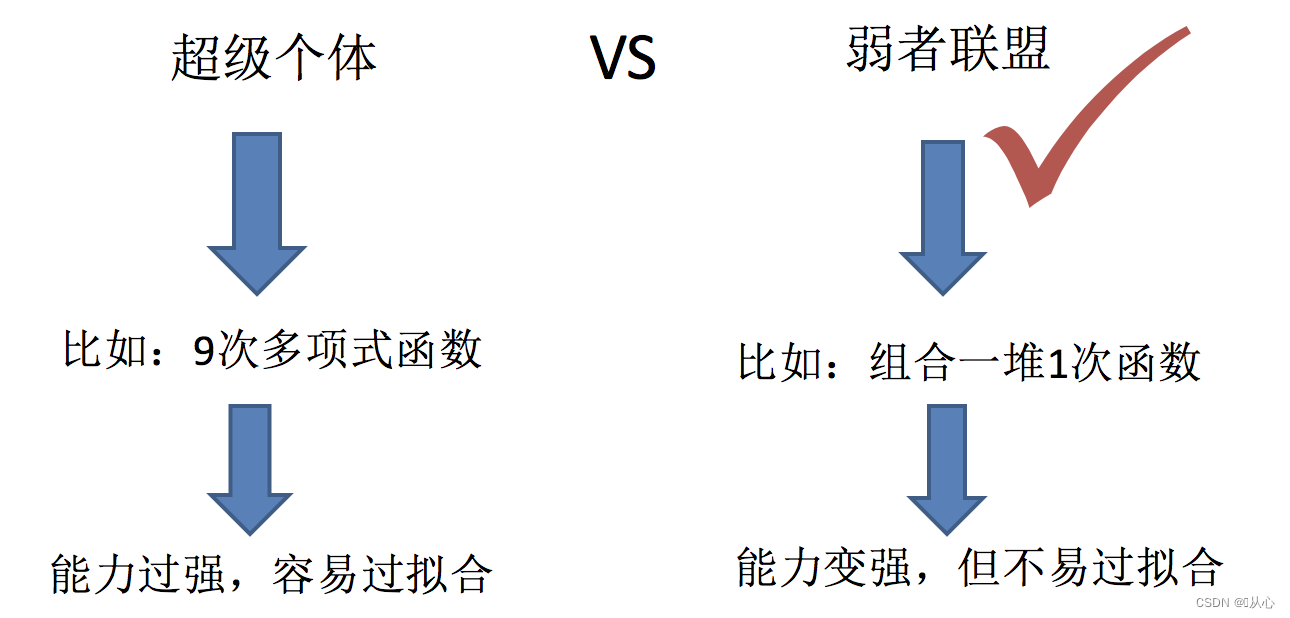
3.1、Bagging(同质基学习器并行)--降低方差
bootstrap aggregation,装袋法,代表算法:随机森林(Random Forest)
各基学习器之间无强依赖,可以进行并行训练。
为了让基分类器之间互相独立,将训练集分为若干子集(有放回抽样;当训练样本数量较少时,子集之间可能有交叠)。Bagging 方法更像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最后的集体决策。
Bagging 方 法则是采取分而治之的策略,通过对训练样本多次采样,并分别训练出多个不同模型,然后做综合,来减小集成分类器的方差。
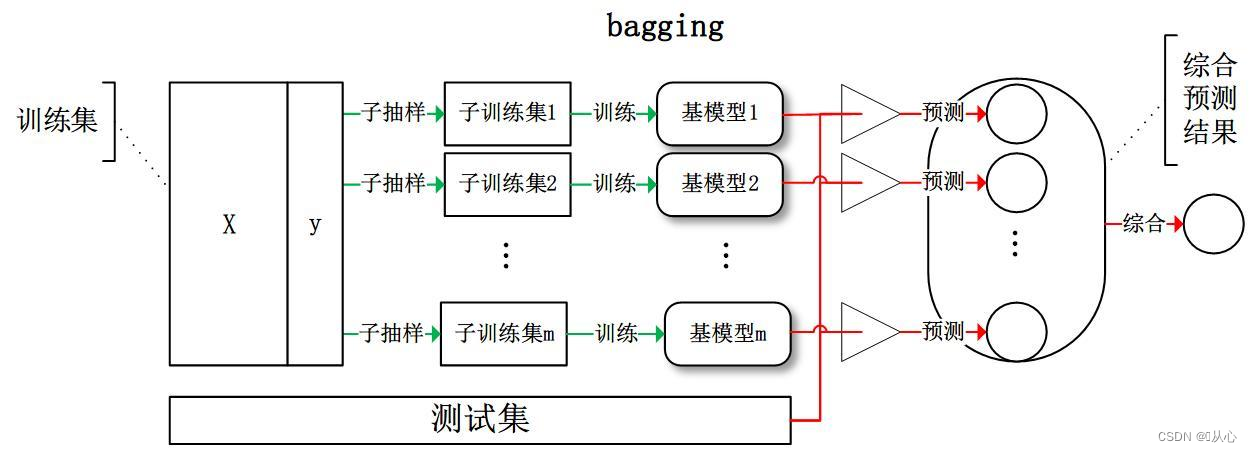
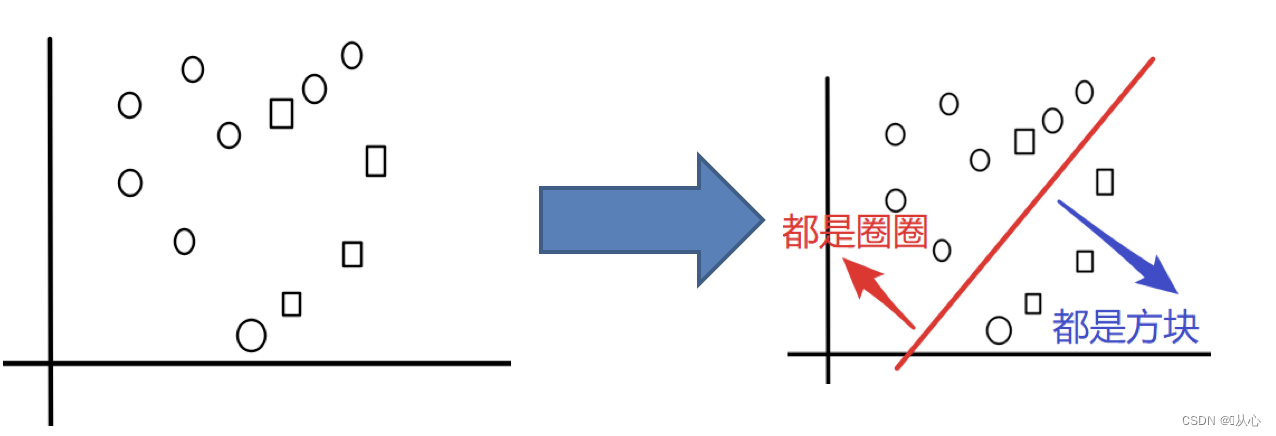
简单示例理解:
目标:把下面的圈和方块进行分类
实现过程:
1.采样不同数据集
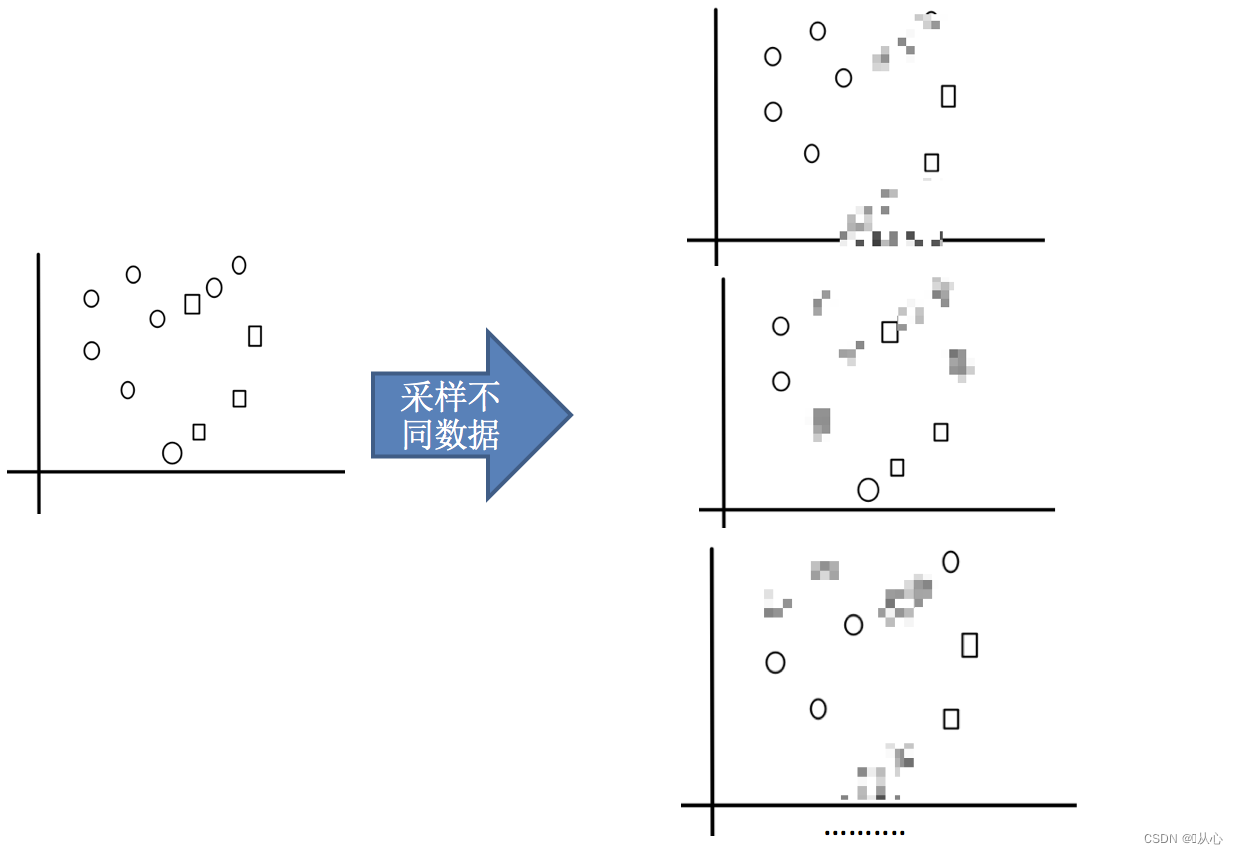
2.训练学习器
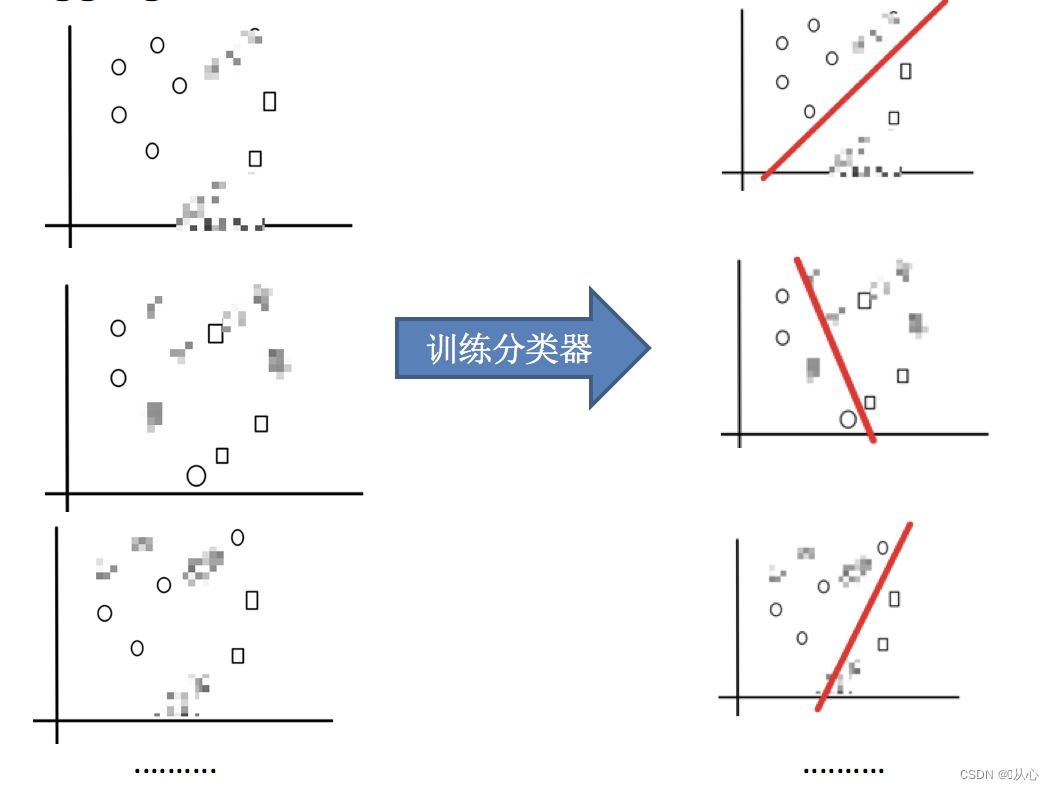
3.平权投票,获取最终结果
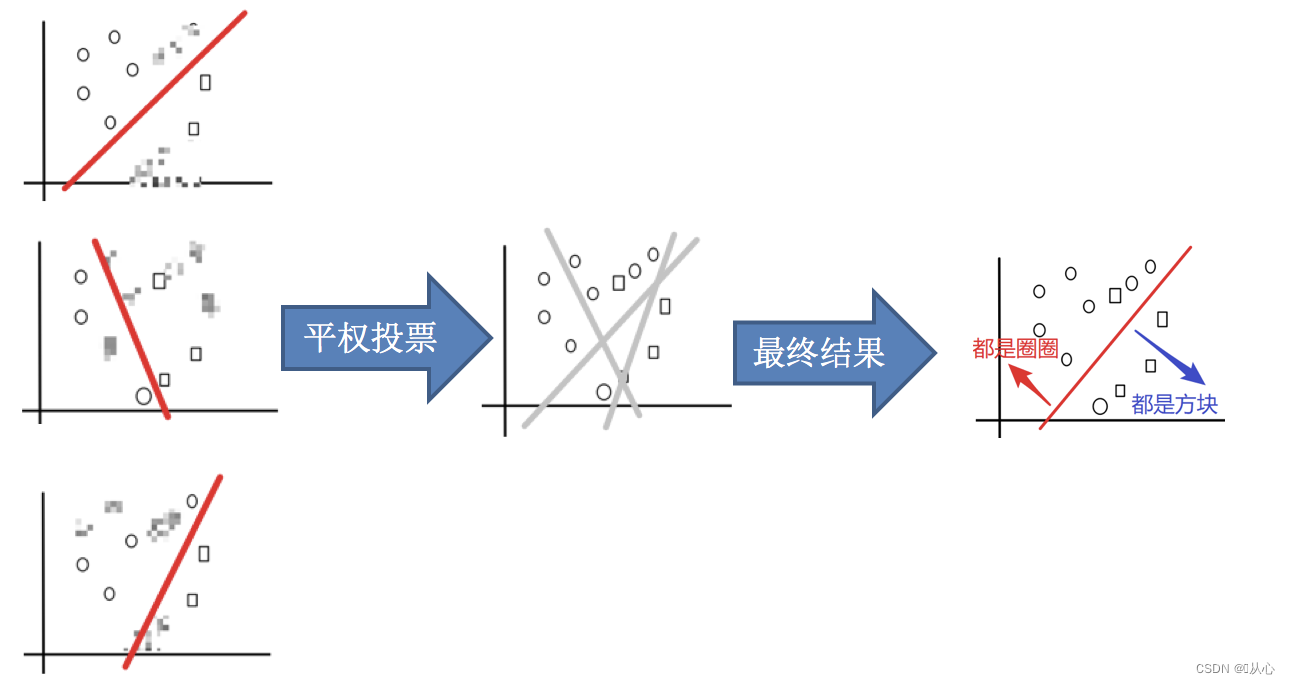
小结
3.2、Boosting(同质基学习器串行)--降低偏差
迭代法(提升法),代表算法:AdaBoost,GBDT, XGBoost
训练基学习器时时采用串行的方式,各个基分类器之间有依赖。(迭代式学习)
将基学习器层层叠加,每一层在训练的时候,对前一层基学习器分错的样本, 给予更高的权重。测试时,根据各层学习器的结果的加权得到最终结果。
Boosting 方法是通过逐步聚焦于基分类器分错的样本,减小集成分类器的偏差。
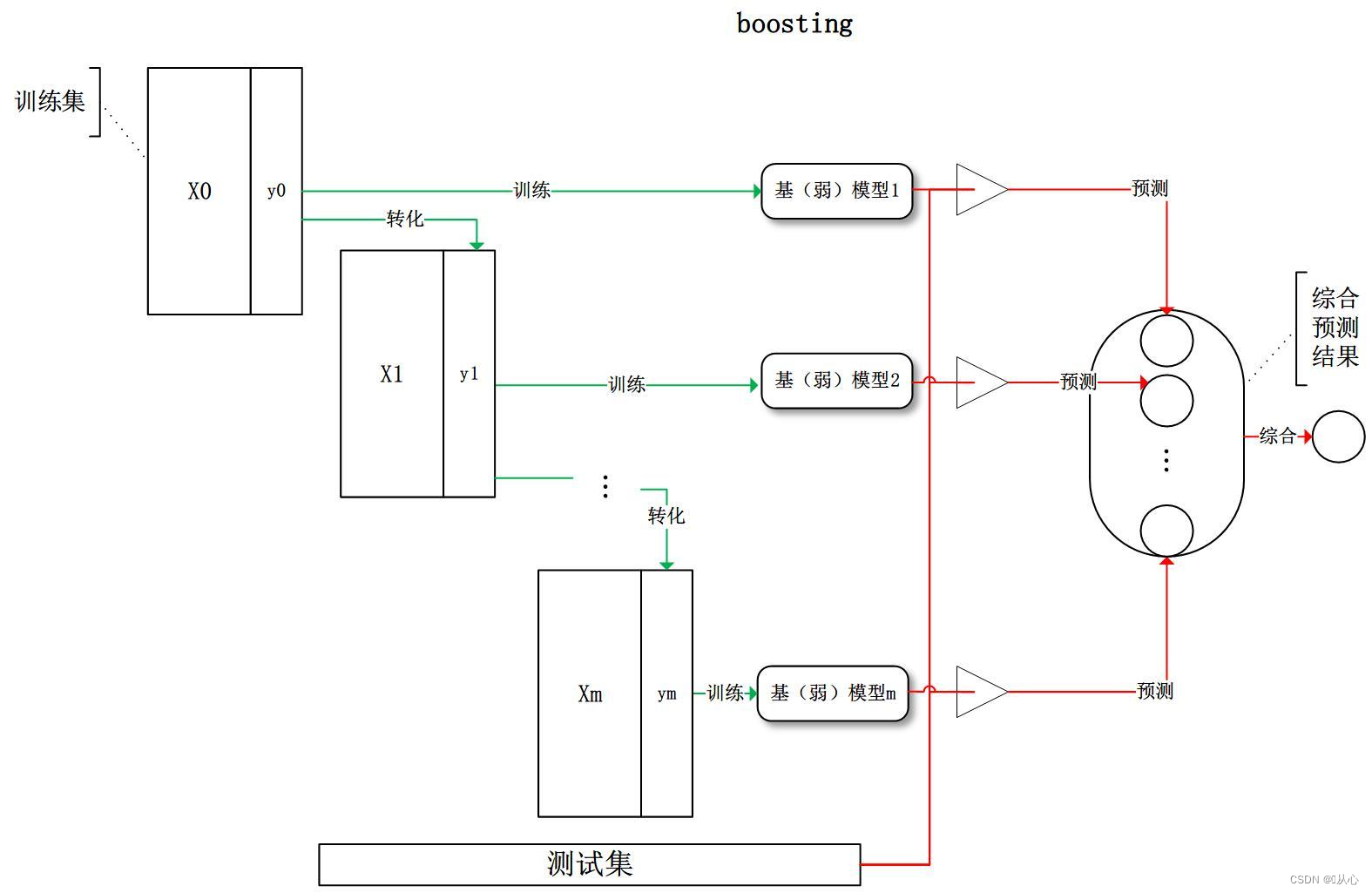
简单示例理解:
过程:
1.训练第一个学习器
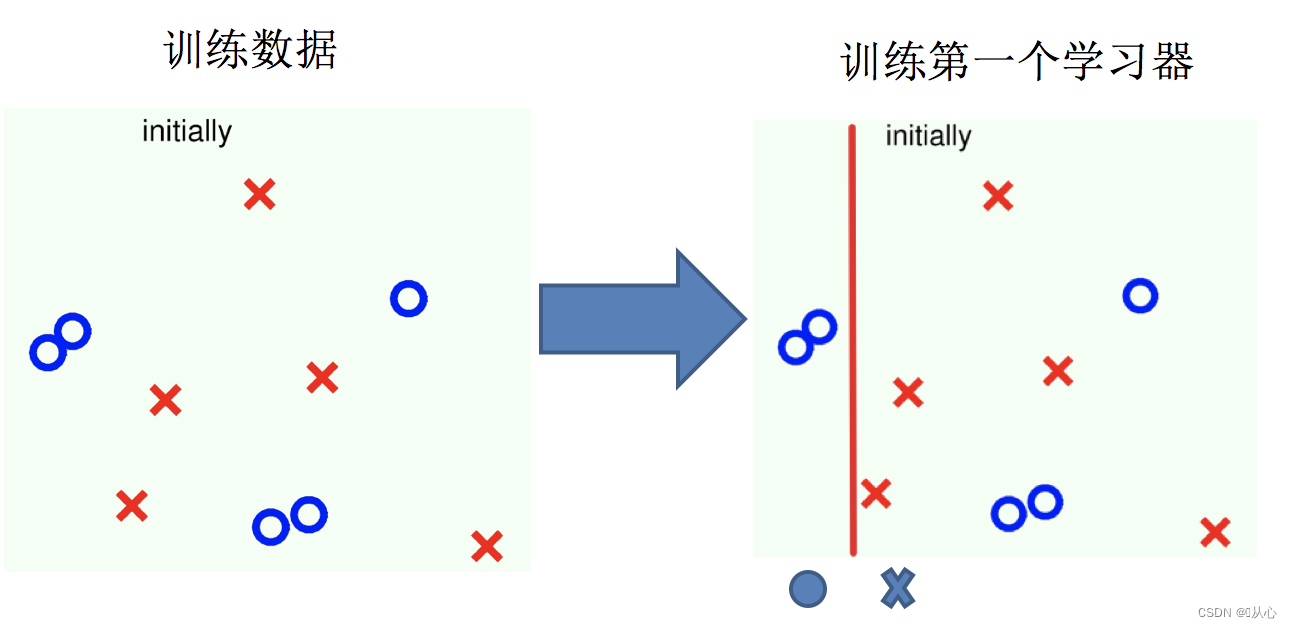
2.调整数据分布
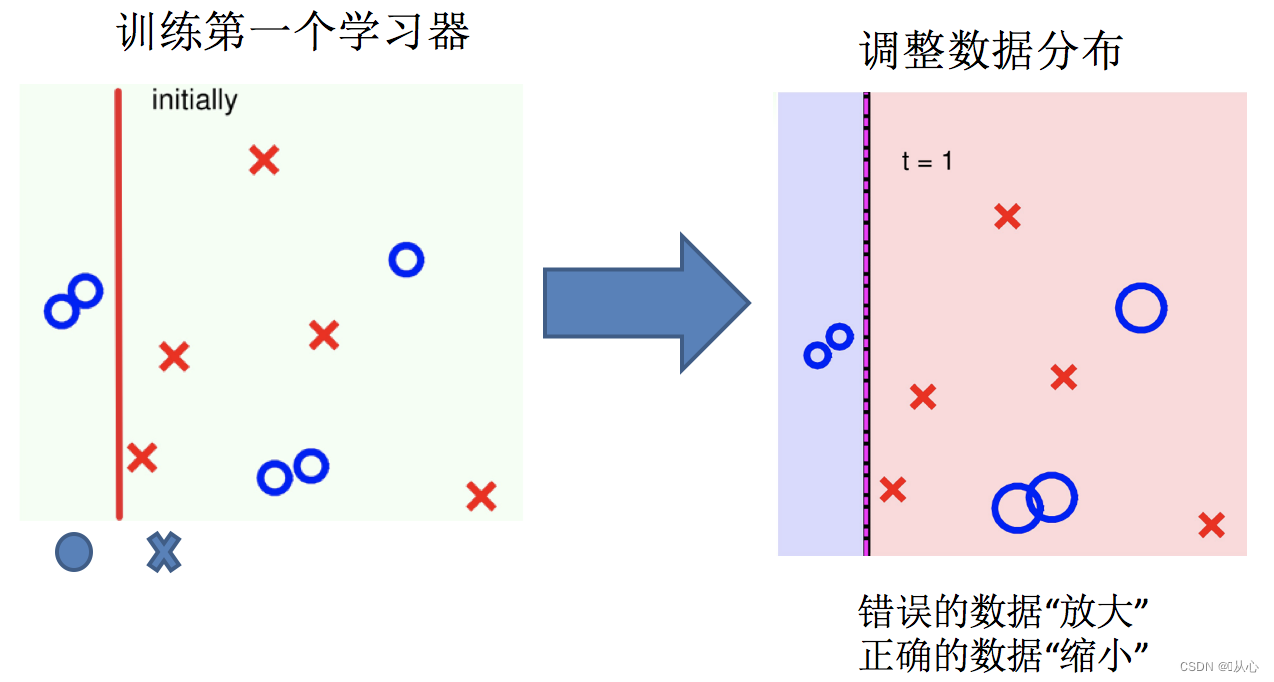
3.训练第二个学习器
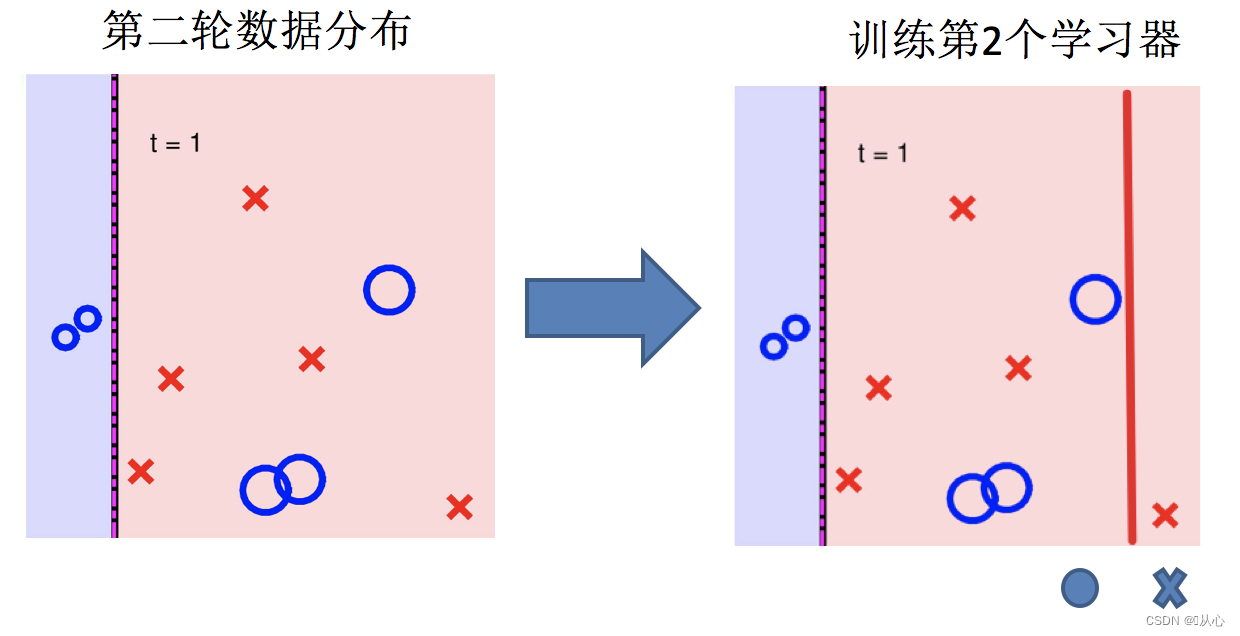
4.再次调整数据分布
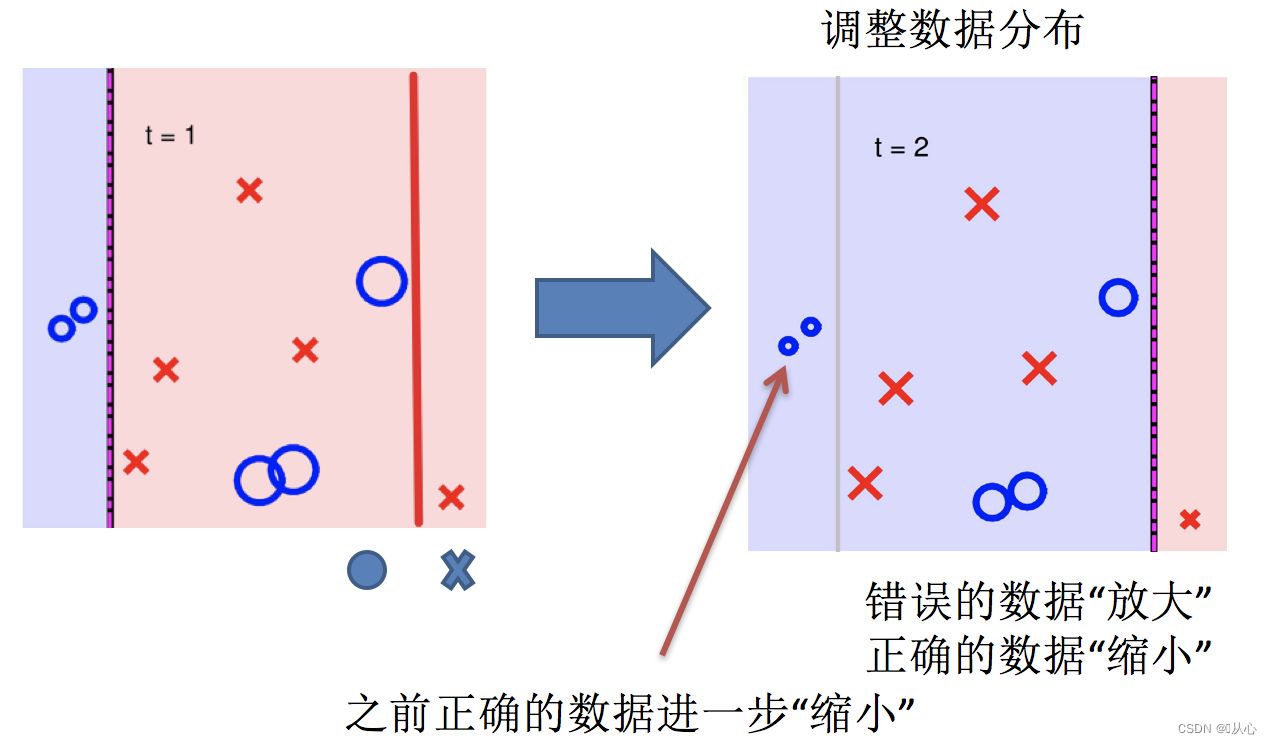
5.依次训练学习器,调整数据分布
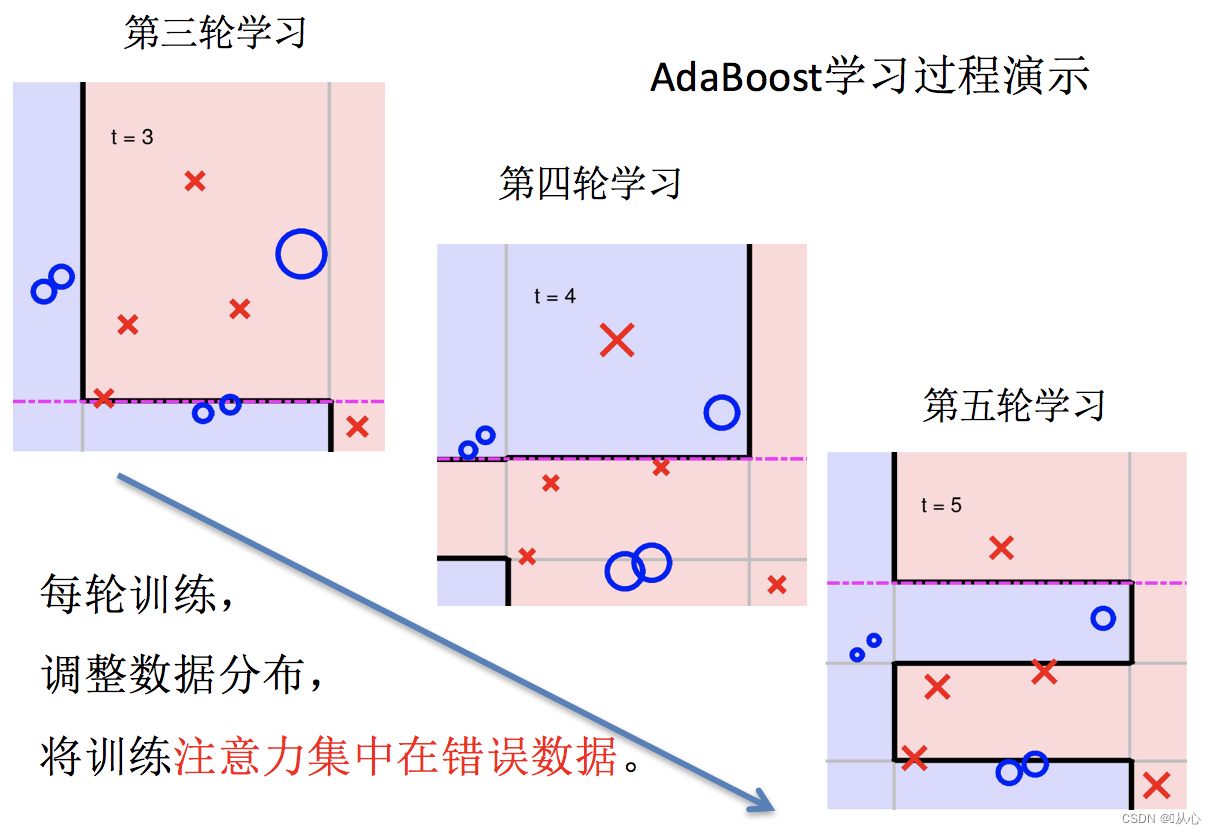
小结
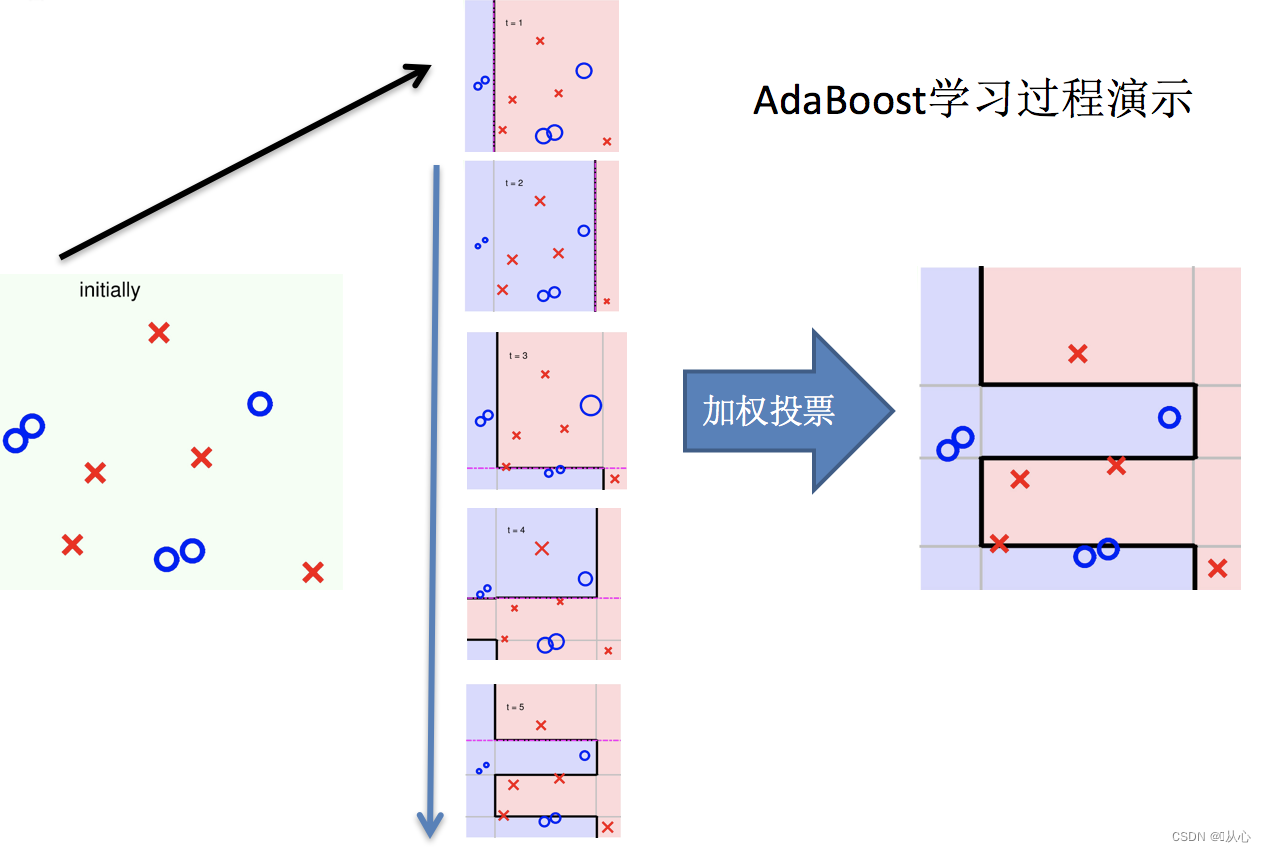
关键点
如何确认投票权重?
如何调整数据分布?
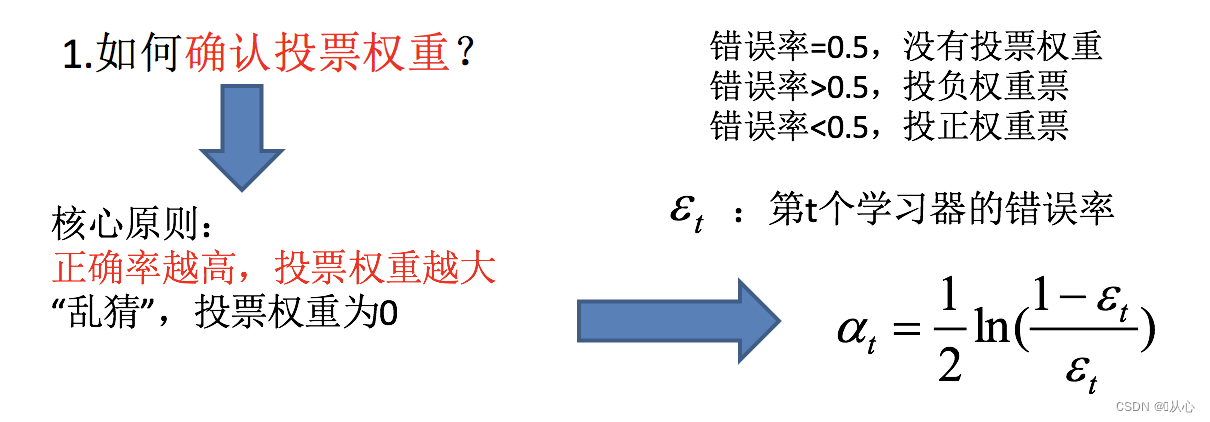

AdaBoost的构造小结

bagging集成与boosting集成的区别:
1、数据方面
Bagging:对数据进行采样训练;
Boosting:根据前一轮学习结果调整数据的重要性。
2、投票方面
Bagging:所有学习器平权投票;
Boosting:对学习器进行加权投票。
3、学习顺序
Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序。
4、主要作用
Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
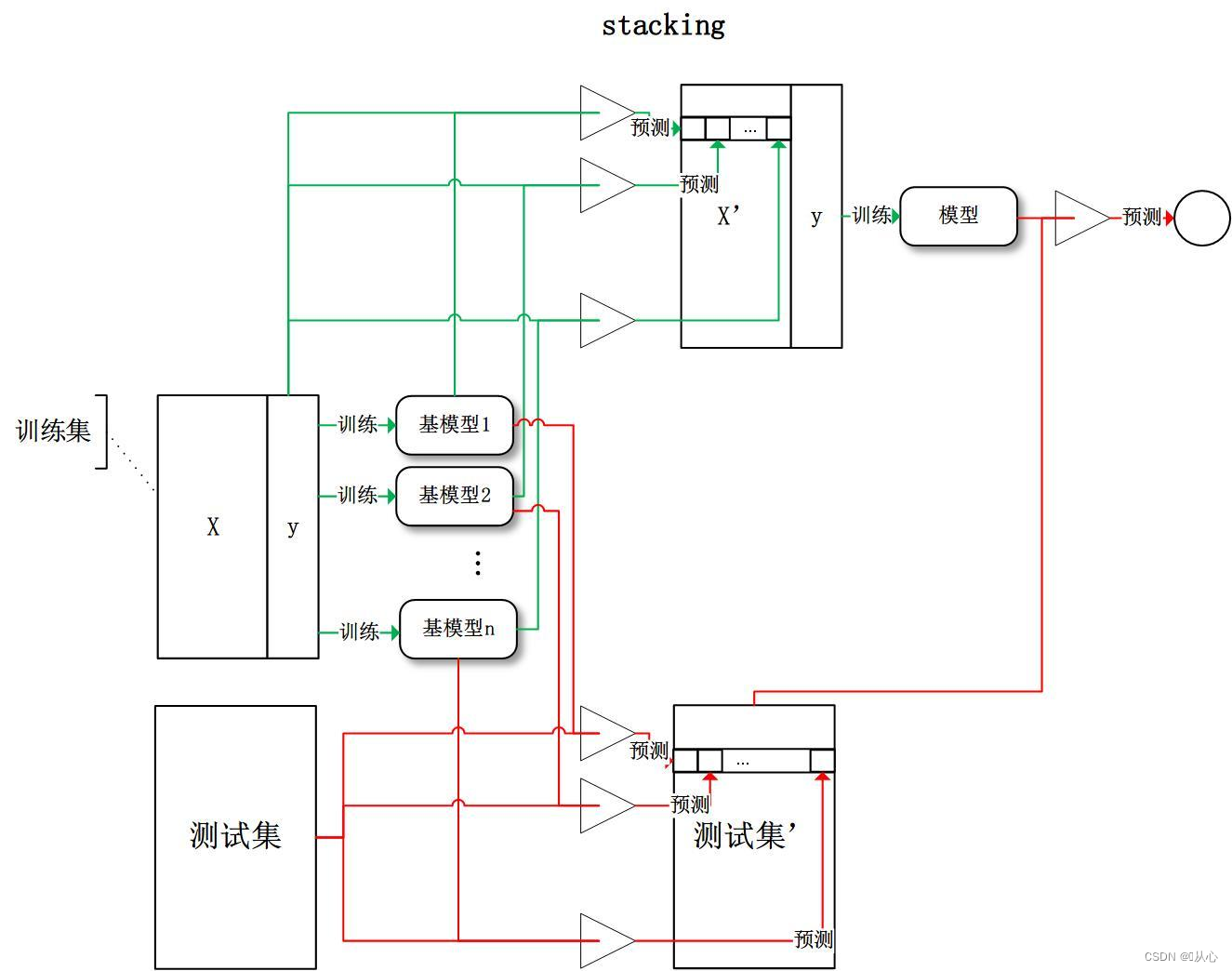
3.3、Stacking(≈异质基学习器叠加)--改进预测
堆叠法(叠加泛化)
简单来讲,不同的学习算法被组合在一起。
3.4、总结
1、Bagging的核心思路是民主投票,每个基础模型都只有一票,投票最多的结果作为最终的结果。
2、Boosting的核心思路是挑选精英,对基础模型进行考验和筛选,给与精英模型更多的投票权,表现不好的模型给较少的投票权,然后综合所有人的投票得到最终结果。
3、Stacking由元估计器和基础估计器两部分构成,元估计器把基础估计器的预测结果作为输入变量,最终对被解释变量做出预测。基础估计器可以由不同的算法模型(如:逻辑回归和KNN)进行组合,元估计器也可以选择完全不同的算法模型(如:决策树),以实现最终减小误差的更好效果。

只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的。
二、通俗理解及定义
What(做什么),Why(为什么做),How(怎么做)
1、什么叫随机森林(What)
随机森林=Bagging+决策树
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由多个树输出的类别的众数而定。
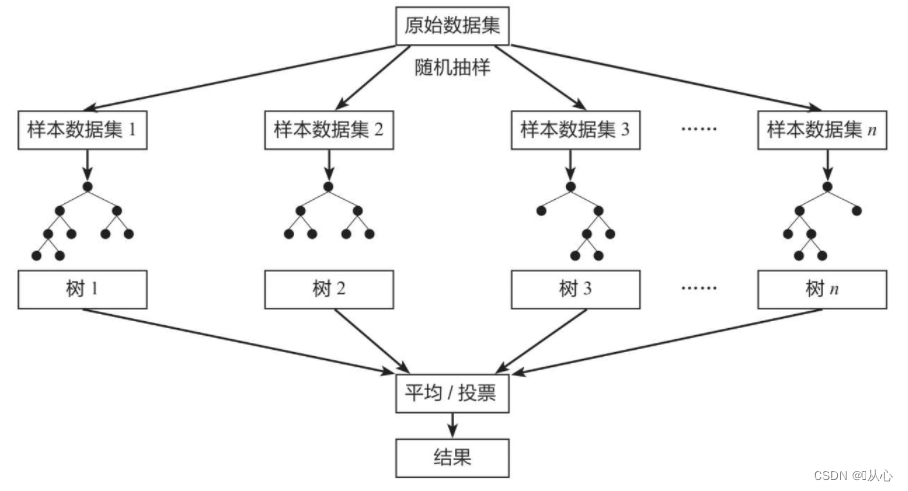
训练集随机
特征随机
2、随机森林的目的(Why)
通过考虑多个学习器建模结果,汇总得到一个综合结果,使单棵树的效果最大化。
(建立11棵树中的6棵树(以上)判错,随机森林才会判断错误。
决策树准确率至少百分之五十,否则随机森林的效果不会好于决策树)
3、怎么做(How)
1、随机选择m条数据
2、随机选取k个数据特征
3、训练决策树
4、重复1-3步,构造n个弱决策树
5、平权投票集成n个弱决策树
例如, 如果你训练了11个树, 其中有6个树的结果是True, 5个树的结果是False, 那么最终投票结果就是True。
三、原理理解及公式
1.为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
2.为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
3、优缺点
3.1、优点:
bagging集成优点:
1.均可在原有算法上提高约2%左右的泛化正确率
2.简单, 方便, 通用
3.适用于有效地运行在大数据集上
4.处理具有高维特征的输入样本,而且不需要降维
3.2、缺点:
四、**算法实现
五、接口实现
1、API
sklearn.ensemble.RandomForestClassifier# 导入
from sklearn.ensemble import RandomForestClassifier# 语法
RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200Criterion:string,可选(default =“gini”)分割特征的测量方法max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30max_features="auto”,每个决策树的最大特征数量If "auto", then max_features=sqrt(n_features).If "sqrt", then max_features=sqrt(n_features)(same as "auto").If "log2", then max_features=log2(n_features).If None, then max_features=n_features.bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样min_samples_split:节点划分最少样本数min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
2、流程
2.1、获取数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier# 获取数据
iris = load_iris() 2.2、数据预处理
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=1473) 2.3、特征工程
2.4、随机森林模型训练
# 实例化学习器
rf = RandomForestClassifier()# 模型训练
rf.fit(x_train, y_train)
2.5、模型评估
# 用模型计算测试值,得到预测值
y_pred=rf.predict(x_test)# 求出预测结果的准确率和混淆矩阵
from sklearn.metrics import accuracy_score, confusion_matrix
print("预测结果准确率为:", accuracy_score(y_test, y_pred))
print("预测结果混淆矩阵为:\n", confusion_matrix(y_test, y_pred))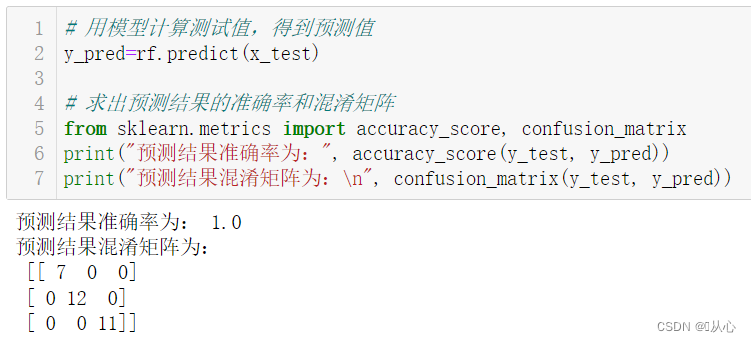
2.6、结果预测
经过模型评估后通过的模型可以代入真实值进行预测。
六、其他boosting算法了解
真的只是了解哦
1、AdaBoost
AdaBoost就是上面单独Boosting算法演示了
2、GBDT
GBDT = 梯度下降 + Boosting + 决策树
梯度提升决策树(GBDT Gradient Boosting Decision Tree) 是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就被认为是泛化能力(generalization)较强的算法。
2.1、主要思想
1.使用梯度下降法优化代价函数;
2.使用一层决策树作为弱学习器,负梯度作为目标值;
3.利用boosting思想进行集成。
3、XGBoost
XGBoost= 二阶泰勒展开+boosting+决策树+正则化
旧梦可以重温,且看:机器学习(五) -- 监督学习(3) -- 决策树
欲知后事如何,且看:机器学习(五) -- 监督学习(5) -- 线性回归1