数据挖掘 | 实验三 决策树分类算法
文章目录
- 一、目的与要求
- 二、实验设备与环境、数据
- 三、实验内容
- 四、实验小结
一、目的与要求
1)熟悉决策树的原理;
2)熟练使用sklearn库中相关决策树分类算法、预测方法;
3)熟悉pydotplus、 GraphViz等库中决策树模型可视化方法。
二、实验设备与环境、数据
PC机 + Python3.7环境(pycharm、anaconda或其它都可以)
python库: sklearn、pydotplus、 GraphViz等,
提供鸢尾花数据集iris150条记录(150*5)包括一个类标号属性。
三、实验内容
1)算法原理
决策树算法依据对一系列属性取值的判定得出最终决策。在每个非叶子节点上进行一个特征属性的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。算法的目的是产生一棵泛化性能强,即处理未见数据能力强的决策树。
2)具体要求
1)利用相应库中算法对鸢尾花数据构建决策树;
了解sklearn相关库中决策树分类方法的接口,清洗、预处理处理鸢尾花数据,说明该方法对数据集的要求。
2)可视化决策树;
了解pydotplus、GraphViz等相关库中决策树可视化方法的接口,结合上述构建方法中参数的设置,分析每次构建的树的层数及叶子数目。
3)分别查看训练集、测试集上模型的评估指标(准确率);
对鸢尾花数据进行分割,或使用交叉验证等方法对每次形成的决策树进行评估。
4)(选做)自己编写ID3/C4.5决策树分类算法,构建决策树,并评估模型。
首先对数据进行预处理,主要包括缺失值的处理以及连续属性的离散化方法;然后进行各个模型的实现,包括:数据集中属性的信息增益(或信息增益率、gini指数)的计算;选择最佳划分属性;以及构建决策树的递归方法等。
实验代码:
# -- coding: utf-8 --
import osfrom sklearn import tree
import pydotplus
from sklearn.datasets import load_iris # 从sklearn包里datasets里导入数据集iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier # 训练器
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from pylab import *
from sklearn.tree import export_text
import randomos.environ["PATH"] += os.pathsep + r'D:\Environment\Graphviz2.38\bin'
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码
# print(os.environ.get('PATH'))
# Graphviz是一个开源的可视化图形工具,可以很方便的用来绘制结构化的图形网络,支持多种格式输出(需要独立的在系统内安装)
# 导入数据集
iris = load_iris()
# print(iris)
# print(iris.data) #原数据
# print(iris.target) #目标数据# 构建模型
# 用于构建决策树,创建分类器
# scikit-learn 提供的 DecisionTreeClassifier 类可以做二分类任务
# 模型的训练,拟合数据
clf = tree.DecisionTreeClassifier().fit(iris.data, iris.target)# X: 训练数据,稀疏或稠密矩阵;Y别标签,整型数组# 导出树的结构
r = export_text(clf, feature_names=iris['feature_names']) # 以文本形式输出,决策树模型
print(r)
'''
tree.export_graphviz参数说明
为了能够准确的输出决策树规则,方法tree.export_graphviz当中一下参数必须设置成以下形式。其余参数使用默认的即可。
feature_names:特征名称,顺序必须和训练样本的数据一致
class_names:类别名称,输入的时候,必须要排序。如将原来的[‘1’, ‘0’]设置为[‘0’, ‘1’],注意:数据类型必须为str型的。
filled:填充,必须为True
node_ids:节点id,必须为True
rounded:画的图形边缘是否美化,必须为True
special_characters:必须为True
'''
# 以Graphviz格式导出
dot_data = tree.export_graphviz(clf,out_file=None,feature_names=iris.feature_names,filled=True,impurity=True,rounded=True)graph = pydotplus.graph_from_dot_data(dot_data) # 以DOT数据进行graph绘制
graph.get_nodes()[7].set_fillcolor("#FFF2DD") # 设置显示颜色
graph.write_png('iris.png') # 保存成图片
#
# 训练集、测试集数据分割seed = random.randint(1, 2647483647)
# 随机将样本集合划分为训练集 和测试集,并返回划分好的训练集和测试集数据。
# train_test_split是交叉验证中常用的函数train_data:所要划分的样本特征集,train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子
train, test, train_label, test_label = train_test_split(iris.data, iris.target, test_size=0.3, random_state=seed)
# print(train,train_label)
# print(test,test_label)
# 选用机器学习算法
models = [] # 模型列表 模型算法对象加入列表
models.append(('DecisionTree', DecisionTreeClassifier())) # 决策树
models.append(('GaussianNB', GaussianNB())) # 朴素贝叶斯
models.append(('RandomForest', RandomForestClassifier())) # 随机森林
models.append(('SVM', SVC())) # 支持向量机SVM# 基于测试集test的预测及验证
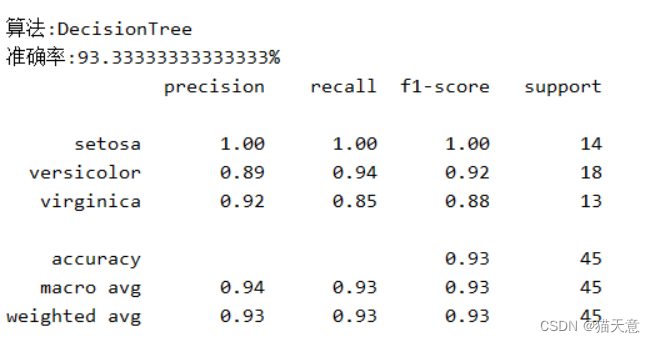
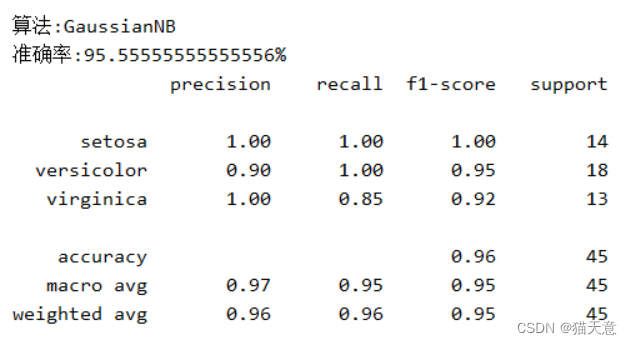
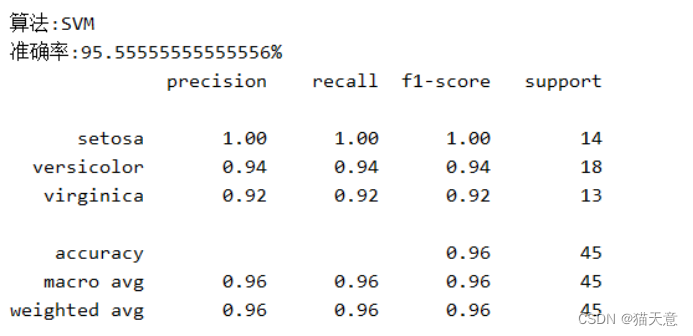
for name, model in models:model.fit(train, train_label) # 进行训练 用训练集和训练标签pre = model.predict(test) # 用测试集进行预测results = model.score(test, test_label) # 结果验证print("算法:{}\n准确率:{}{} ".format(name, results * 100, "%"))print(classification_report(test_label, pre, target_names=iris.target_names))
# 其中列表左边的一列为分类的标签名,右边support列为每个标签的出现次数.avg / total行为各列的均值(support列为总和).
# precision recall f1-score三列分别为各个类别的 精确度/召回率 F1值. F1值是精确度和召回率的调和平均值:
'''
classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
'''# 交叉验证
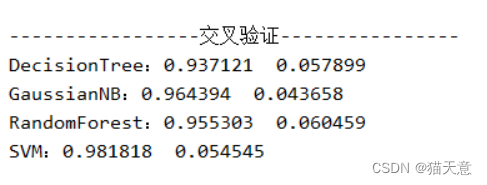
print("-----------------交叉验证----------------")
X_train, X_test, Y_train, Y_test = train_test_split(iris.data, iris.target)
names = []
scores = []
for name, model in models:cfit = model.fit(X_train, Y_train) # 训练cfit.score(X_test, Y_test) # 分数cv_scores = cross_val_score(model, X_train, Y_train, cv=10) # 分数scores.append(cv_scores) # 加入names.append(name) # 名称加入print("{}:{:.6f} {:.6f}".format(name, cv_scores.mean(), cv_scores.std()))# 算法比较
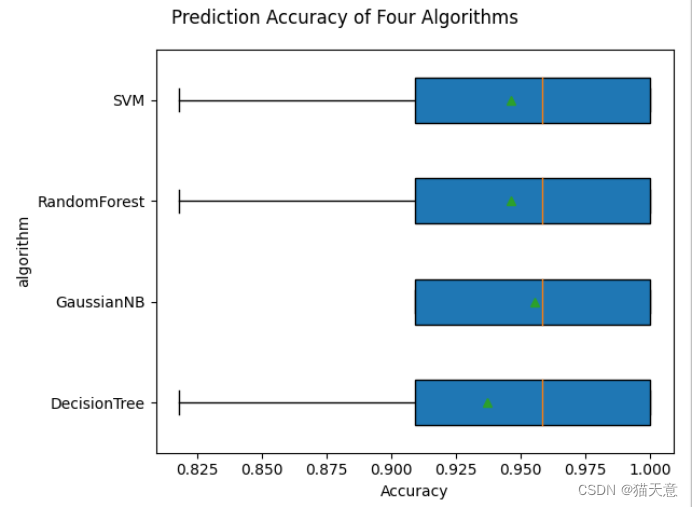
fig = plt.figure() # 创建画布
fig.suptitle('Prediction Accuracy of Four Algorithms') # 设置标题:四种算法准确率比较
ax = fig.add_subplot(1, 1, 1) # 新增子图或区域
# 比如221,指的就是将这块画布分为2×2,然后1对应的就是1号区
# 111 1 * 1 然后1对应的就是1号区
plt.ylabel('algorithm') # 算法
plt.xlabel('Accuracy') # 准确率
# patch_artist控制箱体图的填充,默认值为False, 此时箱体图的颜色指定的是表框的颜色,当取值为True时,color参数的值为箱体图的填充色,用法如下
plt.boxplot(scores, vert=False, patch_artist=True, meanline=False, showmeans=True)
# x :绘图数据。
# vert :是否需要将箱线图垂直放,默认垂直放。
# patch _ artist :是否填充箱体的颜色。
# meanline :是否用线的形式表示均值,默认用点表示。
# showmeans :是否显示均值,默认不显示。
ax.set_yticklabels(names)
plt.show()
实验截图:
决策树结构展示:
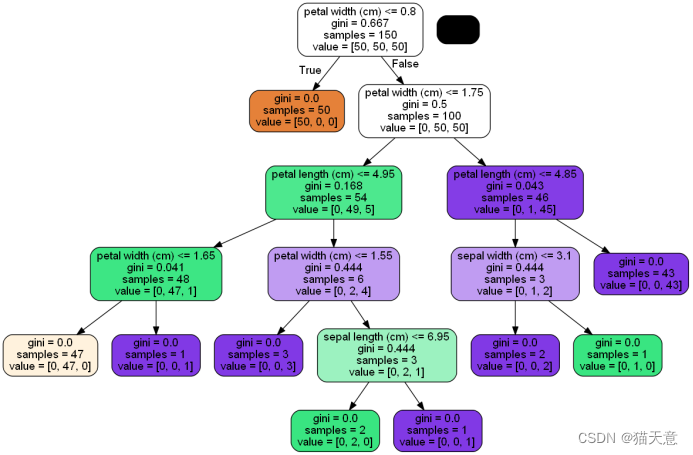
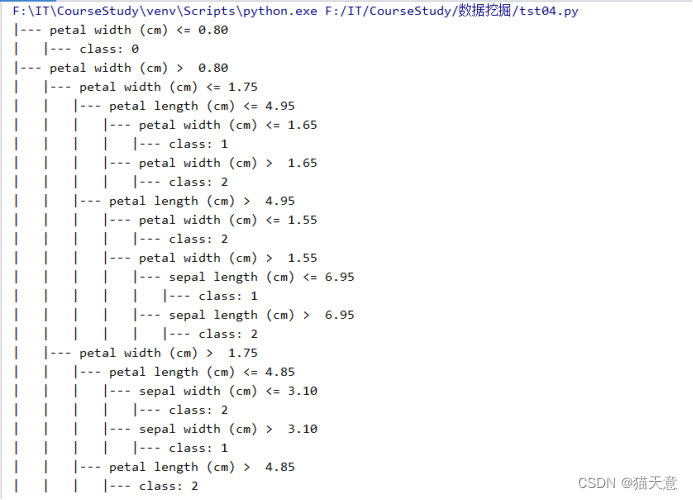
决策树分类器:
高斯分类器:
随机森林分类器:
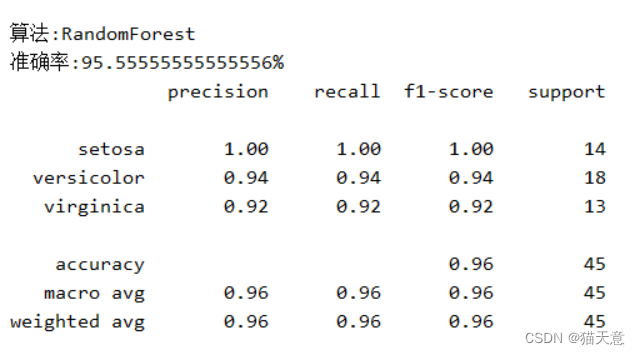
支持向量机分类器:
交叉验证:
预测图:
四、实验小结
总结:
- 通过本次实验加深了我对决策树原理的理解,本次实验使用了4种分类算法进行分类,习了决策树模型的构建过程,分类算法,预测方法,以及决策树的可视化、最后进行交叉验证。
- 本次实验中用到了sklearn库,以及pydotplus库、GraphViz的使用,GraphViz的使用需要下载exe文件安装到电脑中并配置相应的环境变量才可以正常使用。
- 此次实验是通过使用不同算法对鸢尾花数据集进行分类以及预测,对比不同算法的准确率可知,在多次试验后SVM算法的效果较好,鸢尾花数据集还需要多多研究和掌握。
- 这些算法的区别和特点需要清楚,还有背后的原理需要掌握,并且加以实验才能更好的掌握这些知识。