数据科学家必须掌握的12个Python功能

Python 已经成为数据科学家的必选语言,从数据处理到机器学习,它几乎无所不能。本文将探讨一些Python特性,这些特性不仅能帮助你编写更高效、更易读、更易维护的代码,还特别适合数据科学的需求,使你的代码简洁且优雅。
一:推导式(Comprehensions)
Python中的推导式是机器学习和数据科学任务中的一个有用工具,因为它们可以用简洁且易读的方式创建复杂的数据结构。
列表推导式可以用来生成数据列表,例如,从一系列数字中创建平方值列表。嵌套列表推导式可以用来展平多维数组,这是数据科学中常见的预处理任务。
_list = [x**2 for x in range(1, 11)]matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flat_list = [num for row in matrix for num in row] print(_list)
print(flat_list)
字典和集合推导式分别用于创建数据的字典和集合。例如,字典推导式可以用来创建一个包含特征名称及其在机器学习模型中的重要性得分的字典。生成器推导式在处理大数据集时特别有用,因为它们是即时生成值,而不是在内存中创建一个大型数据结构。这有助于提高性能并减少内存使用。
_dict = {var:var ** 2 for var in range(1, 11) if var % 2 != 0}_set = {x**2 for x in range(1, 11)}_gen = (x**2 for x in range(1, 11))print(_dict)
print(_set)
print(list(g for g in _gen))
二:枚举(enumerate)
enumerate 是一个内置函数,可以在迭代序列(如列表或元组)的同时跟踪每个元素的索引。这在处理数据集时非常有用,因为它可以轻松访问和操作各个元素,同时跟踪它们的索引位置。
下面的例子中,我们使用 enumerate 来迭代一个字符串列表,并在索引为偶数时打印出相应的值。
for idx, value in enumerate(["a", "b", "c", "d"]):if idx % 2 == 0:print(value)
三:拉链(zip)
zip 是一个内置函数,允许并行迭代多个序列(如列表或元组)。
在下面的例子中,我们使用 zip 同时迭代两个列表 x 和 y,并对它们的对应元素执行操作。在这种情况下,它打印出 x 和 y 中每个元素的值、它们的和以及它们的积。
x = [1, 2, 3, 4]
y = [5, 6, 7, 8]for a, b in zip(x, y):print(a, b, a + b, a * b)
四:生成器(Generators)
Python中的生成器是一种可迭代对象,允许即时生成一系列值,而不是一次性生成所有值并将其存储在内存中。这使得它们在处理无法全部装入内存的大数据集时特别有用,因为数据是以小块或批次的方式处理的,而不是一次性全部处理。
下面我们使用一个生成器函数来生成前 n 个斐波那契数列。yield 关键字用于一次生成序列中的一个值,而不是一次性生成整个序列。
def fib_gen(n):a, b = 0, 1for _ in range(n):yield aa, b = b, a + bres = fib_gen(10)
print(list(r for r in res))
五:匿名函数(lambda 函数)
lambda 是一个关键字,用于创建匿名函数,即没有名称的函数,可以在一行代码中定义。它们在特征工程、数据预处理或模型评估时非常有用,因为可以即时定义自定义函数。
下面我们使用 lambda 创建一个简单的函数,用于从数字列表中筛选出偶数。
numbers = range(10)even_numbers = list(filter(lambda x: x % 2 == 0, numbers))print(even_numbers)
以下是一个使用 lambda 函数与 Pandas 的代码示例:
import pandas as pddata = {"sales_person": ["Alice", "Bob", "Charlie", "David"],"sale_amount": [100, 200, 300, 400],
}
df = pd.DataFrame(data)threshold = 250
df["above_threshold"] = df["sale_amount"].apply(lambda x: True if x >= threshold else False
)
df
六:映射(map)、筛选(filter)、归约(reduce)
map、filter 和 reduce 是三个内置函数,用于处理和转换数据。
-
map用于将函数应用于可迭代对象的每个元素。 -
filter用于根据条件从可迭代对象中选择元素。 -
reduce用于将函数应用于可迭代对象中的一对一对元素,最终生成一个单一的结果。
下面我们在一个管道中使用这三个函数,计算偶数的平方和:
numbers = [1, 2, 3, 4, 5, 6]# 使用 map 计算每个元素的平方
squared = map(lambda x: x ** 2, numbers)# 使用 filter 选择偶数
evens = filter(lambda x: x % 2 == 0, squared)# 使用 reduce 计算偶数平方的和
sum_of_squares = reduce(lambda x, y: x + y, evens)七:any、all
any 和 all 是内置函数,用于检查可迭代对象中的任意或所有元素是否满足某个条件。
-
any 用于检查可迭代对象中是否存在至少一个元素满足条件。
-
all 用于检查可迭代对象中的所有元素是否都满足条件。
这两个函数在检查数据集中某些条件是否被满足时非常有用。例如,它们可以用来检查某一列中是否存在缺失值,或者某一列中的所有值是否都在某个范围内。
在这个示例中,any 函数检查列表中是否存在任何偶数值,而 all 函数检查列表中的所有值是否都是奇数。
data = [1, 3, 5, 7]
print(any(x % 2 == 0 for x in data))
print(all(x % 2 == 1 for x in data))
八:next
next 用于从迭代器中检索下一个项目。迭代器是一个可以被迭代(循环)的对象,例如列表、元组、集合或字典。
next 常用于数据科学中遍历迭代器或生成器对象。它允许用户从可迭代对象中检索下一个项目,对于处理大数据集或流数据非常有用。
下面我们定义了一个生成器 random_numbers(),用于生成0到1之间的随机数。然后我们使用 next() 函数找到生成器中第一个大于0.9的数字。
import random def random_numbers():while True:yield random.random()num = next(x for x in random_numbers() if x > 0.9)print(f"First number greater than 0.9: {num}")
九:defaultdict
defaultdict 是内置字典类的子类,允许为缺失的键提供默认值。defaultdict 在处理缺失或不完整数据时非常有用,例如在处理稀疏矩阵或特征向量时。它也可以用于计算分类变量的频率。
一个示例是计算列表中项目的频率。int 被用作 defaultdict 的默认工厂,初始化缺失的键为 0。
from collections import defaultdict# 定义数据列表
items = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']# 使用 int 作为默认工厂创建 defaultdict
frequency = defaultdict(int)# 计算每个项目的频率
for item in items:frequency[item] += 1print(frequency)
在这个示例中,我们使用 defaultdict 来计算 items 列表中每个项目的频率。缺失的键会自动初始化为 0。
十:partial
partial 是 functools 模块中的一个函数,它允许从现有函数创建一个新的函数,并预先填充一些参数。
partial 在创建带有特定参数或预填充参数的自定义函数或数据转换时非常有用。这有助于减少定义和调用函数时所需的样板代码量。
这里我们使用 partial 从现有的 add 函数创建一个新函数 increment,并将其中一个参数固定为值 1。调用 increment(1) 本质上是调用 add(1, 1)。
from functools import partial# 定义一个简单的加法函数
def add(a, b):return a + b# 使用 partial 创建一个新函数 increment,将一个参数固定为 1
increment = partial(add, 1)# 调用 increment(1),相当于调用 add(1, 1)
print(increment(1)) # 输出 2
十一:lru_cache
lru_cache 是 functools 模块中的一个装饰器函数,它允许使用有限大小的缓存来缓存函数的结果。lru_cache 在优化计算开销大的函数或可能多次使用相同参数调用的模型训练过程时非常有用。缓存可以帮助加快函数的执行速度并减少整体计算成本。
下面是一个使用缓存(在计算机科学中称为记忆化)高效计算斐波那契数的示例:
from functools import lru_cache@lru_cache(maxsize=None)
def fibonacci(n):if n <= 1:return nreturn fibonacci(n - 1) + fibonacci(n - 2)fibonacci(1e3)
下面是不加缓存的情况,fibonacci(40)所需要的时间:40秒,而添加lru_cache之后计算 fibonacci(1e3) 所需要为0.06秒。
斐波那契数列的递归计算在没有缓存的情况下,其时间复杂度是指数级的,即 O(2^n)。这是因为每个数字的计算都依赖于前两个数字的计算,导致大量的重复计算。
在添加 lru_cache 装饰器后,时间复杂度大大降低。lru_cache 使用缓存存储已经计算过的结果,因此每个数字只计算一次,后续的调用直接从缓存中获取结果。这样,时间复杂度降为线性,即 O(n),因为我们只需计算每个数字一次,缓存命中的时间是常数级别的。
-
不使用 lru_cache 的时间复杂度: O(2^n)
-
使用 lru_cache 的时间复杂度: O(n)
十二:数据类(Dataclasses)
@dataclass 装饰器会根据定义的属性自动生成类的多个特殊方法,例如 __init__、__repr__ 和 __eq__。这有助于减少定义类时所需的样板代码量。数据类对象可以表示数据点、特征向量或模型参数等。
在这个示例中,dataclass 用于定义一个简单的类 Person,该类具有三个属性:name、age 和 city。
from dataclasses import dataclass@dataclass
class Person:name: strage: intcity: str# 创建 Person 对象
person = Person(name="john", age=30, city="上海")print(person)
在这个示例中,@dataclass 装饰器自动生成了 Person 类的初始化方法 __init__、表示方法 __repr__ 等,使得代码更加简洁和易读。
Python已经成为数据科学家的必选语言,其强大的特性使其在数据处理和机器学习任务中表现出色。在本文中,我们探讨了12个Python特性,包括推导式、枚举、拉链、生成器、匿名函数、映射、筛选、归约、any和all、next、defaultdict、partial、lru_cache和数据类。这些特性不仅能帮助你编写更高效、更易读、更易维护的代码,还特别适合数据科学的需求,使你的代码简洁且优雅。掌握这些特性将显著提升你的数据科学工作效率和代码质量。
关于python技术储备
由于文章篇幅有限,文档资料内容较多,需要这些文档的朋友,可以加小助手微信免费获取,【保证100%免费】,中国人不骗中国人。

**(扫码立即免费领取)**
全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
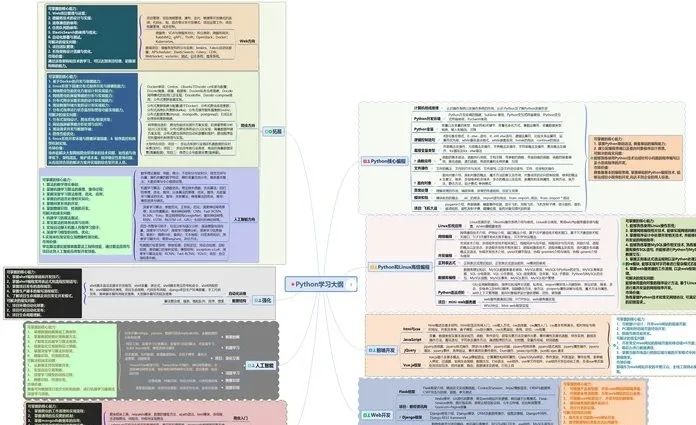

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

如有侵权,请联系删除。