Linux基础IO【II】
今天,我们接着在上一篇文章的基础上,继续学习基础IO。观看本文章之前,建议先看:Linux基础IO【I】,那,我们就开始吧!

一.文件描述符
1.重新理解文件
文件操作的本质:进程和被打开文件之间的关系。
1.推论
我们先用一段代码和一个现象来引出我们今天要讨论的问题:
上码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
//我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}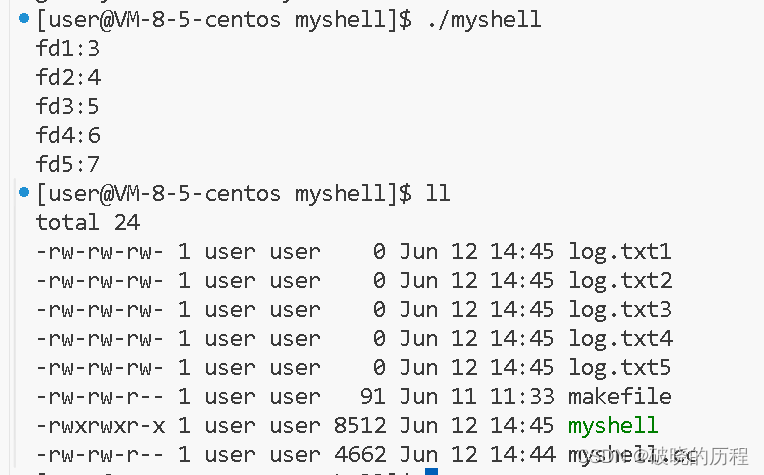
看到输出的结果,各位大佬想到了什么?我想到了数组的下标。也许这和数组有这千丝万缕的关系,但我们都只是猜测,接下来就证明我们的猜测。
首先我们可以利用现在掌握的知识推导出这样一条逻辑链:
- 进程可以打开多个文件吗?可以,而且我们刚刚已经证实了。
- 所以系统中一定会存在大量的被打开的文件。
- 所以操作系统要不要把这些被打开的文件给管理起来?要。
- 所以如何管理?先描述,再组织。
- 操作系统为了管理这些文件,一定会在内核中创建相应的数据结构来表示文件。
- 这个数据结构就是struct_file结构体。里面包含了我们所需的大量的属性。
我们回到刚刚代码的运行结果上来:
为什么从3开始,0,1,2分别表示的是什么?
其实系统为一个处于运行态的进程默认打开了3个文件(3个标准输入输出流):
- stdin(标准输入流) :对应的是键盘。
- stdout(标准输出流): 对应的是显示器。
- stderr(标准错误流) :对应的是显示器。
上面我们提及的struct_file结构体在内核中的数据如下:
/** Open file table structure*/
struct files_struct {/** read mostly part*/atomic_t count;bool resize_in_progress;wait_queue_head_t resize_wait;struct fdtable __rcu *fdt;struct fdtable fdtab;/** written part on a separate cache line in SMP*/spinlock_t file_lock ____cacheline_aligned_in_smp;unsigned int next_fd;unsigned long close_on_exec_init[1];unsigned long open_fds_init[1];unsigned long full_fds_bits_init[1];struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct file {union {struct llist_node fu_llist;struct rcu_head fu_rcuhead;} f_u;struct path f_path;struct inode *f_inode; /* cached value */const struct file_operations *f_op;spinlock_t f_lock;enum rw_hint f_write_hint;atomic_long_t f_count;unsigned int f_flags;fmode_t f_mode;struct mutex f_pos_lock;loff_t f_pos;struct fown_struct f_owner;const struct cred *f_cred;struct file_ra_state f_ra;u64 f_version;
#ifdef CONFIG_SECURITYvoid *f_security;
#endif/* needed for tty driver, and maybe others */void *private_data;#ifdef CONFIG_EPOLLstruct list_head f_ep_links;struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */struct address_space *f_mapping;errseq_t f_wb_err;
}
2.证明

大家有没有好奇过:为什么我们C库函数fopen的返回值类型是FILE*,FILE是什么?当时老师肯定没给我们讲清楚,因为当时我们的知识储备不够。但现在,我们有必要知道FILE其实就是一个结构体类型。
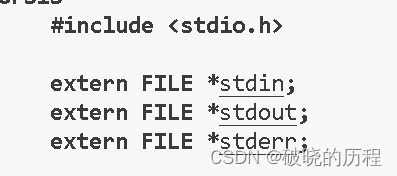
//stdio.h
typedef struct _iobuf
{char* _ptr; //文件输入的下一个位置int _cnt; //当前缓冲区的相对位置char* _base; //文件初始位置int _flag; //文件标志int _file; //文件有效性int _charbuf; //缓冲区是否可读取int _bufsiz; //缓冲区字节数char* _tmpfname; //临时文件名
} FILE;
这3个标准输入输出流既然是文件,操作系统必定为其在系统中创建一个对应的struct file结构体。
为了证明我们的判断,我们可以:调用struct file内部的一个变量。
操作系统底层底层是用文件描述符来标识一个文件的。纵所周知,C文件操作函数是对系统接口的封装。所以FILE结构体中一定隐藏着一个字段来储存文件描述符。而且stdin,stdout,stderr都是FILE*类型的变量,
所以:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
// 我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{printf("stdin:%d\n", stdin->_fileno);//调用struct file内部的一个变量printf("stdout:%d\n", stdout->_fileno);printf("stderr:%d\n", stderr->_fileno);umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}
来啦,终于来啦!!终于证明我们的推断。
2.理解文件描述符
进程中打开的文件都有一个唯一的文件描述符,用来标识这个文件,进而对文件进行相关操作。其实,我们之前就接触到了文件描述符,我们简单回忆一下:
- 调用open函数的返回值,就是一个文件描述符。只不过,我们打开的文件的文件描述符默认是从3开始的,0.1.2是系统自动为进程打开的。
- 调用close传入的参数。
- 调用write,read函数的第一个参数。
可见,文件描述符对我们进行文件操作有多么重要。文件描述符就像一个人身份证,在一个进程中具有唯一性。
文件描述符fd的取值范围:文件描述符的取值范围通常是从0到系统定义的最大文件描述符值。
当Linux新建一个进程时,会自动创建3个文件描述符0、1和2,分别对应标准输入、标准输出和错误输出。C库中与文件描述符对应的是文件指针,与文件描述符0、1和2类似,我们可以直接使用文件指针stdin、stdout和stderr。意味着stdin、stdout和stderr是“自动打开”的文件指针。
在Linux系统中,文件描述符0、1和2分别有以下含义:
- 文件描述符0(STDIN_FILENO):它是标准输入文件描述符,通常与进程的标准输入流(stdin)相关联。它用于接收来自用户或其他进程的输入数据。默认情况下,它通常与终端或控制台的键盘输入相关联。
- 文件描述符1(STDOUT_FILENO):它是标准输出文件描述符,通常与进程的标准输出流(stdout)相关联。它用于向终端或控制台输出数据,例如程序的正常输出、结果和信息。
- 文件描述符2(STDERR_FILENO):它是标准错误文件描述符,通常与进程的标准错误流(stderr)相关联。它用于输出错误消息、警告和异常信息到终端或控制台。与标准输出不同,标准错误通常用于输出与程序执行相关的错误和调试信息。
这些文件描述符是在进程创建时自动打开的,并且可以在程序运行期间使用。它们是程序与用户、终端和操作系统之间进行输入和输出交互的重要通道。通过合理地使用这些文件描述符,程序可以接收输入、输出结果,并提供错误和调试信息,以实现与用户的交互和数据处理。
1.文件描述符的分配规则
文件描述符的分配规则为:从0开始查找,使用最小的且没有占用的文件描述符。
所以:我们是否可是手动的关闭,系统为我们自动带的3个文件呢?so try!
先试着关闭一下0号文件描述符对应的标准输入流
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
// 我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{close(0);umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}结果,我们自己打开的文件就把0号文件描述符给占用了。接着,我们试试关闭之后写入受什么影响。
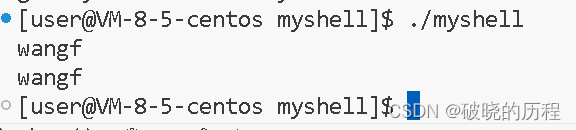
没关闭之前:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{//close(0);char buffer[1024];memset(buffer,0,sizeof(buffer));scanf("%s",buffer);printf("%s\n",buffer);
}
关闭后:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{close(0);char buffer[1024];memset(buffer,0,sizeof(buffer));scanf("%s",buffer);printf("%s\n",buffer);
}
我们发现:scanf函数直接无法使用,输入功能无法使用。原因是什么?
这是因为我们将0号文件描述符关闭后,0号文件描述符就不指向标准输入流了。但是当使用输入函数输入时,他们仍然会向0号中输入,但0号已经不指向输入流了,所以就无法完成输入。
大家也可以自行将1号文件描述符和2号文件描述符试着关闭一下,观察一下关闭前后有什么不同之处。
3.如何理解文件操作的本质?
- 我们说:文件操作的本质是进程和被打开文件之间的关系。对这句话我们应该如何理解呢?
- 文件描述符为什么就是数组的下标呢?
- 如何理解键盘,显示器也是文件?
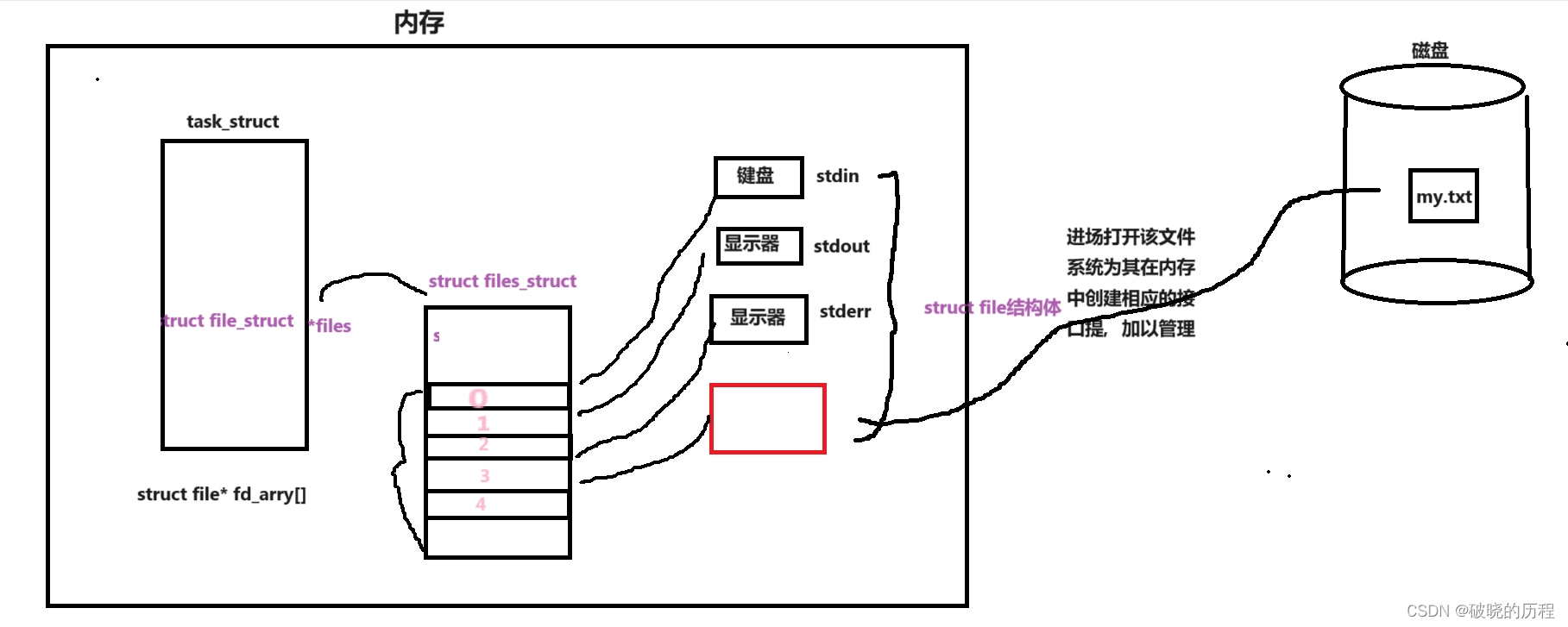
如上图:
进程想要打开位于磁盘上的my.txt文件,文件加载到内存之后,操作系统为了管理该文件,为其创建了一个struct file结构体来保存该文件的属性信息。此时,内存中已经存在系统默认打开的标准输入流,标准输出流,标准错误流对应的struct file结构体。但是,系统中有很多进程,,一定会有大量被打开的文件,进程如何分清个哪文件属于该进程呢?我们知道task_struct结构体保存着关于该进程的所有属性。其中有一个struct file_struct*类型的指针files,指向一个struct file_struct 类型的结构体,该结构体中存在着一个struct file*类型的数组,数组的元素为struct file*类型。正好存放指向我们为每一个文件创建的struct file结构体的指针。所以,根据这个数组,我们就会很顺利的找到每一个文件的struct file结构体。进而找到每一个属于该进程的文件,然后对文件进行相关操作。由于数组的下标具有很好的唯一性,所以系统就向上层返回存放文件的struct file结构体指针的元素下标,供上层函数利用这个下标对文件进行操作。
通过这段文字,相信大家已经对我们刚刚提出的几个问题已经有了答案!
4.输入重定向和输出重定向
1.原理
重定向的原理就是:上层调用的fd不变,在内核中更改fd对应的struct file*地址。
如下图:
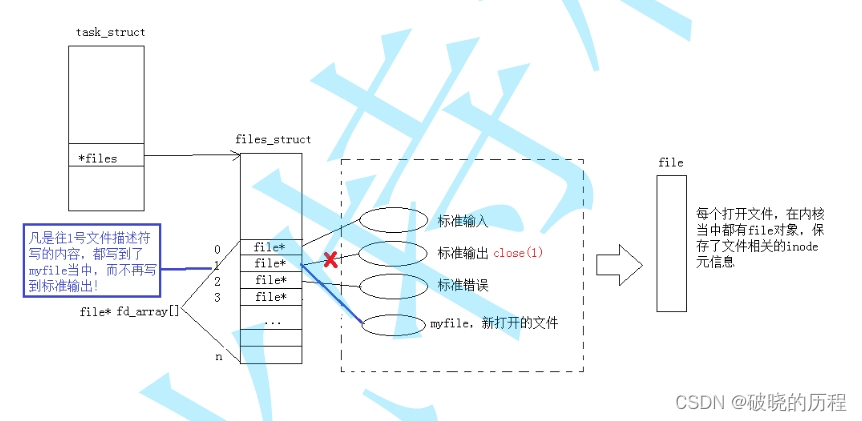
我们调用了close(1)关闭了输出文件流。然后打开了myfile文件,根据文件描述符的分配规则(从0开始查找最小且没有被占用的充当自己的文件描述符)。myfile的文件描述符。但是上层并不知道输入文件流对应的文件描述符已经发生改变,所以当调用printf函数时,仍然向1号文件描述符中输出。但是1号描述符对应的地址已发生改变,变为myfile,所以本想使用printf往显示器中输入的东西就会输入到myfile文件中。这就是输出重定向。
输入重定向和输出重定向原理是一样的,只不过输入重定向关闭的是输入流,输出重定向关闭的是输出文件流。
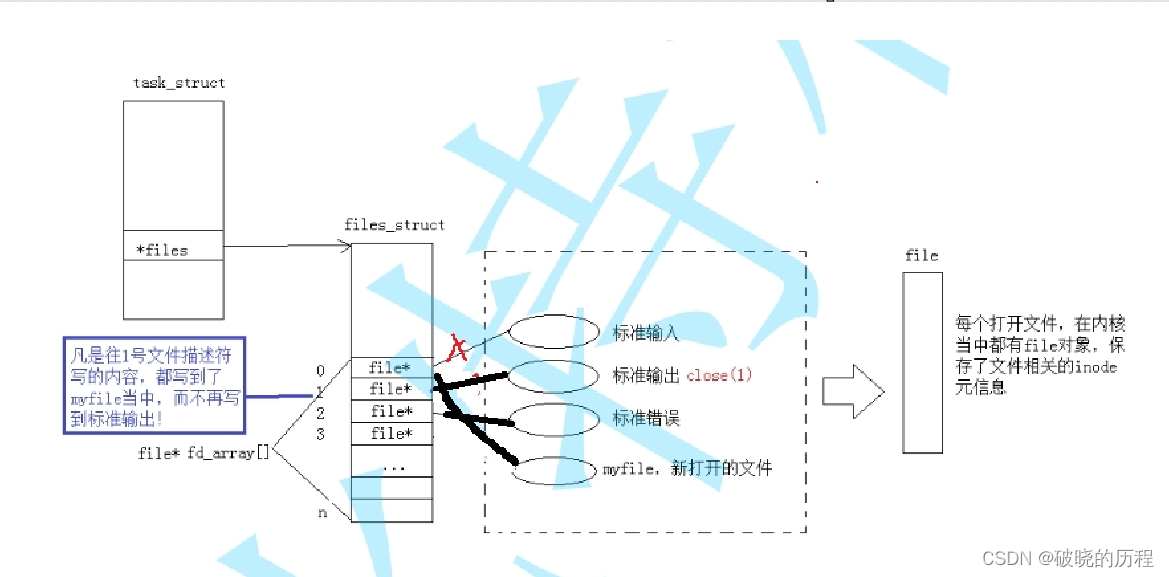
我们调用了close(0)关闭了输入文件流。然后打开了myfile文件,根据文件描述符的分配规则(从0开始查找最小且没有被占用的充当自己的文件描述符)。myfile的文件描述符。但是上层并不知道输入文件流对应的文件描述符已经发生改变,所以当调用printf函数时,仍然向0号文件描述符中输出。但是0号描述符对应的地址已发生改变,变为myfile,所以就会输入到myfile文件中。这就是输出重定向。