CCIG 2024:大模型技术及其前沿应用论坛深度解析
一、CCIG论坛介绍
中国图象图形大会(CCIG 2024)是一场备受瞩目的学术盛会,近期在陕西省西安市曲江国际会议中心举行。这次会议以“图聚智生,象合慧成”为主题,由中国图象图形学学会主办,旨在汇聚图像图形领域的专家学者和产业界同仁,共同探讨和展示最新的研究成果和未来发展趋势。
大会不仅邀请了众多知名学者和企业专家,还设置了25场学术论坛、7场特色论坛和2场企业论坛。

二、大模型技术及其前沿应用论坛
在众多论坛中,“大模型技术及其前沿应用论坛”尤为引人注目。
该论坛由CSIG文档图像分析与识别专业委员会组织,聚焦于大模型技术的最新进展及其在不同领域的前沿应用。
论坛邀请了学术界和产业界的领军人物,共同探讨大模型技术如何推动计算机视觉、自然语言处理、基础科学研究及行业应用的跨界融合与技术发展。

其中,合合信息智能创新事业部研发总监常扬发表了主题演讲,介绍了合合信息在智能文档处理及大数据领域的最新进展和应用,另外,常扬详细介绍了合合信息的TextIn文档解析技术,包括其在大模型训练和应用中的关键作用。
他指出,随着大模型的不断发展,文档解析技术需要不断提升,以满足大规模数据处理和高质量数据获取的需求。同时,他还展示了合合信息在文档解析技术上的最新研究成果和应用案例。
2.1 智能文档解析技术及其在大模型训练与应用中的作用
在人工智能和大数据时代,文档解析技术的重要性日益凸显。特别是对于大模型(如GPT-4和LLAMA2)的训练和应用,准确高效的文档解析至关重要。
合合信息的TextIn智能文档解析技术通过先进的图像处理和自然语言处理算法,显著提升了文档解析的精度和效率,为大模型的训练和应用提供了强有力的支持。
2.2 文档解析技术的背景和挑战

大模型训练面临的挑战
在大模型训练过程中,高质量的训练数据是至关重要的。然而,随着模型规模的不断扩大,训练所需的Token数也急剧增加。
例如,LLAMA2需要2万亿Token,而GPT-4更是高达13万亿Token。面对如此巨大的数据需求,高质量预训练数据的获取成为一个瓶颈。

文档解析的需求
为了满足大模型的训练需求,必须高效获取更多高质量的文档数据,这就要求文档解析技术不仅能够准确识别文档中的各种元素(如表格、段落、公式、标题等),还要能够处理复杂的版面布局(如双栏、三栏、文表混合等)。
此外,对于大模型应用场景,文档解析还需保证快速准确的转换速度,以还原文档的阅读顺序,避免混乱语序。

2.3文档解析解决方案
在应对文档解析过程中遇到的多重技术挑战,包括元素间的遮盖重叠、复杂版式(如双栏、跨页、三栏等)的高效处理,以及无线表格和合并单元格的精准识别等难题时,合合信息公司推出了TextIn文档解析技术。该技术对多文档元素的精准识别、版面布局的深入分析以及高性能算法的运用,成功攻克了上述技术难点。
三、TextIn智能文档解析技术
TextIn文档解析技术的核心在于其能够处理各种格式和版式的文档,包括书籍、教材、论文和企业文档等。
这项技术通过以下几个关键步骤实现高效的文档处理:

3.1核心技术和算法
TextIn文档解析技术采用了一系列先进的算法框架,包括图像预处理、版面分析和文档解析等。
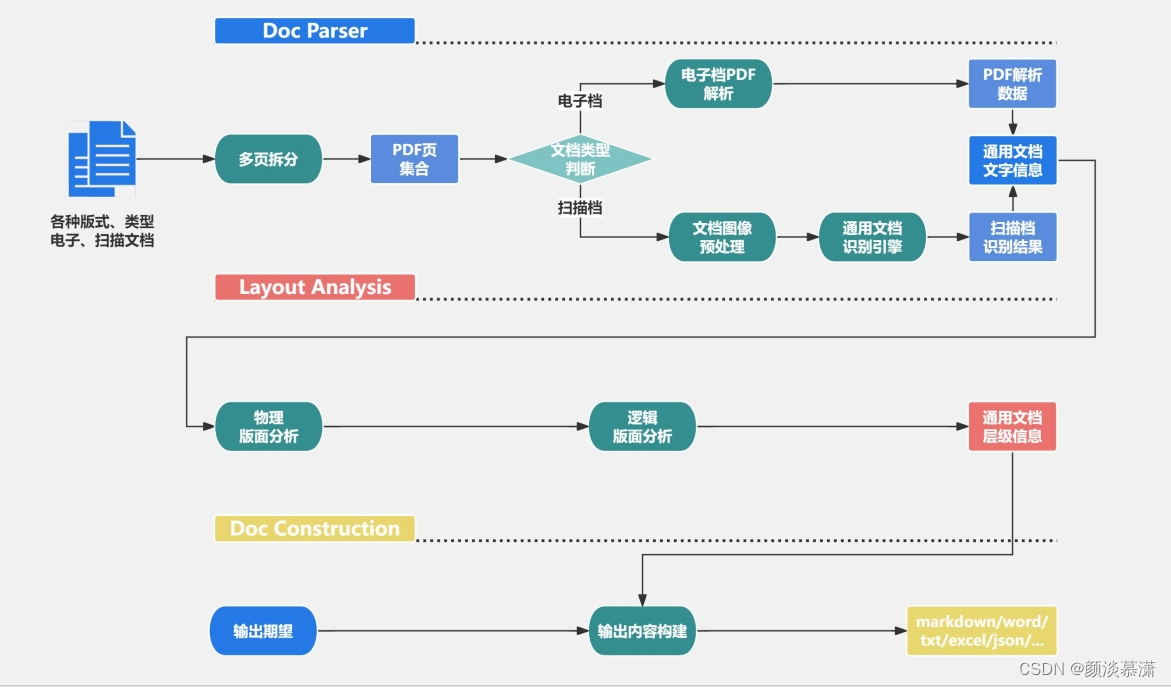
图像预处理算法介绍
图像预处理是图像处理过程中至关重要的一步,其目的是对原始图像进行必要的处理,以使其更适合后续的分析和处理。在文档解析中,图像预处理算法主要用于增强文档图像的质量,以提高后续的OCR识别准确率。
常用的图像预处理算法包括:
- 图像去噪
- 图像增强
- 图像矫正
- 图像分割
另外,在文档解析中,图像增强算法包括:
- 锐化:用于增强图像的边缘和细节,以使其更易于识别。常用的锐化算法包括拉普拉斯算子、Sobel算子等。
- 区域提取:用于提取文档图像中的感兴趣区域,如文本区域、表格区域等。常用的区域提取算法包括阈值分割、边缘检测等。
- 干扰去除:用于去除文档图像中的干扰信息,如手指、印章、阴影等。常用的干扰去除算法包括形态学滤波、区域滤波等。
图像增强:
通过增强锐化、区域提取和干扰去除(如手指去除、形变矫正、阴影去除、摩尔纹去除等)来提升文档图像的质量。
其算法框架如图所示

形变矫正:
- 用于矫正图像的几何畸变,如倾斜、拉伸等。常用的图像矫正算法包括仿射变换、透视变换等。
- 使用DocUNet形变矫正网络和边缘填充结果,实现文档图像的形变矫正和图像恢复。

干扰去除是用的U2net卷积背景提取+干扰去除模块去除摩尔纹等,最终达到去除干扰的效果
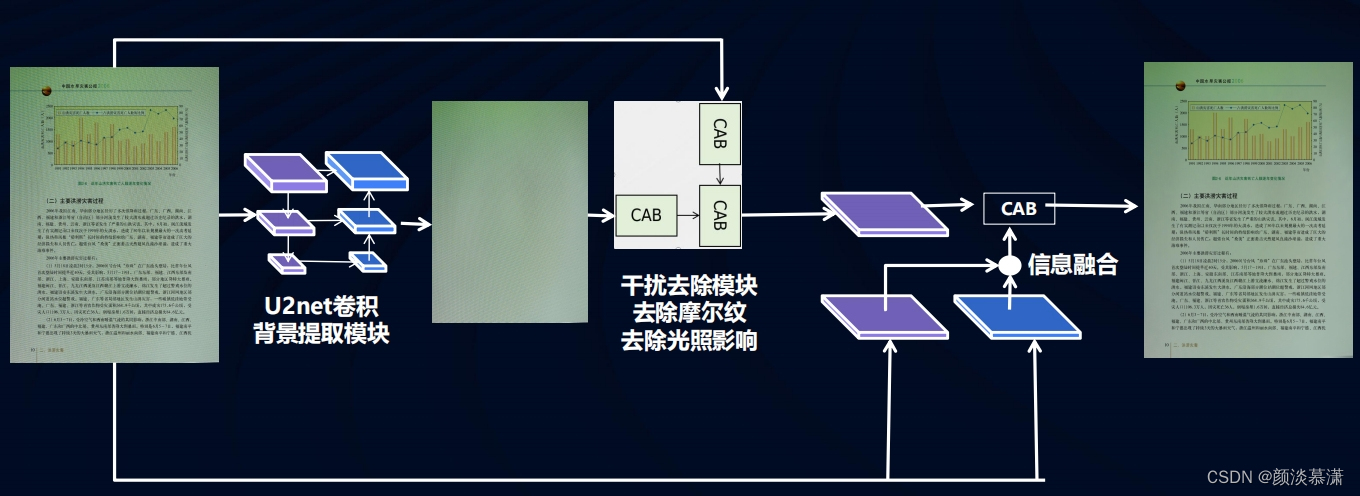
算法效果:

版面分析算法介绍
版面分析是文档解析的关键步骤之一,其目的是识别文档中的不同元素,如文本块、表格、图片、印章等,并分析这些元素之间的关系。版面分析算法主要包括以下三个方面:
- 物理版面分析
- 文档布局分析
- 逻辑版面分析
物理版面分析:
物理版面分析侧重于文档图像的视觉特征,主要任务是将相关性高的文字聚合到一个区域,如段落或表格。常用的物理版面分析算法包括:
- 基于连通性分析的算法:该类算法通过分析文本区域之间的连通性来识别文本块。例如,可以使用标记连接算法、区域生长算法等来识别文本块。
- 基于空间关系分析的算法:该类算法通过分析文本区域之间的空间关系来识别文本块。例如,可以使用基于欧几里得距离的算法、基于方向关系的算法等来识别文本块。
- 基于字体特征分析的算法:该类算法通过分析文本区域的字体特征来识别文本块。例如,可以使用基于字体大小的算法、基于字体样式的算法等来识别文本块。
其主要任务是将相关性高的文字聚合到一个区域,如段落或表格。

文档布局分析:
文档布局分析是物理版面分析的进一步扩展,其目的是识别文档的整体布局结构,包括文本块、表格、图片、印章等元素的排列方式。
具体采用的是目标检测任务建模,使用基于回归的单阶段检测模型,识别文档中的各种布局方式。
下面详细介绍一下:
1. 目标检测任务建模
目标检测任务建模是将文档布局分析转换为目标检测任务的过程。在文档布局分析中,目标可以是文本块、表格、图片、印章等文档元素。目标检测任务的目标是识别文档图像中的所有目标,并确定每个目标的位置和类别。
常用的目标检测任务建模方法包括:
- 基于区域建议的双阶段检测模型:该类模型首先生成候选区域,然后对候选区域进行分类和回归。代表性的模型包括R-CNN、Fast R-CNN、Faster R-CNN等。
- 基于回归的单阶段检测模型:该类模型直接在图像上预测目标的位置和类别。代表性的模型包括YOLO系列、SSD系列、RetinaNet等。
- 在文档布局分析中,由于文档图像中的目标通常具有规则的形状和大小,因此基于回归的单阶段检测模型通常能够获得更高的效率和精度。
基于回归的单阶段检测模型
- 基于回归的单阶段检测模型通常由以下几个部分组成:
- 特征提取器:用于提取图像的特征。常用的特征提取器包括卷积神经网络(CNN)、池化层等。
- 预测器:用于预测目标的位置和类别。常用的预测器包括全连接层、回归层等。
- 损失函数:用于衡量模型的预测结果与真实结果之间的差距。常用的损失函数包括IOU损失、Smooth L1损失等。
在文档布局分析中,常用的基于回归的单阶段检测模型包括:
- YOLO:YOLO(You Only Look Once)是一种实时的目标检测模型,其特点是速度快、精度高。YOLOv5是YOLO系列的最新版本,其性能得到了进一步提升。
- SSD:SSD(Single Shot MultiBox Detector)是一种基于VGG16网络的单阶段检测模型,其特点是易于实现、精度高。
- RetinaNet:RetinaNet是一种基于特征金字塔的单阶段检测模型,其特点是精度高、鲁棒性强。
3. 识别文档中的各种布局方式
有效地识别文档中的各种布局方式,包括:
- 单栏文本:文档中的文本从左到右排列,没有明显的段落划分。
- 多栏文本:文档中的文本分为多个栏,每栏文本从上到下排列。
- 表格:文档中的表格由行和列组成,每个单元格包含一个或多个文本。
- 图片:文档中插入的图片。
- 印章:文档中盖印的印章。
通过识别文档中的各种布局方式,可以为后续的文档理解和处理奠定基础。
以下是一些采用目标检测任务建模,使用基于回归的单阶段检测模型,识别文档中的各种布局方式的应用案例:
- 文档自动整理:可以根据文档的布局方式,自动将文档中的文本、表格、图片等元素进行整理。
- 文档信息抽取:可以根据文档的布局方式,自动抽取文档中的关键信息,如姓名、日期、金额等。
- 文档问答:可以根据文档的布局方式,自动理解文档的内容,并回答用户的提问。
可以说,采用目标检测任务建模,使用基于回归的单阶段检测模型,是一种高效、准确的文档布局分析方法,下面是一个实例说明。
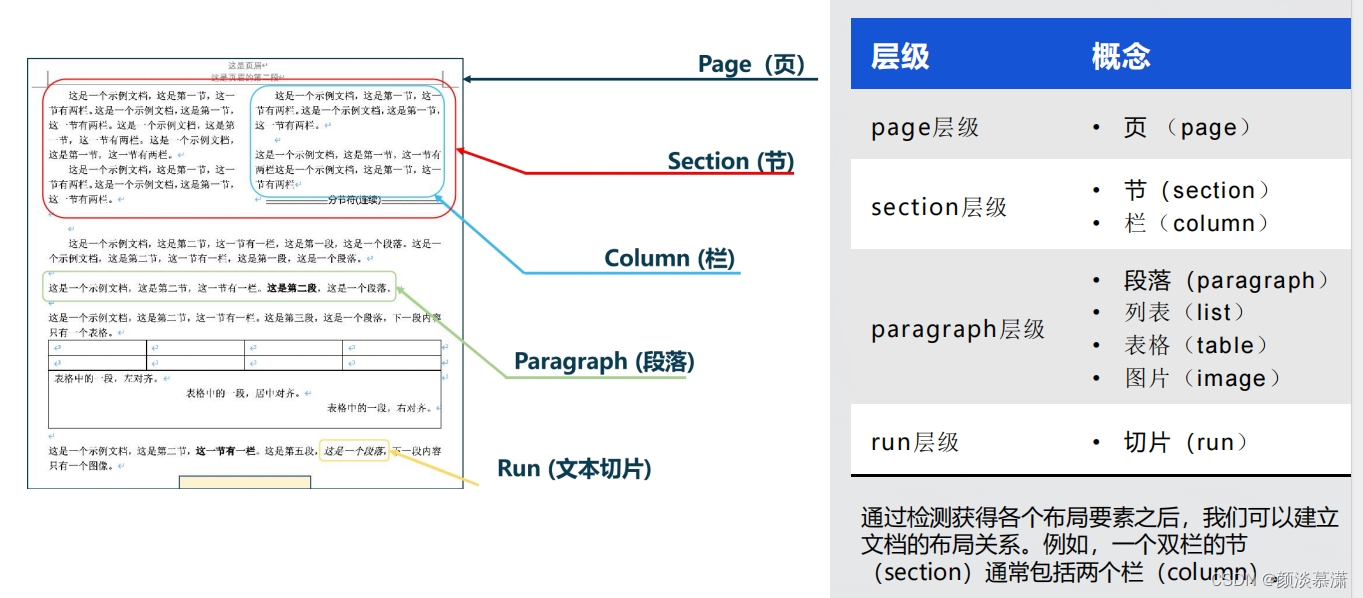
逻辑版面分析:
逻辑版面分析侧重于文档的语义信息,主要任务是理解文档的结构和内容。常用的逻辑版面分析算法包括:
- 基于规则的算法:该类算法通过定义预先设定的规则来识别文档的结构和内容。例如,可以使用基于文本格式的规则、基于文本内容的规则等来识别文档的结构和内容。
- 基于机器学习的算法:该类算法利用机器学习技术来训练模型,以识别文档的结构和内容。例如,可以使用支持向量机、条件随机场等机器学习算法来识别文档的结构和内容。
它主要侧重于语义特征,主要任务是根据语义将不同文字块建模,通过语义层次关系形成树状结构。
3.2 文档解析结果
解析示例-解析pdf
可以看到,针对PDF的解析结果,这个解析结果是很不错的。
解析示例-复杂表格解析
解析复杂表格,也是没问题的。

3.3成果与影响
TextIn文档解析技术的应用已经在行业里产生了重要影响。其母公司合合信息的C端产品在App Store上的商务类和效率类免费应用下载量排行榜中位列第一。

此外,Textin还提供了每周7000页的免费额度,以及公有云API,鼓励开发者和用户使用TextIn文档解析技术。
3.4应用场景
大模型训练
在大模型训练场景中,TextIn文档解析技术可高效获取更多高质量的训练语料,特别是对于上百页PDF文档的快速转换和正确还原阅读顺序,极大地提升了训练数据的质量和数量。
大模型应用
在大模型应用场景中,TextIn文档解析技术可确保文档元素识别的高精准度和高效率,为文档问答、知识库问答等应用提供强有力的支持。
通过准确解析文档中的各种元素和版面布局,提升了大模型在文档问答中的精度和效率。

四、结论
TextIn文档解析技术的成功不仅体现在其高效的文档处理能力上,更在于其对大模型训练与应用的深远影响。
随着技术的不断进步和应用的深入,TextIn文档解析技术有望在未来的人工智能领域发挥更大的作用,推动整个行业的发展。
合合信息的这一创新突破,无疑为大模型训练与应用提供了强有力的支持,为人工智能的未来开辟了新的可能性。