【深度学习】Transformer梳理
零、前言
对于transformer,网上的教程使用记号、术语不一 。
最关键的一点,网上各种图的简化程度不一 (画个图怎么能这么偷懒) ,所以我打算自己手画一次图。
看到的最和善(但是不是那么靠谱,我怀疑图有误)的transformer教程:一文了解Transformer全貌(图解Transformer)
注意: 全连接层在概念上输入必须是一维向量,但是实际实现的时候我们会采用批处理将多个样本的向量组拼成矩阵,用矩阵乘法加速运算。如果用单一样本的向量来标注全文可能更清晰,但是为了更贴近实用,约定全文的输入长这个样子而不是向量:
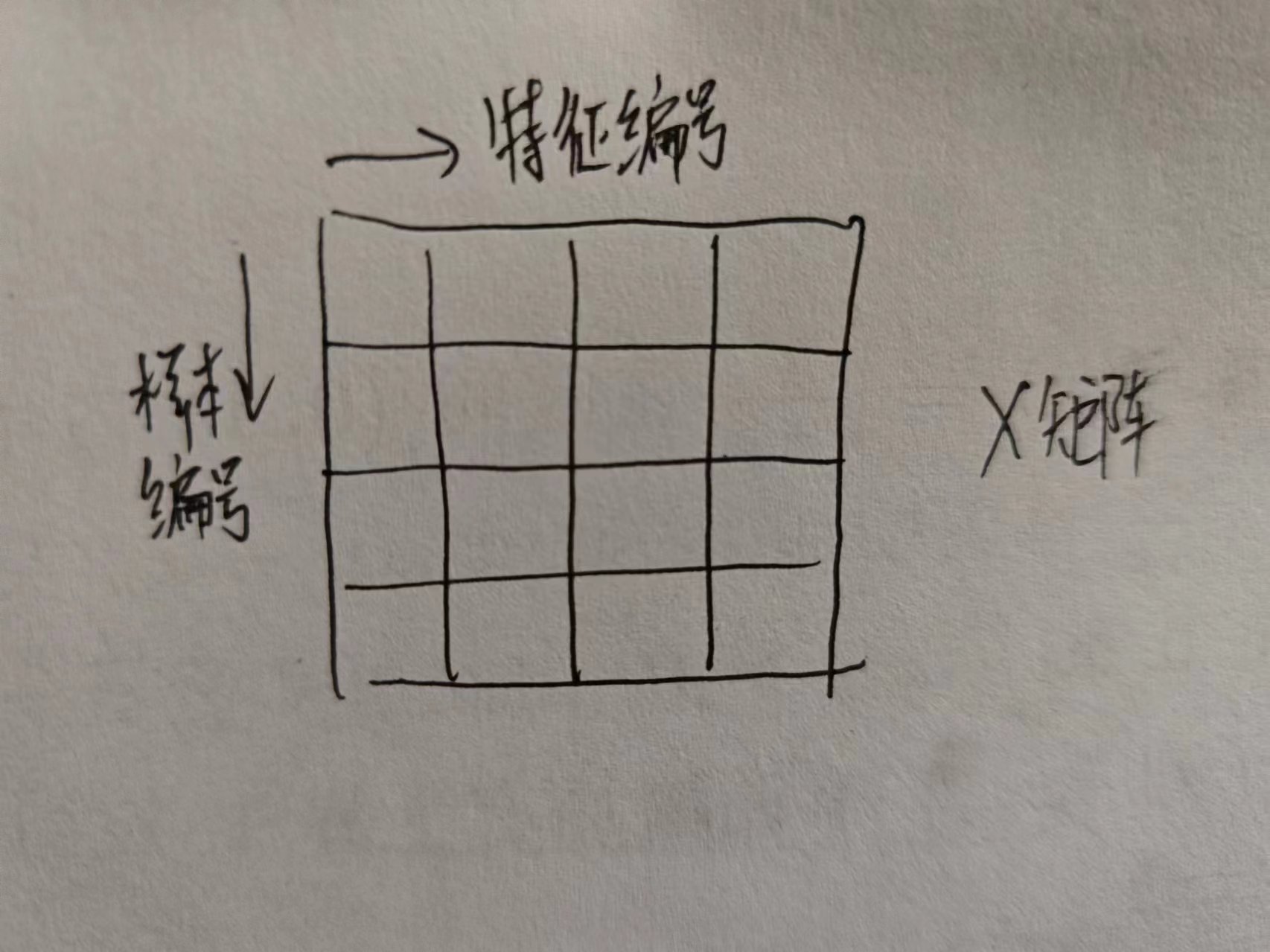 其实,输入也不是矩阵。。。输入是3维张量,三个维度分别是batch_size, number(当前用到的词数), dimension(特征维度)
其实,输入也不是矩阵。。。输入是3维张量,三个维度分别是batch_size, number(当前用到的词数), dimension(特征维度)
其中,number没有画出来,你可以按number=1来想,当成矩阵方便一些
一、前置基础中的前置基础
- RNN
- 残差连接(无论什么书,通常会在CNN的ResNet这一节中讲)
- 归一化
- 注意力机制
二、前置基础
- Encoder-Decoder模型
- 自注意力
- 多头注意力
简单介绍一下,
-
Encoder-Decoder模型是为了解决RNN容易忘记前文的问题(即使是LSTM也可能存在这个问题)
-
自注意力
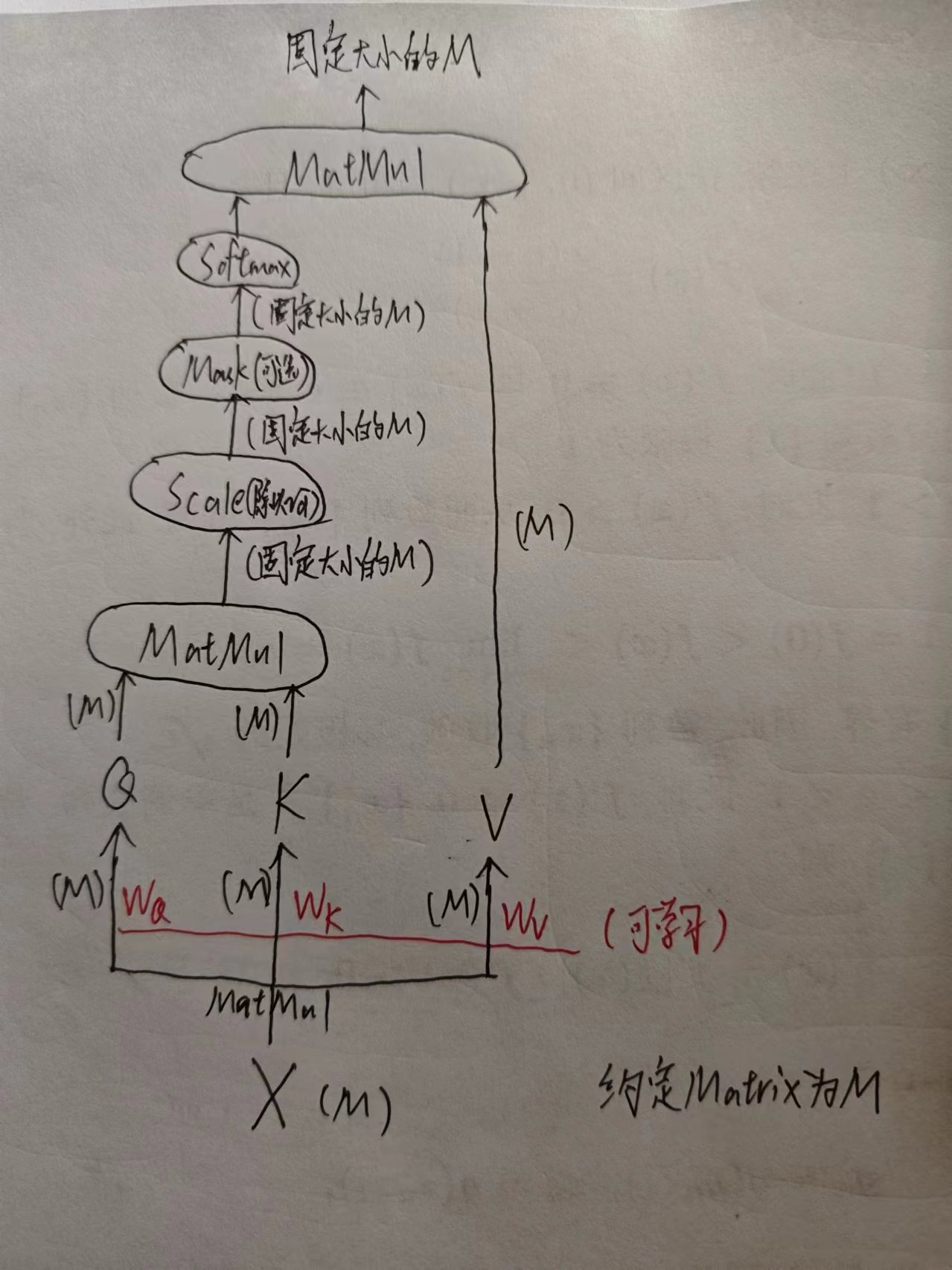
(其中Q、K、V是什么属于“注意力机制”的内容,假设你已经了解了这一块内容并能看懂上面的图)
(对于Scale为什么除以根号d,原因引用一篇文章:Attention为什么要除以根号d)
可以发现,自注意力的作用是把X转换为固定形状的M,便于处理 -
多头注意力
多头注意力本身并不限制使用的是什么注意力来连接起来,Transformer中用的是自注意力。
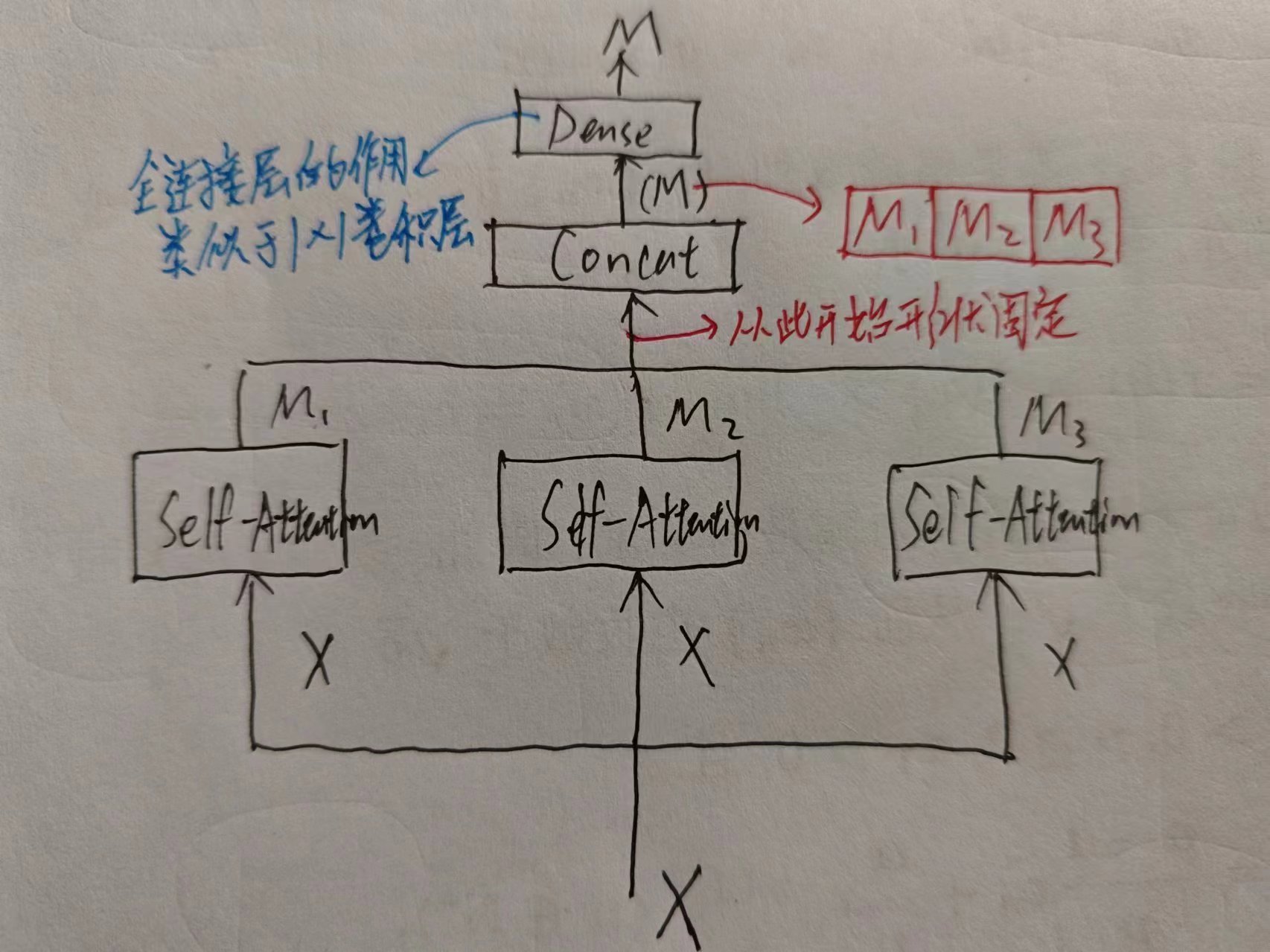 多头注意力将多个自注意力Concat,是因为这样“并列”的结构能优化最长最短路,而且这样能表达的注意力机制更丰富
多头注意力将多个自注意力Concat,是因为这样“并列”的结构能优化最长最短路,而且这样能表达的注意力机制更丰富
三、Transformer
Transformer相比起Seq2Seq模型,区别在于,Seq2Seq中RNN承担了Encoder、Decoder的角色,事实上,Encoder、Decoder可以由多种途径实现,Transformer中RNN不复存在,用的是多头注意力。因此Transformer是一种纯注意力机制的模型。
接下来在一个具体场景中学习Transformer。
目标:做文本翻译
数据集:包含翻译前后的文本,分别为Source和Target
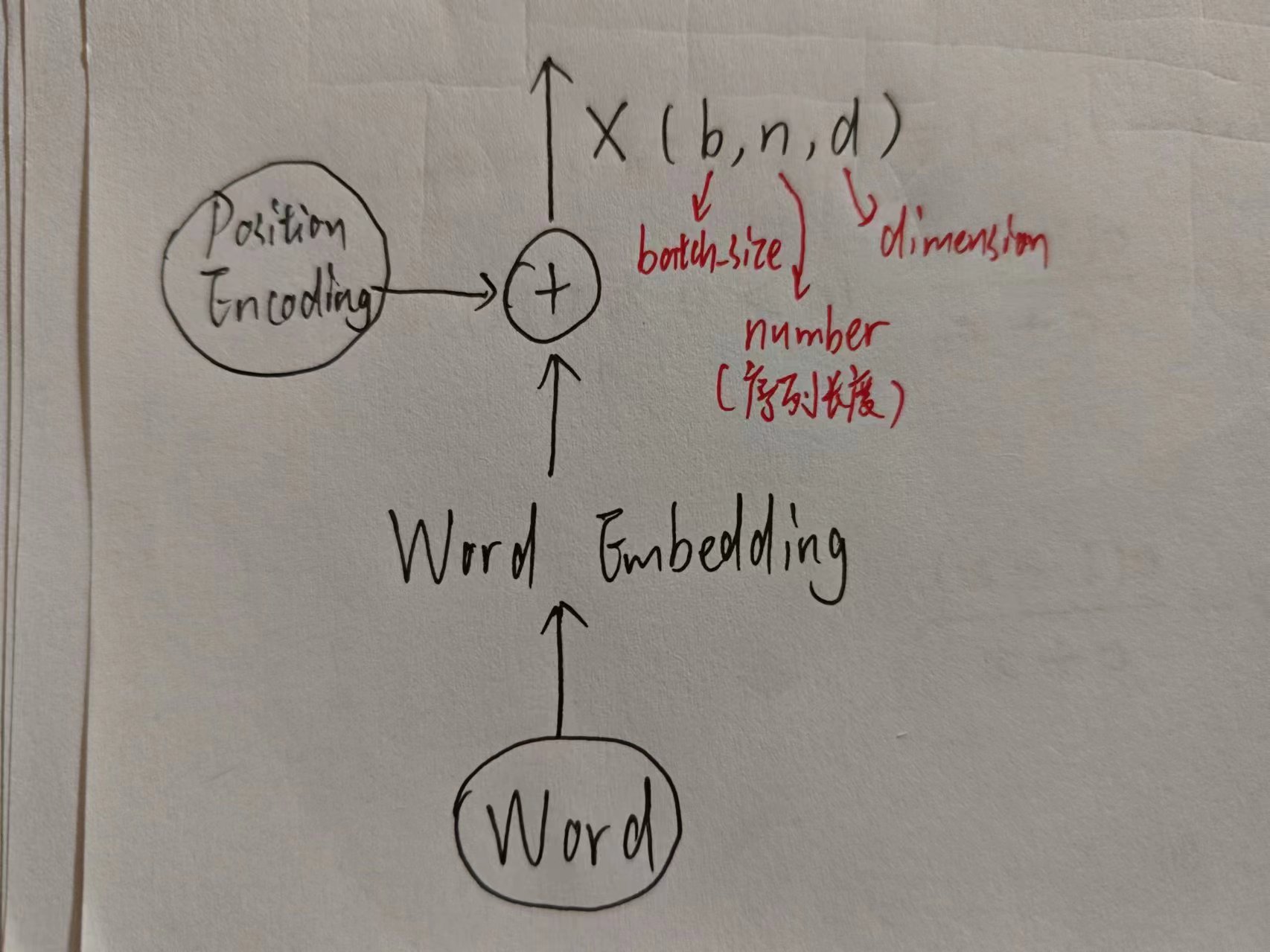
1. 输入原文本Source
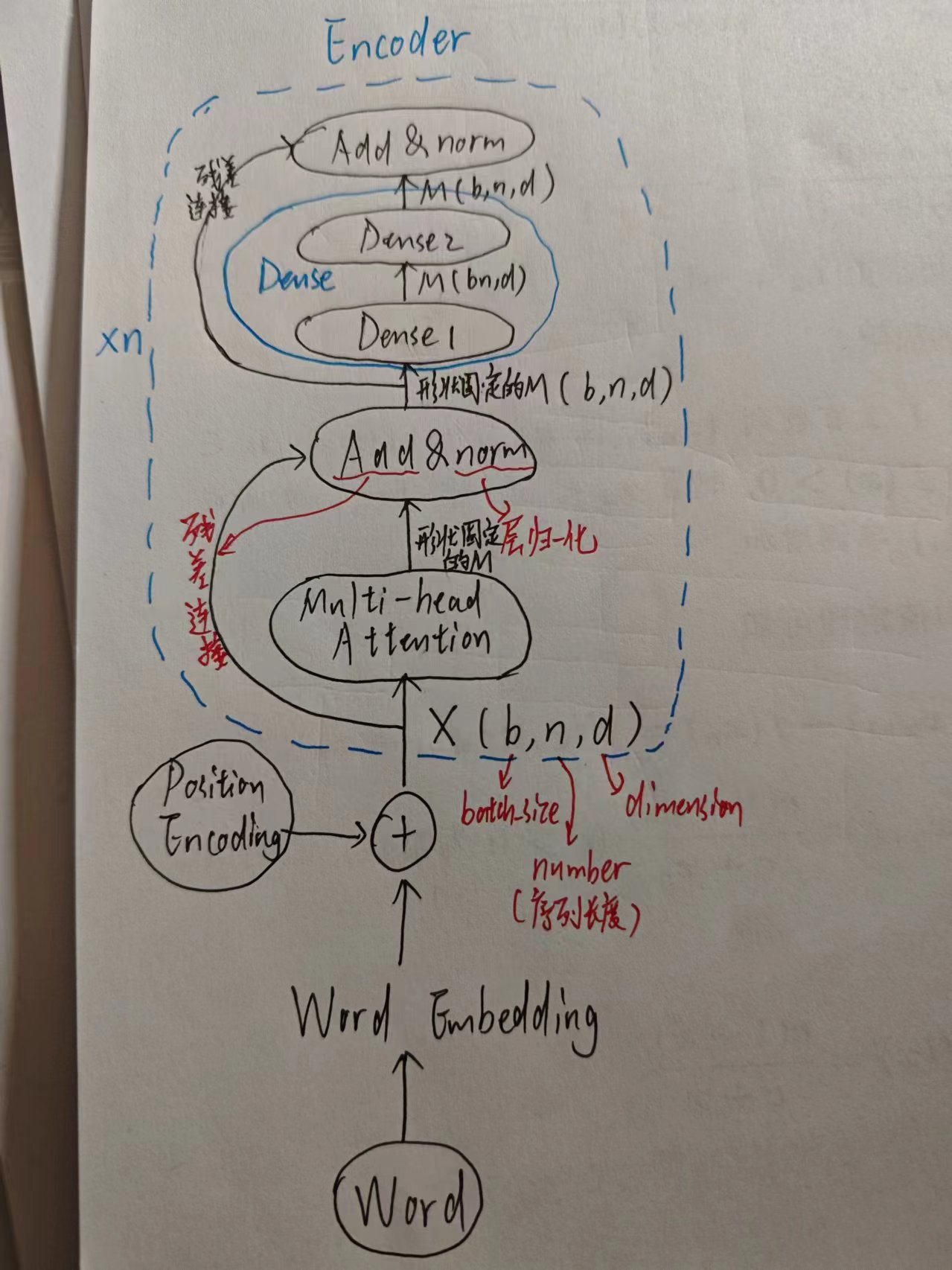
Source是单词,所以不能直接扔进神经网络去,需要先编码成向量,既不要损失词本身的信息,也不要损失词所在语句的位置的信息,那就干脆都编码,然后加起来。
2. Encoder
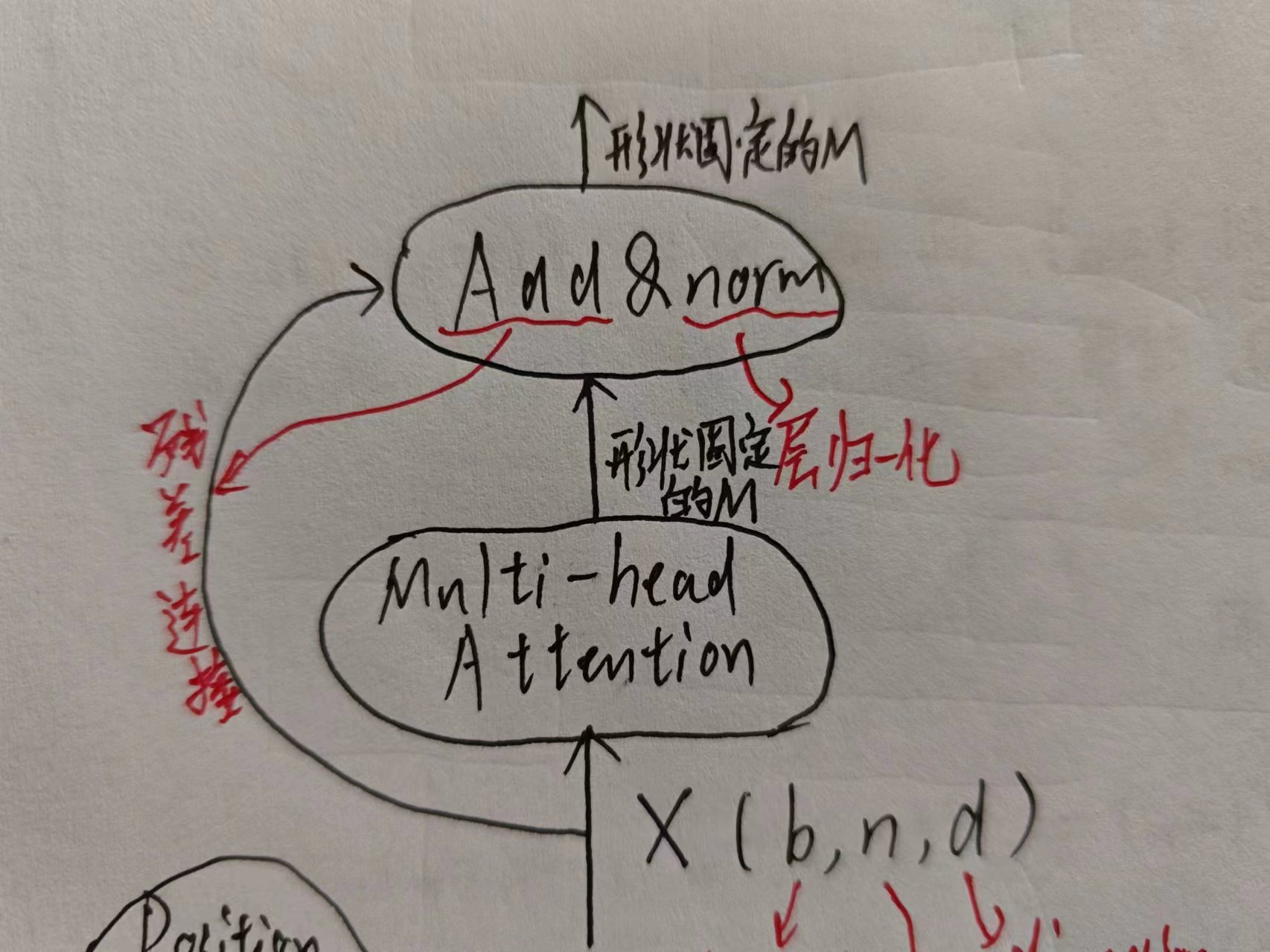
首先先经过多头注意力机制,然后Add&norm
- Add指的是残差连接,使梯度流动更平稳,防止梯度消失/爆炸
- norm本身归一化的目的是为了防止协变量偏移,提高泛化能力,归一化分为两种(层归一化对batch_size归一化,批归一化对dimension进行归一化),这里用的是层归一化
- 关键:多头注意力机制对于注意力的表达更丰富,且本身“注意力”的含义就是对哪个词(所编码的向量)更有偏向(注意力分数,即权重矩阵),也就是说中英文语序这种问题不存在,是靠注意力机制来不定顺序翻译的
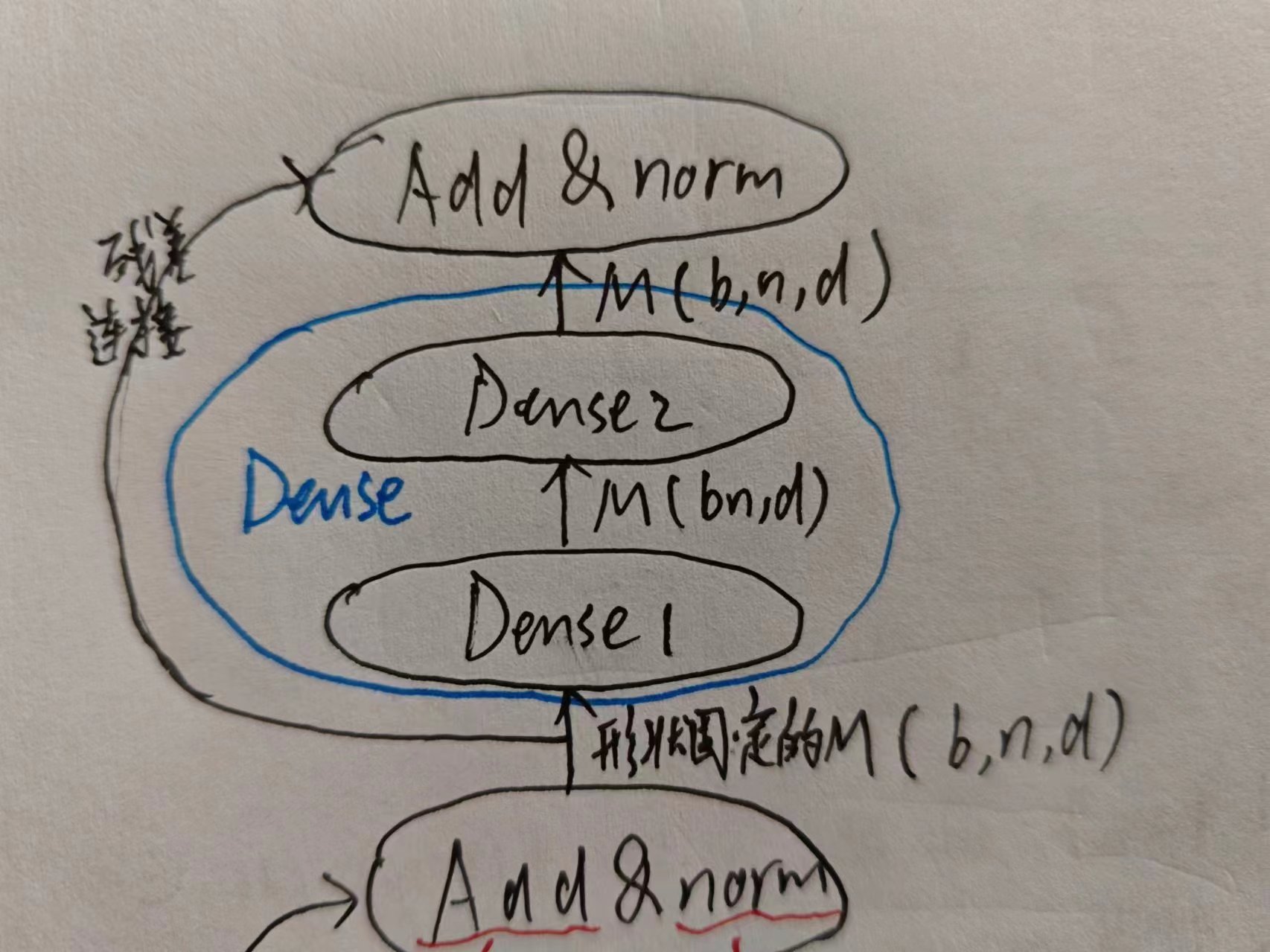 矩阵M是原本是三维张量,漏掉的n并不是随意漏的,而是因为翻译不应当和n相关(后面还会具体解释的),所以这一部分是为了丢掉n这个维度。
矩阵M是原本是三维张量,漏掉的n并不是随意漏的,而是因为翻译不应当和n相关(后面还会具体解释的),所以这一部分是为了丢掉n这个维度。
3. 输入目标文本Target
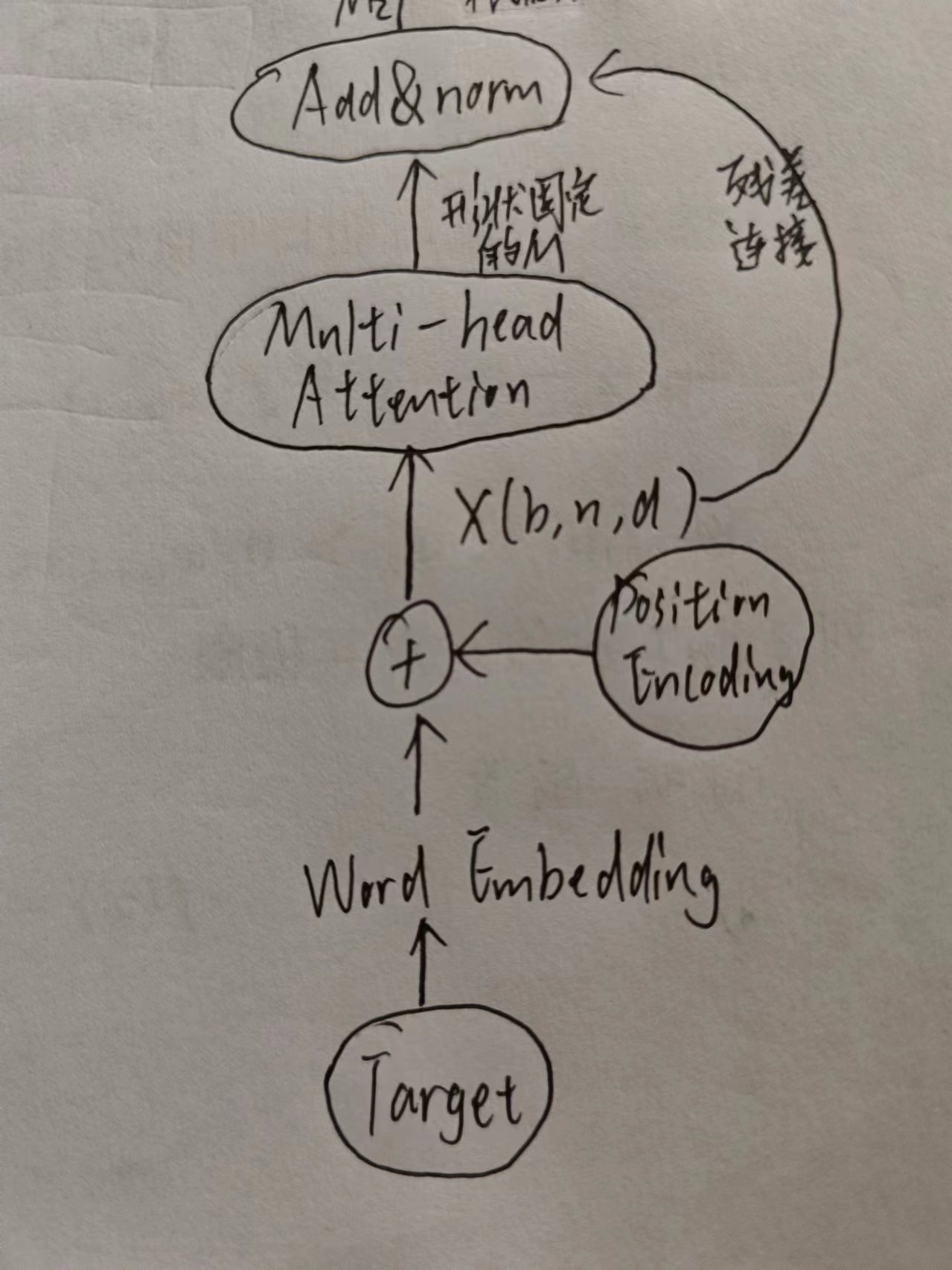
和Source是一样的,但是Target需要有 “Mask” ,为了避免模型过早“偷窥”到Target后面的内容
4.Decoder
上图也展示了Decoder的第一个多头注意力,还有第二个,第二个与之前的Encoder相连
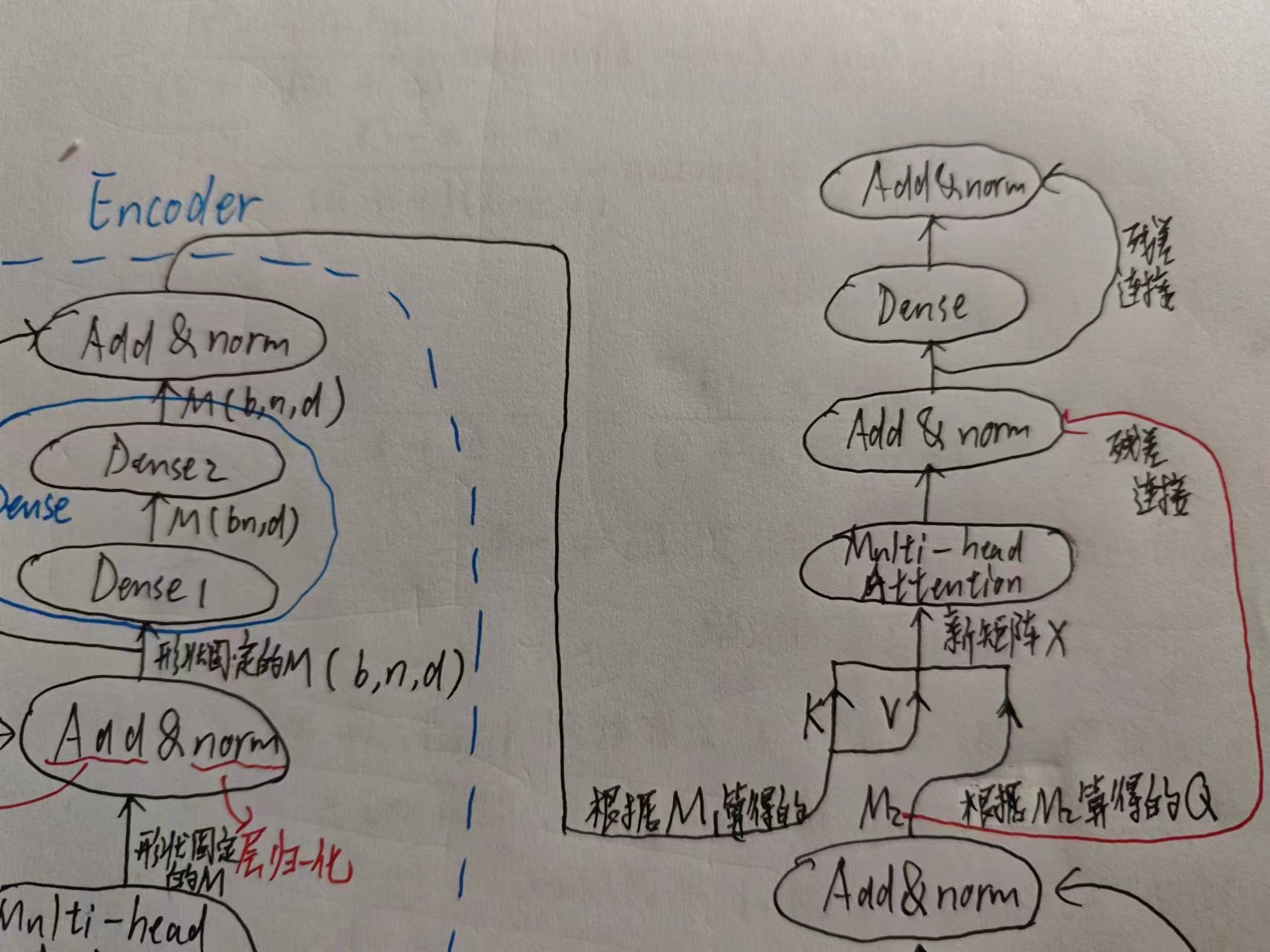 回忆注意力机制,现在把Encoder想成环境条件Key和Value,Decoder中已经出现的Target(没有被Mask的部分)词,你可能会对其中感兴趣也就是Query,那么你就懂上图为什么这么连了。
回忆注意力机制,现在把Encoder想成环境条件Key和Value,Decoder中已经出现的Target(没有被Mask的部分)词,你可能会对其中感兴趣也就是Query,那么你就懂上图为什么这么连了。
接着是熟悉的Dense,和Encoder一样。
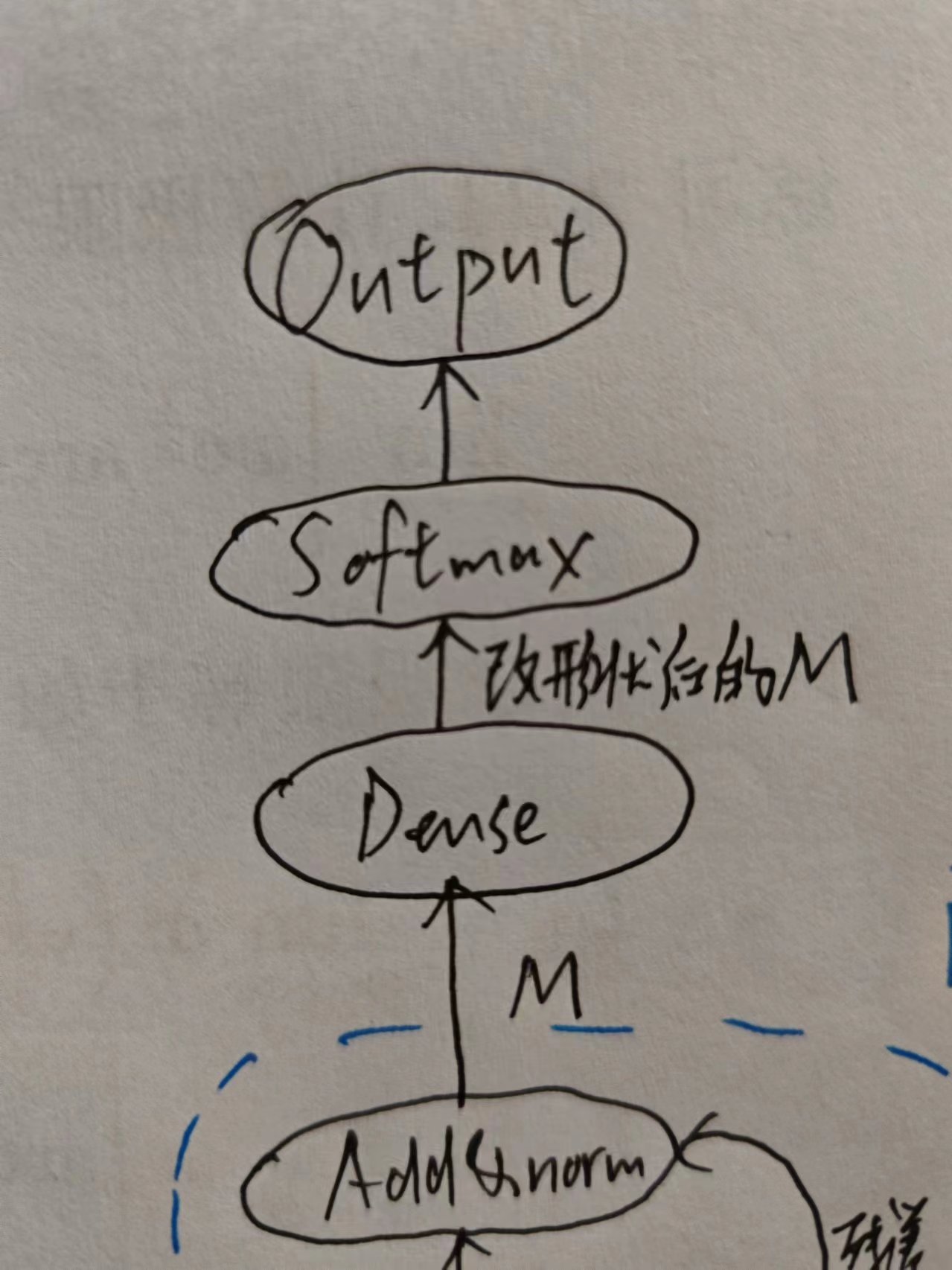 用一个Softmax决定生成哪个词,这里再次体现了Dense类似于1×1卷积层的功能。
用一个Softmax决定生成哪个词,这里再次体现了Dense类似于1×1卷积层的功能。
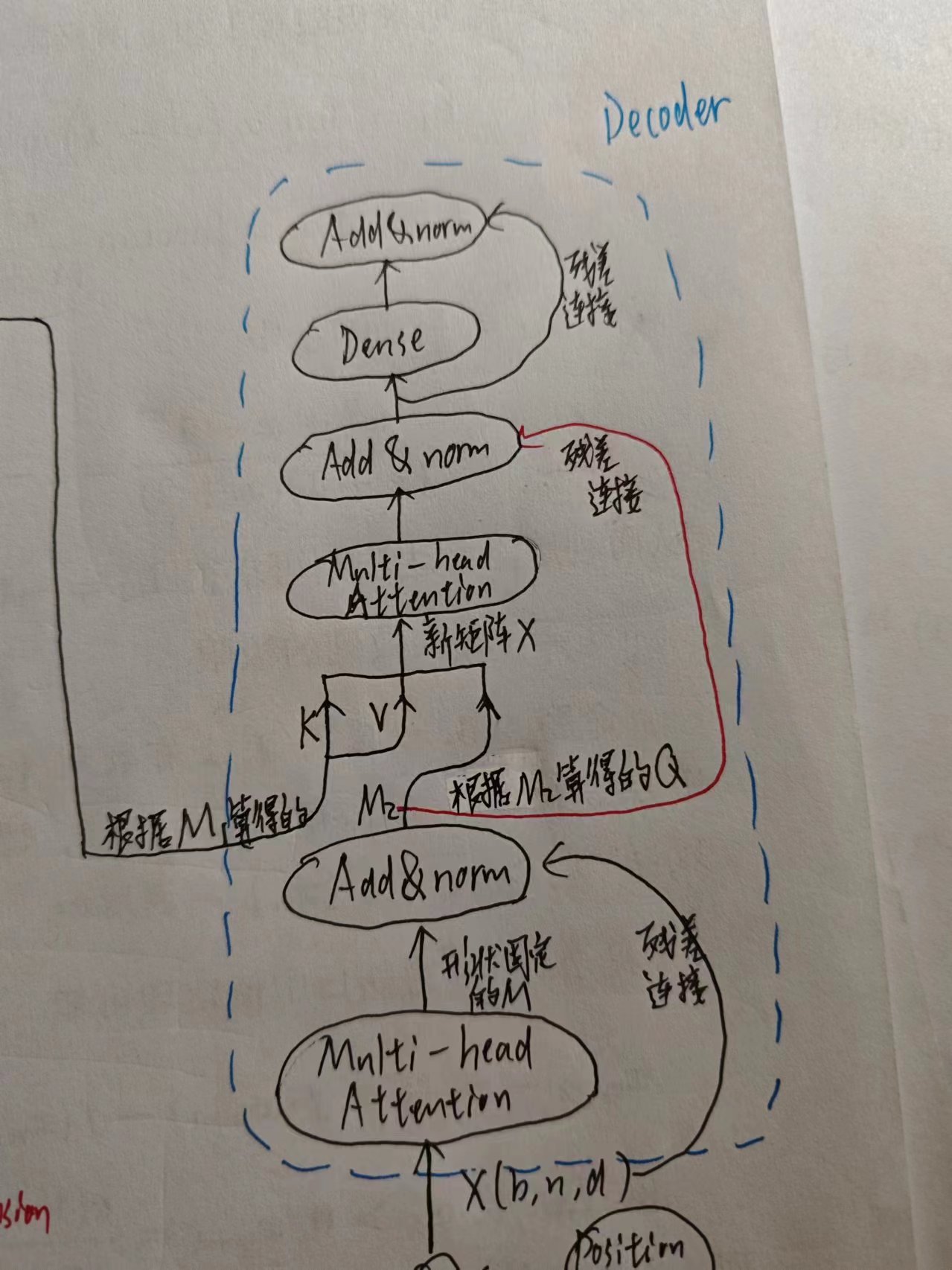 (decoder图里忘了画×n了)
(decoder图里忘了画×n了)
5. 反向传播进行训练
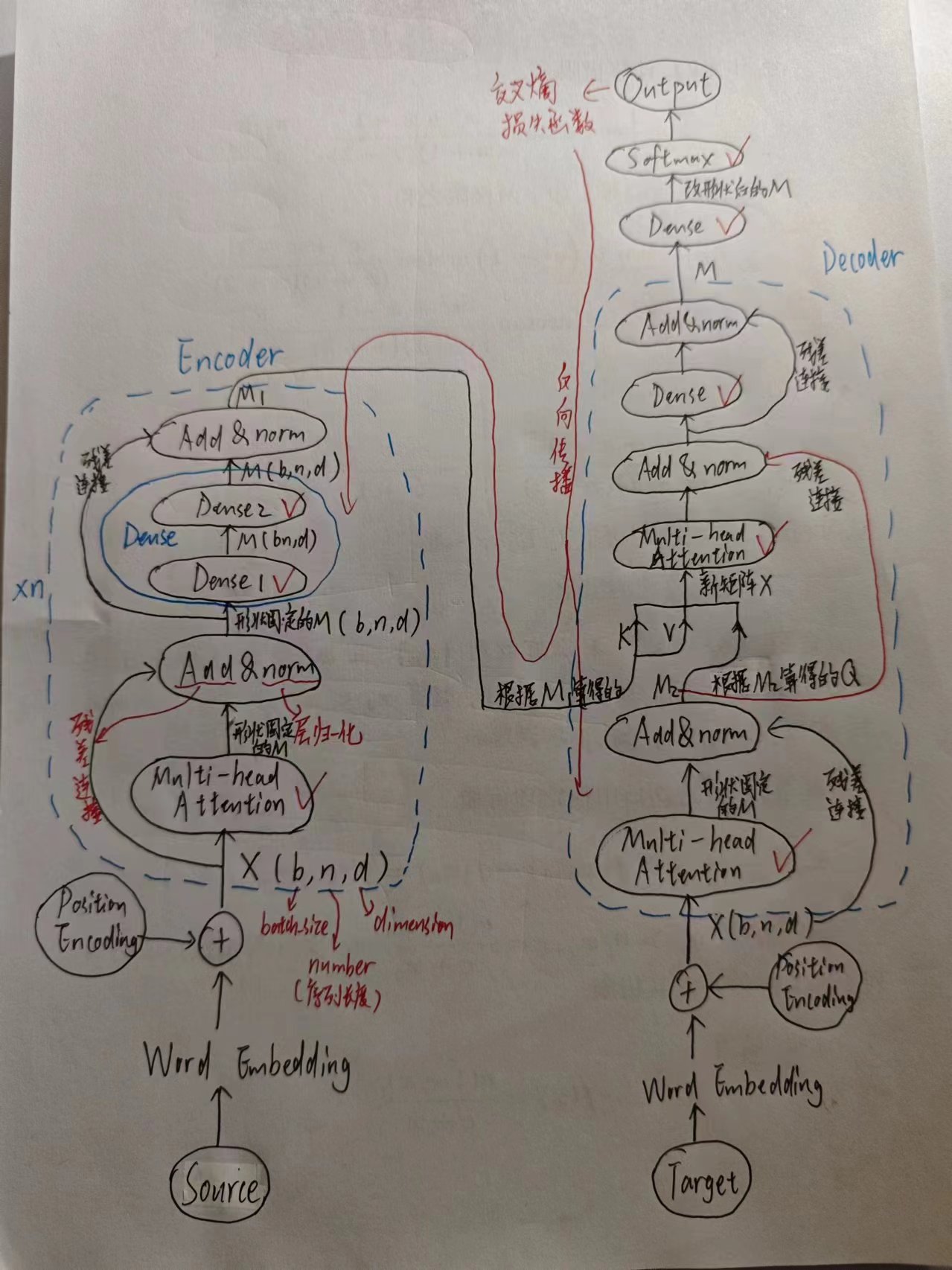 图中打勾的部分是有参数能学的部分,由于输出是Softmax所以用交叉熵损失函数,链式法则反向传播更新参数。
图中打勾的部分是有参数能学的部分,由于输出是Softmax所以用交叉熵损失函数,链式法则反向传播更新参数。
注意一点,反向传播是等到所有词都依次通过一遍transformer后,再反向传播(再次体现了上文中的翻译不应当与序列长度n有关),以确保模型学习到了整个序列的上下文信息。
输出序列长度既可以长于输入序列,也可以短于输入序列,这是因为有输入序列Source有mask(Target也有mask,确实,Transformer有两个地方用到了mask),你认为的一次丢几个词进去,本质上输入序列长度固定,是因为mask的存在使得前面有指定几个词有效。输入序列长度固定,那么输出序列长度也理应固定且很长(是一个你规定的最大长度),只是模型通过大规模的数据集自己判断何时给出,所以输出序列长度是介于没有到这个规定最大长度之间的数,可以长于输入序列,也可以短于输入序列。