Apache DolphinScheduler Worker Task执行原理解析
大家好,我是蔡顺峰,是白鲸开源的高级数据工程师,同时也是Apache DolphinScheduler社区的committer和PMC member。今天我要分享的主题是《Worker Task执行原理》。

整个分享会分为三个章节:
- Apache DolphinScheduler的介绍
- Apache DolphinScheduler的整体设计背景
- Worker任务的具体执行过程
项目介绍
Apache DolphinScheduler是一个分布式、易扩展的可视化工作流调度开源系统,适用于企业级场景。
它提供了以下主要功能,通过可视化操作,提供了工作流和任务全生命周期的数据处理解决方案。
主要特性
简单易用
- 可视化DAG操作:用户可以在页面上通过拖拉拽来编排不同的组件,形成DAG(有向无环图)。
- 插件化体系:包括任务插件、数据源插件、告警插件、存储插件、注册中心插件和定时任务插件等。用户可以根据需要方便地进行插件扩展,以适应自己的业务需求。
丰富的使用场景
- 静态配置:包括工作流定时配置、上线下线操作、版本管理和补数功能。
- 运行态操作:提供了暂停、停止、恢复和参数替换等功能。
- 依赖类型:支持丰富的依赖选项和策略,适应更多场景。
- 参数传递:支持工作流级别的启动参数、全局参数、任务级别的本地参数和动态传参。
高可靠性
- 去中心化设计:各个服务均为无状态,可以水平扩展节点,提高系统的吞吐能力。
- 过载保护和实例容错:
- 过载保护:在运行过程中,master和worker会检测自身的CPU和内存使用情况,以及任务量。如果过载,会暂停本轮工作流/任务的处理分发,等恢复后再继续处理。
- 实例容错:当master/worker节点挂掉时,注册中心会感知服务节点下线,并对工作流实例或任务实例进行容错处理,尽量保证系统的自恢复能力。
整体设计背景
项目架构
下面介绍一下整体的设计背景,以下是官网提供的设计架构图。
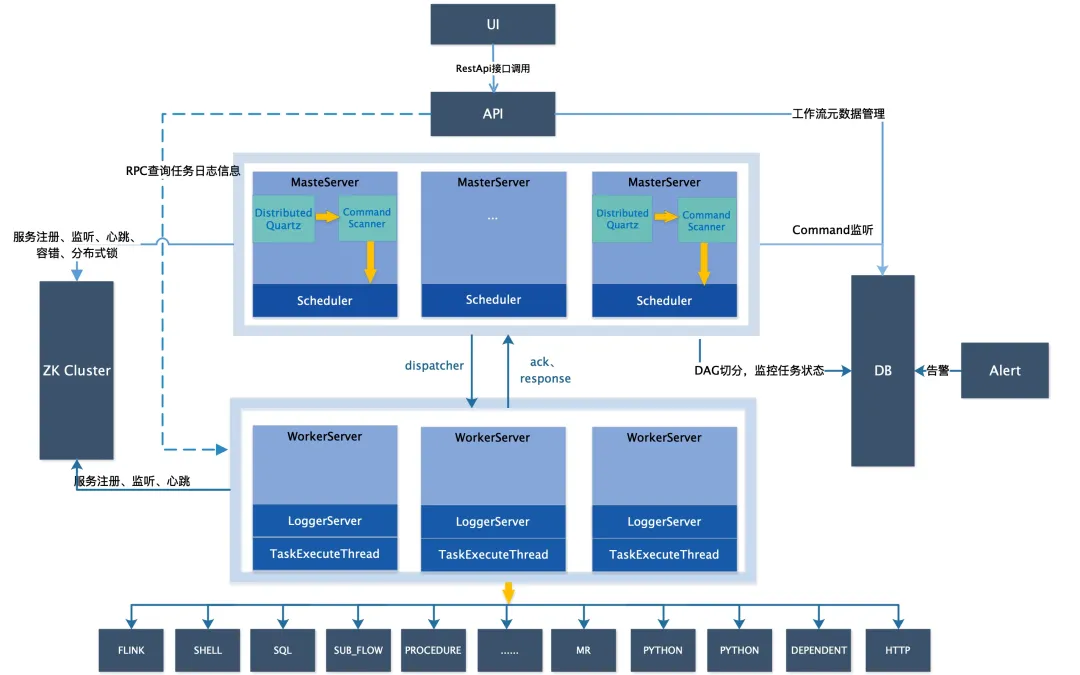
从架构图中我们可以看到,Apache DolphinScheduler由几个主要组件构成:
- API组件:API服务主要负责元数据管理,通过API服务与UI交互,或通过API接口调用来创建工作流任务,以及工作流所需的各种资源。
- Master组件:Master是工作流实例的掌管者,负责消费命令并转换为工作流实例,进行DAG的切分,按顺序提交任务,并将任务分发给worker。
- Worker组件:Worker是具体的任务执行者。收到任务后,按不同任务类型进行处理,并与Master交互,回传任务状态。值得一提的是,Worker服务不与数据库交互,只有API、Master和Alert这三个服务与数据库交互。
- 告警服务:告警服务通过不同的告警插件发送告警信息。这些服务会注册到注册中心,Master和Worker会定期上报心跳和当前状态,确保能正常接收任务。
Master和Worker的交互过程
Master和Worker的交互过程如下:
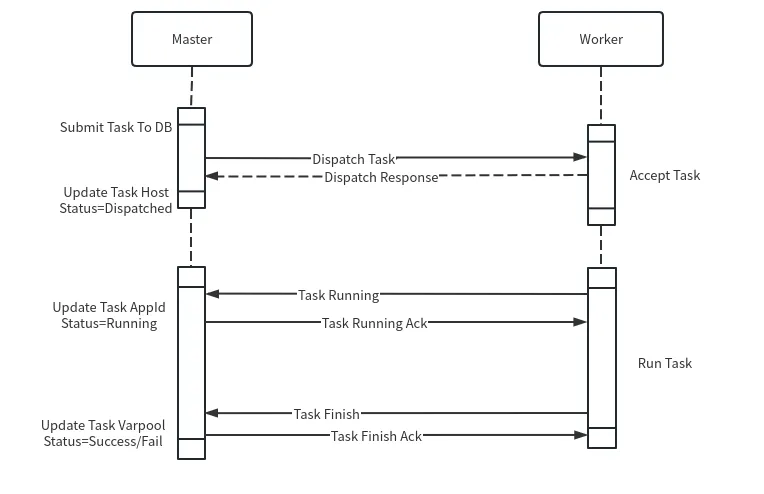
任务提交:Master完成DAG切分后,将任务提交到数据库,并根据不同的分发策略选择合适的Worker分组进行任务分发。
任务接收:Worker接收到任务后,查看自身情况决定是否接收任务。接收成功或失败都会有反馈。
任务执行:Worker处理任务,并将状态更新为running,回馈给Master。Master更新任务的状态和启动时间等信息到数据库。
任务完成:任务执行完毕后,Worker发送finish事件通知Master,Master返回ACK确认。如果没有ACK,Worker会不断重试,确保任务事件不丢失。
Worker接收任务
Worker接收任务时会进行以下操作:
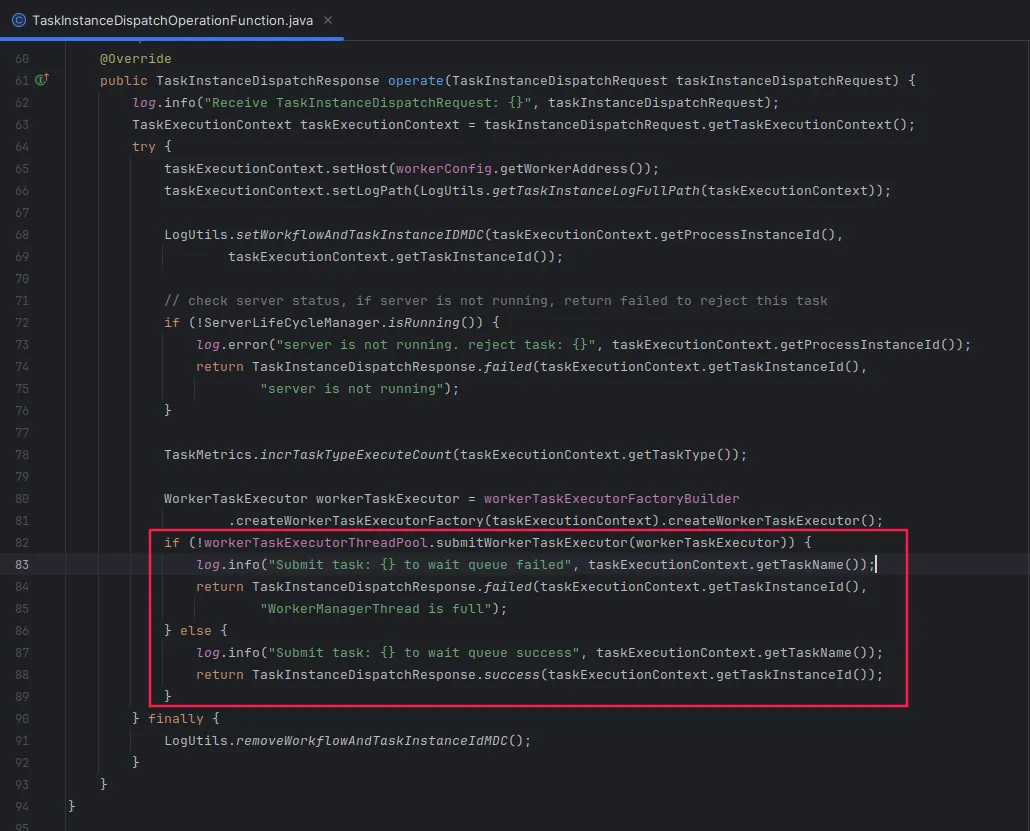
- 填充自己的host信息。
- 生成Worker机器上的日志路径。
- 生成Worker Task Executor,将其提交到线程池中等待执行。
Worker会判断自身是否过载,如果过载会拒收任务。Master接收到任务分发失败的返回后,会根据分发策略继续选择其他Worker进行任务分发。
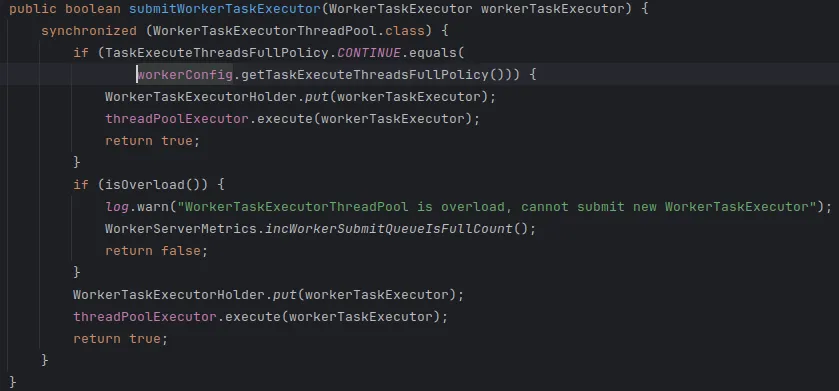
Worker 执行过程
Worker任务的具体执行过程包括以下几个步骤:
- 任务初始化:初始化任务所需的环境和依赖。
- 任务执行:执行具体的任务逻辑。
- 任务完成:任务执行完成后,向Master节点汇报任务的执行结果。
接下来我们详细讲解任务的具体执行过程。
在任务执行开始之前,首先会初始化一个上下文(context)。此时会设置任务的开始时间(start time)。为了保证任务的准确性,需要确保Master和Worker之间的时间同步,避免时间漂移。随后,将任务状态设置为running,并回馈给Master,告知任务开始运行。
由于大部分任务运行在Linux操作系统上,因此需要进行租户和文件的处理:
- 租户处理:首先判断租户是否存在。如果不存在,则根据配置决定是否自动创建租户。这需要部署用户具有sudo权限,以便在执行任务时切换到指定租户。
- 特定用户:对于某些场景,不需要切换租户,只需使用特定用户执行任务。此种情况下,系统同样支持。
处理完租户后,Worker会创建具体的执行目录。执行目录的根目录是可配置的,并需要进行相应的授权。默认情况下,目录的权限设置为755。
任务在执行过程中可能需要使用各种资源文件,例如从AWS S3或HDFS集群中拉取文件。系统会将这些文件下载到Worker的临时目录中,供后续任务使用。
在Apache DolphinScheduler中,支持对参数变量进行替换。主要包括以下两类:
- 内置参数:主要涉及时间和日期相关的参数替换。
- 用户自定义参数:用户在工作流或任务中设置的参数变量,也会进行相应的替换。
通过上述步骤,任务的执行环境和所需资源都已准备就绪,接下来便可正式开始任务的执行。
不同类型的任务
在Apache DolphinScheduler中,我们支持多种类型的任务,每种任务类型适用于不同的场景和需求。下面我们详细介绍几大类任务类型及其具体组件。
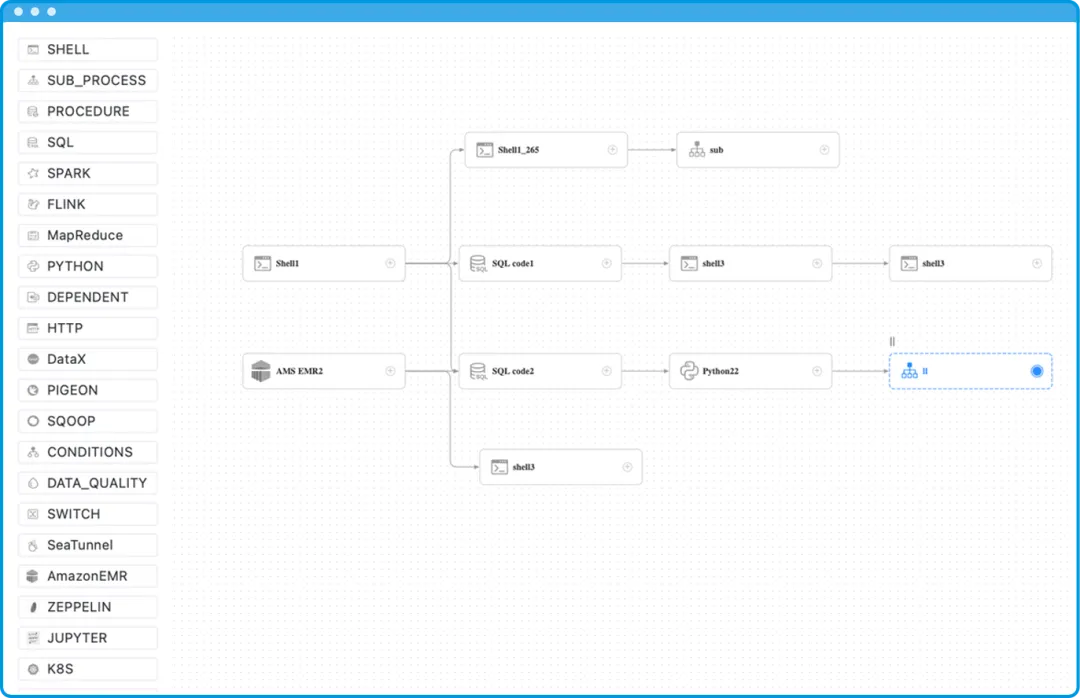
这些组件常用于执行脚本文件,适用于各种脚本语言和协议:
- Shell:执行Shell脚本。
- Python:执行Python脚本。
- SQL:执行SQL语句。
- 存储过程:执行数据库存储过程。
- HTTP:进行HTTP请求。
其商业版还支持通过执行JAR包来运行Java应用程序。
逻辑任务组件
这些组件用于实现任务的逻辑控制和流程管理:
- Switch:条件控制任务。
- Dependent:依赖任务。
- SubProcess:子任务。
- NextLoop(商业版):适用于金融场景的循环控制任务。
- Trigger组件:用于监听文件、数据是否存在。
大数据组件
这些组件主要用于大数据处理和分析:
- SeaTunnel:对应着商业版WhaleTunnel,用于大数据集成处理。
- AWS EMR:Amazon EMR集成。
- HiveCli:Hive命令行任务。
- Spark:Spark任务。
- Flink:Flink任务。
- DataX:数据同步任务。
容器组件
这些组件用于在容器环境中运行任务:
- K8S:Kubernetes任务。
数据质量组件
用于确保数据质量:
- DataQuality:数据质量检查任务。
交互组件
这些组件用于与数据科学和机器学习环境进行交互:
- Jupyter:Jupyter Notebook任务。
- Zeppelin:Zeppelin Notebook任务。
机器学习组件
这些组件用于机器学习任务的管理和执行:
- Kubeflow:Kubeflow任务。
- MlFlow:MlFlow任务。
- Dvc:Data Version Control任务。
整体来看,Apache DolphinScheduler支持三四十个组件,涵盖了从脚本执行、大数据处理到机器学习等多个领域。如果有兴趣了解更多,请访问官网查看详细文档。
任务类型的抽象
在Apache DolphinScheduler中,任务类型被抽象成多种不同的处理模式,以适应各种不同的运行环境和需求。
下面我们详细介绍任务类型的抽象和执行过程。
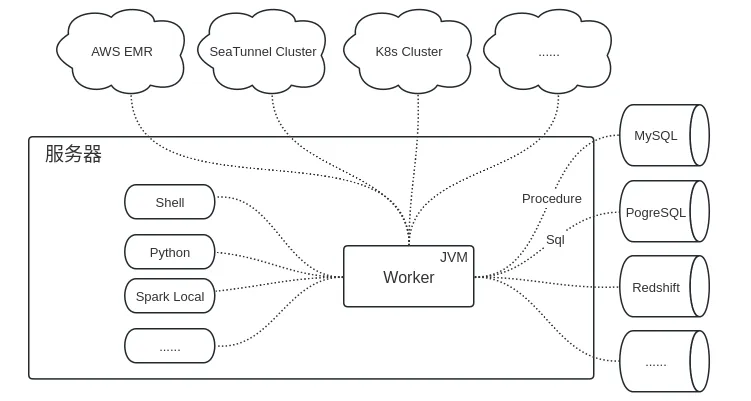
Worker是一个JVM服务,部署在某个服务器上。对于一些脚本组件(如Shell、Python)和本地运行的任务(如Spark Local),它们会起一个单独的进程运行。
此时,Worker与这些任务的交互通过进程ID(PID)进行。
不同的数据源可能需要不同的适配处理。针对SQL和存储过程任务,我们做了面向不同数据源的抽象。
例如,MySQL、PostgreSQL、AWS Redshift等。通过这种抽象,可以灵活地适配和扩展不同的数据库类型。
远程任务指的是在远程集群上运行的任务,如AWS EMR、SeaTunnel集群、Kubernetes集群等。Worker不会在本地执行这些任务,而是向远程集群提交任务,并监听其状态和消息。这种模式适用于云环境的扩展。
任务执行
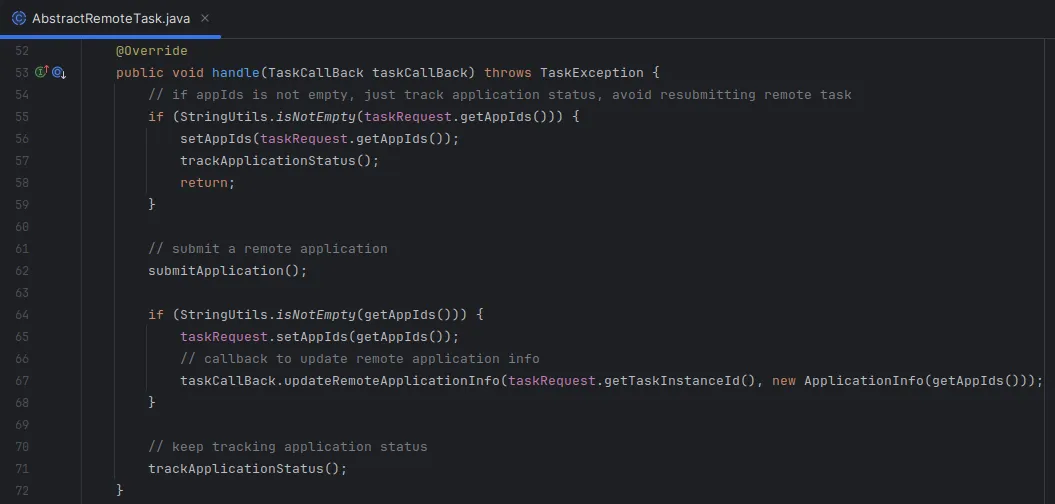
日志收集
不同插件会走不同的处理模式,因此日志收集也有所不同:
- 本地进程:监听进程的输出,记录日志。
- 远程任务:定期检查远程集群(如AWS EMR)的任务状态和输出,将其记录到本地的任务日志中。
参数变量替换
系统会扫描任务日志,查找需要动态替换的参数变量。例如,DAG中的任务A可能会生成一些输出参数,这些参数需要传递给下游的任务B。
在此过程中,系统会读取日志并替换参数变量。
获取任务ID
- 本地进程:获取进程ID(PID)。
- 远程任务:获取远程任务的ID(如AWS EMR任务ID)。
持有这些任务ID,可以进行更多的数据查询和远程任务操作。例如,在工作流停止时,可以通过任务ID调用对应的取消接口,停止正在运行的任务。
容错处理
- 本地进程:如果Worker节点挂掉,本地进程将无法感知,需要重新提交任务。
- 远程任务:如果任务运行在远程集群(如AWS),则可以通过任务ID检查远程任务的状态,并尝试接管任务。如果能接管,则无需重新提交任务,节省时间成本。
执行结束
当任务执行完毕后,需要进行一系列结束动作:
任务完成后,系统会检查是否需要发送告警。例如,对于SQL任务,如果查询结果需要发送告警,系统会通过RPC与告警服务(alert)交互发送告警信息。
Worker会将任务的完成事件(finish事件)回馈给Master。Master更新任务状态到数据库,并进行DAG状态流转。Worker会将任务开始时创建的上下文从内存中移除。清理任务执行过程中生成的文件路径。如果处于调试模式(开发模式),这些文件不会被清理,保留以便调试失败任务。
通过上述步骤,任务实例的整个执行流程就完成了。
社区贡献
如果您对Apache DolphinScheduler感兴趣,并希望为开源社区做贡献,欢迎参考我们的贡献指南。社区非常欢迎大家积极贡献,包括但不限于:
- 提出使用过程中的issue
- 提交文档和代码PR
- 补充单元测试(UT)
- 添加代码注释
- 修复bug或添加新特性
- 撰写技术文章或进行讲座
新手贡献者指南
对于新手贡献者,可以在社区的GitHub issue中搜索标签为good first issue的问题。这些问题通常比较简单,适合初次贡献的用户。
白鲸开源 DataOPS 介绍
白鲸开源是一家开源原生的 DataOPS 商业公司,由多个Apache基金会成员创立。公司主要参与贡献了两个Apache开源项目,一个是Apache DolphinScheduler,另一个是Apache SeaTunnel。基于这两个项目,我们打造了一个商业产品——WhaleStudio。
WhaleStudio 介绍
WhaleStudio是一个分布式云原生并且带有强大可视化界面的 DataOPS 系统,增强了商业客户所需的企业级特性。它结合了调度和数据同步的可视化,能够无缝衔接,并低代码实现企业大数据操作系统和高速公路。
主要特性
调度和数据同步可视化结合
- 无缝衔接,低代码实现企业大数据操作系统和高速公路。
集成工具支持
- 商业版对接了GitLab等集成工具,完善了DataOPS流程。
丰富的数据源对接
- 支持更多的数据源和传统ETL数据组件,如Informatica。
完善的权限控制
- 提供细粒度的角色和权限分配和控制。
审计系统和新创环境适配
- 提高安全性和可观测性。
工作流和任务实例操作优化
- 提高操作性能和数据完整性,增强运维能力。
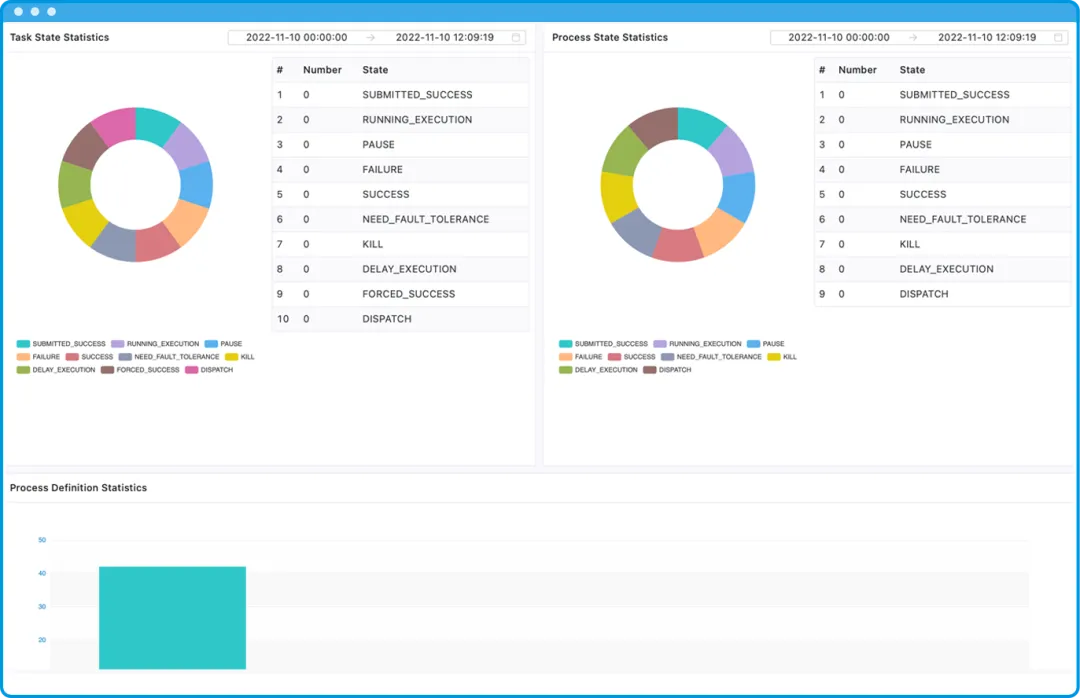
产品界面
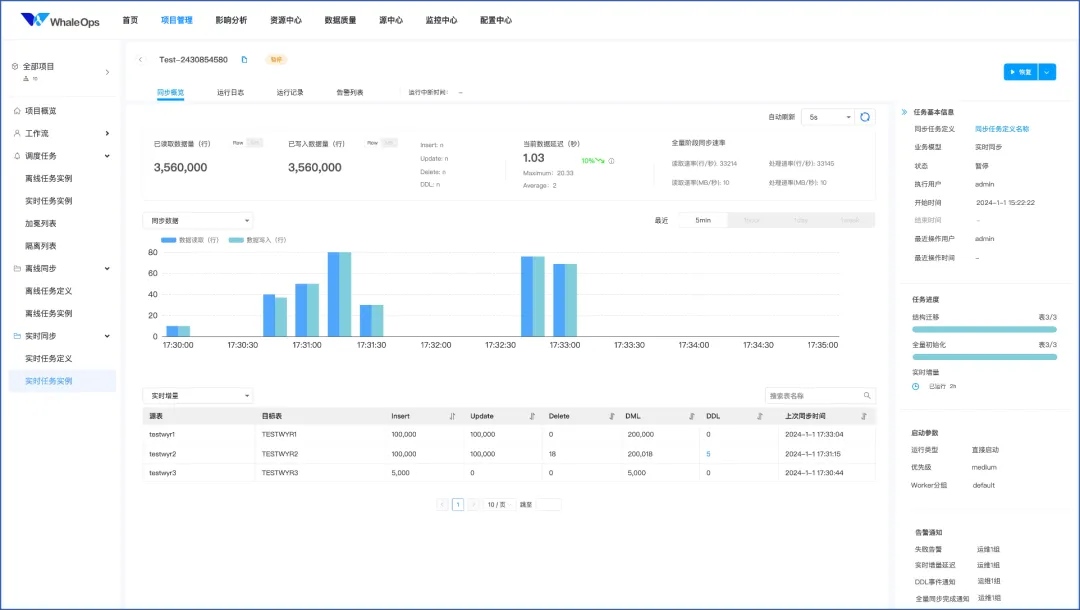
下图展示了我们DataOPS系统中的实时任务实例界面。可以看到界面提供了详细的数据和面板,帮助用户更好地管理和监控任务。
通过今天的分享,我们了解了Apache DolphinScheduler的项目介绍、整体设计背景以及Worker任务的具体执行过程。
希望这些内容能够帮助大家更好地理解和使用Apache DolphinScheduler。如果大家有任何问题,欢迎随时与我交流。谢谢大家!
本文由 白鲸开源科技 提供发布支持!