在 Kubesphere 中开启新一代云原生数仓 Databend
上周六,由 KubeSphere 社区联合 Databend 社区以及纵目科技共同组织的云原生 Meetup 北京站在北京圆满落幕。本次 Meetup 活动邀请到了 SkyWalking PMC 成员、青云科技架构及可观测性团队负责人、江苏纵目科技 APM 研发总监、青云科技容器产品经理、数元灵科技 CTO 以及 Databend 云平台负责人等专家和大咖,为小伙伴们带来精彩的技术分享。

Databend Labs 云平台负责人李亚舟
在活动中,Databend 云平台负责人李亚舟老师为大家带来的分享是《使用 Kubesphere 部署 Databend,极速启动新一代云原生数据分析平台》,介绍了如何使用 KubeSphere 创建和部署 Databend 高可用集群,并使用 QingStor 作为底层存储服务,解锁 Databend 的强大分析能力。以下是演讲实录:
【Meetup 分享】使用 KubeSphere 部署 Databend,极速启动新一代云原生数据分析平台_哔哩哔哩_bilibili
Databend 是一个用 Rust 研发,采用存算分离架构,基于对象存储构建的云原生数仓。它可以提供极致的性能、快速的弹性扩展能力,用户可以私有化部署也可以直接使用云上的 SaaS 服务,致力于打造开源版的 Snowflake 产品。随着数据量逐渐增长,大数据的痛点是长期存在的,即海量数据的存储成本和管理复杂性高等。面对这种情况,对象存储可以说是存储成本的终极方案。现在新的存储软件基本都是基于对象存储原生设计的,但是对象存储并不是说用上就自然解决一切问题。对象存储也有一些自己的局限性,比如说它的 latency 比较难预期,单个文件的吞吐有限,这就要求在 IO 的调度上要做的特别精细,这也是 Databend 云原生数仓引擎所擅长的。
Databend 云原生数仓可以让你轻松地分析对象存储上的 PB 级海量数据。PB 级的数据如果都放在对象存储上,成本一定会大幅下降的,相比放在 SSD 或者 HDD,可能会降到原先 5% 或者 10% 的水平。同时,Databend 还会对你的数据做大规模的压缩,这样你的存储成本会进一步大幅下降。
此外,Databend 完全云原生的设计让你的计算也是弹性的,这意味着当你的计算资源不活跃的时候,计算资源是可以回收的。比如在分析场景中,有时候你一天只跑一次报表,那你不跑报表的时候回收计算资源,成本在计算和存储层面都会大大下降。
Databend 架构
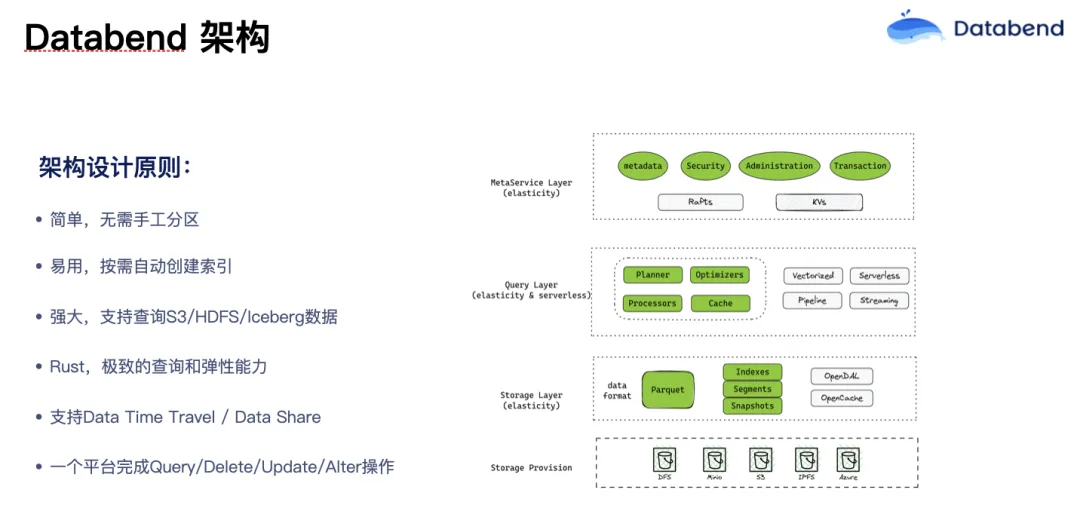
Databend 在架构设计上的原则,一是要简单实用,要做到开箱即用,在部署的时候基本上等于一键部署。这也得益于它云原生的完全无状态设计,对象都在对象存储里,所以部署和管理都会特别容易。我们还提供了丰富的查询语句支持。有一些客户可能一个 SQL 有三四百行、五六百行,Databend 中丰富的函数让这些客户的复杂查询得到很好的支持。
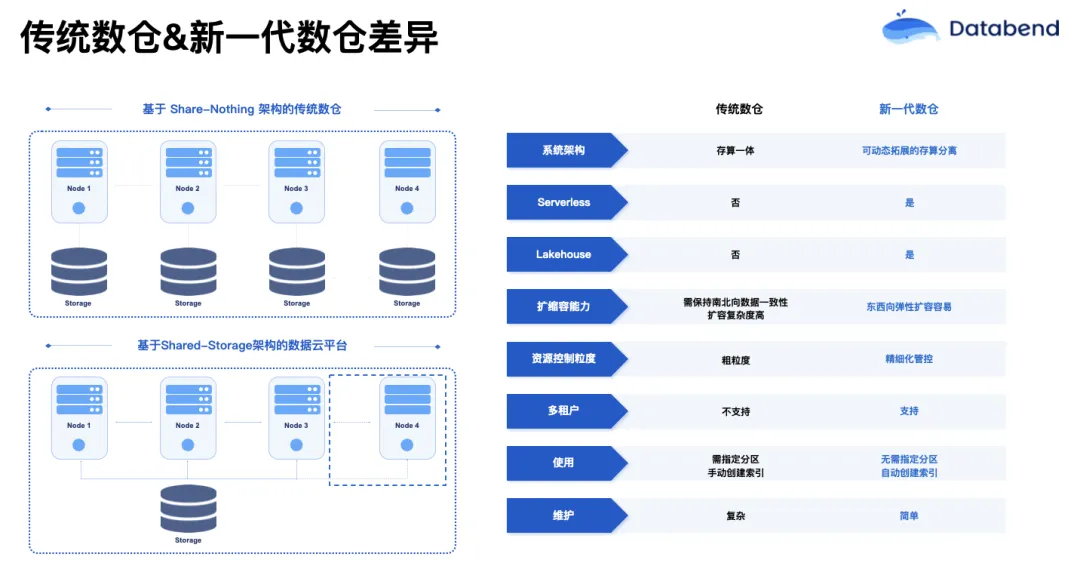
从上图可以看出,云原生数仓和传统数仓最大的一个区别,是传统数仓会使用本地盘,然后把磁盘 shard。当你的数据增长后,你再做一些 reshard,这样可能涉及一些昂贵的数据搬运。ClickHouse 算是一个传统数仓的典型,大家用了这么多年,对它的运维依然感觉很痛。而 Databend 在运维上就没有这方面的痛点,下面的存储都在对象存储上,如果计算压力变大,只要加计算节点就可以了。对象存储的存储容量接近于无限,所以不需要担心 scale 的问题。另外,Databend 除了自己的表查询引擎之外,还有丰富的数据湖格式支持,并支持丰富的对象存储。AWS、 Azure 和 GCP 的对象存储其实有点不一样,所以 Databend 内部孵化了一个项目叫做 OpenDAL,已经纳入到 Aparche 基金会维护。它能适配所有云厂商的对象存储,比如我们今天分享里提到的青云的 QingStor。
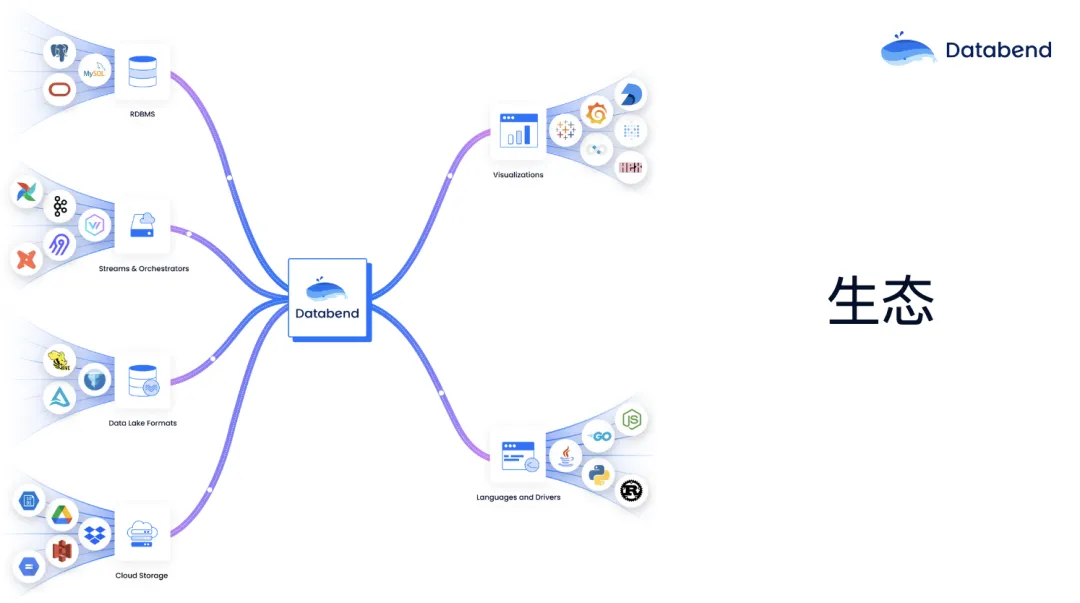
大数据生态在过去十来年的发展中有很多痛,其中一个痛点是比较持续的,就是你的数据在持续增长,这必然带来数据管理成本以及管理复杂度的上升。大数据有一个笑话,整个大数据就像一个动物园,如果想把它搞起来,需要 Spark、HDFS、Yarn 等等 120 个组件,需要操心的事特别多。但是在 Databend 架构中,只需要一个 Databend 和对象存储就可以了。我们也做了很多投入在大数据生态的适配中,比如来自上下游的各种 ETL 工具,上游的 PG 和 MySQL,数据同步的组件,下游的 Grafana、Metabase 等数据可视化的支持等。

以上的 logo 是 Databend 落地的一些客户案例。
自从 Databend 发布后,它的低成本、存算分离等特性已经吸引了很多客户前来试用。我们发现有一些客户的场景是在传统数仓的认知之外的一些场景,但是用了 Databend 之后也得到了很好的落地。目前 Databend 有几个比较大的应用场景:
一个是 OLAP 实时分析。比如说有上游的数据,实时 Ingest 进 Kafka,然后通过 Databend 可以做出来实时分析的报表,而不会像 Hive 或者 Spark 那样需要一个相对缓慢的 ETL 流程。
另外一个是海量日志存储。因为日志一不小心就会产生大量的成本,而对象存储配合上 Databend 优秀的查询引擎,也成为一个优秀的日志解决方案。我们有很多客户跑着 MySQL ,他们会把历史数据归档到 Databend 中,然后再做一个联合的查询,这样能使线上数据库的压力大大减少,同时历史数据又能比较简单地进行查询与分析。
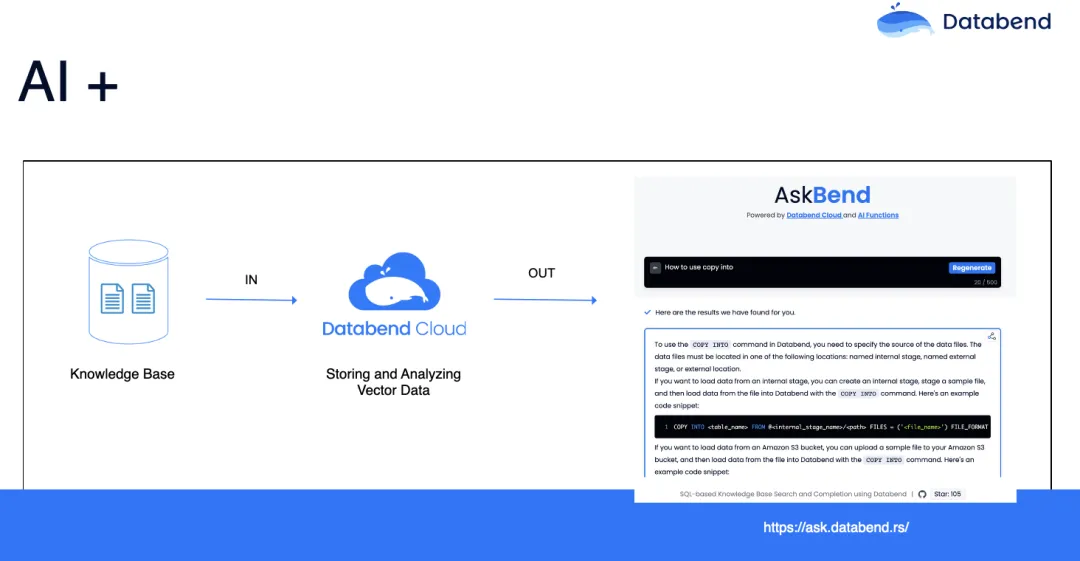
Databend 今年也不能免俗地有一些 AI 的原生支持。你可以把你的知识库存储在 Databend 中, Databend 可以结合 embedding 去查询,然后帮助你实现一个 RAG 解决方案,这个 AskBend 是我们的一个 RAG 解决方案,可以对 Databend 文档进行提问,它可以给你一些基于 Databend 文档的回答,是挺好玩的一个应用。
Databend 的部署
下面来简单介绍一下 Databend 是如何做部署的。Databend 是一个完全云原生的软件,而云原生的一个典型特征就是无状态,所以你部署起来会特别容易。它的状态都在对象存储里,还有一小部分是在 Databend 的元信息中。

所以在部署 Databend 的时候,你只需要关注三个组件: 一个组件就是对象存储。这个对象存储一般是各个云厂商各自的对象存储服务,比如青云有 QingStor,阿里云有 OSS, AWS 有 S3。也有一些客户是直接在 K8s 里跑 MiniIO,这是一些私有部署的场景;
另一个组件是 Metasrv。Meta 是一个相对比较小的 Raft 集群,通常有 3 个或 5 个节点,通过 open Raft 框架实现强预制的高可靠集群,它会来用来存储 Databend 的一些元信息,对象存储的入口会展示在这个 Meta 里;
最后一个组件是 Query。 Query 部署起来是最容易的,它是完全无状态的,只要连上 Meta 和对象存储,就可以拿来查东西。
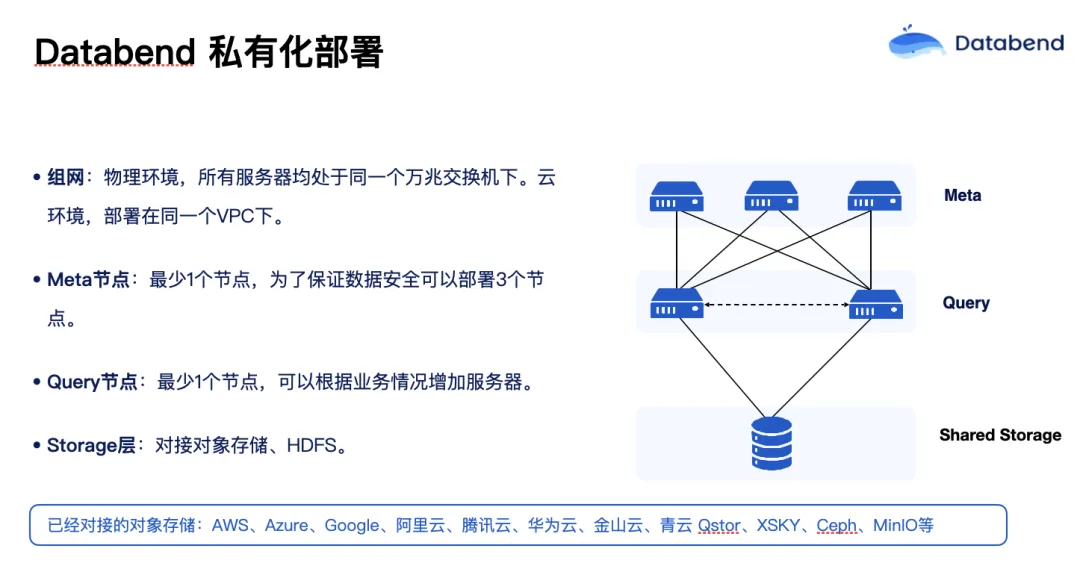
使用 Databend 最便捷的方法是 Databend Cloud,我们提供云上的 SaaS 服务。但如果你想做私有部署,我们也提供 Databend 企业版和开源版,上图是 Databend 私有部署的架构,你可以使用 K8s,也可以用 bare metal 的虚拟机。其实就是刚才介绍的这几个节点,先把 Meta 部署起来,再把对象存储准备好,然后把 Query 启动起来就可以了。此外,还可以根据你的需求,把 Query 节点分成不同组。比如说 A 部门用这几个 Query,B 部门用那几个 Query。它们都是完全隔离的,不会相互影响,不同部门也可以根据自己的需求单独 scale 计算资源。
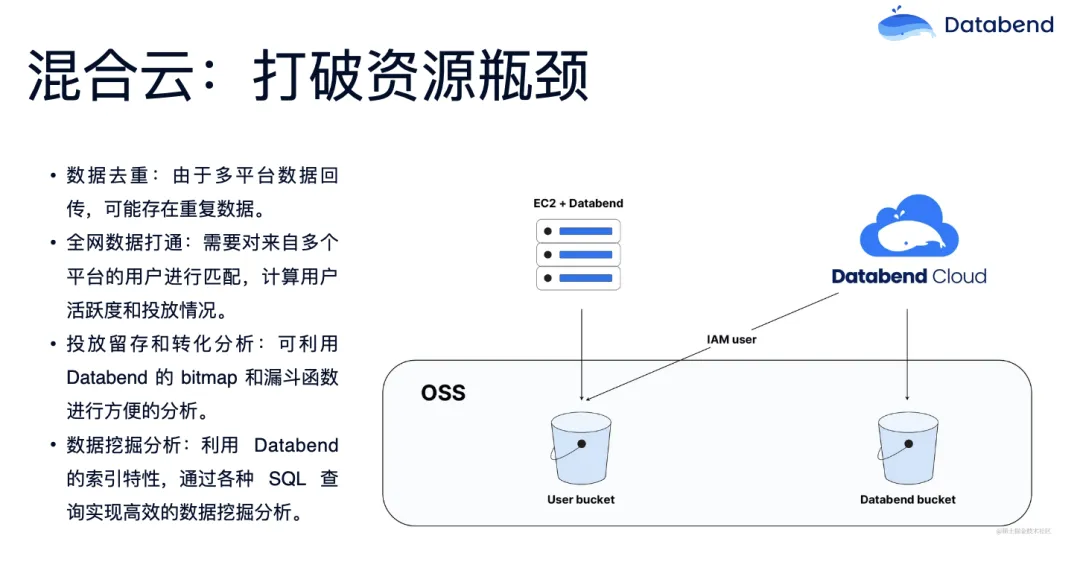
除了 Databend Cloud 和私有部署,Databend 还允许使用混合云的部署方式,把你的数据存储在自己的对象存储里,通过 Databend Cloud 的可弹性算力去计算。之前有客户和我们提过一个反馈,他是在 K8s 里跑分析的 workload,但是公司的计算资源限额比较少,所以他就想高峰期或者在跑报表的时候,把 OS bucket mount 到 Databend Cloud 上,利用 Databend Cloud 弹性算例帮助分析,分析完就可以全部释放掉,不会造成任何其他的额外的成本。这就是一种典型的混合云的部署方式。
使用 KubeSphere Cloud 部署 Databend
接下来具体介绍一下怎么使用 KubeSphere Cloud 来部署 Databend。 我们为什么要选择 KubeSphere?KubeSphere 有一个易用的管理 UI,使用 Helm Chart 就可以很简单地一键部署到 KubeSphere 中。应用的管理和部署的过程,以及后续的运维、监控、日志,都可以通过 KubeSphere 作为入口去管理,具有很好的使用体验。
使用 Kubernetes 来管理 Databend 是我们最推荐的部署方式,因为 Kubernetes 有很强大的 coordination 能力,能帮助我们做到自动恢复、水平扩展、负载均衡等等。部署在 Kubernetes 里,你的程序、进程 crash 了也不用特别担心,它都能自动重新拉起来。在 Kubernetes 里,你的 Prometheus、 Grafana 和 MiniIO 都可以在一个生态里面共同运作。总结来说,用 Kubernetes 来部署 Databend 是首选,而 KubeSphere 又是 Kubernetes 的最佳搭档。

部署的第一步是先登录青云用户后台,创建一个 QingStor 的 bucket。如果你用阿里云、腾讯云、AWS、GCP,有其他的对象存储,或者自己私部的 MiniIO 也都是类似的。需要额外注意的就是拿到它的 Endpoint 地址以及它的访问的 ak、sk,你需要把这部分信息先记下来,后面在部署的时候会用到。然后我们可以在 KubeSphere Cloud 上创建一个 KubeSphere 集群。使用默认配置创建免费版集群即可尝鲜体验,个人用户每月有 10 小时免费额度。创建之后访问它的控制台,可以看到 KubeSphere 的管理员界面。
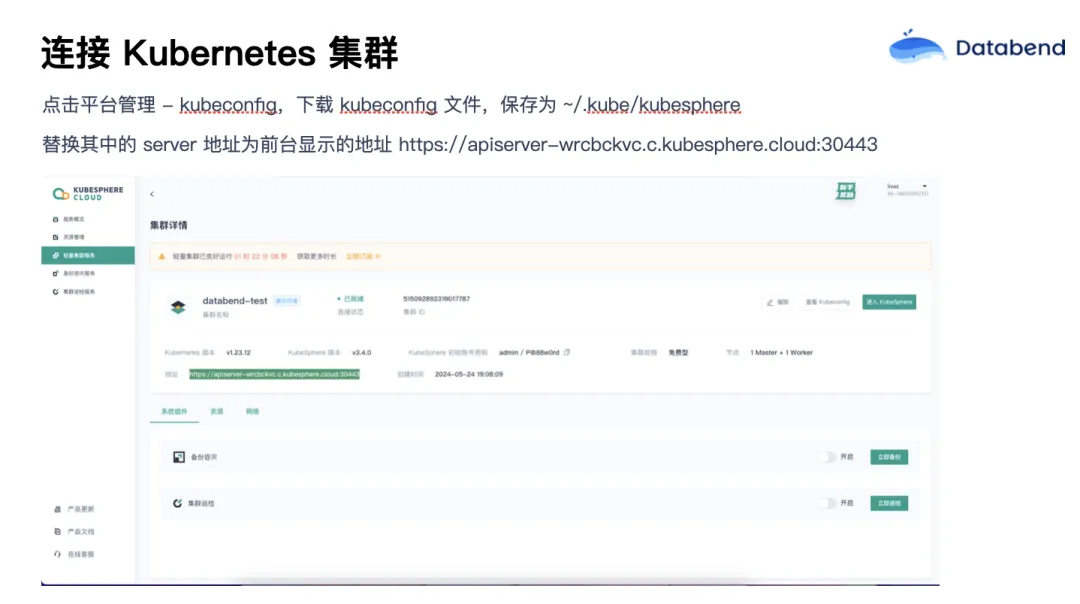
点击平台管理,我们可以下载它的 kubeconfig 文件,保存为 ~/.kube/kubesphere。这里需要做一个小修改,它前台有一个 API Server 的地址,你要把这个地址记下来,替换其中的 Server 地址为前台显示的地址。

开始先部署 Meta 节点。因为是演示试用,我们先部署了一个 Meta 实例。在生产环境中的话,一般建议最少要配 3 个实例。实例一定是奇数,不要配偶数,这是 Raft 共识协议的要求。基本上把这个命令往上一贴一运行,就能够稳定地把它部署上来。

在 Meta 节点就绪之后,开始部署 Query 节点。前面我们已经得到了对象存储的地址,图中红色的部分其实就是刚才对象存储的 ak、sk 以及 Endpoint 地址。然后填上刚才那个 Meta 的地址。

打开 shell,执行上述命令,Query 就准备出来一个 values.yaml。然后 install,Query 就能正常运行了。执行 get svc 命令就可以看到 data query 已经启动了。
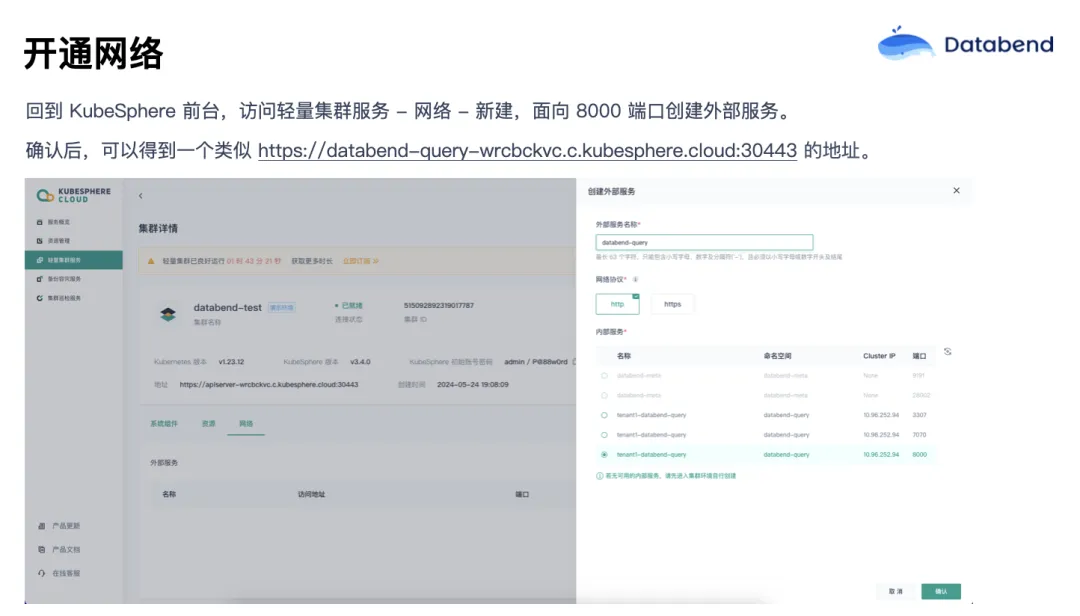
回到 KubeSphere 前台,这里还可以做网络映射。点网络新建,可以把 Databend 的 8000 端口暴露出来,得到一个地址。这个地址可以用来访问 KubeSphere Cloud 里的 Databend 实例。
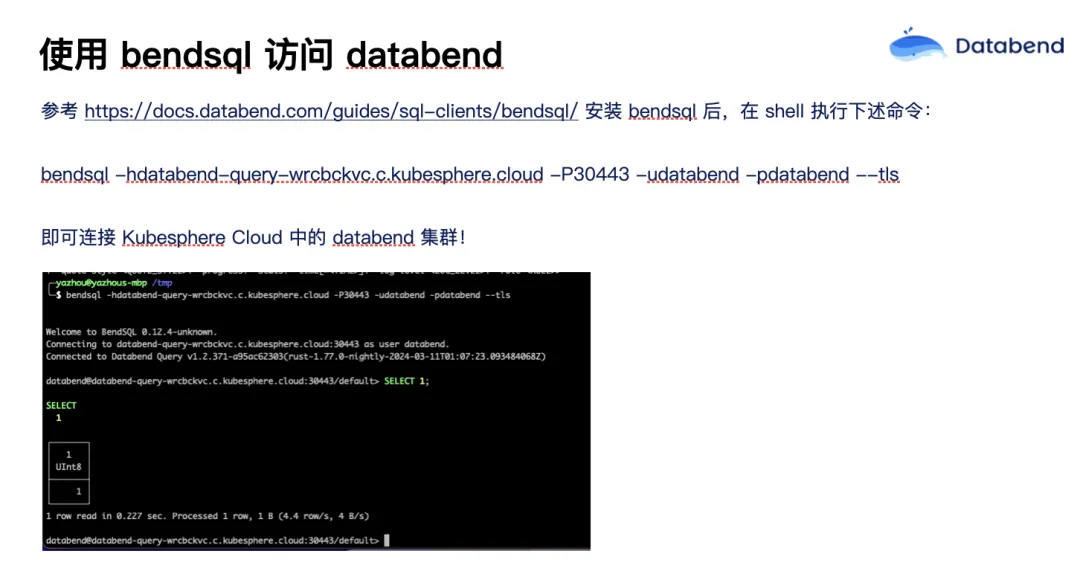
接下来如何连接 Databend 呢?Bendsql 是 Databend 一个十分方便的命令行界面客户端工具。下载安装之后,我们可以把刚才的 host 贴过来,输入 user、password 连接 Databend 集群。
整个部署的过程其实非常简单,跑两个命令,先把 meta 部署上去,然后再把 Query 也部署上去。部署完后,你就可以在 K8s 里面,根据你的需求去 Scale up ,Scale down,不用的时候就把它变成 0 回收掉。用的时候再把它 Scale 出来,随自己的需要来控制就好。
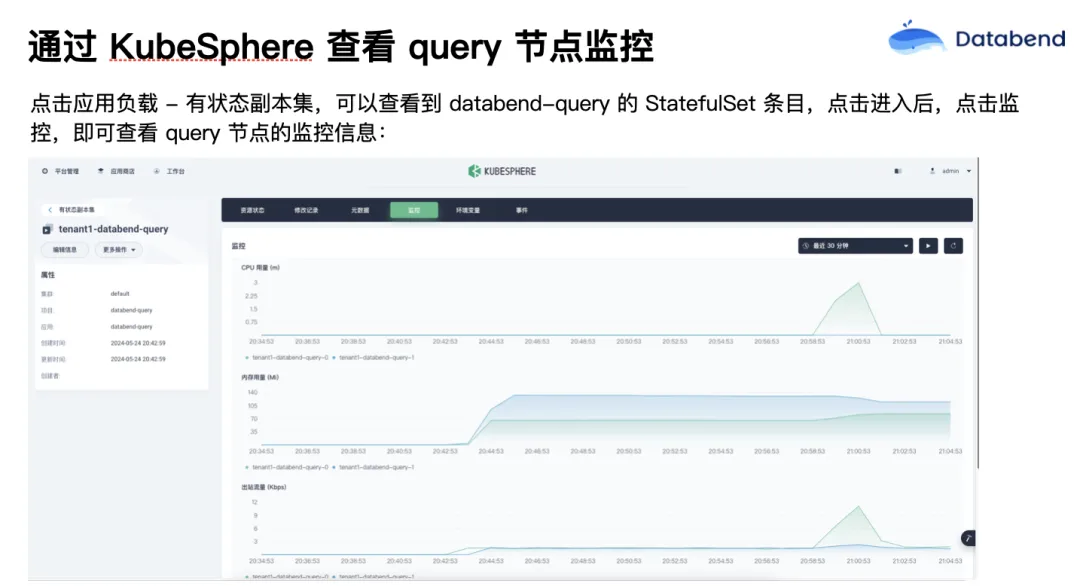
部署完后,你可以在 KubeSphere 界面去查看 Databend query 的 statefulset。Databend query 虽然是无状态的,但是 stable set 可以给每个 Pod 一个编号。我们在查 SQL 的时候,可以找一个固定的 query 节点去发SQL。你可以看到它的监控状态。当 CPU 或者内存不够时,可以有针对性地去调整它的规格,这样平时的运维就会简单一些。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
Databend Cloud:https://databend.cn
Databend 文档:Databend
Wechat:Databend
GitHub:GitHub - datafuselabs/databend: 𝗗𝗮𝘁𝗮, 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 & 𝗔𝗜. Modern alternative to Snowflake. Cost-effective and simple for massive-scale analytics. https://databend.com