机器学习二分类数据集预处理全流程实战讲解
本文概述
本文对weatherAUS数据集进行缺失值分析并剔除高缺失特征,合理填补剩余缺失值,利用相关性筛选关键特征,采用多种机器学习模型(如逻辑回归、随机森林等)在80%训练集上训练,并在20%测试集上预测明日降雨,最终通过可视化对比模型性能。
数据集展示
我们这次使用的是weatherAUS数据集,它大概长这样

缺失值处理
机器学习算法效果的好坏很大程度上取决于训练数据集质量的高低,这凸显了特征工程的重要性。特征工程作为预处理的关键环节,实质上界定了模型潜能的上限,深度影响着算法的最终表现力。因此,首要任务是对数据集进行全面而细致的分析,为后续的机器学习流程奠定坚实基础。
1、缺失值比例统计
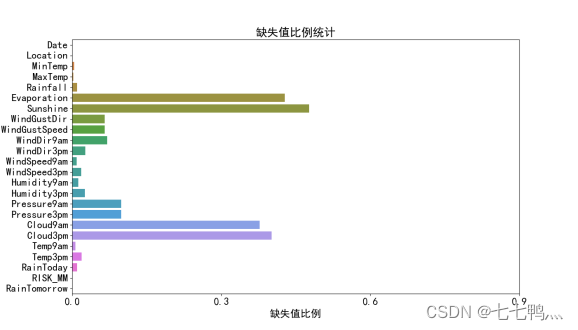
通过上面的缺失值比例统计图我们可以知道,"Evaporation"(蒸发量)、"Sunshine"(日照时长)、"Cloud9am"(上午9点云量)以及"Cloud3pm"(下午3点云量)这四个特征存在较高的数据缺失率。鉴于这些特征的缺失值比例较大,采用常规的缺失值填充方法可能无法有效反映其真实情况,且可能引入不必要的偏差到后续的分析之中。因此,为确保数据质量和分析结果的准确性,因此我们从数据集中剔除这些特征。此外,"Date"这一时间变量,对于预测"RainTomorrow"(明日降雨)这一目标变量并无直接助益。因此我们也将从数据集中剔除这个特征。
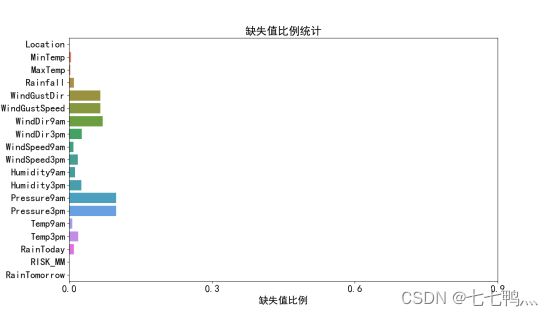
那么初步特征筛选剩下的特征如图所示
上面缺失值比例统计的代码如下
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from seaborn.palettes import color_palette
import numpy as np# 读取CSV文件
input_file_path = 'weatherAUC.csv'
df = pd.read_csv(input_file_path)#字体大小设置
plt.rcParams['font.size'] = 14
plt.rcParams['axes.titlesize'] = 20
plt.rcParams['axes.labelsize'] = 18
plt.rcParams['xtick.labelsize'] = 18
plt.rcParams['ytick.labelsize'] = 18# 计算每列的数据量和空值数量,以及缺失值比例
column_info = df.isnull().sum().to_frame(name='Missing_Values')
column_info['Total_Values'] = df.shape[0]
column_info['Filled_Values'] = column_info['Total_Values'] - column_info['Missing_Values']
column_info['Missing_Value_Ratio'] = column_info['Missing_Values'] / column_info['Total_Values']# 定义色彩调色板
palette = color_palette("husl", n_colors=len(column_info))# 设置matplotlib以支持中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=Falseplt.figure(figsize=(14, 8))
sns.barplot(y=column_info.index, x=column_info['Missing_Value_Ratio'], palette=palette, orient='h')
plt.title('缺失值比例统计')
# 根据比例调整x轴刻度
plt.xticks(np.arange(0, 1.1, 0.3))
plt.xlabel('缺失值比例')
plt.ylabel('')
plt.yticks(rotation=0) # 旋转y轴标签使其垂直显示
plt.show()2、数值变量的缺失值填补
weatherAUS数据集中的这些列都是数值变量
['MinTemp', 'MaxTemp', 'Rainfall','WindGustSpeed', 'WindSpeed9am','Humidity9am','Humidity3pm', 'Pressure9am',
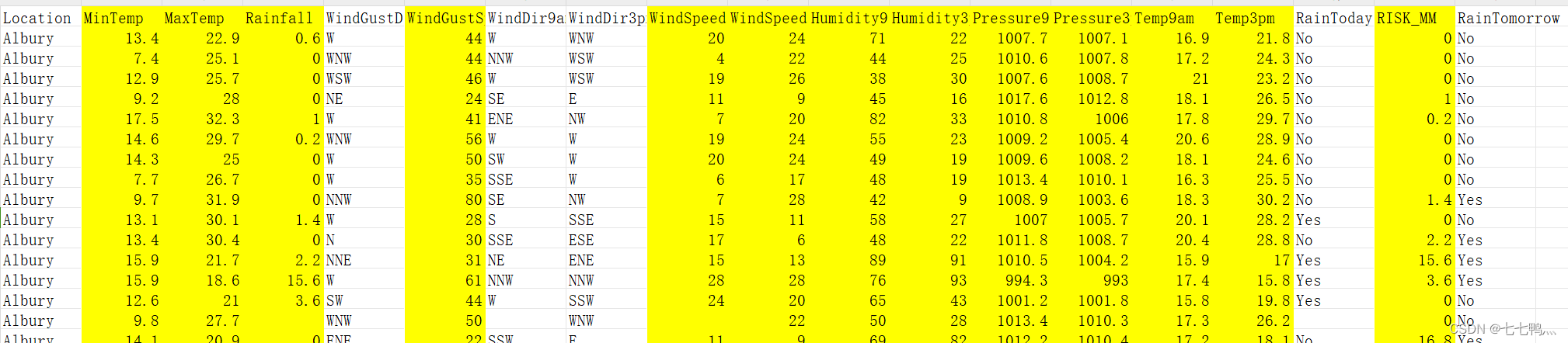
'Pressure3pm', 'Temp9am', 'Temp3pm', 'RISK_MM']下面是数值变量的部分截图(黄底背景)
对于数值变量来说,我们常用的填补方式有,中位数填补,平均值填补,众数填补。
均值填补:适用于数据大致对称且无极端值的情况,能够最小化填补后数据的方差。但是,如果数据中有偏斜或异常值,均值可能不具代表性。
中位数填补:对偏斜分布的数据更为稳健,不易受极端值影响。
众数填补:适用于分类似的数值变量或某些特定的偏态分布,但较少用于连续数值变量。
-
均值填补
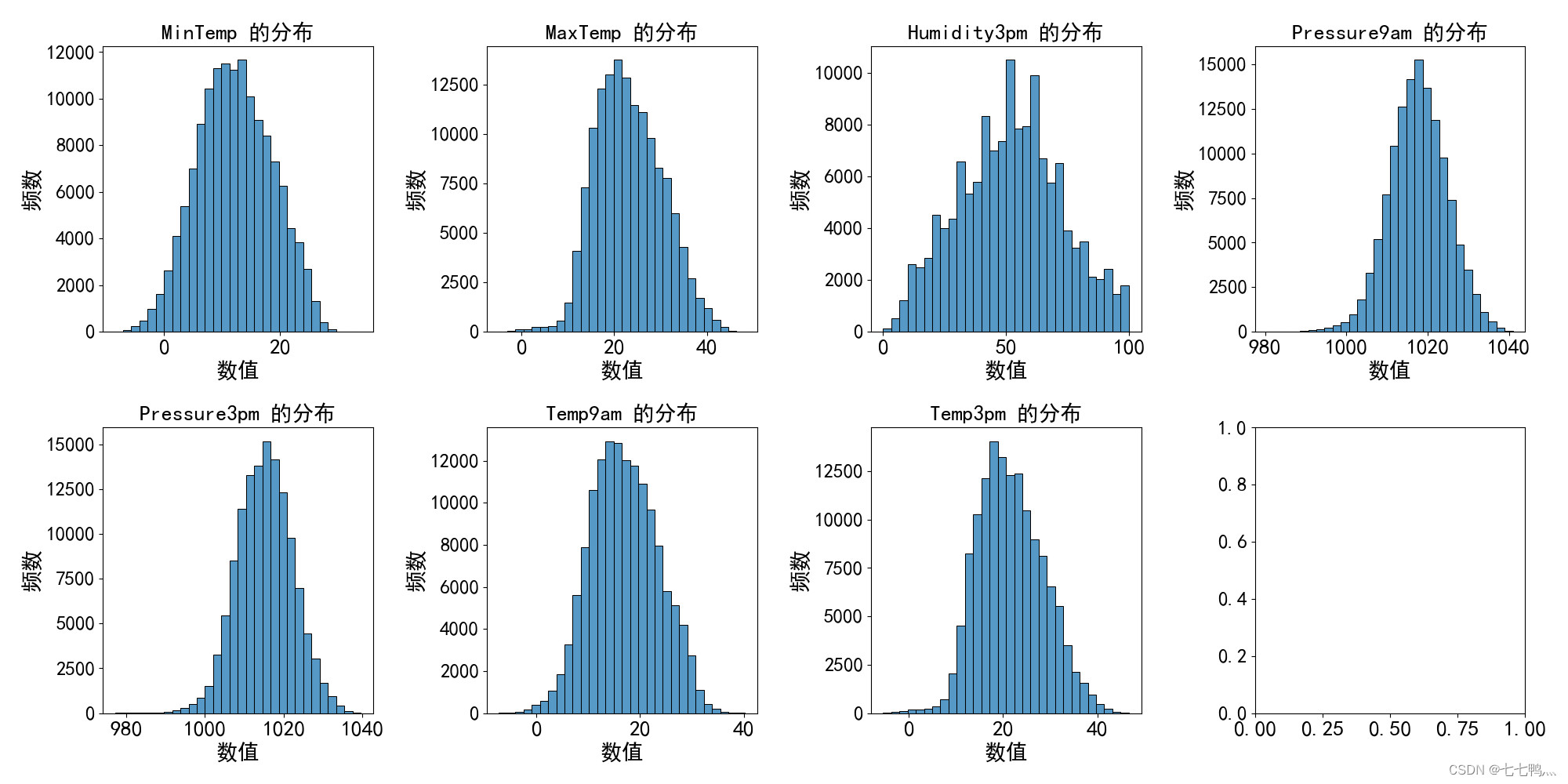
我们观察这几列数据的频率直方图,发现它们基本上是对称分布的,那么我们对于这些列的缺失值最好使用平均值填补的方式去填补缺失值。
-
中位数填补
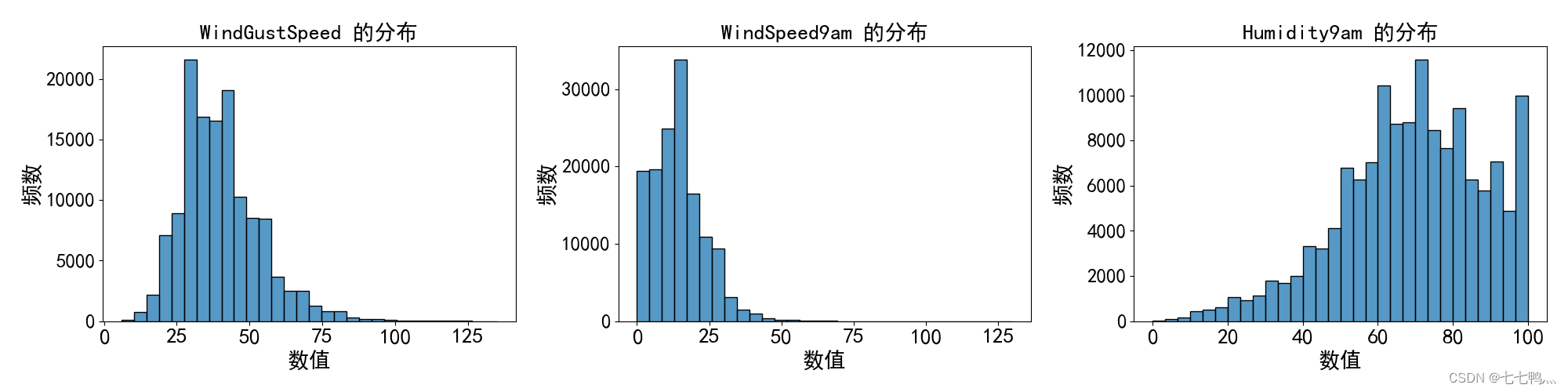
我们观察这几列数据的频率直方图,发现它们是存在偏斜情况的,即数据往一侧集中。那么我们对于这些列的缺失值最好使用中位数填补的方式去填补缺失值。
-
众数填补
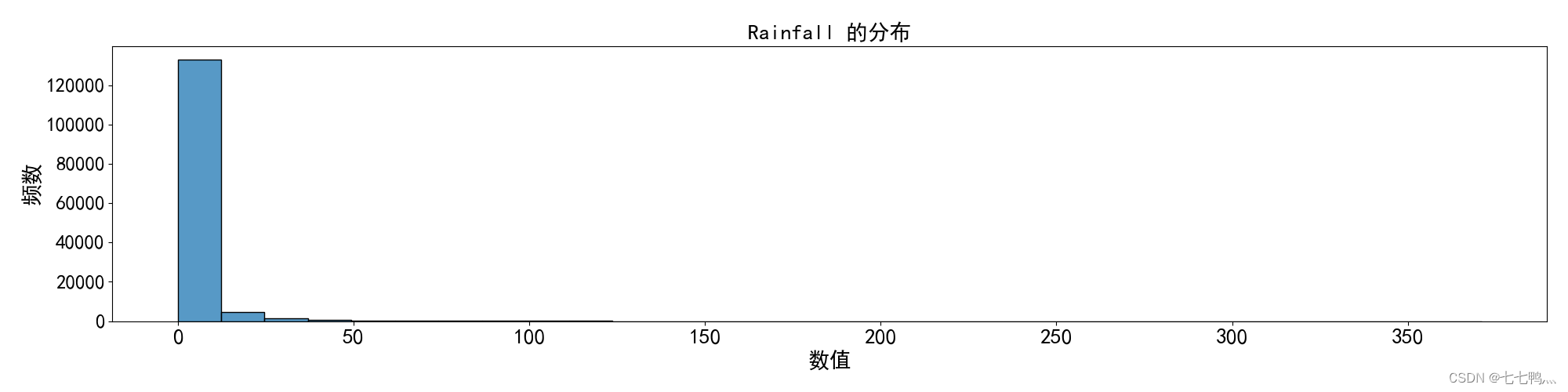
我们观察这列的频率直方图,我们发现它不仅存在偏斜情况,而且某个值的数量远远高于其它值的数量,那么我们对于这列的缺失值最好使用众数填补的方式去填补缺失值。
3、分类变量的缺失值填补
在处理分类变量的缺失值时,常见的填补方法包括以下几种:
众数填补:利用该类别出现频次最高的值来填充缺失项。适用于那些含有明显主导类别的特征。
模型预测填补:构建一个辅助模型,基于其他完整特征的关系来预测缺失值。
新增缺失值类别:将缺失值视为一个独立的类别加入到原有分类体系中。这种方法承认数据缺失的事实,有时能够捕捉到缺失值本身所携带的信息,适用于缺失值背后可能隐藏特定模式或意义的情形。

如上图的频率直方图所示,除了RainToday,其它列并没有明显的众数,单纯使用众数填补可能会引入较大的误差,导致无法准确的预测结果,因此不适用众数填补的方法。
为了节省工作量,而且这些分类变量的缺失值占比比较低,我们可以对这些分类变量的缺失值统一使用-1去填补,从而减少工作量。
至于RainToday,根据我们的常识,今天下雨很可能明天就不会下雨,因此我们也不能使用众数去填补,这可能会引入很大的噪音,我们也暂时先使用-1去填补缺失值,后续通过分析相关性再决定是否要进一步处理。
上面使用到频率直方图可视化代码如下
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False#字体大小设置
plt.rcParams['font.size'] = 18
plt.rcParams['axes.titlesize'] = 30
plt.rcParams['axes.labelsize'] = 30
plt.rcParams['xtick.labelsize'] = 20
plt.rcParams['ytick.labelsize'] = 18# 读取CSV文件
file_path = r'new_file_with_selected_columns.csv' # 请替换为您的CSV文件路径
df = pd.read_csv(file_path)# 定义要分析的列
columns_to_analyze = ['MinTemp', 'MaxTemp', 'Rainfall', 'WindGustSpeed', 'WindSpeed9am', 'Humidity9am', 'Humidity3pm','Pressure9am', 'Pressure3pm', 'Temp9am', 'Temp3pm']# columns_to_analyze = ['MinTemp', 'MaxTemp', 'Humidity3pm',
# 'Pressure9am', 'Pressure3pm', 'Temp9am', 'Temp3pm']# columns_to_analyze = ['WindGustSpeed', 'WindSpeed9am', 'Humidity9am']# columns_to_analyze = ['Rainfall']# 计算统计量可以放在最后展示或者单独处理,这里先注释掉以聚焦于绘图部分# 确定子图的行数和列数,这里假设不超过4列以保持可读性
num_cols = min(len(columns_to_analyze), 4)
num_rows = (len(columns_to_analyze) - 1) // num_cols + 1fig, axes = plt.subplots(num_rows, num_cols, figsize=(20, 5 * num_rows), squeeze=False)
for idx, col in enumerate(columns_to_analyze):row = idx // num_colscol_idx = idx % num_cols# 绘制直方图sns.histplot(data=df, x=col, bins=30, ax=axes[row][col_idx])axes[row][col_idx].set_title(f"{col} 的分布", fontsize=20)axes[row][col_idx].set_xlabel("数值", fontsize=20)axes[row][col_idx].set_ylabel("频数", fontsize=20)# 调整子图间距
plt.tight_layout()plt.show()数据标准化
完成了缺失值填补之后,我们还需要对数值变量进行一个标准化,让其均值为0,标准差为1,这样可以让模型更好的使用这些特征
然后完成了上面所有步骤之后的特征变量如下
相关性分析
但是现在特征还是太多了,我们需要更进一步的进行特征的筛选,我们这里使用相关性分析,分别分析每个变量和RainTomorrow的关系,然后得出相关性矩阵,将相关性比较低的特征变量给剔除出去。
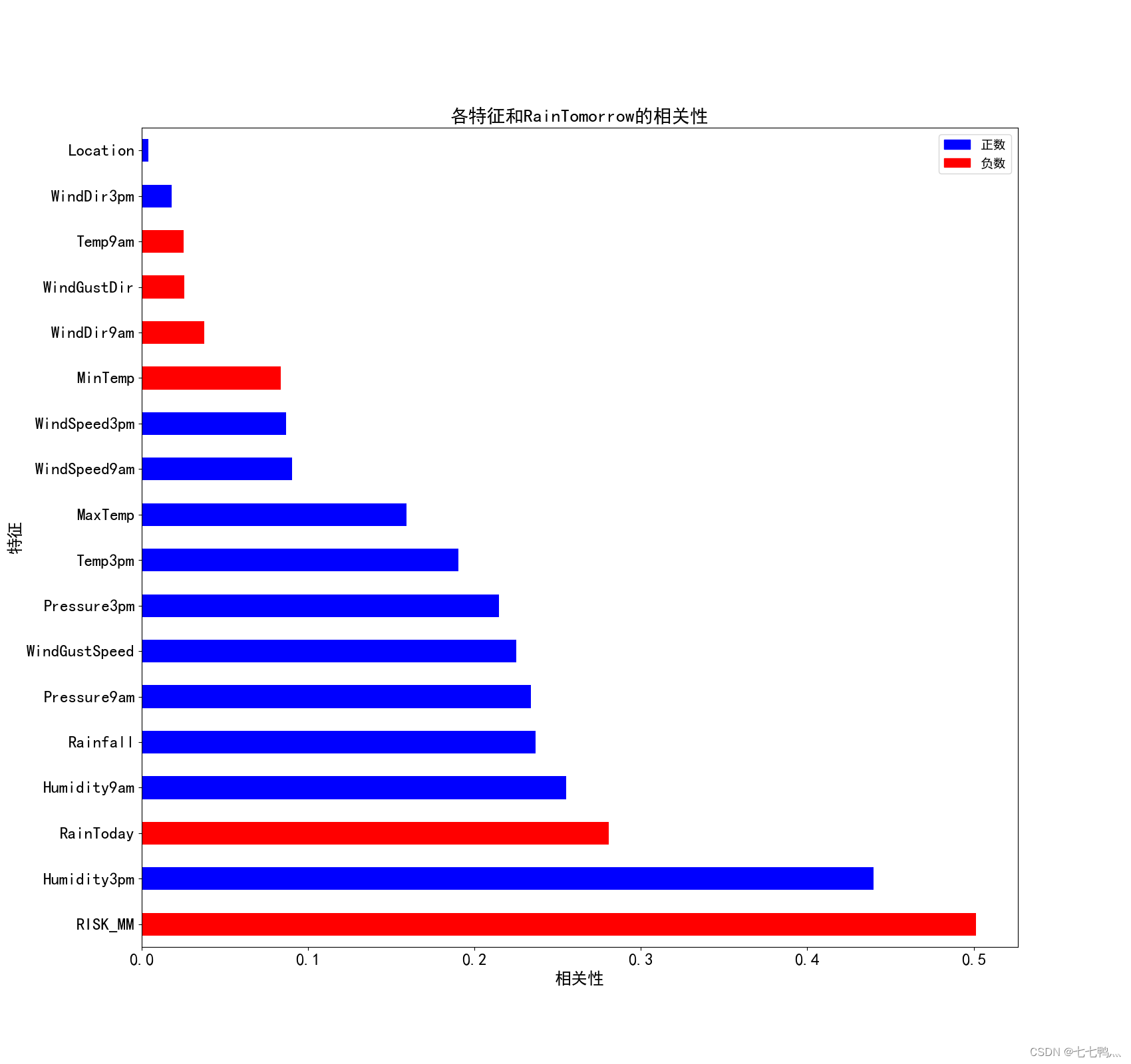
上面是各特征变量和RainTomorrow的相关性条形图,我们只保留相关性绝对值在0.2以上的特征
下面是可视化和筛选特征的代码
import pandas as pd
from matplotlib import pyplot as plt
# 读取标准化后的CSV文件
standardized_file_path = 'new_file_with_labelencoder.csv'
df_standardized = pd.read_csv(standardized_file_path)# 分离特征和目标变量
X = df_standardized.drop('RainTomorrow', axis=1)
y = df_standardized['RainTomorrow']### 数值特征的相关性分析# 相关性计算
correlation_matri = X.corrwith(y)print("\n数值特征与RainTomorrow的相关性:")
print(correlation_matri)# 设置matplotlib以支持中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False#字体大小设置
plt.rcParams['font.size'] = 14
plt.rcParams['axes.titlesize'] = 20
plt.rcParams['axes.labelsize'] = 18
plt.rcParams['xtick.labelsize'] = 18
plt.rcParams['ytick.labelsize'] = 18# 定义颜色映射并添加到图例
colors = {'正数': 'blue', '负数': 'red'}
handles = [plt.Rectangle((0,0),1,1, color=colors[label]) for label in colors]
labels = colors.keys()# 绘制横向条形图展示各特征与RainTomorrow的相关性
plt.figure(figsize=(17, 16)) # 调整图形大小以适应横向展示
correlation_matri.abs().sort_values(ascending=False).plot(kind='barh', color=['blue' if x > 0 else 'red' for x in correlation_matri.values], orientation='horizontal')
plt.axvline(x=0, color='k', linewidth=0.6) # 修改为垂直参考线
plt.title('各特征和RainTomorrow的相关性')
plt.xlabel('相关性')
plt.ylabel('特征')# 添加图例
plt.legend(handles, labels, loc='upper right')plt.show()# 筛选相关性绝对值大于等于0.2的特征
relevant_features = correlation_matri[abs(correlation_matri) >= 0.2]# 提取出满足条件的特征列名
selected_feature_names = relevant_features.index.tolist()# 保存相关性系数绝对值大于等于0.2的特征
selected_features_df = df_standardized[selected_feature_names + ['RainTomorrow']]new_file_path = 'features_above_correlation_threshold.csv'
selected_features_df.to_csv(new_file_path, index=False)
print(f"\n已保存到文件:{new_file_path}")最终得到的特征变量如下
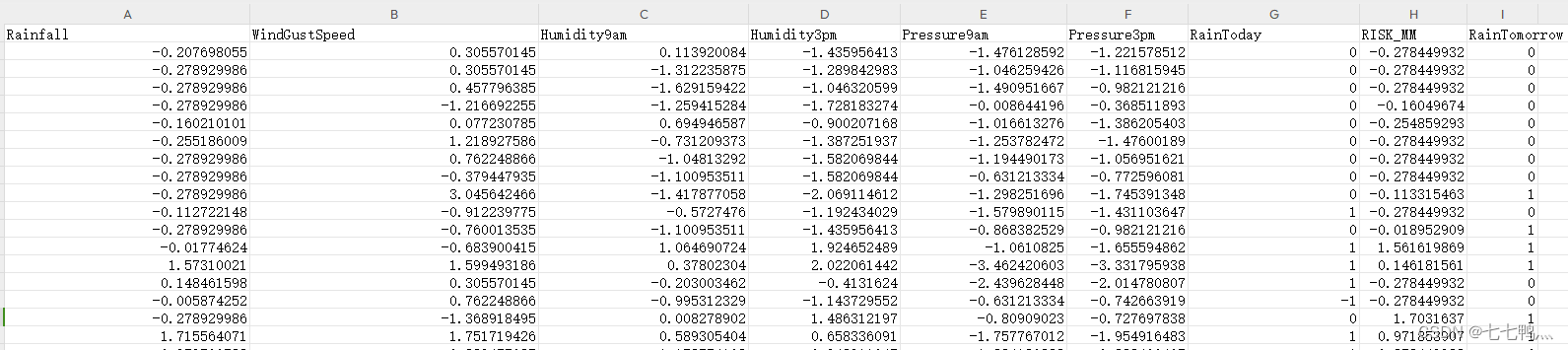
进一步处理缺失值
经过上面的相关性分析之后,我们筛选掉了大部分弱相关的特征,但是RainToday这个分类变量的相关性是比较高的,因此我们需要对其进行进一步的缺失值处理。
-
相关性分析
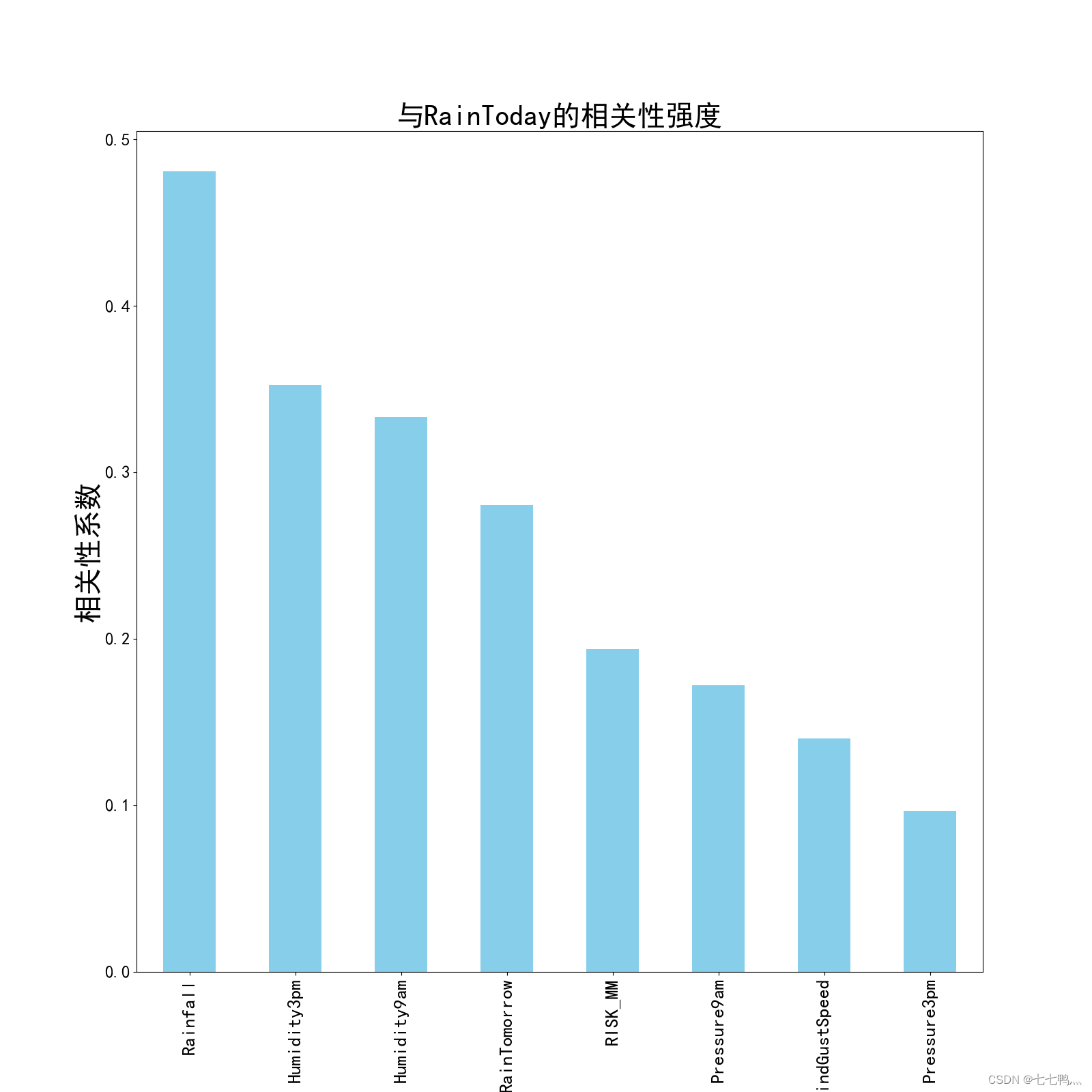
经过相关性分析,Rainfall、Humidity3pm、Humidityam这三个变量与RainToday有较强的相关性,我们将通过这三个变量去预测Rainfall的缺失值。
-
预测并填补缺失值
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False#字体大小设置
plt.rcParams['font.size'] = 18
plt.rcParams['axes.titlesize'] = 30
plt.rcParams['axes.labelsize'] = 30
plt.rcParams['xtick.labelsize'] = 20
plt.rcParams['ytick.labelsize'] = 18file_path = 'features_above_correlation_threshold.csv' # 请替换为您的输入CSV文件路径
df = pd.read_csv(file_path)
# 计算RainToday与其他所有特征的相关性
correlation_with_RainToday = df.corrwith(df['RainToday']).drop('RainToday')# 打印相关性结果
print("与RainToday的相关性:")
print(correlation_with_RainToday)# 可视化相关性
plt.figure(figsize=(16, 16))
correlation_with_RainToday.abs().sort_values(ascending=False).plot(kind='bar', color='skyblue')
plt.axhline(y=0, color='k', linestyle='--', linewidth=0.5)
plt.title('与RainToday的相关性强度')
plt.xlabel('特征')
plt.ylabel('相关性系数')
plt.show()# 假设我们选择了相关系数绝对值大于0.3的特征
strong_corr_features = correlation_with_RainToday[abs(correlation_with_RainToday) > 0.3].index.tolist()df['RainToday'] = df['RainToday'].replace(-1, np.nan)# 分离特征和目标变量,仅使用强相关特征
X_strong_corr = df[df['RainToday'].notnull()][strong_corr_features]
y_strong_corr = df[df['RainToday'].notnull()]['RainToday']# 划分训练集和验证集
X_train_strong, X_valid_strong, y_train_strong, y_valid_strong = train_test_split(X_strong_corr, y_strong_corr, test_size=0.2, random_state=42)# 训练逻辑回归模型
logreg = LogisticRegression(max_iter=1000)
logreg.fit(X_train_strong, y_train_strong)# 预测缺失值
missing_indices = df['RainToday'].isnull()
X_missing = df.loc[missing_indices, strong_corr_features]
predicted_RainToday = logreg.predict(X_missing)# 填补缺失值
df.loc[missing_indices, 'RainToday'] = predicted_RainTodayprint("缺失值已根据强相关特征预测并填补。")output_file_path = 'processed_data_with_imputed_values.csv' # 输出文件路径# 保存处理后的DataFrame到新的CSV文件
df.to_csv(output_file_path, index=False)print(f"处理后的数据已保存至: {output_file_path}")模型的训练和预测
然后就是使用常见的几种机器学习算法去进行训练和预测了,至于模型的超参数调整部分这里就不详细介绍了,后面单独开一篇文章来讲解。
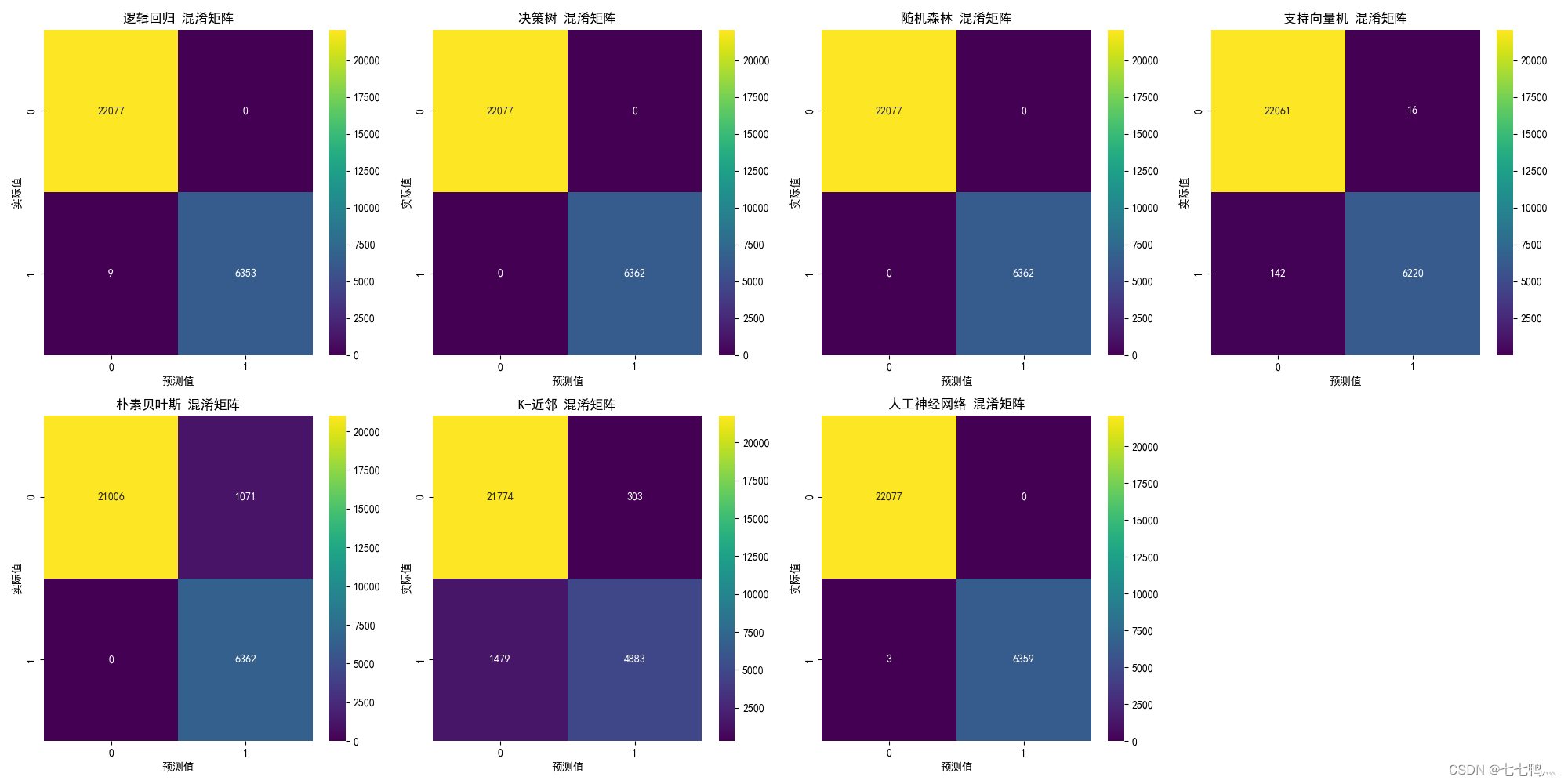
混淆矩阵
准确率和耗时比较
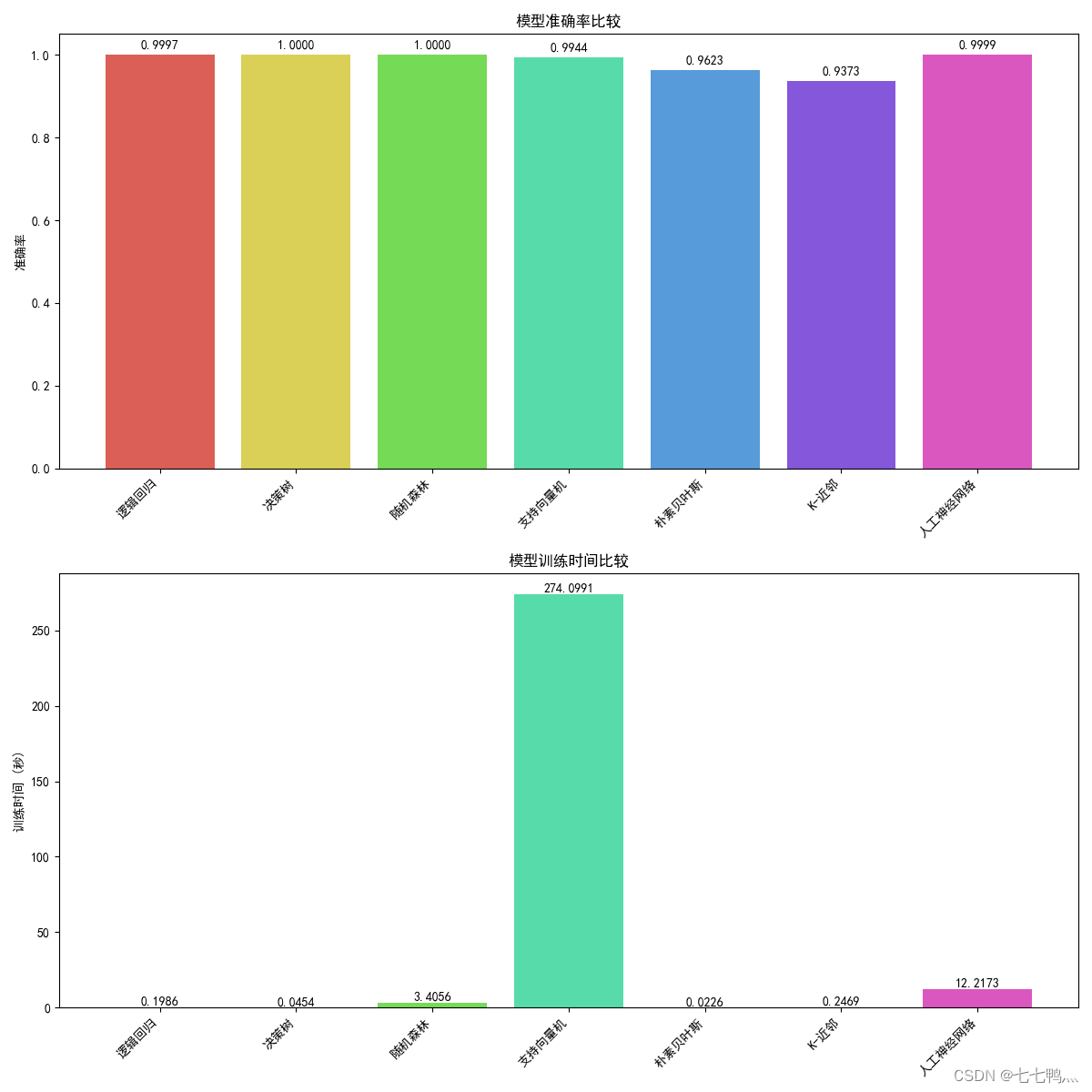
综合比较下来,使用决策树去进行下雨预测是最优解。
训练和预测的代码如下
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import seaborn as sns
import matplotlib.pyplot as plt
from time import perf_counter
# 读取CSV文件
# 读取CSV文件
file_path = 'processed_data_with_imputed_values.csv'
df = pd.read_csv(file_path)# 分离特征和目标变量
X = df.drop('RainTomorrow', axis=1) # 假设'RainTomorrow'是目标变量
y = df['RainTomorrow']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=77)# 定义一个函数来训练和评估模型并记录训练时间
def train_and_evaluate_with_time(model, name):start_time = perf_counter()model.fit(X_train, y_train)end_time = perf_counter()train_time = end_time - start_timey_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)conf_mat = confusion_matrix(y_test, y_pred)report = classification_report(y_test, y_pred, output_dict=True)print(f"{name}模型准确率: {accuracy}")print(f"{name}混淆矩阵:\n{conf_mat}")# print(f"{name}分类报告:\n{report}")return accuracy, train_time, report# 初始化模型列表
models = {"逻辑回归": LogisticRegression(max_iter=1000),"决策树": DecisionTreeClassifier(random_state=77),"随机森林": RandomForestClassifier(random_state=77),"支持向量机": SVC(probability=True),"朴素贝叶斯": GaussianNB(),"K-近邻": KNeighborsClassifier(),"神经网络": MLPClassifier(max_iter=1000, random_state=77)
}# 评估每种模型并收集结果
results_with_time = {}
for name, model in models.items():accuracy, train_time, report = train_and_evaluate_with_time(model, name)results_with_time[name] = {"Accuracy": accuracy, "Train Time": train_time,"Classification Report": report}# 设置matplotlib以支持中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False# 绘制混淆矩阵
ncols = min(len(models), 4)
nrows = -(-len(models) // ncols)
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(20, 10))for idx, (name, _) in enumerate(models.items()):row = idx // ncolscol = idx % ncolsax = axes[row, col] if ncols > 1 else axes[col]conf_mat = confusion_matrix(y_test, models[name].predict(X_test))sns.heatmap(conf_mat, annot=True, fmt='d', cmap='viridis', ax=ax)ax.set_title(f'{name} 混淆矩阵')ax.set_xlabel('预测值')ax.set_ylabel('实际值')for i in range(idx + 1, ncols * nrows):fig.delaxes(axes.flatten()[i])plt.tight_layout()
plt.show()# 绘制准确率和训练时间的条形图,并为每个条形指定不同颜色
color_palette = sns.color_palette("hls", len(results_with_time)) # 生成与模型数量相同的不同颜色fig, axs = plt.subplots(2, 1, figsize=(12, 12)) # 修改为1列2行的布局# 准确率条形图
for idx, (model_name, metrics) in enumerate(results_with_time.items()):accuracy_bar = axs[0].bar(model_name, metrics["Accuracy"], color=color_palette[idx])# 在条形图上方添加准确率数值axs[0].text(model_name, metrics["Accuracy"] + 0.01, f'{metrics["Accuracy"]:.4f}', va='bottom', ha='center')
axs[0].set_title('模型准确率比较')
axs[0].set_ylabel('准确率')
axs[0].set_xticklabels(results_with_time.keys(), rotation=45, ha="right") # 旋转x轴标签以避免重叠# 训练时间条形图
for idx, (model_name, metrics) in enumerate(results_with_time.items()):train_time_bar = axs[1].bar(model_name, metrics["Train Time"], color=color_palette[idx])# 在条形图上方添加训练时间数值axs[1].text(model_name, metrics["Train Time"] + 0.1, f'{metrics["Train Time"]:.4f}', va='bottom', ha='center')
axs[1].set_title('模型训练时间比较')
axs[1].set_ylabel('训练时间 (秒)')
axs[1].set_xticklabels(results_with_time.keys(), rotation=45, ha="right") # 旋转x轴标签以避免重叠plt.tight_layout()
plt.show()作者介绍
作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果你觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
尾言
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。