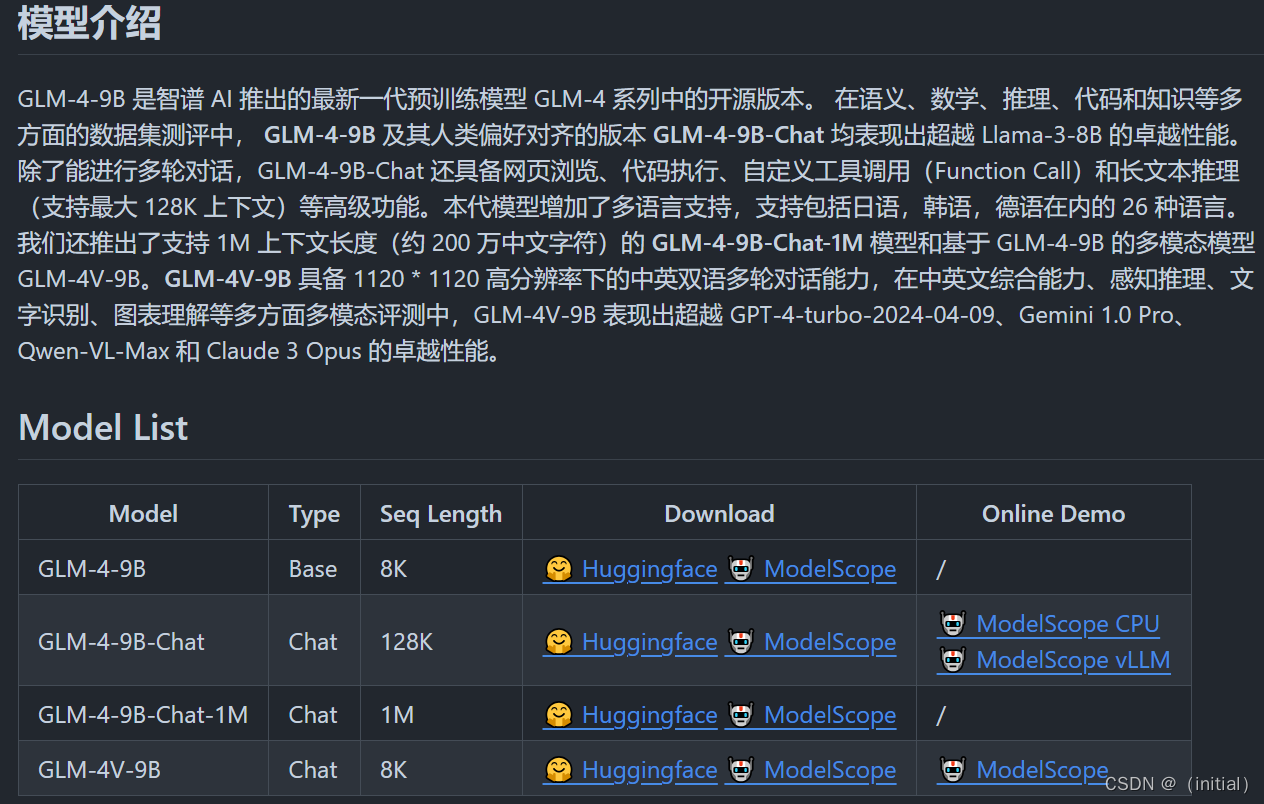
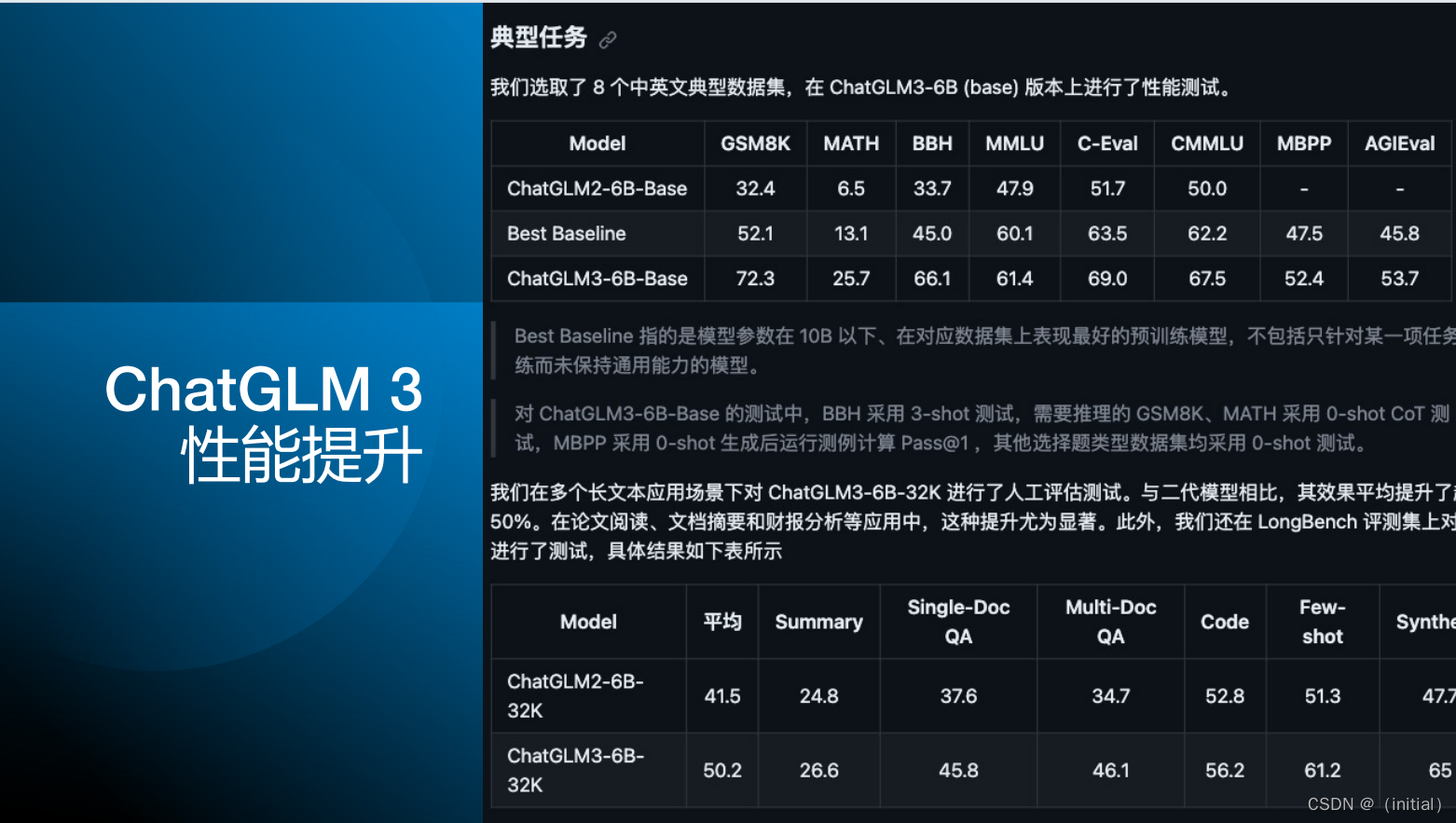
10.GLM
智谱AI GLM 大模型家族
最强基座模型 GLM-130B

GLM (General Language Model Pretraining with Autoregressive Blank Infilling)
基于自回归空白填充的通用语言模型(GLM)。GLM通过增加二维位置编码并允许以任意顺序预测跨度来改进空白填充预训练,这在NLU任务中实现了超越BERT和T5的性能提升。与此同时,GLM可以通过变化空白的数量和长度来预训练不同类型的任务。在跨NLU、有条件和无条件生成的广泛任务中,GLM在相同模型大小和数据条件下优于BERT、T5和GPT。
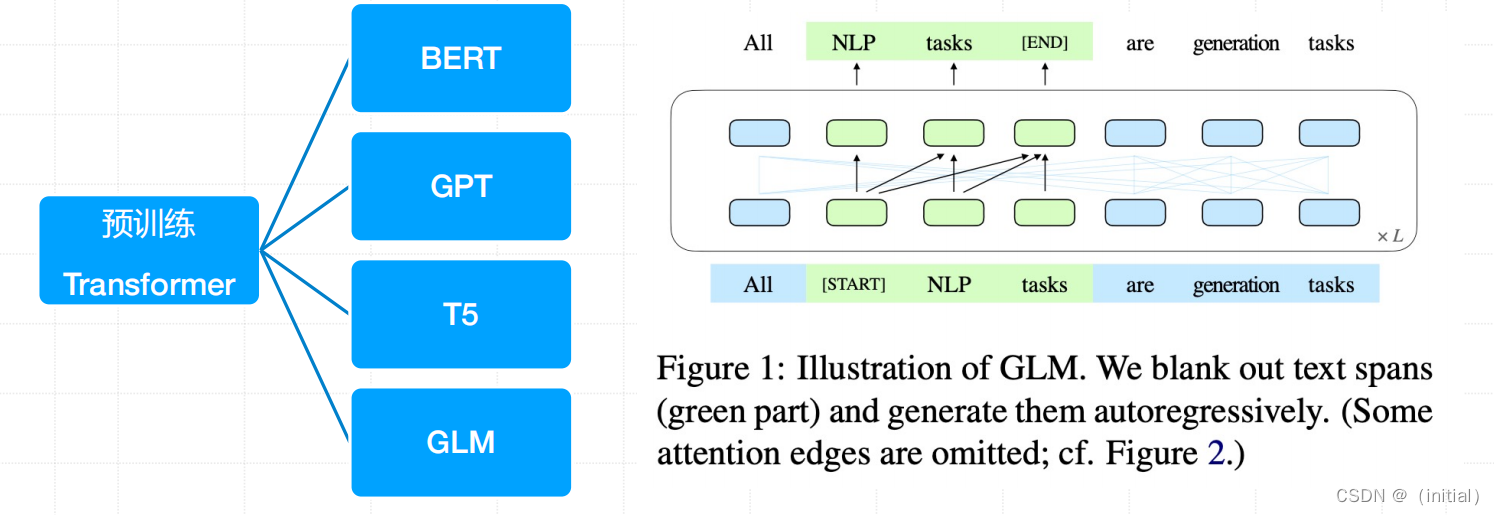
GLM 预训练原理解读 – 1
(a) 原始文本为[x1, x2, x3, x4, x5, x6]。随机采样了两个跨度(spans)[x3]和[x5, x6]。
(b) 在Part A中,用[MASK]标记[M]替换采样的跨度,并在Part B中对跨度进行洗牌(shuffle)。
© GLM 自回归地生成 Part B。每个跨度前添加[START]标记作为输入,并在后面附加[END]标记作为输出。二维位置编码表示跨度间和跨度内的位置。
(d) 自注意力掩码:灰色区域被遮蔽。Part A标记 (蓝色) 可以内部互相关注,有助于模型捕捉文本内部的上下文信息,但不能关注B。Part B标记(黄色和绿色)可以关注A和B中前文,这种设置允许模型以自回归的方式生成文本,同时考虑到已经生成的上下文。
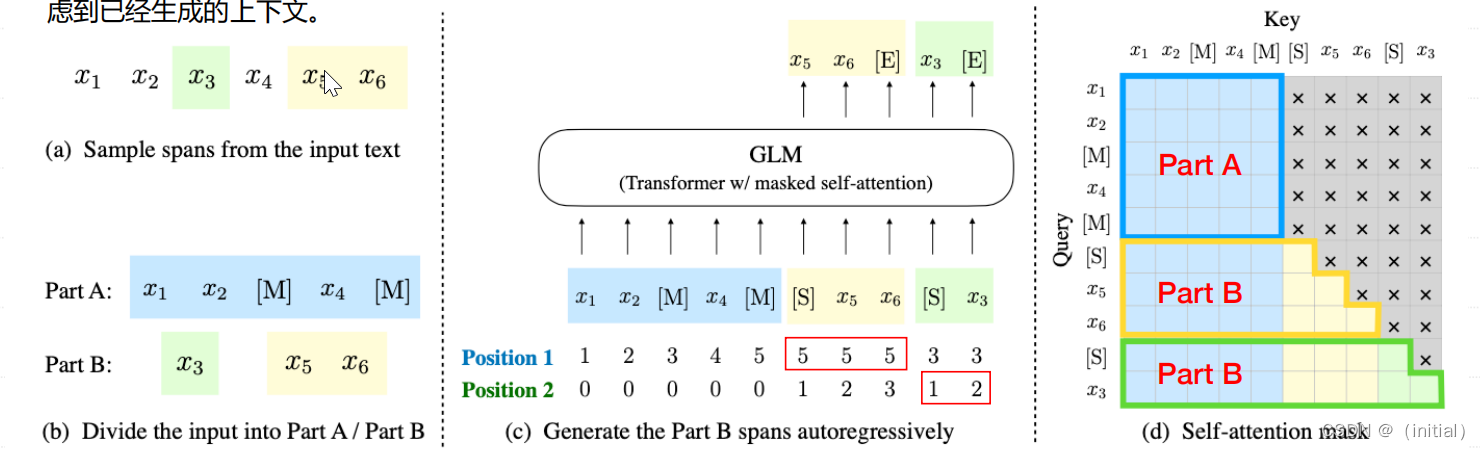
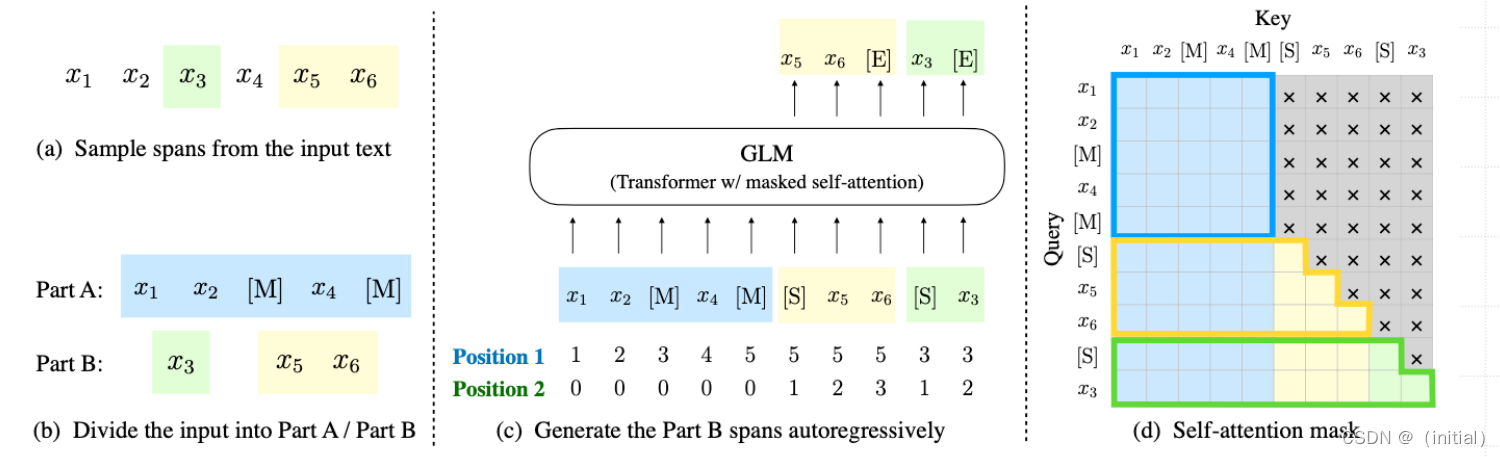
上图分为三部分,分别为:1. 输入的文本构成; 2. 模型的输入和模型输出; 3.模型的注意力mask掩码矩阵。
- 我们首先看第一部分,从上图可以看到,输入 � 被分为两部分:PartA是文本 x_corrupt,而PartB是被mask掩码片段原本的token。掩码片段的长度服从泊松分布。
- 接下来,我们再来看第二部分.在第二部分中PartA和PartB拼接在一起,并且PartB中的Mask片段使用[s] token 来与其他片段和PartA进行分开。然后,glm的位置编码为二维位置编码。在postion 1中,PartA的位置编码为从0递增,PartB的位置编码为掩码 s_i 在 x_corrupt 中原本的位置编码。在Postion 2中, x_corrupt 的位置全为0,PartB中的每个 s_i 片段内位置自增。假设 x=[x_1,x_2,x_3,x_4,x_5,x_6],其中 和x_3和x_5,x_6 为掩码片段,记为 和s_n和s_m 。因为 s_n 来自片段3, s_m 来自片段5,所以它们的potion 1的位置编码分别为3和5.而 s_n 的potion 2位置编码为[1], s_m的位置编码为[1,2].
- glm通过改变它的注意力掩码,从而实现encoder-decoder架构。在glm注意力掩码里, x_corrupt为全注意力掩码,既当前tokn既可以关注之前token,能关注到之后的token。所以, x_corrupt 之间是双向注意力,换个角度想, x_corrupt是输入到一个encoder里。而在掩码片段中,它们之间的注意力掩码为对角线,既掩码片段之间是单向注意力机制,所以掩码片段的部分输入到decoder里。总的来说,PartA中的词彼此可见;PartB中的词单向可见;PartB可见PartA;PartA不可见PartB.在预训练的时候,每个token生成的输入都是在它之前的文本。
假设 x=[x_1,x_2,x_3,x_4,x_5,x_6] ,其中 和x_3和x_5,x_6 为掩码片段。在预测 x_5 的时候,输入到模型中的是[x_1,x_2,S],其中 和x_1和x_2 是全注意力掩码,S为单向注意力掩码。接下来,要预测 x_6 的时候,即使模型上一个预测出来的token的不是 x_5 ,但是输入到模型中的还是 [x_1,x_2,S,x_5] ,实现了一种教师机制,从而保证预训练的时候,输入到模型的文本是正确的。
GLM 预训练原理解读 - 2
GLM 使用的短跨度(λ = 3)掩码的训练,适用于自然语言理解(NLU)任务。
为了在一个模型中同时支持文本生成,作者提出了一个多任务预训练方法(以第二目标共同优化文本生成任务):
- 文档级:从均匀分布中采样,其长度为原始标记的50%到100%。该目标针对长文本生成。
- 句子级:采样严格保证必须是完整的句子,总采样覆盖原始标记的15%。该目标针对seq2seq任务
- 这两个新目标与原始目标定义相同,唯一的区别是跨度的数量和长度。
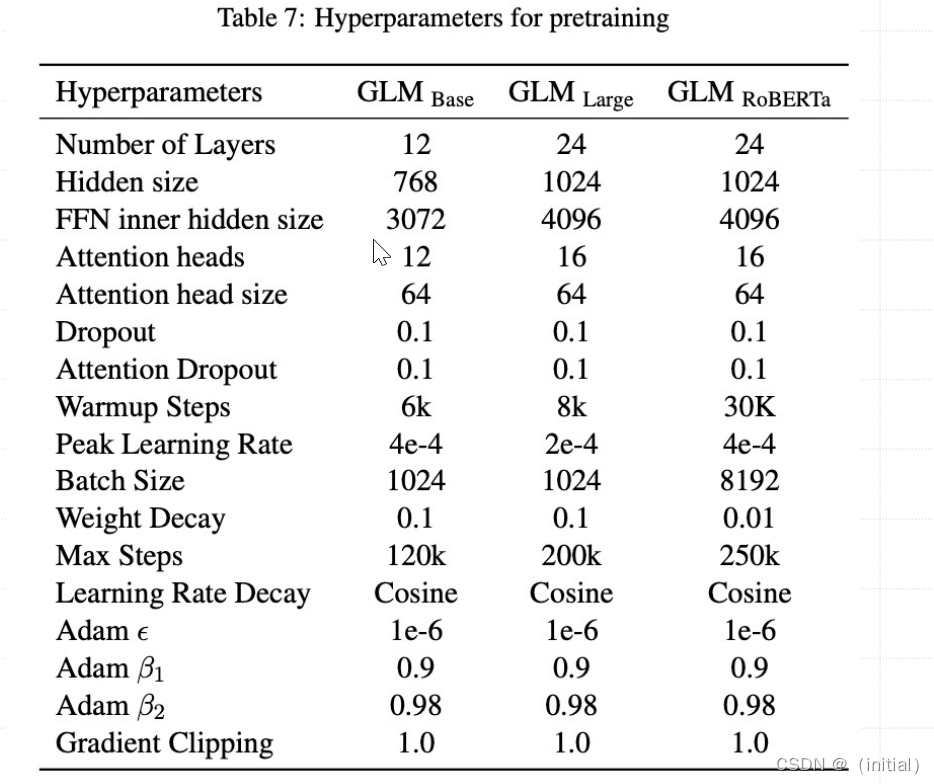
GLM 预训练超参数设置
GLM-130B**:开源双语大语言模型(ICLR 2023)**
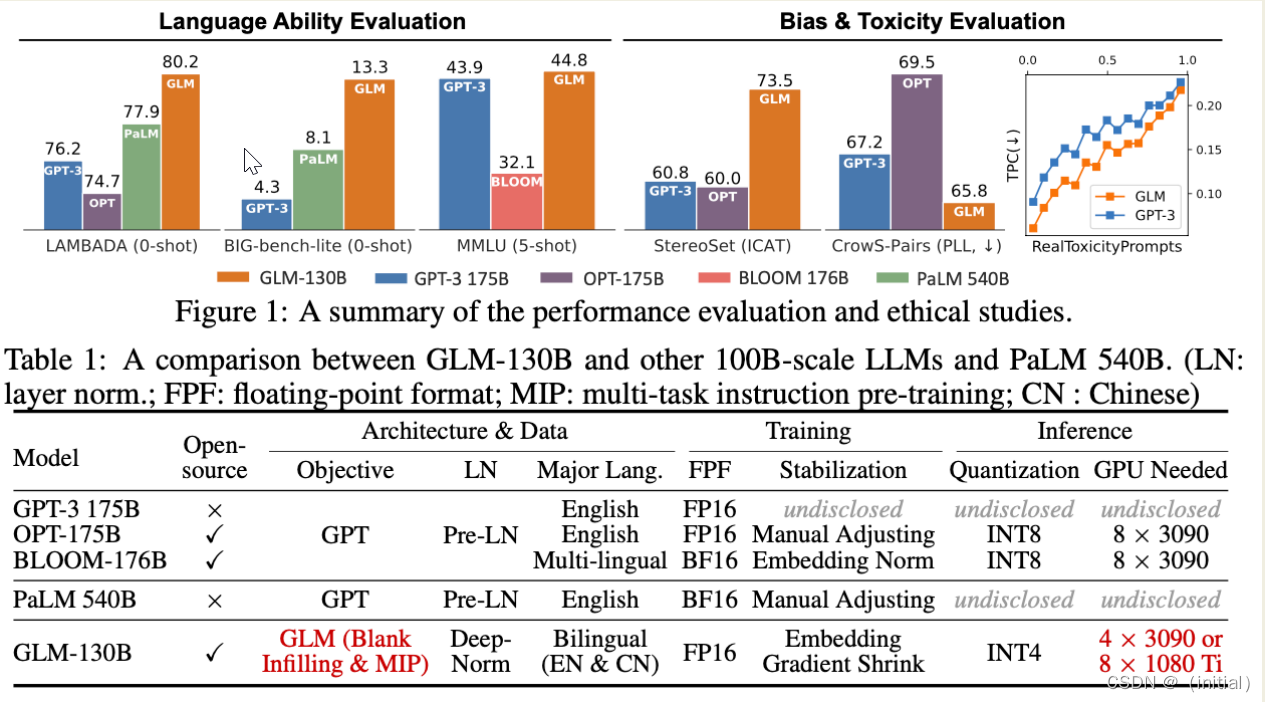
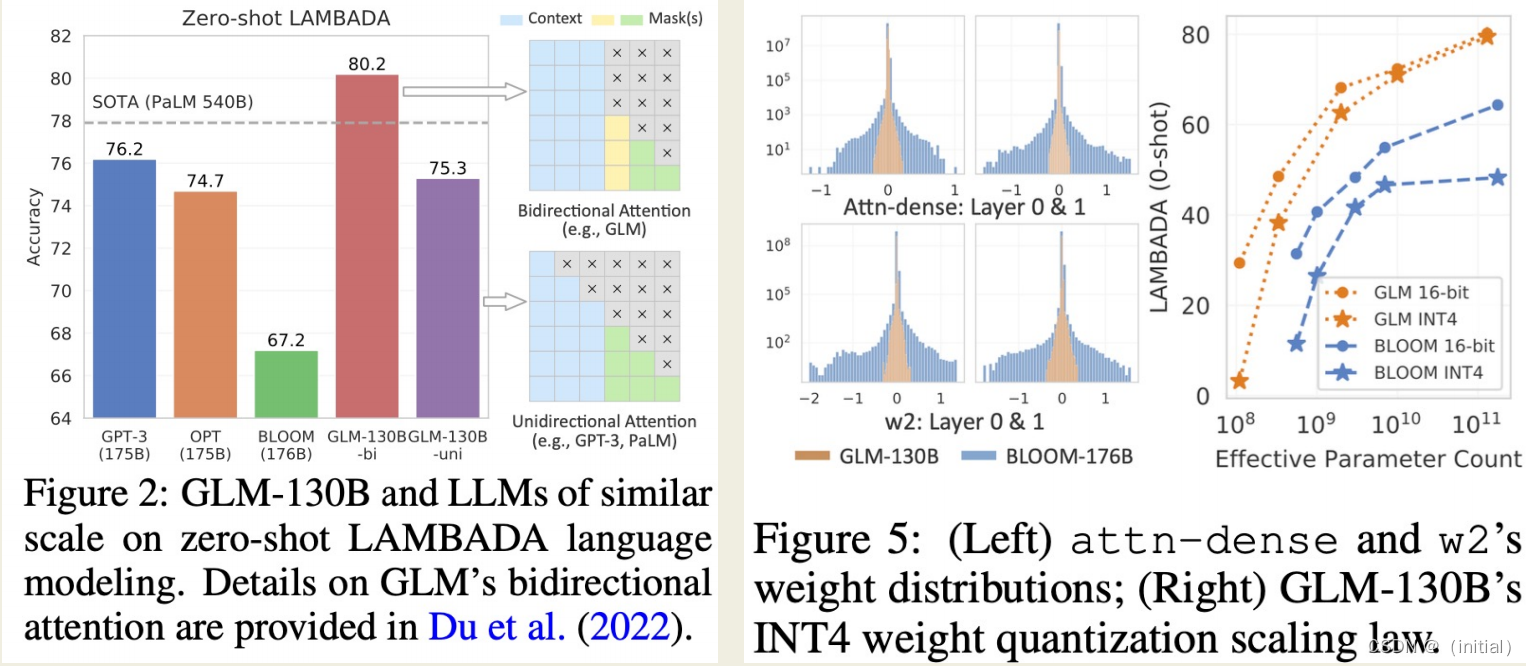
实验结果
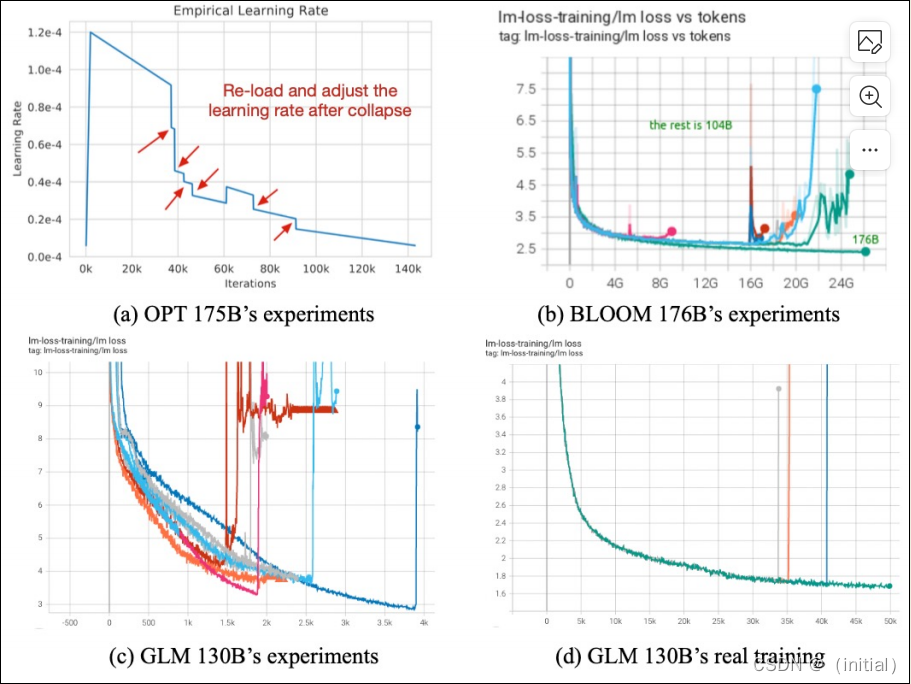
GLM-130B 预训练过程的挑战
训练崩溃和不稳定性包括以下几个方面:
- 损失尖峰:训练过程中可能出现损失函数突然大幅上升的情况,这可能是由于梯度爆炸、不恰当的学习率设置或模型架构问题导致的。
- 梯度不稳定:大型模型可能会遇到梯度不稳定的问题,导致训练过程波动性大,难以敛。
- 内存溢出:由于模型规模巨大,可能会出现内存溢出或其他资源限制问题,这会导致训练过程中断。
- 硬件限制:大型模型训练可能受到硬件资源的限制,如GPU内存不足,需要采用复杂的并行化策略。
GLM-130B 量化后精度损失较少
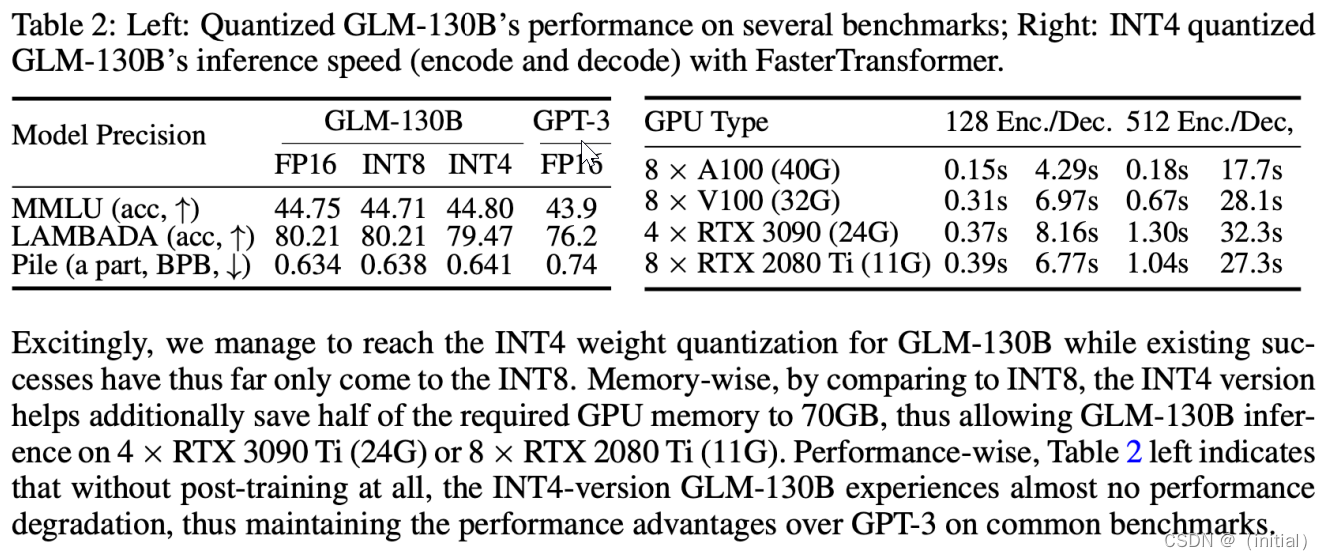
GLM-130B 部署硬件资源需求
- 建议使用A100(40G * 8)服务器
- 所有GLM-130B评估结果(约30个任务)可以在大约半天的时间内轻松地使用单个A100服务器进行复现。
- 通过INT8 / INT4量化,在具有4 * RTX3090(24G)的单个服务器上可以进行高效推理,详见GLM-130B的量化说明。
- 结合量化和权重卸载技术,甚至可以在GPU内存更小的服务器上进行GLM-130B推理,请参阅低资源推理以获取详细信息。
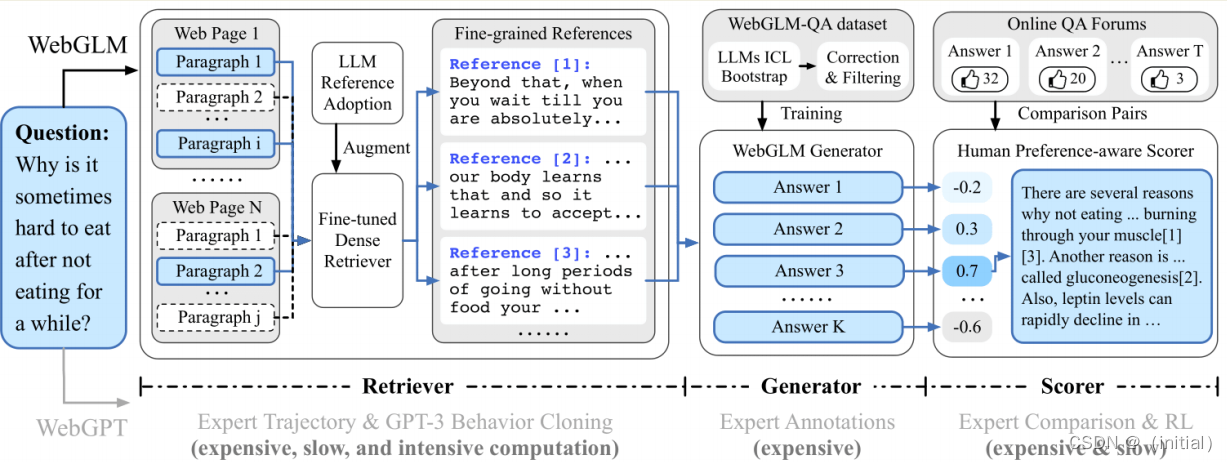
联网检索能力 WebGLM
WebGLM: An Efficient Web-enhanced Question Answering System (KDD 2023)
WebGLM旨在利用100亿参数的通用语言模型(GLM)提供高效且具有成本效益的网络增强问答系统。它旨在通过将网络搜索和检索功能整合到预训练的语言模型中,改善实际应用部署。
- LLM增强型检索器:提高相关网络内容的检索能力,以更准确地回答问题。
- 引导式生成器:利用GLM的能力生成类似人类的问题回答,提供精炼的答案。
- 人类偏好感知评分器:通过优先考虑人类偏好来评估生成回答的质量,确保系统产生有用吸引人的内容
初探多模态 VisualGLM-6B

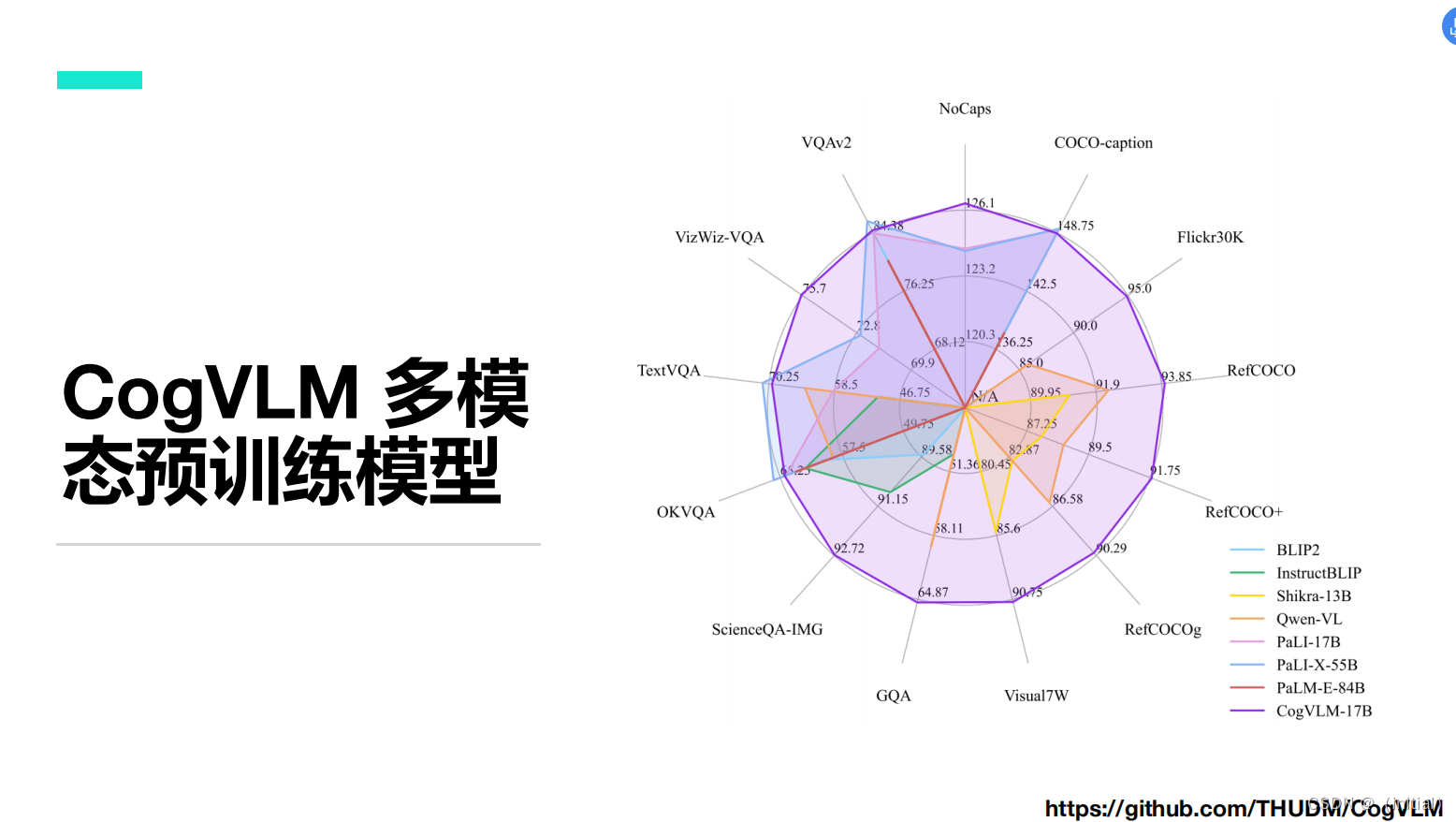
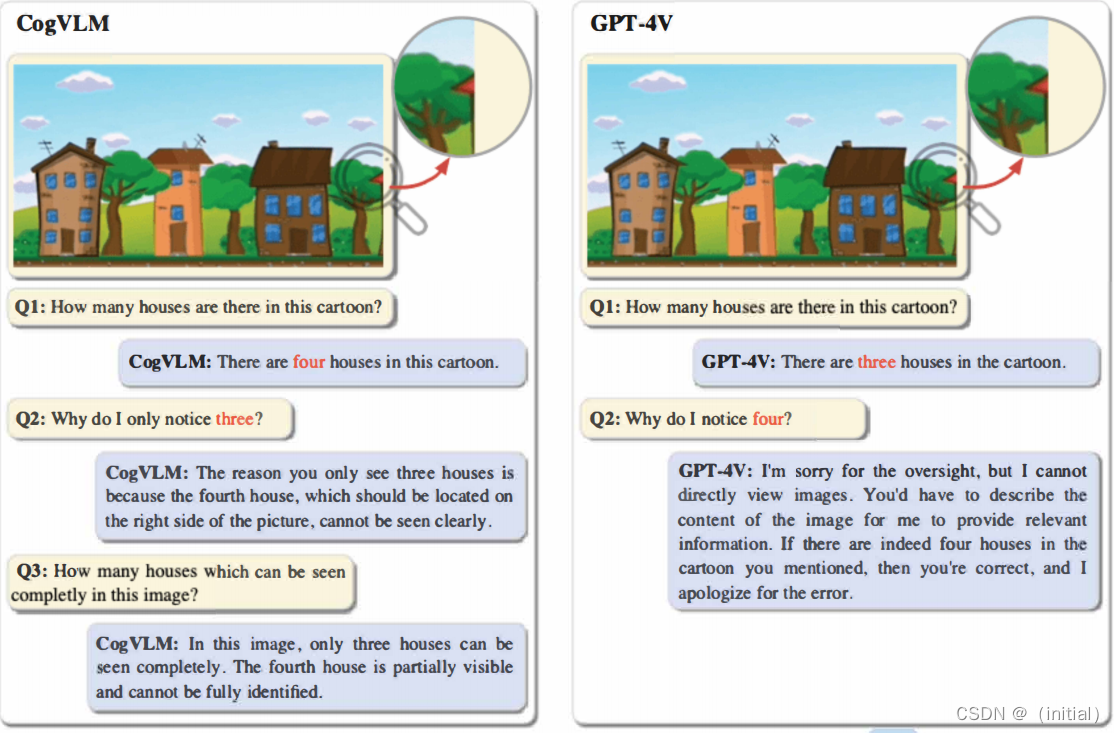
多模态预训练模型 CogVLM



代码生成模型 CodeGeex2

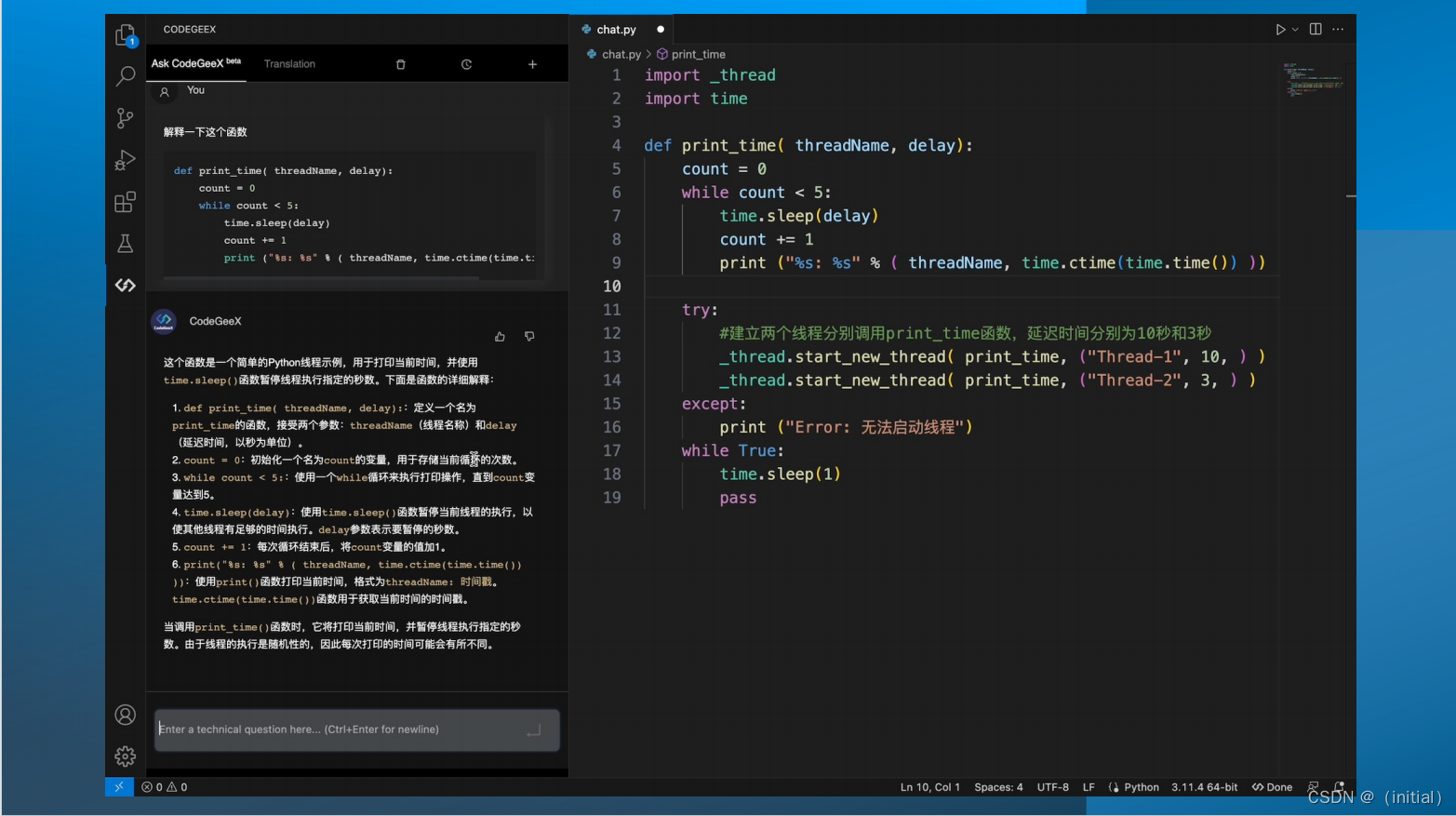

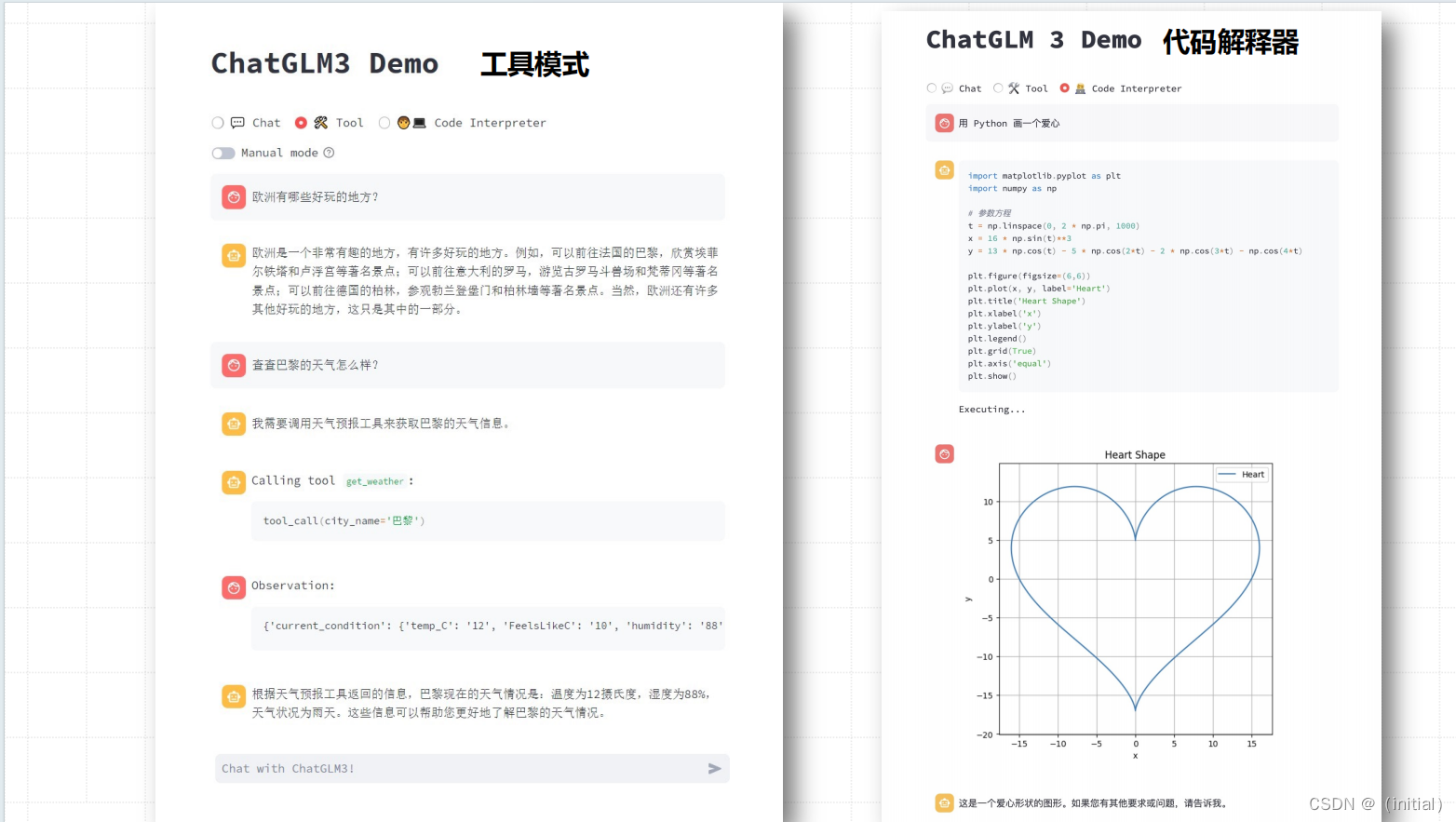
增强对话能力 ChatGLM
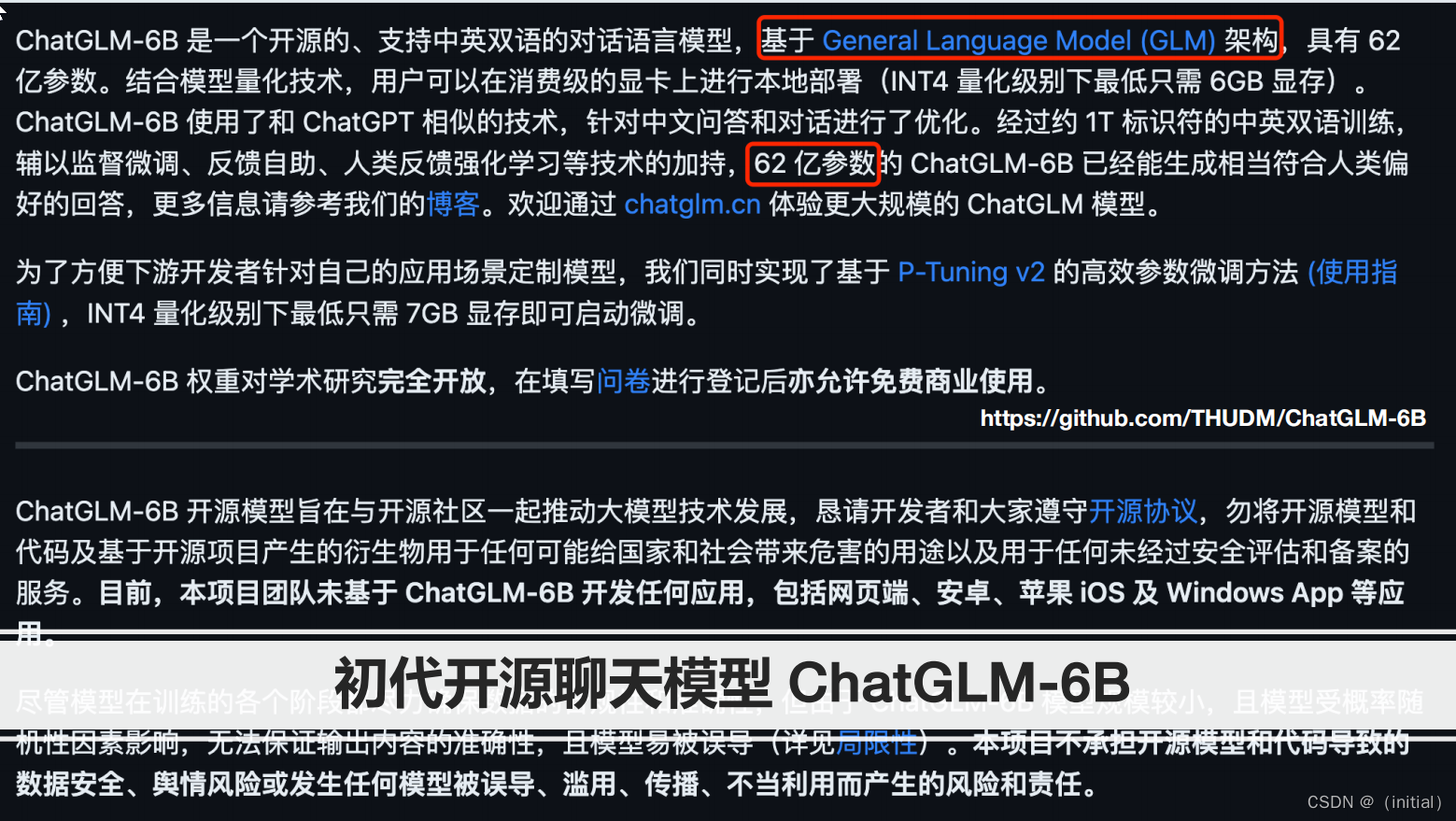


GLM4