小知识点快速总结:Batch Normalization Layer(BN层)的作用
本系列文章只做简要总结,不详细说明原理和公式。
目录
- 1. 参考文章
- 2. 主要作用
- 3. 具体分析
- 3.1 正则化,降低过拟合
- 3.2 提高模型收敛速度,加速训练
- 3.3 减少梯度爆炸或者梯度消失的情况
- 4. 补充
- 4.1 BN层做的是标准化不是归一化
- 4.2 BN层的公式
- 4.3 BN层为什么要引入gamma和beta参数
1. 参考文章
[1] Sergey Ioffe, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”
[2] WellWang_S, “神经网络中BN层的原理与作用”
[3] 是Dream呀,“机器学习:BN层介绍及深入理解”
[4] 标准化和归一化,请勿混为一谈,透彻理解数据变换
[5] 针对:'‘标准化和归一化什么区别?’'问题,答主本空的回答
2. 主要作用
BN层主要是为了解决网络训练过程中出现的internal Covariate Shift(内部协方差偏移,简成ICS)问题。ICS问题会导致随着网络深度的加深,训练越来越困难,收敛越来越慢。
具体可以分为三个作用:
1.正则化,降低过拟合。
2.提高模型收敛速度,加速训练。
3.减少梯度爆炸或者梯度消失的情况。
在机器学习领域有个很重要的假设:独立同分布。即训练集和测试集必须具有相同的分布,这样经过训练的模型才能在测试集合上去的很好的表现。
但是,在网络的训练过程中,随着反向传播的进行,网络每一层的权重都会进行更新,这就导致每一层输入数据的分布由于上一层权重的更新而时刻改变[1]。 这种数据分布的变化也会随着网络的加深,而逐渐剧烈。使得网络深层很难进行学习。
并且原文[1]中也指出在网络的训练过程中,数据分布改变后会往激活函数的上限或者下限偏移,随着网络的层层加深,数据整体分布会逐渐偏移到激活函数的梯度饱和区域,出现梯度降低甚至消失现象,使得网络难以训练,无法收敛。
上面这种现象就被称为ICS问题。
那么BN的作用就显而易见了,就是将每个Batch内的数据分布都拉到均值为0,方差为1的标准正态分布,使得每一层神经网络的输入保持相同分布(博客[4]中说到,标准化不会改变原有分布,但是大部分数据都是正态分布,所以我也写成标准正态分布)
3. 具体分析
3.1 正则化,降低过拟合
我个人理解:首先网络过拟合说明网络对于训练集的数据分布学习的太好了,几乎完全一样了。这样会导致网络缺乏泛化性。BN层作为一种标准化方法,可以将所有的数据分布统一成标准正态分布,减少方差大的特征(离散特征)对于整体数据分布的影响[5], 从而让网络更加关注共性特征,降低对离散特征的学习,提高泛化性。
3.2 提高模型收敛速度,加速训练
在第二章中,我们提到网络之所以难以收敛,主要是因为ICS问题导致的数据分布偏移,从而出现激活函数梯度消失现象。从下图中(来自博客[5])可以看到,经过标准化后,数据都会集中在均值为0,方差为1的正太分布中,这个数据分布正好是激活函数中梯度响应最大的区域,可以有效地提高模型的收敛速度,加速模型训练。
| 原始数据 | 标准化后数据 |
|---|---|
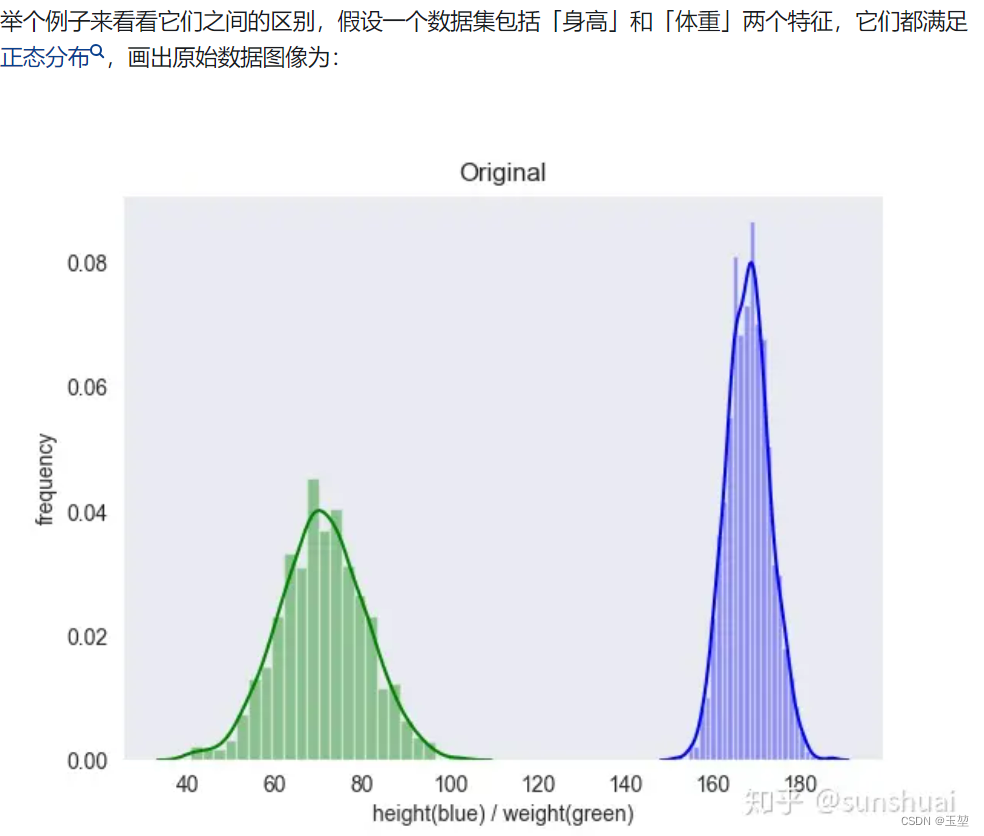 | 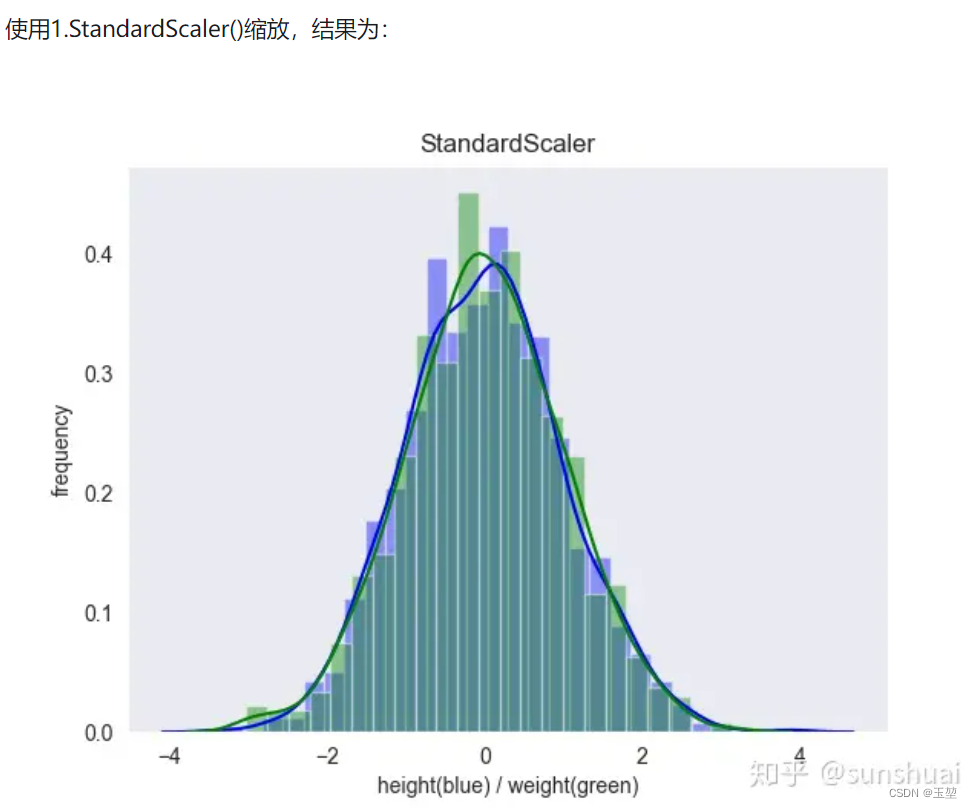 |
3.3 减少梯度爆炸或者梯度消失的情况
网络权重更新依据的是梯度的反向传递。梯度求解的主要受有4个因素影响,分别是:
- 当前层的输入(上一层的输出)。
- 激活函数的偏导。
- 后一层的权重。
- 损失函数L的偏导。
由于链式求导法则,梯度是不同层的4个因素的累乘。如果4个因素中设置不合理则会导致梯度爆炸或者梯度消失的现象。
BN层之所以会减少梯度爆炸或者梯度消失,因为BN层制约着激活函数的偏导这一因素。
当然BN层只能减轻,但无法完全解决。
例如:
第一种情况: 权重设置不合理,还是会导致梯度爆炸现象。
第二种情况: 如果采用sigmod激活函数,其最大梯度是0.25,如果网络设置过深,0.25的累乘会导致梯度越来越小,甚至梯度消失。
4. 补充
4.1 BN层做的是标准化不是归一化
BN层,也被称为Batch Normalization Layer。虽然被翻译为批次归一化层,但是从公式上看,BN层实际上实现的是标准化。不要被归一化这个翻译迷惑。结果并不是将数据缩放到0-1,然是将数据缩放到均值为0,方差为1的相同分布中。
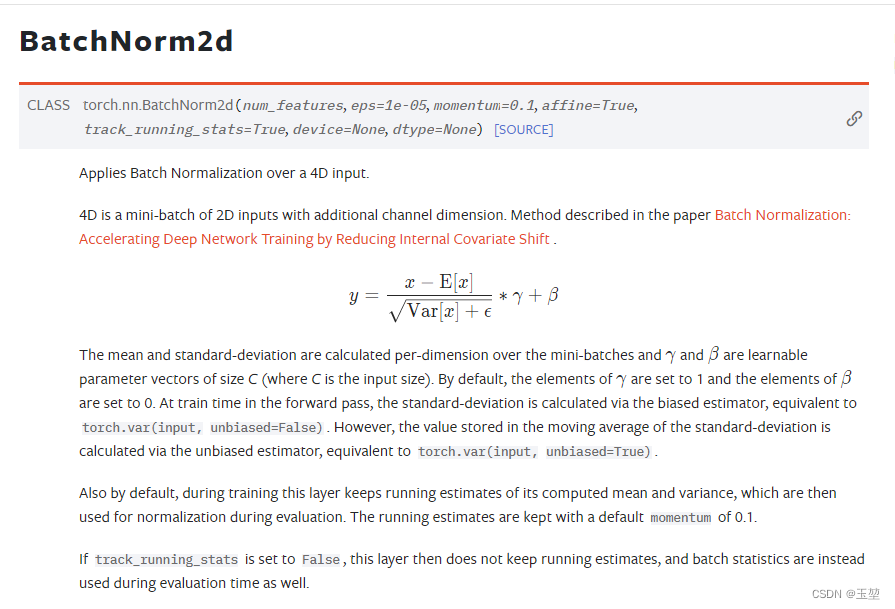
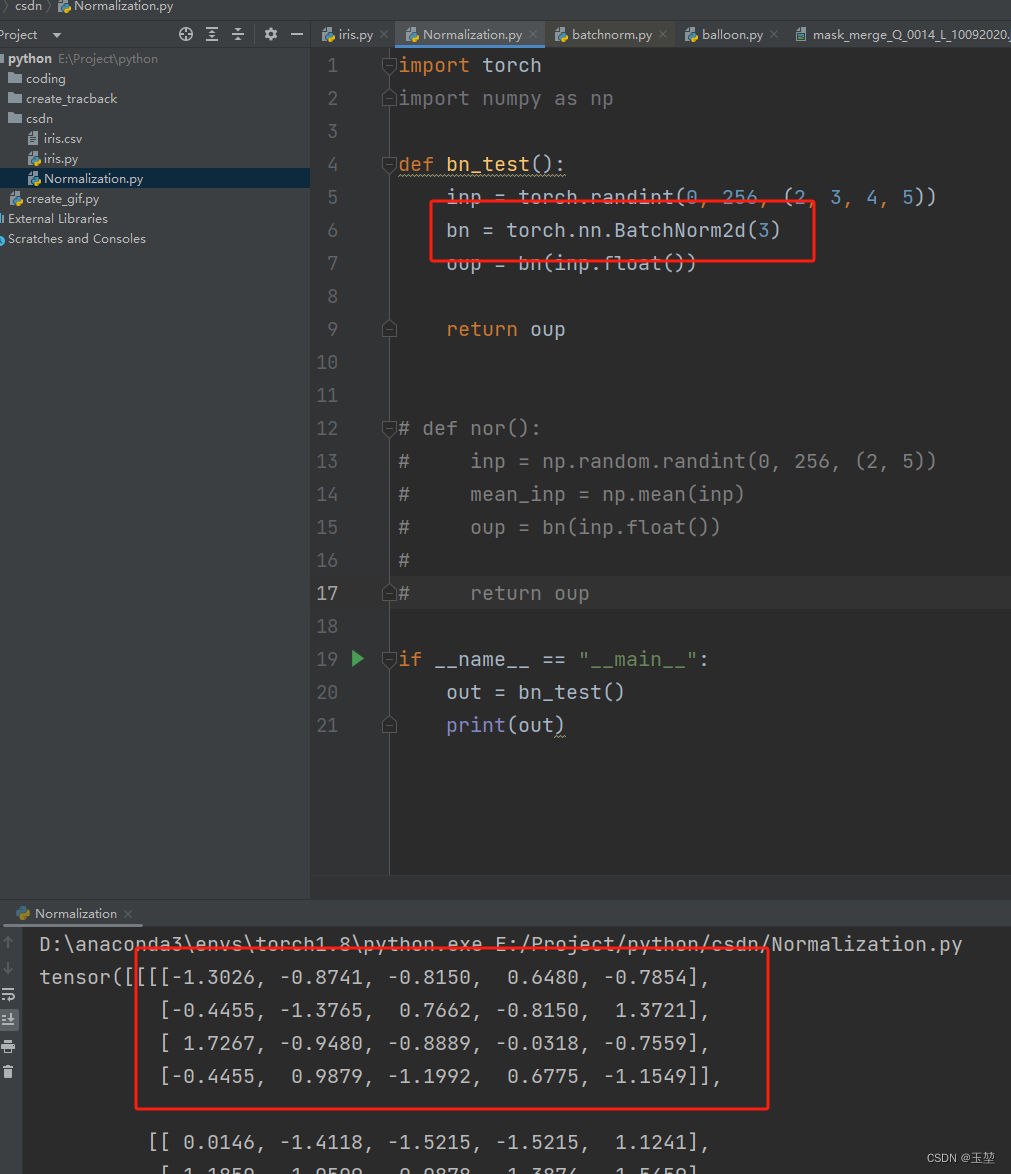
4.2 BN层的公式

4.3 BN层为什么要引入gamma和beta参数
截图自:[2] WellWang_S, “神经网络中BN层的原理与作用”,如需详细理解,可以去该作者文章中细读。
