PgSQL HashAgg算法 | 第2期 | 版本12的spill溢出磁盘解秘
PgSQL HashAgg算法 | 第2期 | 版本12的spill溢出磁盘解秘
HashAgg需要在内存中构建Hash表,以此来构建聚合分组;但是当数据量大到内存放不下时,就需要spill溢出到磁盘;构建好当前hash表并输出分组值后,再将磁盘上的spill文件中数据加载重新构建hash表并构建聚合分组。PgSQL在演进过程中,有两种spill磁盘方式,本期介绍如何spill并根据磁盘临时文件构建聚合分组。
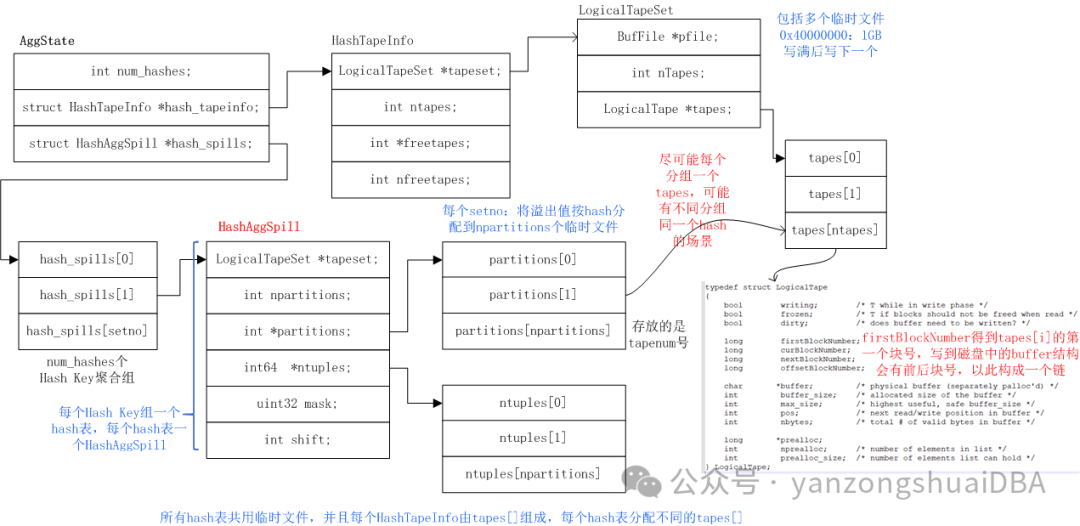
Spill的管理方式如上图所示,源头信息都存放在AggState中,分布为HashTapeInfo* hash_tapeinfo和HashAggSpill* hash_spills。
1)num_hashes为分组聚合中Hash Keys分组集个数,比如group by grouping sets((id1),(id2),(id3))中,就由3个分组集,即num_hashes值为3
2)hash_tapeinfo为该AGG使用的临时文件的tapes信息,其中ntapes为tape总个数,会有回收和复用,空闲tape由freetapes管理
3)LogicalTapeSet包含一个BufFile* pfile,管理着多个文件,当一个临时文件写满1GB后,会写如下一个文件
4)LogicalTapeSet还管理LogicalTape* tapes数组
5)再返回到AggState结构中,HashAggSpill* hash_spills数组大小为num_hashes个数,也就是每个分组集对应一个hash_spills[]
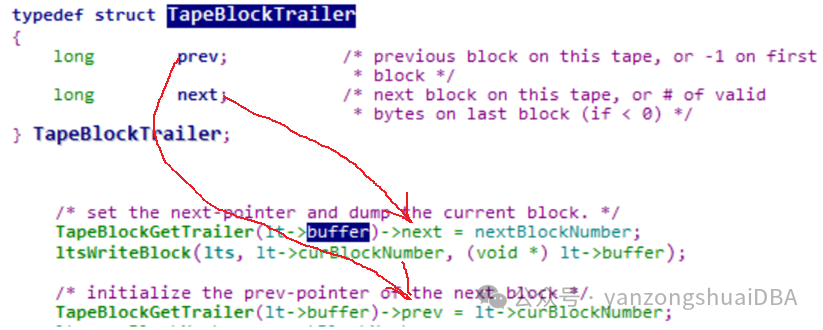
6)HashAggSpill由一个partitions数组,存放着分配的tapes[]下标号。Tapes写到磁盘时,buffer的尾部会有一个结构TapeBlockTrailer,保存前后block号,这样形成一个链表,读时,通过该链表将同一个tabpes[]的数据读取出来
因为写入的时候,根据hash值确定使用哪个tapes[],所以一个tapes[]中存放的近似一个分组的所有值(由于会有hash冲突场景,也包括不是一个分组的值)
简单了解数据读写管理后,我们接着看下HashAgg的spill流程:

agg_fill_hashtable构建hash表,然后通过agg_retrieve_hash_table从hash表中获取分组聚合值,若有spill,则hash表取完后,再从磁盘临时文件加载重新构建下一批分组聚合的hash表。
1)agg_fill_hash_table调用lookup_hash_entries构建所有set的hash表;调用hashagg_finish_initial_spills处理所有临时文件的元数据
2)lookup_hash_entries对所有Hash Key组进行构建hash表,若一个Hash key组的hash表构建过程中发生spill磁盘,则后面其他Hash Key组的hash表全部会spill磁盘
3)首先每个Hash Key组通过调用hashagg_spill_init初始化各自的HashAggSpill,管理各自的partitions[]数组等
4)hashagg_spill_tuple将tuple写到Hash Key组对应的tape链表,当然是统一写到一个文件,当文件满1GB则写入下一个文件。写下去的tuple包括所有需要的列,不仅仅是当前set需要的列
5)所有set全部spill完后,调用hashagg_spill_finish,遍历各自的partitions[]数组,每个tape形成一个HashAggBatch,记录有setno和tapenum,最终将所有HashAggBatch构建成一个链表hash_batches
6)agg_retrieve_hash_table先调用agg_retrieve_hash_table_in_memory从hash表取出分组值,取完后再调用agg_refill_hash_table从磁盘文件中读取记录重新构建hash表,并计算分组聚合值
7)agg_refill_hash_table可知从hash_batches链表取出一个HashAggBatch,得到setno和tapenum,从而从临时文件中读取该tape的所有值构建到hash表中。本次是一个tape的构建,弄好后,需要从hash表输出,之后再次进入该函数,重新从hash_batches链表取一个HashAggBatch继续下一个tape的读取
8)这里需要注意,有可能会再次spill,并且可能写到之前同一个临时文件中,并追加到同一个链表hash_batches。