【OceanBase系列】—— OceanBase应急三板斧
作者:
花名:洪波, OceanBase 数据库解决方案架构师
目前随着OceanBase数据库越来越流行,社区已经有很多用户在生产环境使用了OceanBase,也有不少用户的核心业务用到了OceanBase数据库,在使用OceanBase数据库过程中,难免会遇到各种各样的问题需要应急处理,特别是在遇到集群故障或者出现集群变慢、SQL响应超时的情况,为了保证业务能够快速恢复,就需要DBA人为介入对集群进行运维管理,帮助集群快速恢复以提供业务服务。
本文主要针对当出现OceanBase集群变慢或者出现节点故障的情况,提供应急处理的几个招式,帮助业务快速止血恢复降低事故影响范围,当然很多时候故障场景会复杂很多,一定要根据具体情况执行对应的恢复流程。以下列几个常见场景,后续还会持续更新,加入新场景进来。
常见场景
场景一:当出现节点故障,业务停服或报错情况
场景二:数据库响应变慢,SQL响应延迟(RT)明显变高
场景三:业务偶发卡顿,机器CPU飙升
场景四:日志盘(clog)满,导致集群出现问题
场景五:数据盘(data)满,导致集群出现问题
应急处理方式
场景一:当出现节点故障,业务停服或报错情况
现象:收到主机不可用或者observer不可用告警,业务反馈大量报错
第一步:首先快速检查主机可用性、网络连通行,排除因为网络抖动等导致的误报。
第二步:检查故障主机或连接不通的主机是否影响集群多数派。
- 故障节点占多数派
- 确认主机或者网络故障原因,评估是否能够快速恢复,如果可以,尽快恢复;
- 如果不能快速恢复,则快速进行主备切换,将流量切换到备租户/备集群;
- 主集群问题解决之后,等流量低峰期,再将业务切回到主库
- 故障节点占少数派
- 确认主机或者网络故障原因,评估是否能够快速恢复,如果可以,尽快恢复;
- 如果不能快速恢复,则尝试登陆sys租户,如果可以登陆,进入第三步,如果不能登陆,跳到第四步;
第三步:如果可以登陆sys租户,检查各节点状态,以及各日志流状态
# 检查集群各节点状态
select * from OceanBase.DBA_OB_SERVERS;
# 检查集群各租户的日志流状态
select * from OceanBase.__all_ls_status;正常情况下,可依赖OceanBase自身高可用机制,自动执行重新选举,选出新的leader,8秒内可快速恢复,如果未选出新的leader,几分钟内无法快速定位故障原因,业务着急恢复,则执行操作一。
操作一:stop节点,将故障节点进行隔离,隔离之前,建议先检查下永久下线参数server_permanent_offline_time的值,默认为1小时,建议将其调大一点,防止节点故障超过一个小时未恢复而被提出集群:
# 检查永久下线参数值
show parameters like "%server_permanent_offline_time%";
# 停止节点,隔离故障节点
ALTER SYSTEM STOP SERVER 'svr_ip1:svr_port1';在执行操作一之后2分钟还没有没恢复,执行操作二
操作二:对受到影响的租户进行切主操作,如果random配置,无脑选一个不包含问题observer的zone进行切主操作。
ALTER TENANT tenant1 primary_zone='不包含问题observer的zone';执行操作二之后,3分钟还没有缓解迹象,执行操作三
操作三:重启observer集群
如果集群是通过obd管理,则直接执行obd cluster restart 命令重启,具体如下:
obd cluster restart 集群名称 -c oceanbase-ce -- 重启整个ob集群obd cluster restart 集群名称 -c oceanbase-ce -s xx.xx.xx.xx,xx.xx.xx.xx -- 只重启ob集群指定节点如果集群是通过ocp管理,则在ocp管理页面上,执行集群重启
执行完操作三之后5分钟没有恢复迹象,则立刻执行主备集群切换,因为此时主租户已不可用,只能执行failover的切换,通过备集群的sys租户,执行切换命令
ALTER SYSTEM ACTIVATE STANDBY TENANT = tenant_name;查询 DBA_OB_TENANTS 视图,确认备租户是否已切换为主租户
SELECT TENANT_NAME, TENANT_TYPE, TENANT_ROLE, SWITCHOVER_STATUS FROM oceanbase.DBA_OB_TENANTS;这里需要注意:Failover 操作通常是在主租户出现无法恢复的故障时所做的切换行为。执行 Failover 操作后,对应的备租户角色会变换成 PRIMARY。同时,如果对主租户故障前一直正常同步的备租户执行 Failover 操作,则执行 Failover 操作后,一般会产生百毫秒级别的数据损失,执行时间一般为秒级。
第四步:如果不能正常登陆sys租户
操作一:执行observer节点重启,restart observer
查看另外两个zone上任意两台observer上的 /home/admin/oceanbase/etc/obcluster.config.bin 确认当前RS所在服务器的ip地址
strings observer.config.bin | grep rootservice_list后依次针对RS执行串行重启应急操作。
3分钟没有缓解迹象。
操作二:fail over/restart cluster (切主备集群/重启集群),切换和重启方式同第三步。
场景二:数据库响应变慢,SQL响应延迟(RT)明显变高
现象:数据库响应变慢,收到SQL响应超时报错,监控中SQL执行时间陡升
第一步:确认机器网络、磁盘IO延迟情况,排除因网络延迟、磁盘IO性能等问题导致的SQL响应延迟增高;
第二步:登陆ocp,查看租户的SQL诊断,进入到 top sql/slow sql/可疑sql 中,检查是否有异常sql

检查点一:执行计划是否变差
进入到具体的SQL中,下方执行计划,可查看该SQL实际执行的执行计划,检查是否合理

如果不合理,则可以手动将SQL与某个合理的执行计划进行绑定,或创建outline进行指定

检查点二:SQL是否存在过多等待事件
在SQL诊断中,在TopSQL/SlowSQL页面,打开列管理,选择需要查看的具体指标,这里可以关注几个重要指标,如最长等待事件、IO等待时间、返回行数、访问分区数、RPC次数、等待次数等。
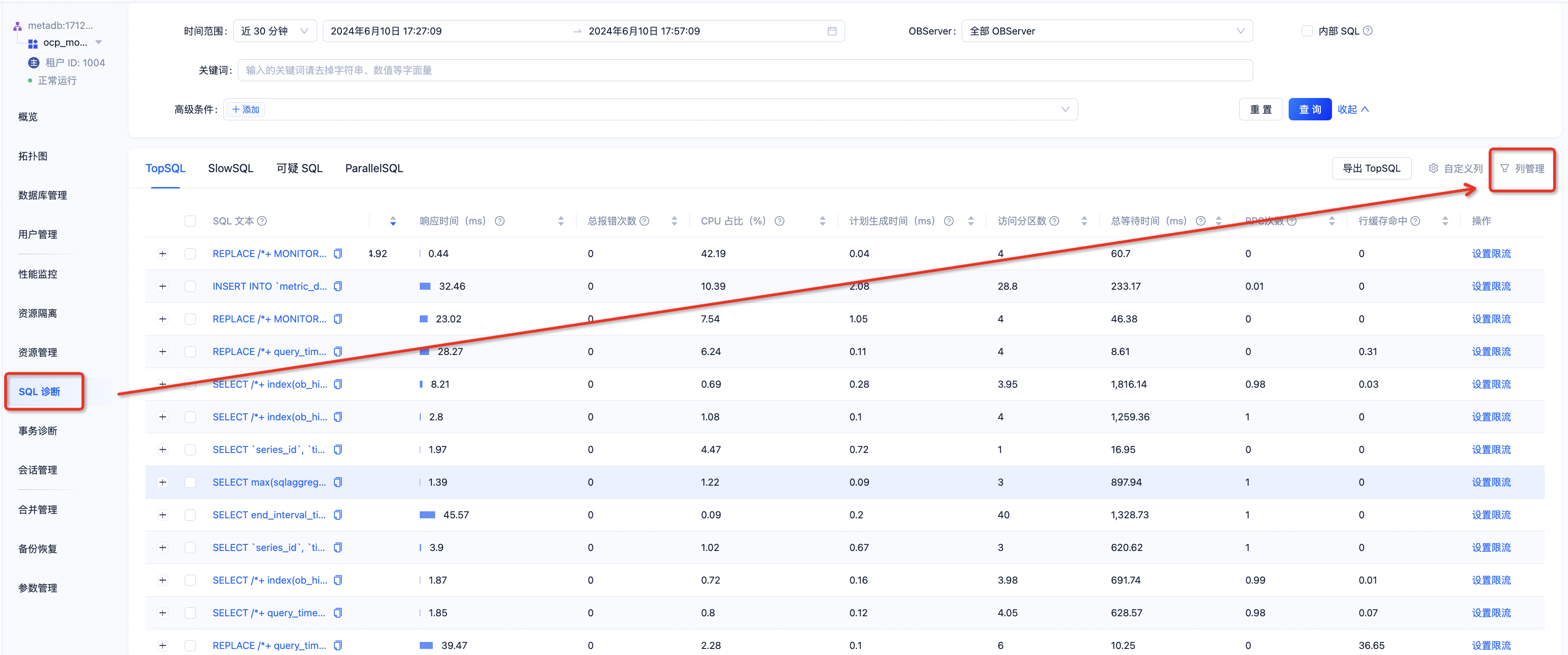

如发现有异常情况,评估是否可以通过增加索引或修改SQL逻辑等方式,对SQL进行优化。
第三步:如果以上都未发现有明显异常,则检查租户是否有资源瓶颈,通过对日志中租户的dump信息进行检查,查看租户的队列是否存在积压情况
grep "dump tenant info(tenant={id:租户ID," observer.log检查dump信息中total_size大小,如果大于0,则存在一定的队列积压,租户资源遇到一定瓶颈。
方案一:对租户进行扩容,修改租户的resource unit,增加cpu、内存资源;或者为集群加入新的observer,然后修改租户的unit数量等;
方案二:对SQL执行限流操作,可在OCP中直接针对某条SQL设置限流

场景三:业务偶发卡顿,机器CPU飙升
现象:收到CPU使用率高的告警,SQL响应延迟突然变高,监控中CPU使用率飙升
第一步:通过 top 命令,确认是observer进程导致的CPU使用率升高,如果不是observer进程导致,尽快排查其他进程导致CPU升高原因;
第二步:通过 top -H 命令,检查导致CPU使用率过高的observer线程,如果是TNT_L0_xx线程,则在CPU高场景下收集3次obstack,然后可以寻求官方协助,如问答区提问。如果不是这类线程导致,则进行第三步;
第三步:如果不是以上问题,则大概率是top/slow sql导致,进入到OCP中的SQL诊断里,可根据SQL的CPU占比进行排序,快速找到CPU使用率过高的SQL

然后对SQL进行排查:
检查点一:是否在短时间内生成大量执行计划,即短时间内大量的不同SQL请求、或者相同SQL加了不同的 hint 导致每次SQL执行都要重新生成执行计划;
检查点二:CPU占比高的SQL执行计划是否合理,同场景二中的处理方式,可对SQL执行计划进行绑定;
检查点三:是否存在计算量大的SQL,如存在此类SQL,可对SQL执行限流操作,或进行资源组的隔离。
场景四:日志盘(clog)满,导致集群出现问题
现象:收到磁盘告警,业务报错,无法执行写入和更新的SQL,无法选举和缺副本等
第一步:根据告警及现象,判断出现问题的租户;
第二步:登陆sys租户,通过如下SQL查看对应租户log_disk使用情况
select a.svr_ip,a.svr_port,a.tenant_id,b.tenant_name,
CAST(a.data_disk_in_use/1024/1024/1024 as DECIMAL(15,2)) data_disk_use_G,
CAST(a.log_disk_size/1024/1024/1024 as DECIMAL(15,2)) log_disk_size,
CAST(a.log_disk_in_use/1024/1024/1024 as DECIMAL(15,2)) log_disk_use_G,
log_disk_in_use/log_disk_size 'usage%'
from __all_virtual_unit a,dba_ob_tenants b
where a.tenant_id=b.tenant_id;第三步:通过如下SQL检查集群的log_disk磁盘空间是否已经分配完,如果log_disk_free为0,则表示已分配完
select zone,concat(SVR_IP,':',SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from gv$ob_servers;第四步:如果上面SQL查出来log_disk_free还有剩余空间,则直接扩容该租户的log_disk大小,通过如下SQL
ALTER RESOURCE UNIT unit_name
LOG_DISK_SIZE = 'NEW SIZE';如果log_disk_free空间为0,则检查机器操作系统磁盘是否已经全部分配给OceanBase集群的日志盘,如果有剩余空间,可以修改集群级别log_disk_size 或者log_disk_percentage,增加OceanBase集群的log_disk大小,然后再通过上面命令,增加租户的log_disk大小,修改log_disk_size和log_disk_percentage SQL如下
ALTER system SET log_disk_size = 'NEW SIZE';
ALTER system SET log_disk_percentage = NEW PERCENTAGE;第五步:如果OceanBase集群log_disk已分配完,并且操作系统上的磁盘也已经被分配完,则主动停止租户的写入,防止 clog 盘临时腾挪的空间再次快速被业务写入打满,无法修复
第六步:停止集群写入后,临时调大 clog 盘停写的阈值比例,由 95% 调整到 98%,通过如下命令调整;
ALTER system SET log_disk_utilization_limit_threshold = 98;观察一段时间,多数情况下 clog 追上后,集群可以恢复。如果还未恢复,扩容操作系统磁盘空间来增加足够的log_disk空间。
场景五:数据盘(data)满,导致集群出现问题
现象:收到磁盘告警,日志中出现ERROR,无法转储、无法合并等,导致集群无法写入
第一步:登陆sys租户,通过如下命令查看当前集群各节点数据盘使用情况
select svr_ip,svr_port,
round(total_size/1024/1024/1024,2) total_size,
round(used_size/1024/1024/1024,2) used_size,
round(free_size/1024/1024/1024,2) free_size
from __all_virtual_disk_stat;第二步:检查存放数据盘的操作系统磁盘,是否还有空间可以分配,如果有空间可以分配,则修改集群级别的参数datafile_disk或者datafile_disk_percentage,增加数据库的数据盘大小,通过如下命令:
ALTER system SET datafile_disk_percentage = 98;
ALTER system SET datafile_disk = 'NEW SIZE'第三步:如果操作系统磁盘没有可用空间分配,则考虑对磁盘进行扩容,如果也无法扩容,则可以通过对集群扩容节点 + 迁移Unit的方式来均衡数据。
第四步:扩容节点,通过OCP等工具,给集群的zone中新增机器,然后使用 OCP 进行手动迁移。登陆OCP中对应的集群中,在资源管理页面,可以通过点击 Unit 后的规格进行资源的迁移操作,迁移只能在单个zone内进行。

以上简单总结了五种常见问题场景处理方式,大家可以做个简单参考。另外,这里再强烈推荐一款工具,可以用来帮忙我们快速定位问题的根因:OceanBase 敏捷诊断工具(obdiag)
OceanBase 敏捷诊断工具(obdiag)介绍
OceanBase 敏捷诊断工具 obdiag 是一款适用于 OceanBase 的黑屏诊断工具,obdiag 现有功能包含了对于 OceanBase 日志、SQL Audit 以及 OceanBase 进程堆栈等信息进行的扫描、收集,可以在 OceanBase 集群不同的部署模式下(OCP,OBD 或用户根据文档手工部署)实现一键执行,完成诊断信息的获取。
obdiag 主要包含四大块内容:
- 一键集群巡检:使用 obdiag check 命令可帮助 OceanBase 数据库集群相关状态巡检,目前支持从系统内核参数、内部表等方式对 OceanBase 的集群进行分析,发现已存在或可能会导致集群出现异常问题的原因分析并提供运维建议;
- 一键根因分析:使用 obdiag rca 命令可帮助 OceanBase 数据库相关的诊断信息分析,目前支持对 OceanBase 的异常场景进行分析,找出可能导致问题的原因;
- 一键诊断分析:使用 obdiag analyze 命令可帮助 OceanBase 数据库相关的诊断信息分析,目前支持对 OceanBase 的日志进行分析,找出发生过的错误信息;
- 一键信息收集:分为常规信息收集和场景化信息收集,使用 obdiag gather 命令可帮助 OceanBase 数据库相关的诊断信息收集,使用 obdiag gather scenes 命令可以一键执行将某些问题场景所需要的排查信息统一捞回,解决分布式节点信息捞取难的痛点;
对于上面节点故障的场景,我们可以通过如下的 obdiag 命令进行分析。执行完成之后,会自动生成一份报告,显示日志中的ERROR信息,帮忙我们快速定位。
obdiag analyze log --from "故障开始时间" --to "故障结束时间"如果短时间没办法分析出原因,可以先将日志收集下来以备后续进行问题定位,通过下面的 obdiag 命令可收集故障时间段的所有日志
obdiag gather log --from "故障开始时间" --to "故障结束时间"
obdiag gather obproxy_log --from "故障开始时间" --to "故障结束时间"像磁盘满等问题,实际上可以通过一键集群巡检,提前发现这类问题,运行如下 obdiag check 命令,可以对集群整体健康状况做一次检查,包括操作系统各项配置、数据库各项配置等
obdiag check -c 配置文件路径对于SQL执行慢的场景,可以通过下面命令一键收集所属 OceanBase 集群指定 trace_id 的并行 SQL 的执行详情信息,包括所有涉及到的表结构、SQL的执行计划等等信息,帮助我们定位SQL执行慢的原因
obdiag gather plan_monitor --trace_id YB420BA2D99B-0005EBBFC45D5A00-0-0 --env "{db_connect='-hxx -Pxx -uxx -pxx -Dxx'}"关于 obdiag 的相关功能还有很多,并且也支持用户自定义开发,其他详细功能大家可以访问官网 OceanBase 敏捷诊断工具(obdiag)一探究竟,obdiag 在日常运维工作中,能帮助我们节省非常多的工作,建议大家都可以了解下。