在Modelarts上微调量化Llama3,并用docker部署
本文概述
本文先使用llama-factory去微调llama3大模型,然后使用llama.cpp去量化模型并打包为docker部署到服务器上让qq机器人能够调用服务,实现qq群内问答。
效果展示

环境准备
本文使用华为云的Modelarts的notebook去进行的模型微调
ubuntu20.04,cuda:11.7,pytorch:2.0.0,gpu:v100 32G
一、配置自定义镜像
华为云默认的镜像非常垃圾,请自行前往AI Gallery里面获取自定义镜像
链接:AI Gallery_算法_开发者_华为云

推荐使用这个,然后点击进入详情页
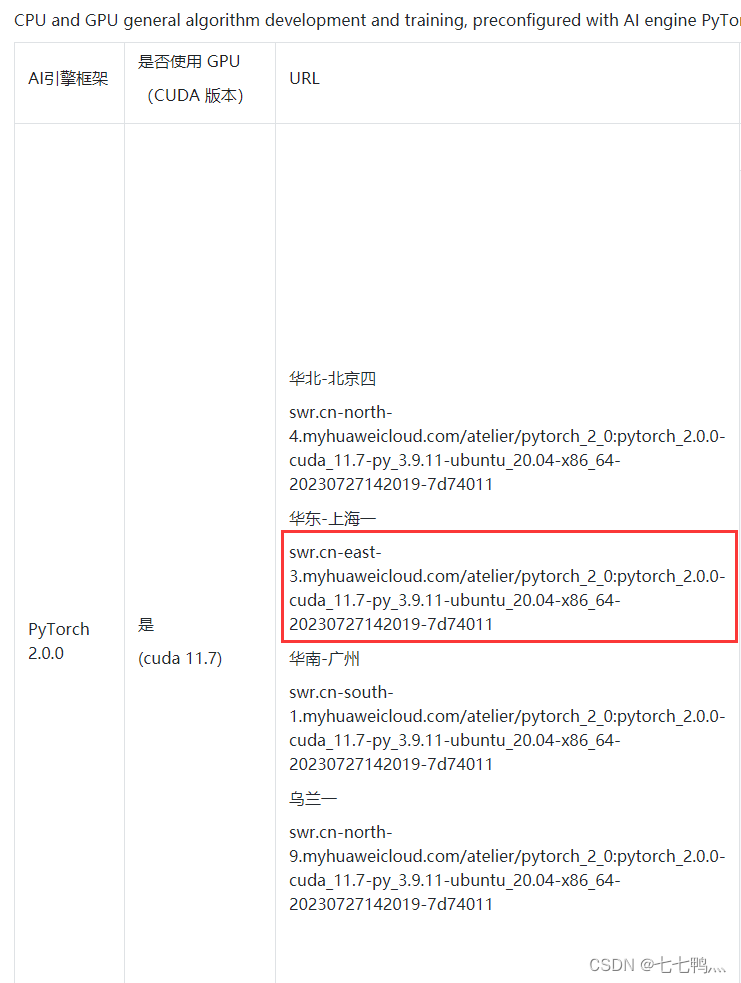
复制与你modelarts相同区域的url

然后在modelarts控制台的镜像管理这里去点击注册镜像

粘贴刚才复制的url,然后把这两个类型都勾选上,自定义镜像就创建完成
二、创建notebook
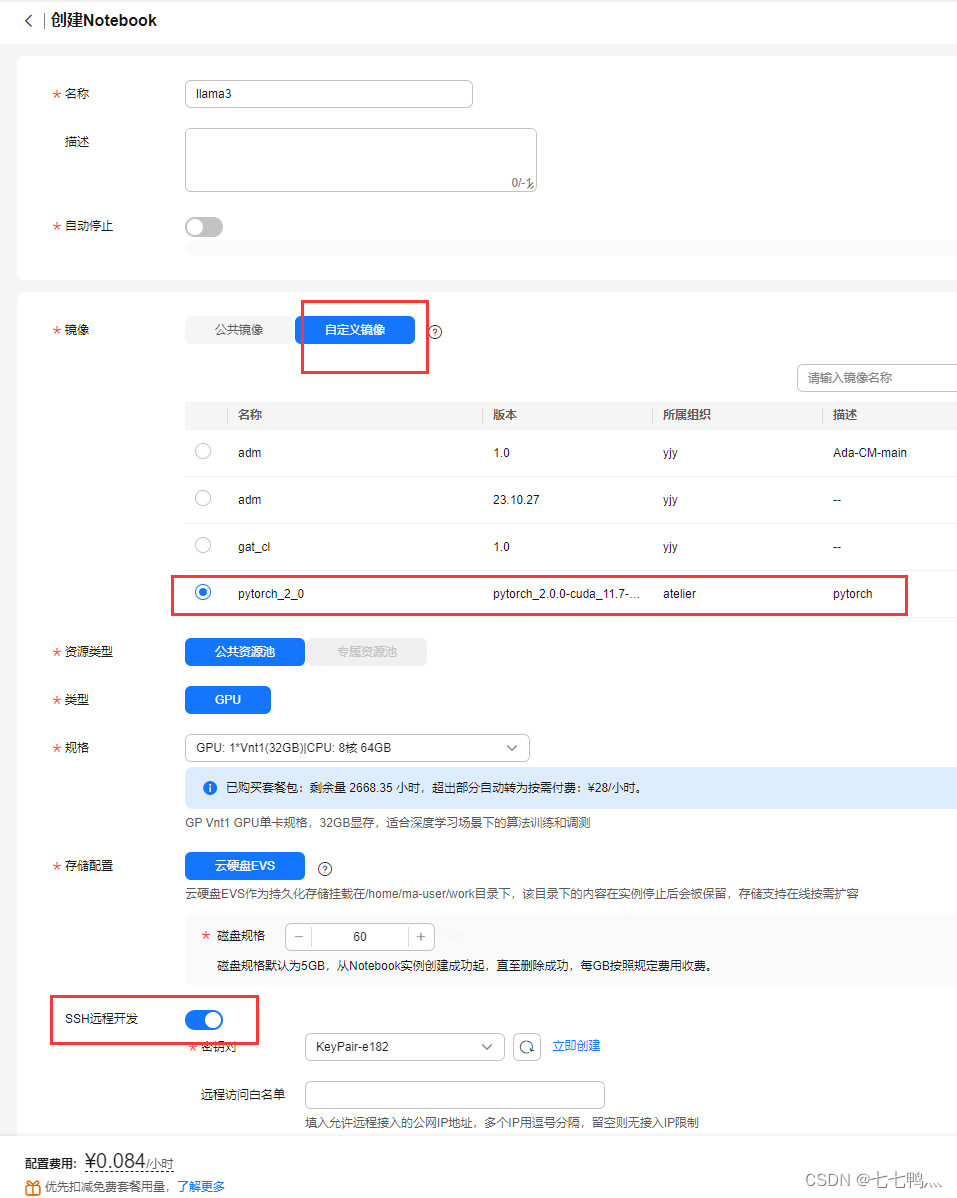
按照上图去进行配置,注意的是我们要开启这个ssh远程开发,因为使用modelarts自带的非常难用。

然后进入notebook详情页,在地址哪里第一个框就是服务器的用户名,第二个框是主机地址
三、使用Xshell和Xftp连接服务器

将主机地址和端口号填好,然后点击确认
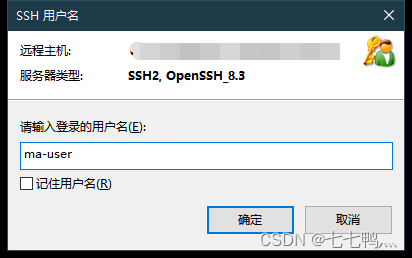
然后输入用户名

选择public,然后点击浏览并选择用户密钥

然后点击导入,导入你刚才在华为云哪里配置的密钥对文件(后缀为.pem)

然后选择用户密钥之后,点击确认
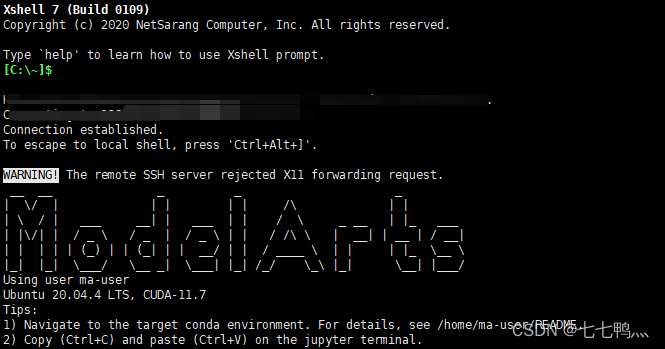
然后就连接成果了,Xtfp也是这样操作,具体就不演示了。
四、安装llama-factory
执行下面指令,即可完成安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
五、下载llama3-8b-chinese-chat
因为llama3-8b基本上是没有任何中文能力的,所以我们需要在别人训练好的中文模型的基础上进行微调,如果你的任务是英文的那么直接下载原版的就好了。
因为hugging face上下载速度堪忧,我这里直接上传到百度网盘上供大家下载。
链接:https://pan.baidu.com/s/1ETy7Q90IPdJbVLOXjVFGeA?pwd=6rw7
提取码:6rw7
--来自百度网盘超级会员V5的分享
六、准备好微调数据集

这个数据集是我自己采集数据构建的特定任务数据集,大概有1200多组数据,共80多W字。
七、修改dataset_info.json


然后按照这个结构去增加你新添加的数据集信息
八、使用factory webui界面去可视化微调llama3
先将之前下载的中文模型通过xftp上传到服务器,将修改后的datasets_info.json覆盖原来服务器上的
然后执行下面这行代码
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui

然后点击属性
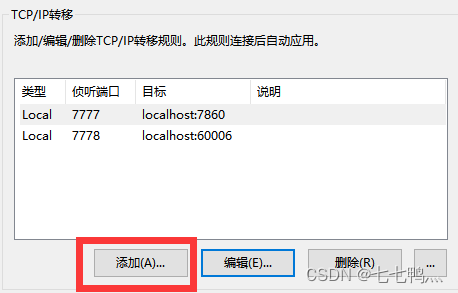
点击添加按钮

将目标端口改为factory web服务的端口,然后点击确定。
然后在浏览器上输入127.0.0.1:7777就可以打开factory webui页面

然后调整参数进行训练即可,具体调参和训练过程这里就不演示了
九、合并lora模型
在LLaMA-Factory的examples/merge_lora文件夹下,编辑llama3_lora_sft.yaml文件

其中model_name_or_path是预训练大模型的路径,adapter_name_or_path是我们微调好的lora的路径。export_device默认为cpu,如果你需要使用gpu去进行推理的话就改为gpu
保存之后我们执行下面这行命令,完成lora和预训练模型的合并
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml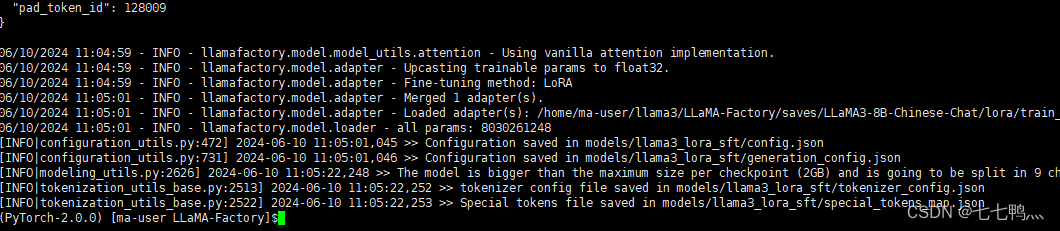
十、安装llama.cpp
$ git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp注意,编译的话有两种
第一种是使用cpu去推理
make第二种是使用gpu去推理
make LLAMA_CUDA=1根据你的需求去选择编译类型,然后等待编译完成,便完成了llama.cpp的安装
十一、将hugging face格式的模型转换为gguf格式的模型
在llama.cpp根目录下执行下面这个命令,后面的路径是要转化格式的模型路径
python convert-hf-to-gguf.py /home/ma-user/llama3/LLaMA-Factory/models/llama3_lora_sft

转换好的后得到一个gguf格式的模型权重文件
十二、将模型量化为4bit,加快推理速度
./quantize /home/ma-user/llama3/LLaMA-Factory/models/llama3_lora_sft/ggml-model-f16.gguf /home/ma-user/llama3/LLaMA-Factory/models/llama3_lora_sft/ggml-model-q4.0.gguf q4_0第一个路径是原来精度的gguf模型路径,第二个路径是量化后模型的保存路径,q4_0这个参数的意思是将模型量化为4bit
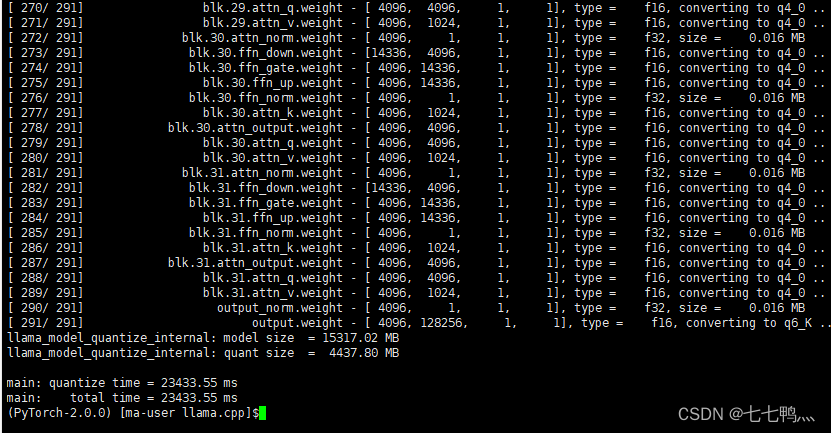
至此就完成了模型的量化
十三、测试模型
./server -m /home/ma-user/llama3/LLaMA-Factory/models/llama3_lora_sft/ggml-model-q4.0.gguf -c 4096 -b 64 -n 1024 -t 9999 --repeat_penalty 1.2 --top_k 20 --top_p 0.5 --color -i --main-gpu 0 --n_gpu_layers 33 --port 60006 -ngl 41
使用这行命令启动llama.cpp的可视化界面

端口这样设置

然后我们在浏览器上输入127.0.0.1:7778打开可视化界面
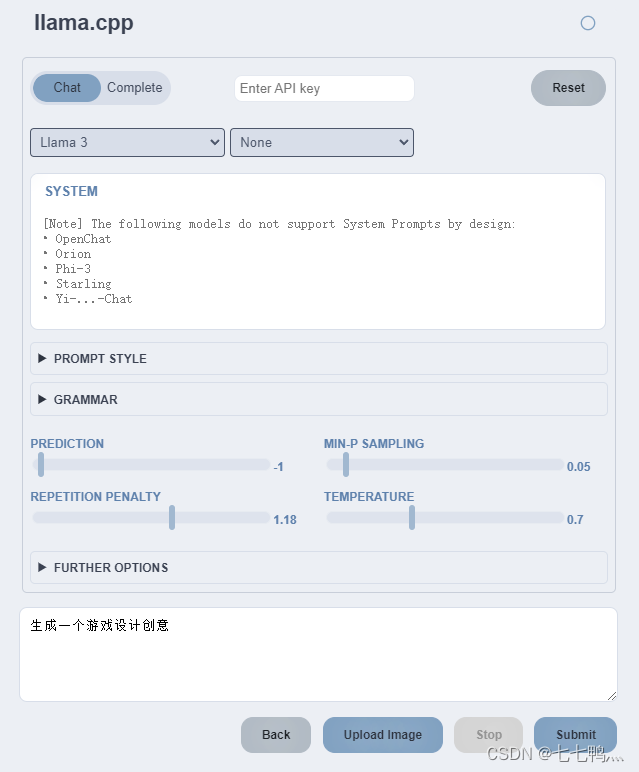
十四、使用docker部署模型
ps:modelarts里面没有docker,并且也不能安装docker,所以下面这几步我在本地主机上演示,你们也可以在有GPU的服务器上进行(我A100云服务器过期了什么人间疾苦)
执行下面这条命令
docker run -d -p 8080:8080 -v D:/llama3/models:/models --name llama3 --gpus all ghcr.io/ggerganov/llama.cpp:server-cuda -m models/ggml-model-q4.0.gguf -c 4096 -b 64 -n 1024 -t 9999 --repeat_penalty 1.2 --top_k 20 --top_p 0.5 --n_gpu_layers 33 --host 0.0.0.0 --port 8080然后执行
docker ps
出现这个就是运行成功了
import requestsdef send_request(prompt):url = "http://localhost:8080/completion" # 假设服务端点为/completion,根据实际情况调整headers = {"Content-Type": "application/json",}data = {"prompt": prompt,"n_predict": 1024}try:response = requests.post(url, headers=headers, json=data)response.raise_for_status() # 如果响应状态码不是200,将抛出异常response_data = response.json()print("Response:", response_data)except requests.exceptions.RequestException as e:print(f"Error occurred: {e}")if __name__ == "__main__":prompt = '{"prompt":"给出一个游戏设计创意"}'send_request(prompt)
然后我们用python去写个请求去测试一下我们的api服务是否正常

最后也是能够正常的调用我们的llama3去生成这个回答。
十五、部署到QQ机器人上
这部分过于繁杂,而且难度不大,暂时省略。
(完结撒花了~,这篇文章是偏向应用的,后续会更新更多涉及原理的文章)
作者介绍
作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果你觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
尾言
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。