LLM的基础模型8:深入注意力机制

大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。

自注意力
Self-Attention
自注意力的主要功能是从输入序列本身生成上下文感知向量,而不是像基于RNN的编码器-解码器架构那样同时考虑输入和输出。在继续往下之前,还是需要帮助大家温习下之前的内容,也请各位能够认真的理解自注意力。

在例句中,“火车准时离开车站”中有 7 个Tokens,可以得到一个 7x7 的自注意力得分矩阵。根据图中描绘的自注意力得分,“火车”一词更关注“车站”一词,而不是关注其他单词。自注意力分数有助于理解给定句子中单词的上下文含义。例如,这里的“车站”一词用于火车站的上下文,而不是用于其他上下文,如加油站或公共汽车站等。
自注意力分数是通过余弦相似度计算的,即两个词向量的点积。它用于评估两个词向量之间的关系强度或比较词向量之间的相似程度。

这些自注意力分数最后会被按照权重进行加权累加,最终输出一个向量可以理解为已经将上下文进行编码。例如,当前词为“站”这个词时,与“站”密切相关的词对总和的贡献更大(包括“站”这个词本身),而不相关的词几乎不会贡献任何词。由此产生的向量作为“站”一词的新表示,并结合了周围的上下文。在理解这句话的时候,火车站的上下文信息就被编码到最后的输出。


多头注意力
Multi-Head Attention
在Transformer中,大量的使用了多头注意力的模块,它的原理和自注意力差不多。下面来解释下这个模块和自注意力机制的关系。
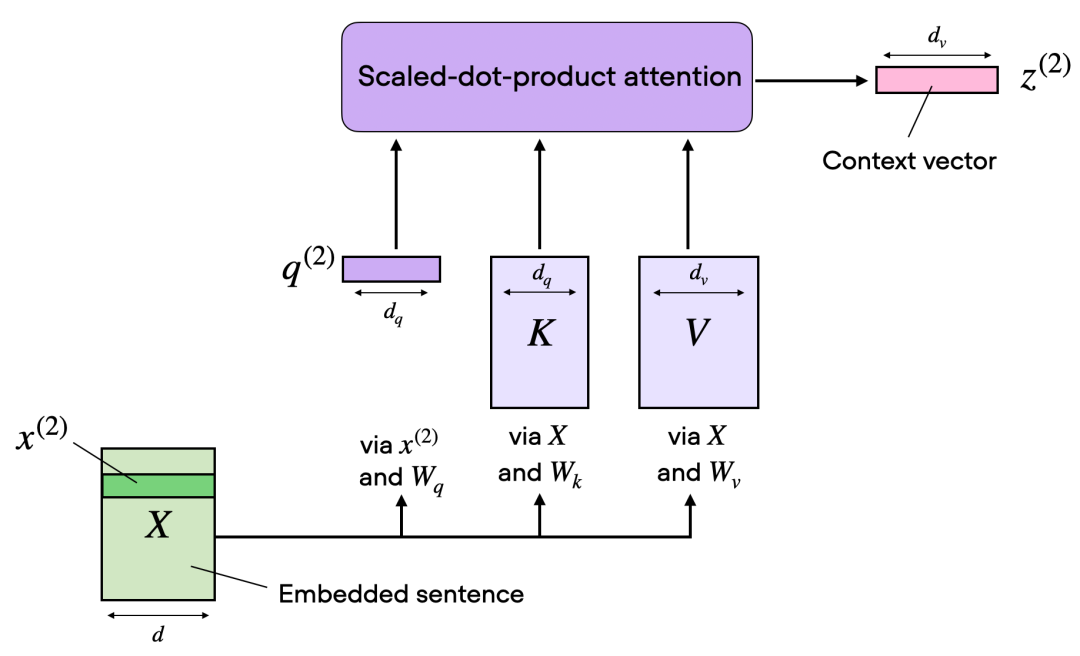
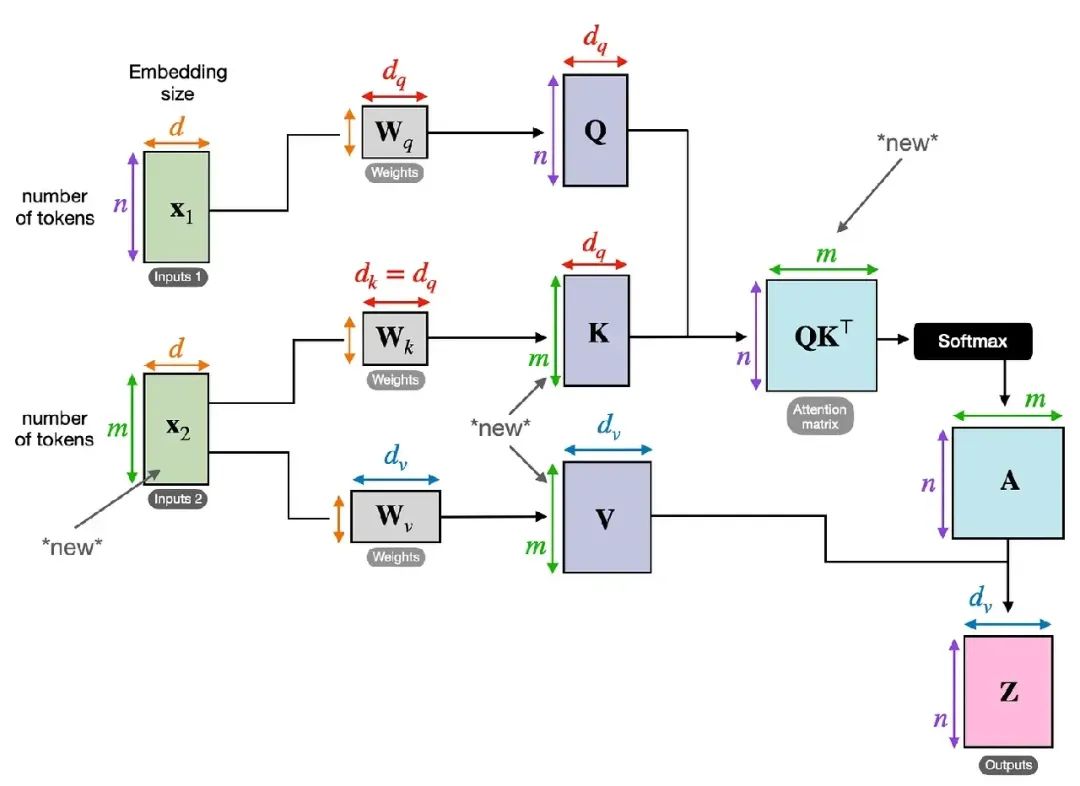
在刚才提到的点积注意力中,如下图所示,输入序列通过代表查询Q、键K和值V的三个矩阵进行转换然后计算自注意力。其中绿色x(2)为一个Embedding向量。
而在多头注意力的背景下,某种意义三个矩阵可以被看作是一个单独的注意力头。增加单个自注意力头的输出维度和使用多个注意力头之间的区别在于模型如何处理数据并从中学习。虽然这两种方法都增加了模型表示数据不同特征或方面的能力,但它们的方式基本不同。
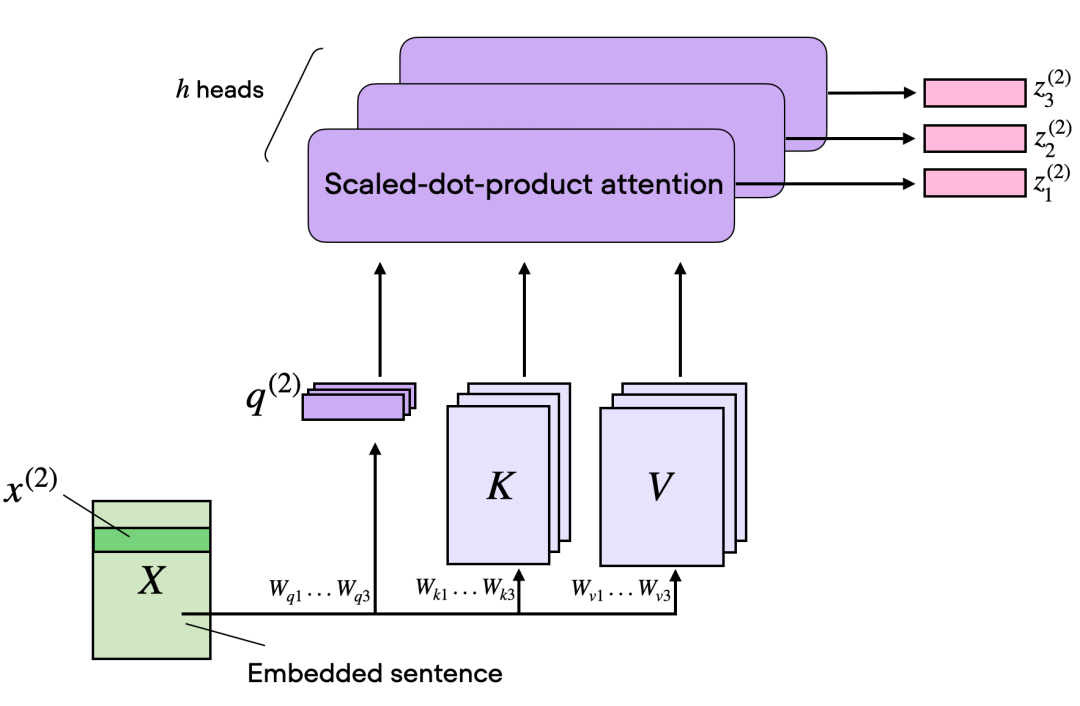
上面这张图想表达的是一个输入的Embedding可以和多套的QKV协同运算。论文上描述的是多个W变换到子空间,但是实现上一般采用分段的方式。大白话说是将Embedding的长度切分为n段分别做运算。比如原来Embedding是512维,假定32头,那么Embedding 会被切分成512/32=16维,相当于多个子空间。
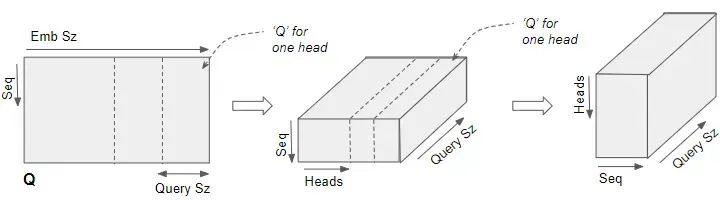
例如,多头注意力机制中的每个注意力头理论上可以学习集中在输入序列的不同部分,捕捉数据中的各种方面或关系。这种多样性是多头注意力成功的关键,毕竟每一个Embedding基本上都是高维度,通过多头分别捕获数据在各个层面的依赖和关系。
例如有的头专门捕获感情因子,有的头专门捕获地域特征,有的头专门捕获人物关系等等……
多头注意力也可以更高效,特别是在并行计算方面。每个头部可以独立处理,使其非常适合现代硬件加速器,如擅长并行处理的 GPU 或 TPU。简而言之,使用多个注意力头不仅仅是为了增加模型的容量,而是为了增强其学习数据中多样特征和关系的能力。

交叉注意力
Cross-Attention
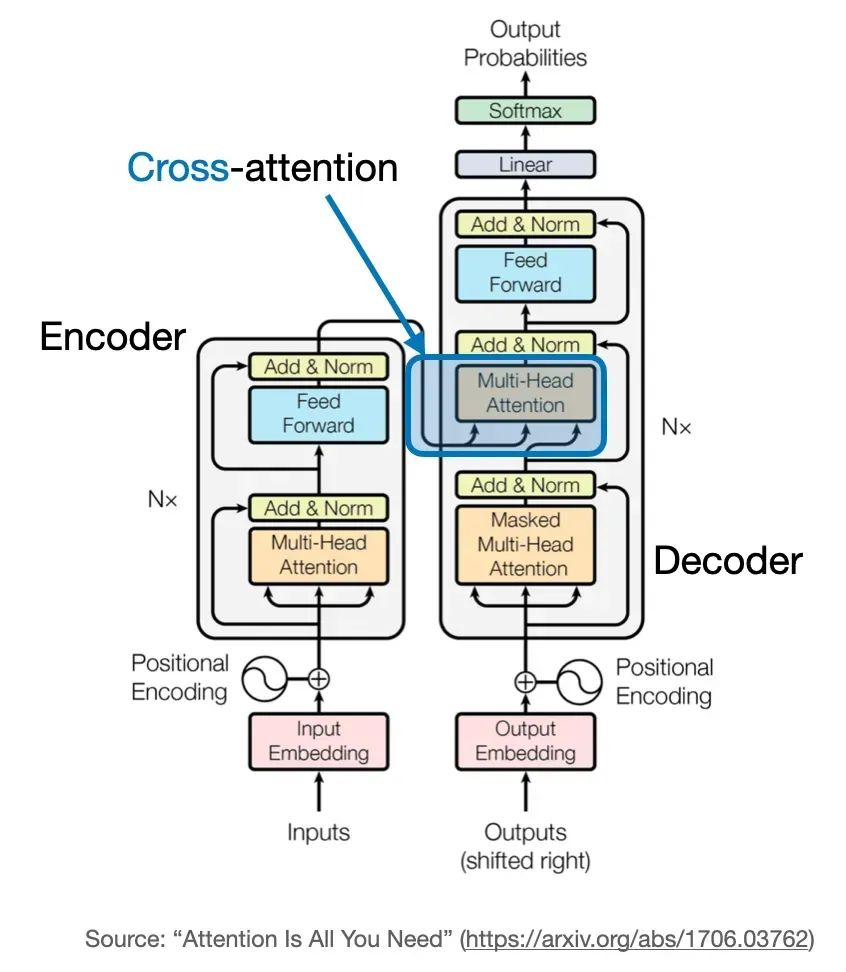
除输入部分外,交叉注意力计算与自注意力相同。交叉注意力说白了就是Q来至一个序列,而KV来至另一个序列。这些序列都是相同维度的嵌入序列。相比之下,自注意力输入是单个嵌入序列。而交叉注意力则是其中一个序列用作Q输入,而另一个序列用作K和V输入。
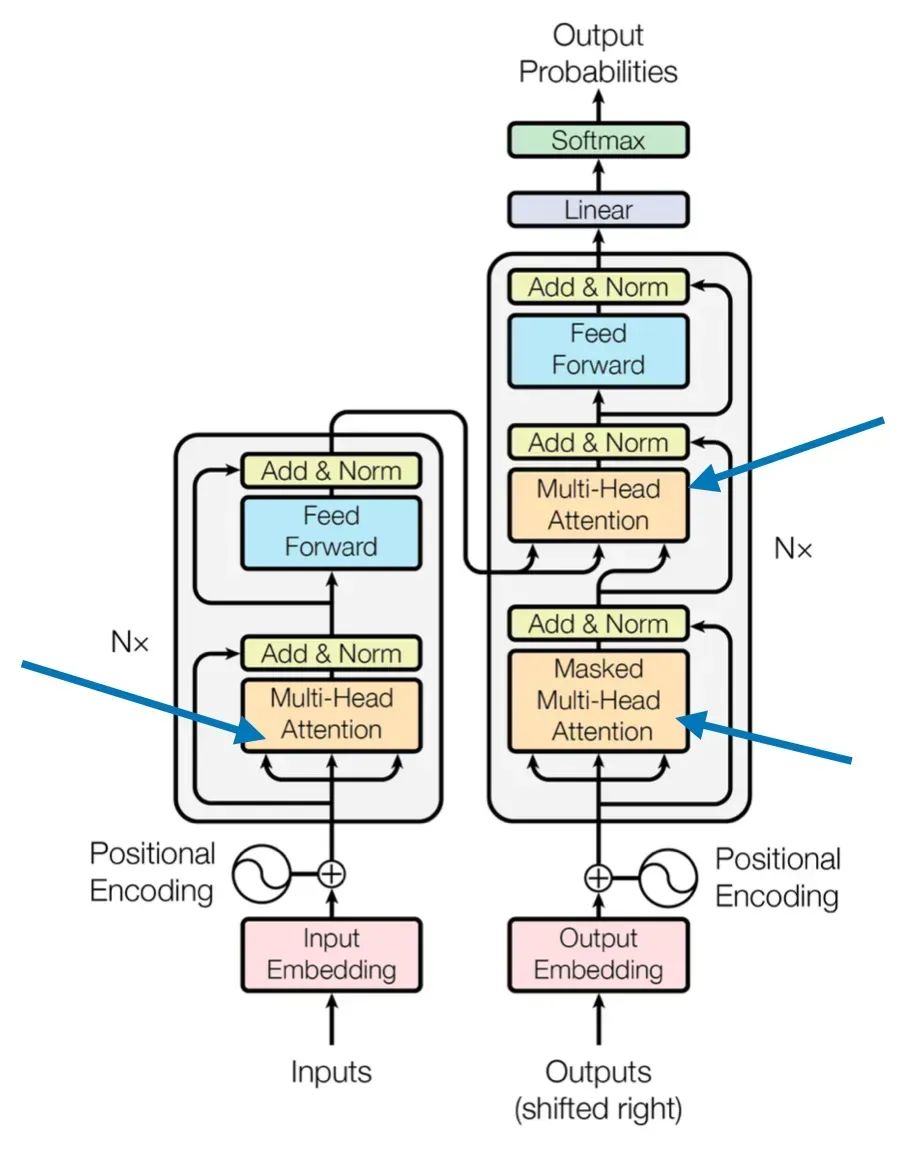
读者可以仔细观察上图,在传统的Transformer的架构中,自注意力机制一般在Encoder(下图左),而交叉注意力机制一般在Decoder(下图右)。
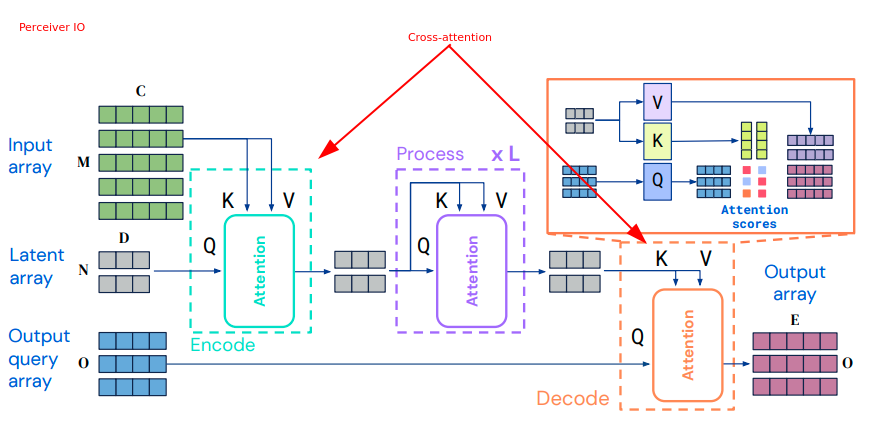
其实也很好理解,对大模型的提问输入在Encoder中经过自注意力抽取出查询的上下文信息,然后输入为K和V供给给Decoder,而Decoder一方面不断地工作产生新的Token,一方面不断地将已经输出的序列嵌入输出Q,再次和Encoder的K和V做交叉注意力,供后续的组件吐出下个Token的概率分布。

因果注意力
Causal-Attention
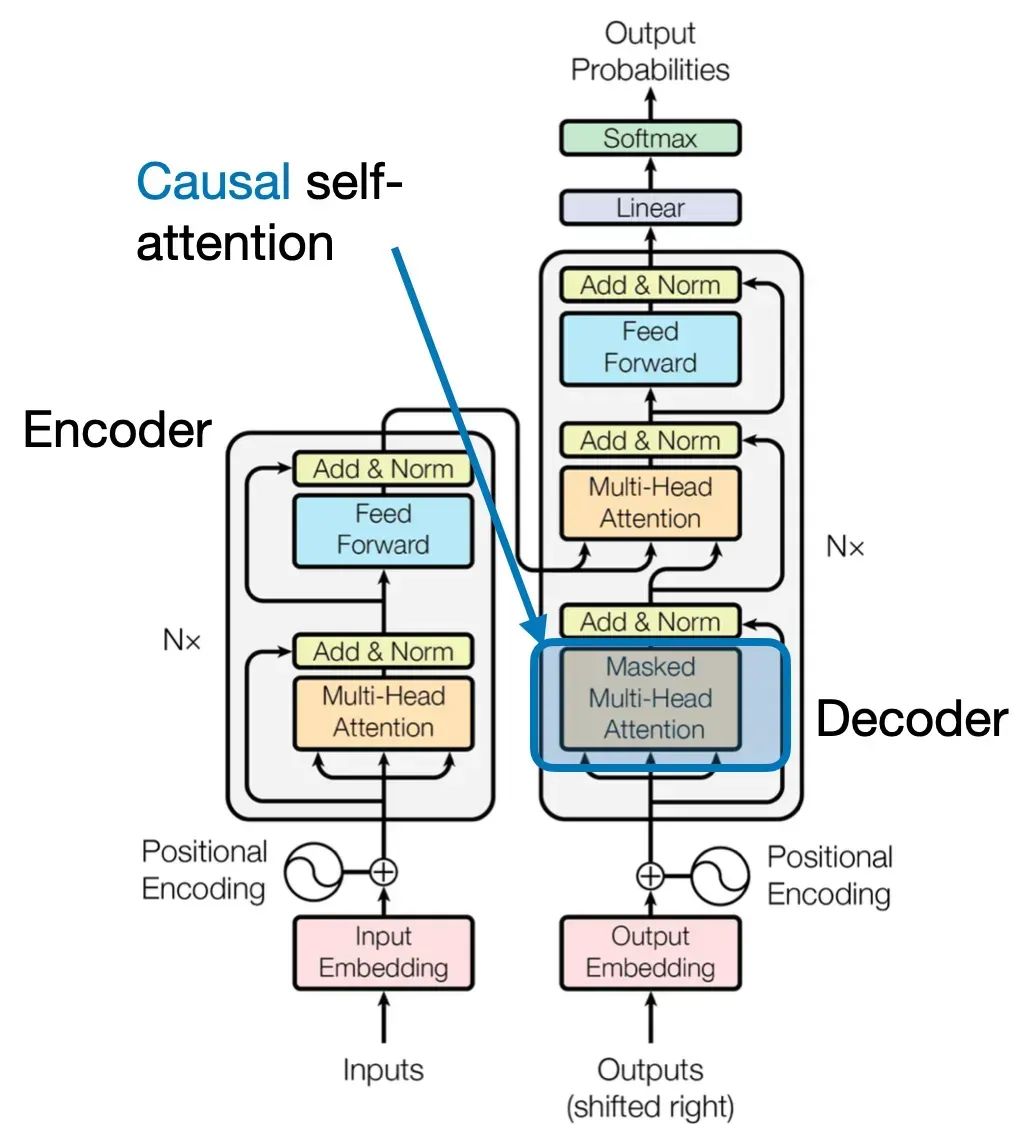
因果自注意的起源来至序列中某个位置的输出仅仅依赖于先前位置的已知输出,而不是基于未来位置。比如说Decoder,它是按照顺序产生Token,先产生的Token肯定无法依赖后产生的Token。因此对于处理的每个Token,因果注意力机制屏蔽了未来的Token。所谓的未来,就是在当前Token之后的尚未生成的Tokens。因此原来的自注意力矩阵则成为上三角矩阵,因为有一半是不需要计算的。
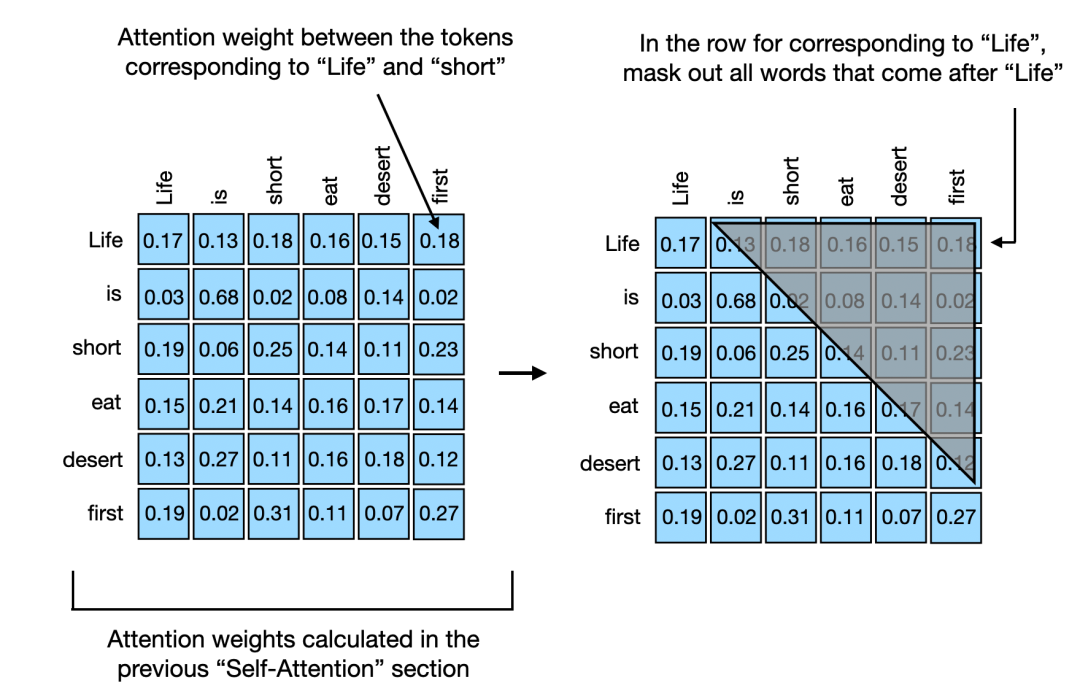
例如life生成的时候只需要计算和自己,当生成到life is的时候,则只需要计算is和life,is和自己,如此类推……
值得一提的是,每次生成的注意力矩阵每一行都需要归一化。这里有个小小的技巧,可以将尚未生成的Token标记为-∞,然后在由softmax进行归一化。

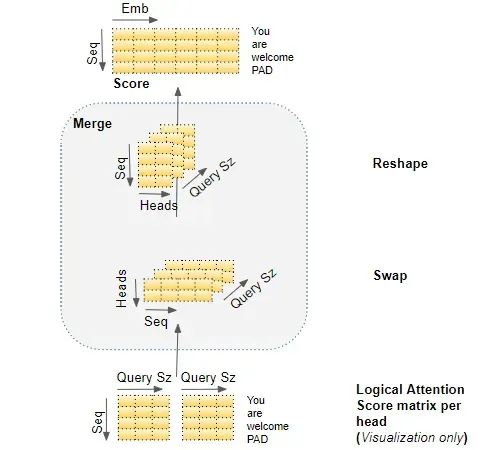
附录:多头注意力的变换过程
全景图
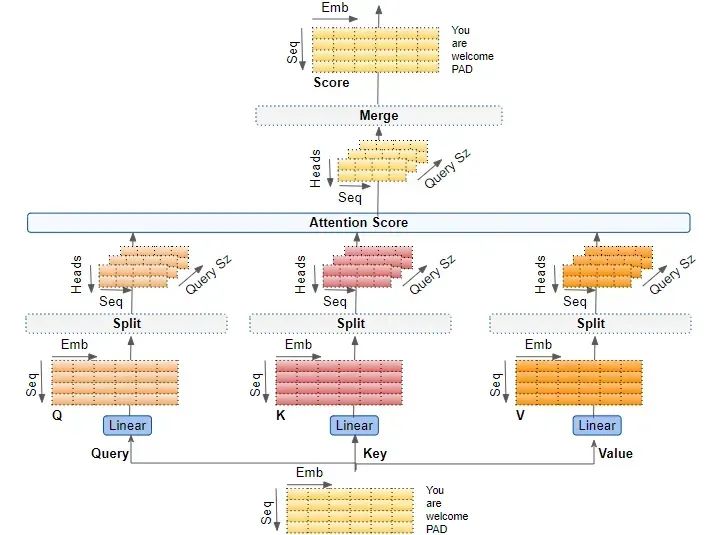
推导步骤1:
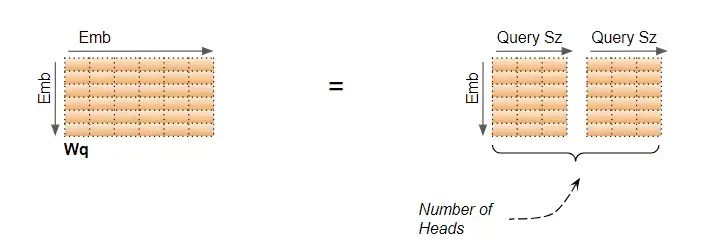
推导步骤2:
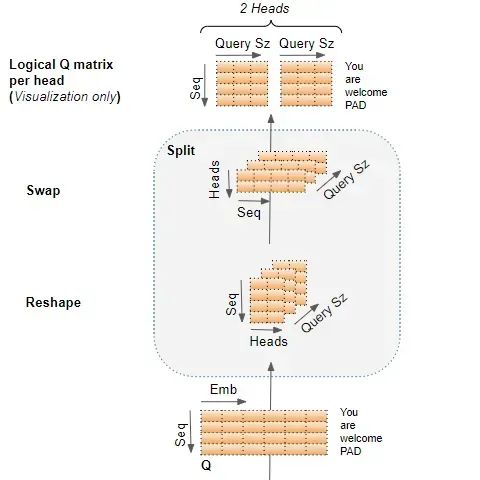
推导步骤3:
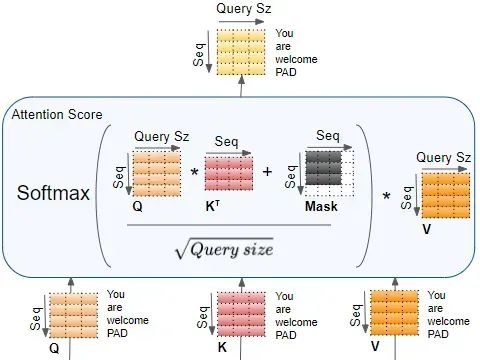
推导步骤4: