Python爬虫实例--新浪热搜榜[xpath语法]
Python爬虫实例--新浪热搜榜[xpath语法]
1.基础环境配置:
requests-->版本:2.12.4
lxml-->版本:3.7.2


2.网页分析
很容易从html源码中看到,热搜内容在html的<a></a>标签内,热度在<span></span>标签内,我们可以利用这一点用xpath语法进行数据的提取。

3.代码编写

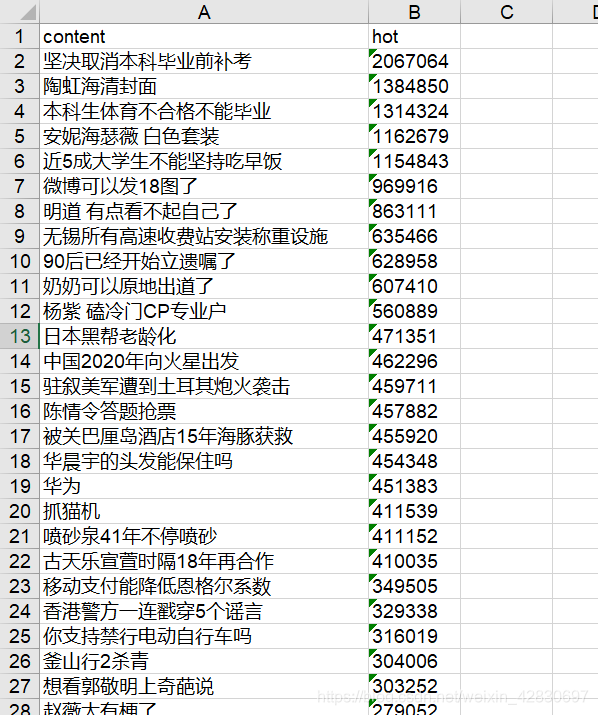
4.结果保存:
将提取结果保存在excel里面。
5.爬虫注意事项:
(1)网页分析一定要做好。
(2)一定要设置headers信息,否则容易被反爬虫拦截。
(3)不要频繁爬取同一个网站,你的IP容易被拉到黑名单。
扫描二维码即可参与该课程,解锁更多爬虫知识:
