[CR]厚云填补_SEGDNet
Structure-transferring edge-enhanced grid dehazing network
Abstract
在过去的二十年里,图像去雾问题在计算机视觉界受到了极大的关注。在雾霾条件下,由于空气中水汽和粉尘颗粒的散射,图像的清晰度严重降低,使得许多计算机视觉系统,如用于物体检测、物体识别、监视、驾驶辅助等的计算机视觉系统难以进行进一步的处理和操作。然而,以往的除雾方法通常存在亮度差、偏色、去除不清洁、光晕、伪影和模糊等缺点。为了解决这些问题,本研究提出了一种新的结构转移边缘增强网格去雾网络(SEGDNet)。采用一种保持边缘的平滑算子—引导滤波器,有效地将图像分解为低频图像结构和高频边缘。提出了低频网格除雾子网络(LGDSn),在除雾过程中有效地保留了网格的低频结构。提出了高频边缘增强子网络(HEESn),在去除噪声的同时增强边缘和细节。采用低频和高频融合子网(L&HFSn)对低频和高频结果进行融合,得到最终去雾图像。在合成和真实世界数据集上的实验结果表明,我们的方法在定性和定量评估方面都优于最先进的方法。
1 Introduction
雾霾是一种常见的大气现象。灰尘、烟雾、棉绒和其他空气中的颗粒会降低大气的清晰度,并在摄影中造成问题,在摄影中,允许光线穿透大气是可视化远处物体所必需的。物体对比度下降的视觉效果是由于光通过雾粒散射的影响造成的。在过去的几十年里,图像去雾问题在计算机视觉界受到了广泛的关注。图像去雾的目的是为了恢复由于雾霾、难以检测等原因造成的不清晰图像。该技术有助于减轻天气、环境等因素引起的图像失真对各种计算机视觉分析任务的影响,对于开发强大的计算机视觉系统,如行人检测、反射去除、眼中心定位、目标检测等领域的计算机视觉系统具有重要意义。由于这些原因,摄影和计算机视觉应用需要去除雾霾的技术。
除雾是一个具有挑战性的问题,因为通过雾霾的光透射程度取决于未知的深度,而深度因位置而异。各种图像增强技术已经被用于从单幅图像中去除雾霾,包括基于直方图的、基于对比度的和基于饱和度的去雾。此外,其他研究也提出了使用多幅图像或深度信息的方法。例如,基于偏振的方法通过拍摄多幅不同偏振度的图像来消除雾霾的影响。基于对比的方法采用了多个约束条件,在不同天气条件下捕获同一场景的多幅图像。基于深度的方法需要来自用户输入或已知3D模型的深度信息。在实际应用中,深度信息或多幅朦胧图像并不总是可用的。
对于计算机来说,从单个图像中去除雾霾是一项艰巨的任务。相比之下,人类大脑可以在没有额外信息的情况下迅速从自然场景中区分出有雾和无雾的区域。研究人员已经提出了几种去雾霾图像的方法,从传统的图像增强方法到之前简单地通过大气散射模型近似雾霾的方法,估计图像各个部分的雾霾浓度,以及现代更流行的机器学习方法。根据卷积神经网络(convolutional neural networks, cnn)在行人检测、眼中心定位、物体检测等高级计算机视觉任务中的成功经验,近年来出现了一些基于卷积神经网络的方法。深度学习方法已被提出用于图像绘制或超分辨率等任务。然而,这些深度学习方法在应用于单图像处理时往往存在缺陷。
具体来说,许多深度学习图像绘制方法需要使用合成数据集进行训练。为了创建这样的数据集,必须有一个相应的图像失真的物理模型(例如,霾的大气散射模型)。一个明显的问题是,图像绘制算法本身的设计是否应该依赖于这个物理模型。显然,由于模型不匹配,依赖于模型的算法在实际图像处理中可能表现不佳。然而,这个模型创建的数据集的好处是,它可以生成许多图像,而不需要在相同的条件下拍摄两张前后失真的照片。除了数据集的问题外,单幅图像的去雾通常会导致雾霾厚度的估计不准确,去雾后的整体图像太暗,或者可能会有严重的颜色失真,降低输出图像的质量,大量或部分雾霾没有被清除干净,晕伪影出现在物体的边缘等。因此,我们在本研究中提出了一种新型的结构转移边缘增强网格去雾网络(SEGDNet)来解决上述问题,以达到更好的去雾效果,使被雾霾遮挡的图像可以在各种计算机视觉应用中正常使用,使图像在视觉上更加清晰。
本研究的贡献总结如下:
- 我们提出了一种新的结构转移边缘增强网格去雾网络(SEGDNet),以解决单幅图像去雾在亮度差、色偏、去除不清洁、光晕、伪影和模糊方面的问题。
- 提出了低频网格除雾子网络(LGDSn),在除雾时有效地保留了低频结构。
- 提出了高频边缘增强子网络(HEESn),在去除噪声的同时增强边缘和细节。
- 实验结果表明,所提出的SEGDNet在合成数据集和真实数据集的定性和定量评估方面都优于目前最先进的方法。
2 Related Work
无雾图像对许多计算机视觉系统都很重要,因此单图像去雾是非常有价值的。本节将介绍以往关于图像去雾的研究。目前的图像去雾方法一般可以分为基于先验的去雾方法和基于学习的去雾方法。
2.1 基于先验的除雾方法
在以前的文献中,已经提出了许多基于先验的脱雾方法。Fattal提出了一种估算单幅朦胧图像光透射率的方法。基于这个估计,散射光被去除以增加场景的可见度并恢复无雾图像的对比度。Tan基于两个基本观测结果开发了一个系统:首先,能见度高的图像比受恶劣天气影响的图像具有更高的对比度;其次,大气光线的变化主要取决于物体与观察者之间的距离。在此基础上,提出了马尔科夫随机场框架下的除雾方法。Tarel和Hautiere通过大气掩膜推断、图像恢复和平滑以及色调映射实现了快速去雾。有研究提出了暗通道先验,这是一种室外无雾图像的统计量。他们观察到,户外无雾图像中的大多数局部斑块包含至少一个颜色通道中强度非常低的像素。利用该先验和大气散射模型,可以直接估计雾霾的厚度,恢复高质量的无雾图像。Nishino等人提出了一种贝叶斯概率方法,通过充分利用单个雾霾图像的底层统计结构,联合估计场景反照率和深度。Meng等人,能够通过正则化方法去霾,这得益于对传递函数固有边界约束的探索。Fattal认为小图像块的像素通常在RGB色彩空间中呈一维分布,称为色线,并根据色线与原点的偏移量恢复图像。Berman和Avidan提出了一种基于非局部先验的雾霾线算法,该算法考虑无雾图像的颜色,在RGB空间中形成紧密聚类。Bui和Kim提出的方法构建了一个彩色椭球,在RGB空间中对雾霾像素簇进行统计拟合,然后根据彩色椭球的几何形状计算透射值和去霾值。Hsu和Chen开发了一种基于多尺度小波和非局部去雾的新方法。对低频子图像进行非局部去雾,对高频子图像进行小波去噪,分别去除雾和噪声。Galdran提出了一种除雾技术,该技术可以在不依赖于雾霾形成物理模型的反演的情况下消除雾霾造成的视觉退化,但尊重其主要的基本假设。
2.2 基于学习的除雾方法
由于基于先验的去雾方法有一定的局限性,最大的问题是,如果待去雾的图像不符合先验假设,那么去雾效果会大大降低,甚至会导致图像出现伪影或偏色。因此,鉴于卷积神经网络(CNN)在计算机视觉任务中的普遍成功,一些去雾算法依赖于各种CNN直接从数据中彻底学习去雾图像,以避免从单个图像估计物理参数时的不准确性。
Cai等人提出了一种可训练的端到端系统DehazeNet,通过大气散射模型估计介质输运并恢复无雾图像。Ren等提出了一种多尺度深度神经网络,其中粗尺度网络基于整个图像预测传输图,细尺度网络对结果进行局部细化。Li等人提出AOD-Net通过基于重新制定的大气散射模型设计的轻量级cnn直接生成干净的图像。Ren等人能够使用由编码器和解码器组成的端到端可训练神经网络GFN进行去雾,编码器用于捕获输入图像的上下文,解码器用于估计每个输入对最终去雾结果的贡献。Santra等人提出了一种除雾块质量比较器,通过将各种输出块与原始朦胧版本进行比较,然后选择最佳的块进行除雾。Tang等人提出了LMSN,一种端到端多尺度卷积神经网络,其中多尺度块可以提取不同尺度的特征,并采用整体跳过连接来提高模型的性能。Wang等先提出大气照度,认为雾霾主要对YCrCb色彩空间的亮度通道有显著影响,而色度通道受影响较小。通过多尺度卷积网络自动识别雾霾区域,恢复不足的纹理信息,称为AIPNet。Liu等人提出了一种迭代运算算法,将图像去雾问题表示为一个突变模型的最小化。在经典梯度下降法的基础上,利用CNN对该突变模型进行解雾。Liu等人。提出了GridDehazeNet,它由预处理、主干和后处理三个模块组成。预处理模块生成学习输入,主干模块实现对网格网络的多尺度估计,后处理模块减少伪影。Zhang和Tao提出了FAMED-Net,它由三尺度编码器和融合模块组成。编码器由级联且紧密连接的点卷积层和池化层组成。
3 Proposed Method

如图1所示,在本研究中,我们提出了一种新颖的结构转移边缘增强网格去雾网络(SEGDNet),以解决单幅图像去雾在亮度差、偏色、去除不清洁、光晕、伪影和模糊方面的问题。
- 首先,利用保持边缘的平滑算子Guided filter将图像有效分解为低频子图像和高频子图像;
- 其次,提出低频网格去雾子网络(LGDSn),在去雾的同时有效地保留低频结构;
- 提出高频边缘增强子网络(HEESn),在去噪的同时增强边缘和细节。
- 最后,我们将低频和高频结果与低频和高频融合子网络(L&HFSn)结合使用,得到最终的去雾图像。
3.1 引导滤波器(Guided Filter)
制导滤波器是一种图像滤波器,当用作边缘保持平滑算子时表现良好。此外,该滤波器也是一种速度最快的保边滤波器。在本研究中,通过Guided Filter对输入的雾霾图像进行滤波,得到输入图像的低频图像结构,然后将滤波后的图像与原始输入图像相减,得到高频图像边缘,用于后续处理。
3.2 低频网格除雾子网(Low-frequency Grid Dehazing Subnetwork,LGDSn)

通过Guided Filter从输入图像中过滤LF图像,然后通过三行六列的网格深度神经网络LGDSn,如图2所示。每一行对应一个不同的比例尺,由5个RDB block组成,同一行的feature map个数相同。每列的特征图大小不同,不同大小的列通过上采样和下采样块连接。在每个上采样或下采样块中,特征图的大小被减少或增加2倍,特征图的数量也被增加或减少2倍。上下采样是通过卷积完成的。
具体来说,上下采样块在结构上是相同的,只是使用不同的卷积层来调整特征映射的大小。它为每个RDB块包含五个卷积层。采用前四层来增加特征映射的数量,而最后一层则融合这些特征映射,然后通过通道加法将其输出与该RDB块的输入结合起来。当低频图像结构通过LGDSn时,可以得到除雾后的低频图像结构,作为后续加入HEESn的基础。
3.3 高频边缘增强子网(High-frequency Edge Enhancement Subnetwork,HEESn)

HEESn可以有效去除噪声,同时增强从输入图像中提取的边缘。首先,通过引导滤波器从输入图像中提取边缘。提取边缘信息后,通过卷积、RRDB、上采样块输入HEESn,如图3所示。此外,还有一个带有sigmoid激活函数的掩码层,用于去除边缘的噪声。
具体来说,原来的DB被替换为RRDB,性能得到了提高。提供了一个边缘增强损失函数来进一步增强边缘的重建,如章节3.5所述。最后,在去雾的低频图像结构中加入网络增强的高频图像边缘,应用L&HFSn。
3.4 低高频融合子网(Low-and-high Frequency Fusion Subnetwork,L&HFSn)

将LGDSn和HEESn的输出相加后,可以得到边缘增强的去雾图像。然而,直接去雾的图像输出往往包含伪影。因此,在我们的模型中提出了l&hfsni来去除伪影,提高去雾图像的质量。L&HFSn的架构由残差密集块(RDB)和卷积层组成,如图4所示。
3.5 损失函数
采用Smooth L1 Loss和Perceptual Loss作为训练该方法的网络。Smooth L1 Loss可以定量测量去雾图像与GT之间的差异,并且由于L1准则可以降低爆炸梯度的概率,它对异常值的敏感性不如MSE损耗。对L1损失部分进行平滑处理,其中,表示去噪图像中像素x的第i个颜色通道的强度,N表示总像素数。整个Smooth L1 Loss可表示为:


与逐像素损失不同,Perceptual Loss利用从预训练的深度神经网络中提取的多尺度特征来量化预测地图和GT之间的视觉差异。在本研究中,我们使用在ImageNet上预训练的VGG16作为损失网络,在前三个阶段(即Conv1-2、Conv2-2和Conv3-3)中提取每一层的特征。感知损失定义为:

其中,
, j = 1,2, 3表示上述与去雾图像 j 和“GT J”相关的三个VGG16特征映射。“
”、“
”、“
”为
、
的维数,j = 1、2、3。将Smooth L1 Loss和Perceptual Loss结合定义总损耗如下:
![]()
其中λ是用于调整两个损失函数的相对权重的参数。在本研究中,λ设为0.04。
4 Experiments
4.1 数据集准备
在实验中使用了最流行的RESIDE数据集来评估所提出的方法。该数据集包含72,135张室外合成雾霾图像及其对应的无雾图像。训练完成后,使用RESIDE SOTS测试数据集进行测试,该数据集包含500张室内外朦胧图像,HSTS测试数据集包含10张合成图像和10张真实图像进行测试。
4.2 训练细节和参数
在实验中,使用了英特尔酷睿i9-9900KF @ 3.60GHz和32GB内存。该模型在NVIDIA GeForce RTX 2080 TI GPU上使用Pytorch进行训练。参数设置描述如下:图像patch大小为240×240,使用Adam优化器,批大小为8,epoch为80,学习率为0.0001。
4.3 不同方法的定性评价

图5 在HSTS数据集上对已有方法和我们的方法进行定性比较.
之前的方法和我们的方法在HSTS数据集中的定性比较如图5所示。在城市景观中,可以看到DCP和BCCR的方法效果不佳,天空的颜色变得夸张,而NLD的颜色整体变得非常暗,我们的方法是最接近GT图像的。在湖表面的图像中,DCP、BCCR和nldd方法都显示出天空中严重的偏色。CAP方法相对好一些,但是可以看到湖面的感觉比GT要浅一些。但是在除雾的时候,我们的方法天空和湖面的颜色是最接近GT的。

图6 基于深度学习的方法和我们在HSTS数据集中的定性比较.
图6展示了基于深度学习的方法和我们在HSTS数据集中的定性比较。从第一排的图像可以看出,MSCNN和GFN的方法过于饱和,而AOD-Net的整体颜色变得太暗。DehazeNet相对较好,但整体色温太冷。然而,我们的方法可以很好地恢复原始图像的色调。在第四行图像中,MSCNNandAOD-Net中间部分的雾霾没有去除,GFN变得太暗,人物几乎与背景融为一体。DehazeNet的方法比较好,但是叶子、树枝、树枝的细节变得很暗,而我们的方法很好地保留了树木的各种细节,干净地去除了雾霾。

图7 最先进的方法和我们在真实世界图像中的定性比较。
最先进的方法和我们在真实世界图像中的定性比较如图7所示。在秸秆堆的图像中,可以看到NLD方法的对比度太强,阴影变得太暗,CAP和MSCNN中的雾霾没有被清晰地去除,AOD-Net的整体亮度变得太暗,而我们的方法准确地显示了干草堆的各种细节。在第5排的山地图像中,DCP和NLD的方法导致整体图像非常暗,CAP和AOD-Net的方法也较暗,但相对更好。在MSCNN中,只有左边的石头和人物似乎被适当地去雾了,远处的山脉几乎没有变化。我们的方法有最自然的色调的石头和人物,大部分的阴霾在山上已经被删除。在第六列的人物形象中可以看出,DCP使人物的肤色变暗;在NLD中,它变得苍白,CAP也有整体的颜色偏移,AOD-Net中的颜色偏黄,而我们的方法保留了角色最自然的肤色。
4.4 不同方法的定量评价
SEGDNet与几种最先进的方法进行了定量和定性比较。其中,基于先验的方法有FVR、DCP、BCCR、CAP和NLD,基于深度学习的方法有DehazeNet、MSCNN、AODNet、GFN、EPDN、FAMED-Net,基于GAN的方法有DisentGAN和RefineNet。最先进的方法和我们在SOTS和SUN RGB-D数据集上的定量比较分别列在表1和表2中。结果表明,我们的方法在PNSR和SSIM方面优于最先进的方法。

表1 最先进的方法和我们在SOTS数据集中的定量评估。

表2 在SUN RGB-D数据集中对最先进的方法和我们的方法进行定量评估。
4.5 消融实验
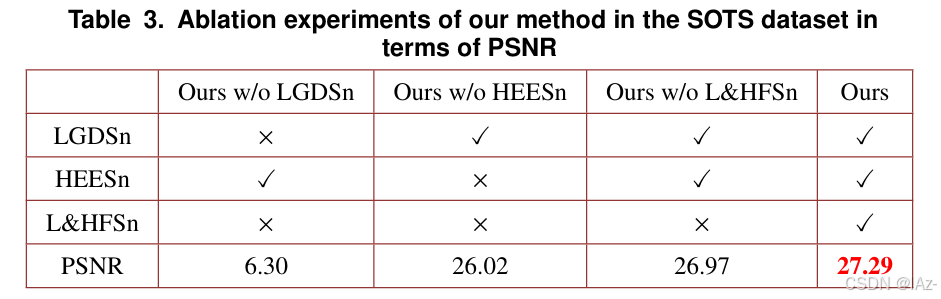
表3 我们的方法在SOTS数据集上的PSNR消融实验。
表3列出了我们方法的烧蚀实验。当只训练LF和HF图像而不进行L&HFSn时,分别表示为LGDSn和HEESn。即采用LGDSn来评价低频图像的低频重建能力,采用HEESn来验证高频图像的高频恢复能力。我们模型的LGDSn包含了大部分的图像信息。结果显示,PSNR略低于27。然而,HEESn仅适用于高频图像,未恢复的图像在模型中表现出明显较低的PSNR。“Oursw/oL&HFSn” 表示所提出的模型是在不使用L&HFSn的情况下进行训练的。当涉及到L&HFSn时,我们的模型达到了27.29的最佳PSNR。这表明,同时训练LGDSn、HEESn和L&HFSn时,获得了足够的信息量,从而在模型学习过程中获得了出色的特征提取。
5 Conclusion
在这项研究中,我们提出了一种新的SEGDNet来解决各种不同情况下的单幅图像去雾问题。该滤波器有效地将图像分解为低频子图像和高频子图像。LGDSn在去雾的同时有效地保留了低频结构,而HEESn在去噪的同时增强了边缘和细节。L&HFSn在融合低频和高频子图像时去除伪影,得到最终去雾图像。实验结果表明,在合成数据集和真实数据集上,我们的方法在定性和定量上都比目前最先进的方法获得了更好的性能和视觉呈现。在未来的工作中,我们将把提出的模型推广到更复杂和自然的雾霾数据集,以实现实际应用,如交通改善和目标跟踪。