Hadoop3:NameNode和DataNode多目录配置(扩充磁盘的技术支持)
一、NameNode多目录
1、说明
NameNode多目录,需要在刚搭建Hadoop集群的时候,就配置好
因为,配置这个,需要格式化NameNode
所以,如果一开始没配置NameNode多目录,后面,就不要配置了。
2、配置
1、修改配置
hdfs-site.xml
<property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
其中,dfs.namenode.name.dir这个参数在core-site.xml文件中配置的

配置好后,保存,分发。
2、停掉Hadoop集群
myhadoop stop
3、所有节点,删除/data、/log目录
cd /opt/module/hadoop-3.1.3/
rm -rf data/ logs/
4、格式化NameNode
hdfs namenode -format
此时,就已经有2个目录了
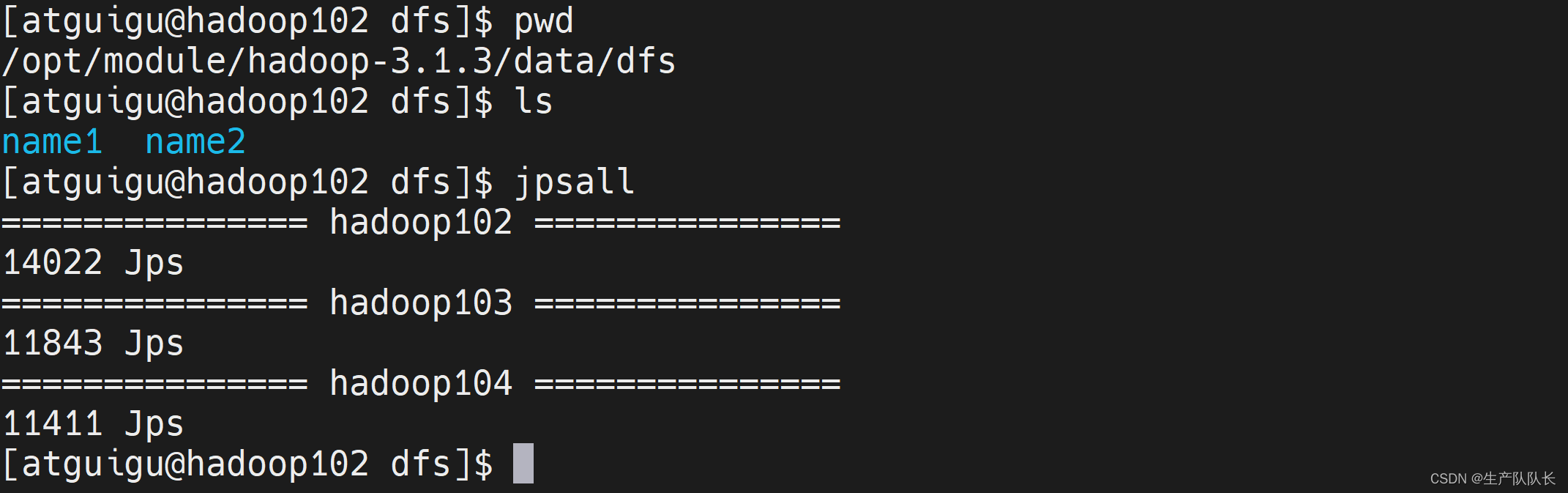
5、启动集群
myhadoop start
3、验证
name1目录
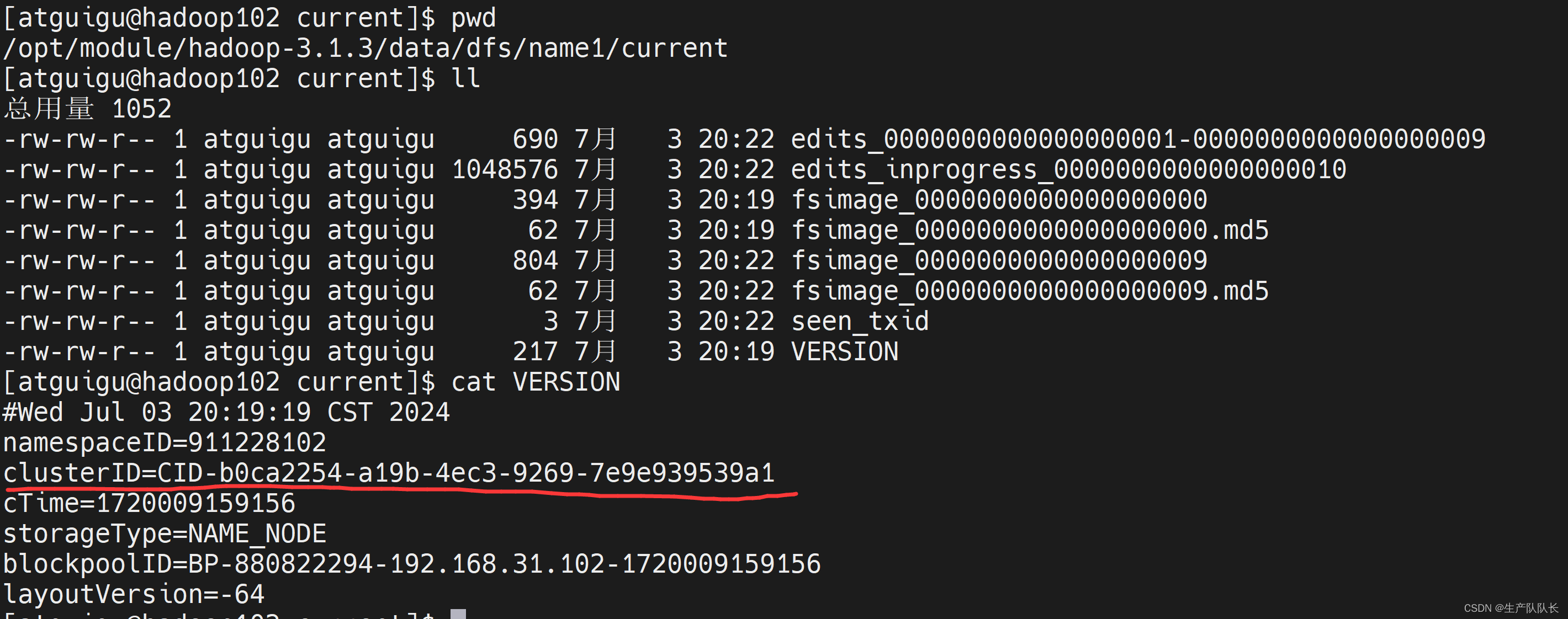
name2目录
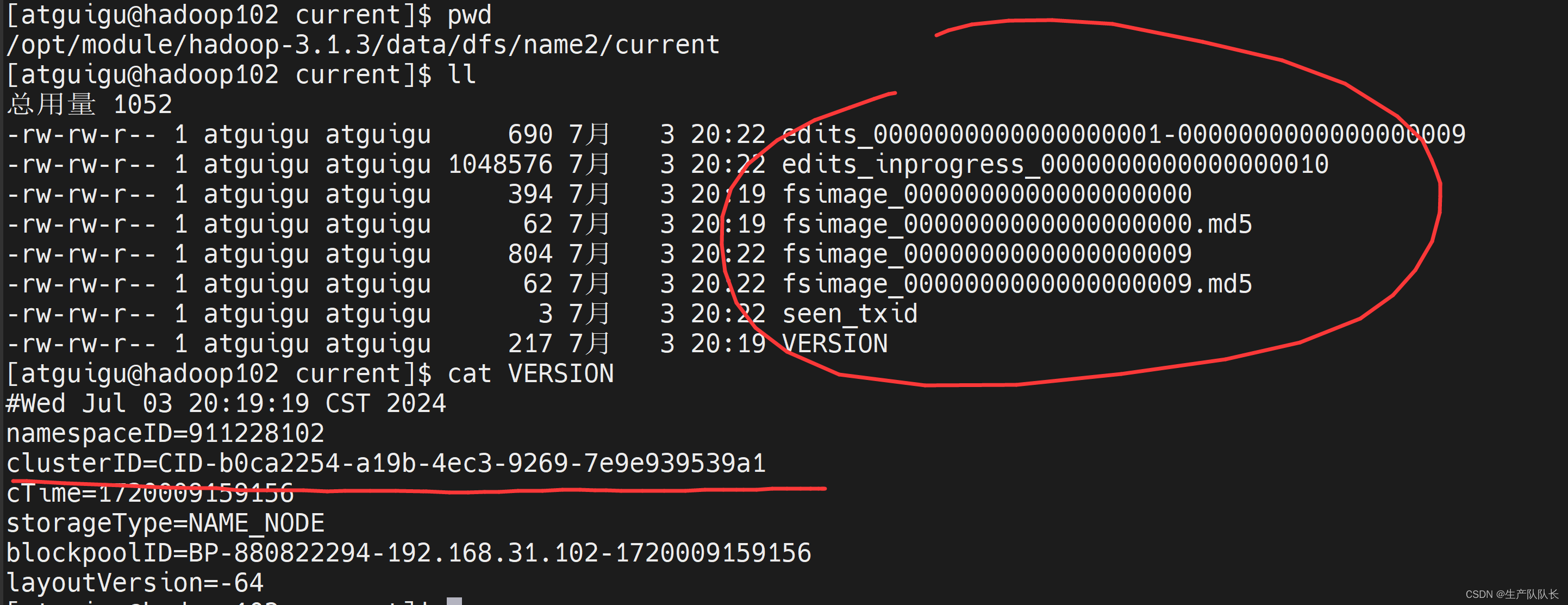
会发现,两个目录存储的内容完全一样
但是,本次实操,是在102一个节点上,所以,不是真正的高可用。
如果,102挂掉了,数据丢失。那么,依然无法恢复。
真正的高可用,是配置两个不同机器上的NameNode。
这个,最多是,防止误删,提高了一点安全性。
如果,看到多目录,就明白是怎么回事了。
二、DataNode多目录(重要)
1、说明
DataNode可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)
这个,为集群扩充磁盘提供了基础支持。
一般情况,服务器,挂载几块硬盘,就配置几个目录,对应关联。
2、配置
1、修改配置
hdfs-site.xml
<property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
这个配置,不一定要分发给所有的节点
要看每个节点的磁盘情况是否相同,来考虑是否分发。
我这里,三台机器情况完全相同,所以,分发到另外几台机器。
2、重启集群
myhadoop stop
myhadoop start
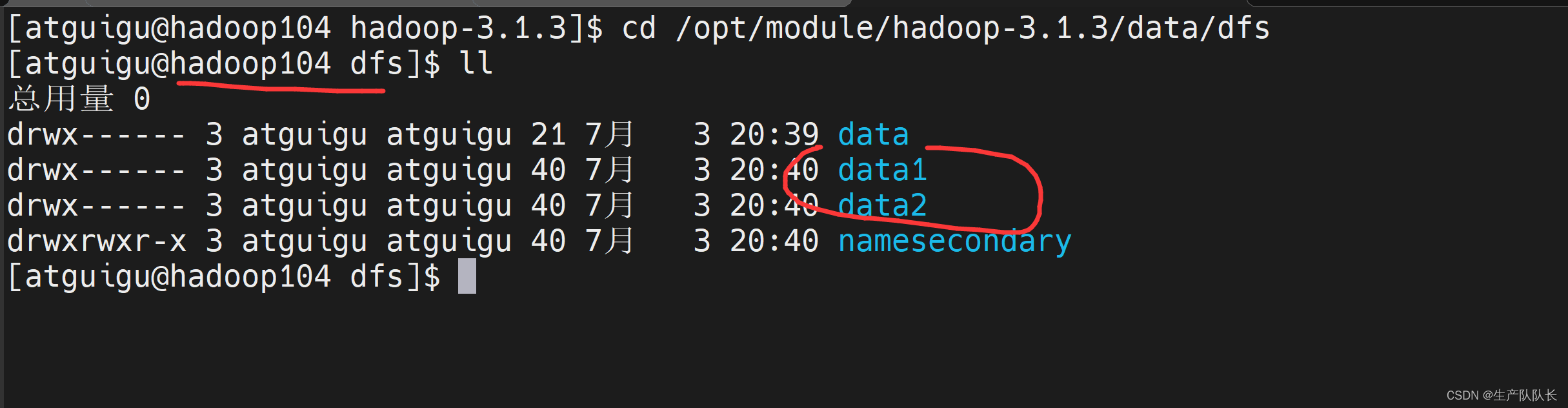
3、验证
三个节点都有两个目录。
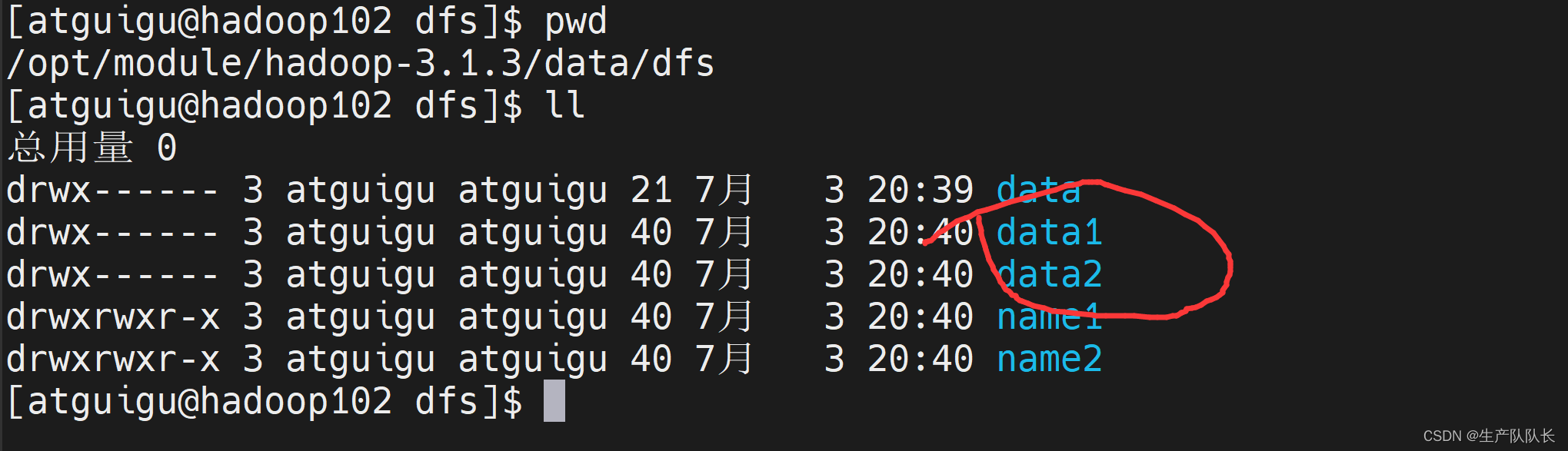

4、数据均衡(重要)
经过上面的配置,我们就可以挂载信申请的磁盘了。
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。
刚加载的硬盘没有数据时,可以执行磁盘数据均衡命令。(Hadoop3.x新特性)
对应命令:
(1)生成均衡计划(我只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json