spark 整合 yarn
spark 整合 yarn
1、在master节点上停止spark集群
cd /usr/local/soft/spark-2.4.5/sbin
./stop-all.sh

2、spark整合yarn只需要在一个节点整合, 可以删除node1 和node2中所有的spark文件
分别在node1、node2 的/usr/local/soft目录运行
rm -rf spark-2.4.5/
3、 进入 /spark-2.4.5/conf目录,增加 hadoop 配置文件地址
cp /usr/local/soft/spark-2.4.5/conf
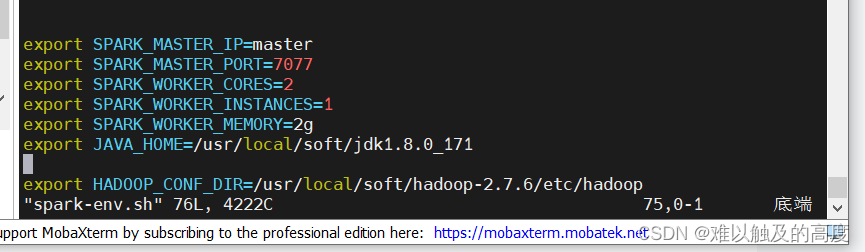
vim spark-env.sh
直接在文件最后加上
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop
4、 进入/usr/local/soft/hadoop-2.7.6/etc/hadoop目录,修改yarn-site.xml文件(往yarn提交任务需要增加两个配置)
先关闭yarn
stop-all.sh
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop
vim yarn-site.xml
在<configuration> </configuration>之间加上 :
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5、同步到其他节点
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop
scp -r yarn-site.xml node1:`pwd`
scp -r yarn-site.xml node2:`pwd`

再启动yarn
start-all.sh
master:50070 -- 检查HDFS
master:8088 -- 检查Yarn
6、测试
spark有两种模式 :
(1) standalone client模式 日志在本地输出,一般用于上线前测试(bin/下执行)
cd /usr/local/soft/spark-2.4.5/examples/jars
提交spark任务
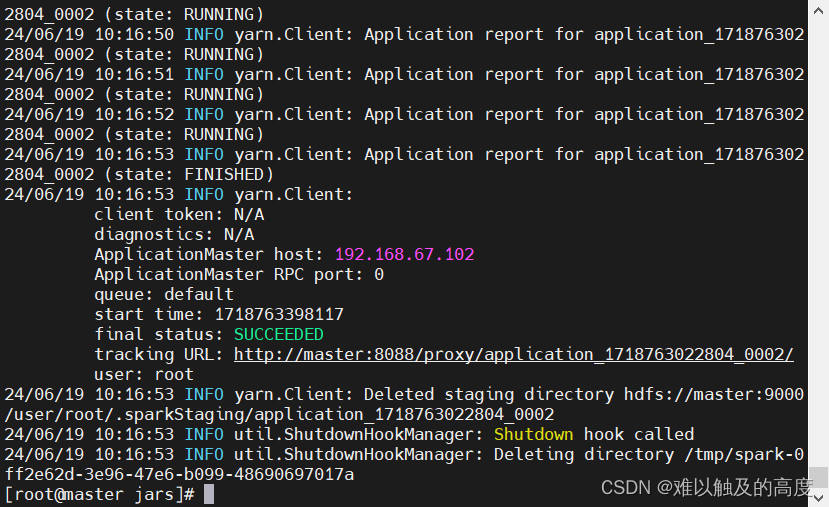
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client spark-examples_2.11-2.4.5.jar 100
(2) standalone cluster模式 上线使用,不会再本地打印日志 减少io
cd /usr/local/soft/spark-2.4.5/examples/jars
提交spark任务
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster spark-examples_2.11-2.4.5.jar 100
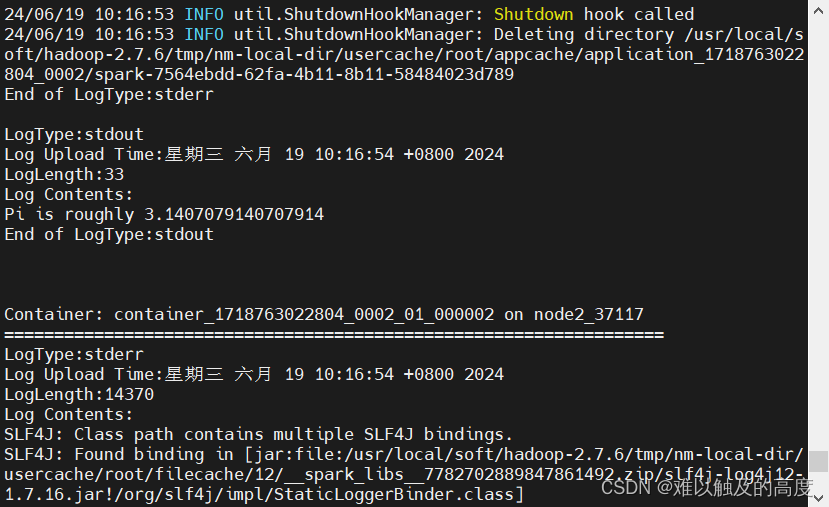
获取yarn程序 cluster模式 下的执行日志 , 执行成功之后才能获取到
yarn logs -applicationId application_1560967444524_0003