ElasticSearch学习笔记(三)RestClient操作文档、DSL查询文档、搜索结果排序
文章目录
- 前言
- 5 RestClient操作文档
- 5.4 删除文档
- 5.4 修改文档
- 5.5 批量导入文档
- 6 DSL查询文档
- 6.1 准备工作
- 6.2 全文检索查询
- 6.3 精准查询
- 6.4 地理坐标查询
- 6.5 复合查询
- 6.5.1 相关性算分
- 6.5.2 布尔查询
- 7 搜索结果处理
- 7.1 排序
- 7.1.1 普通字段排序
- 7.1.2 地理坐标排序
前言
ElasticSearch学习笔记(一)倒排索引、ES和Kibana安装、索引操作
ElasticSearch学习笔记(二)文档操作、RestHighLevelClient的使用
5 RestClient操作文档
5.4 删除文档
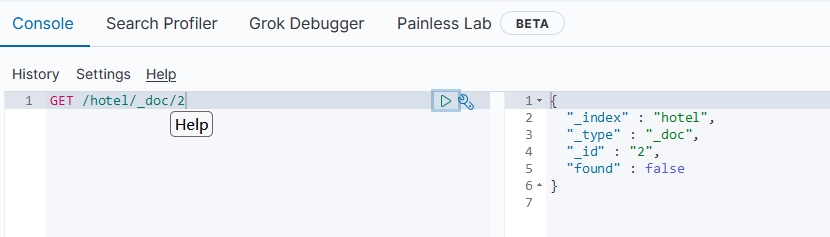
删除文档的DSL语句示例如下:
DELETE /hotel/_doc/2
对应的Java代码如下:
@Test
public void testDeleteHotelDoc() throws IOException {// 1.创建Request对象DeleteRequest request = new DeleteRequest("hotel", "2");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}
执行以上单元测试,在DevTools工具中查询该文档:
5.4 修改文档
上一节已经了解到,修改文档有全量修改和增量修改两种方式。
在RestClient的API中,全量修改与新增文档的API完全一致,判断依据是文档ID是否已存在:
- 新增时,如果ID已存在,则修改;
- 如果ID不存在,则新增。
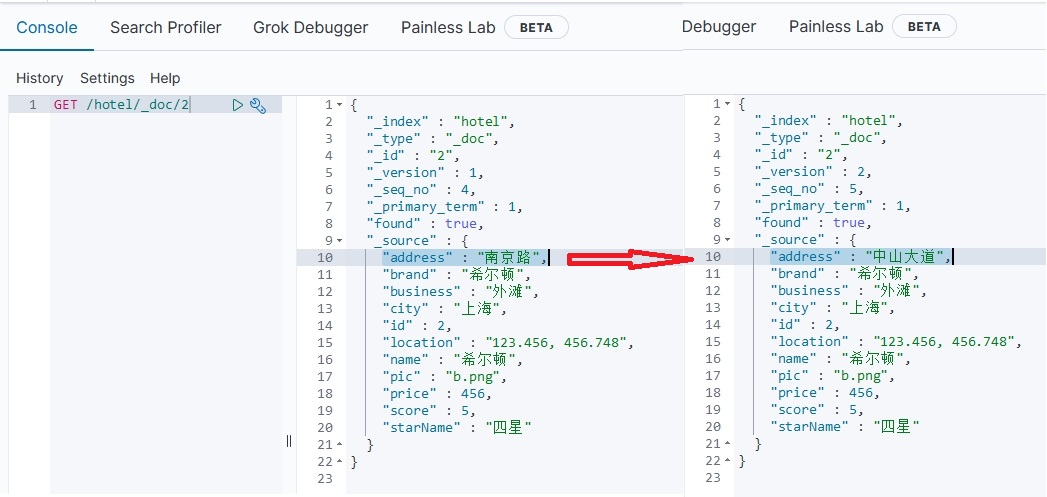
而增量修改是修改文档中指定的字段值,其DSL语句示例如下:
POST /hotel/_update/2
{"doc": {"address": "中山大道"}
}
对应的Java代码如下:
@Test
public void testUpdateHotelDoc() throws IOException {// 1.创建Request对象UpdateRequest request = new UpdateRequest("hotel", "2");// 2.设置要修改的字段request.doc("address", "中山大道");// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}
执行以上单元测试,在DevTools工具中查询该文档:
5.5 批量导入文档
RestClient提供了一个BulkRequest类用于批量导入文档,其本质就是将多个普通的CRUD请求组合在一起发送,主要使用其add()方法:
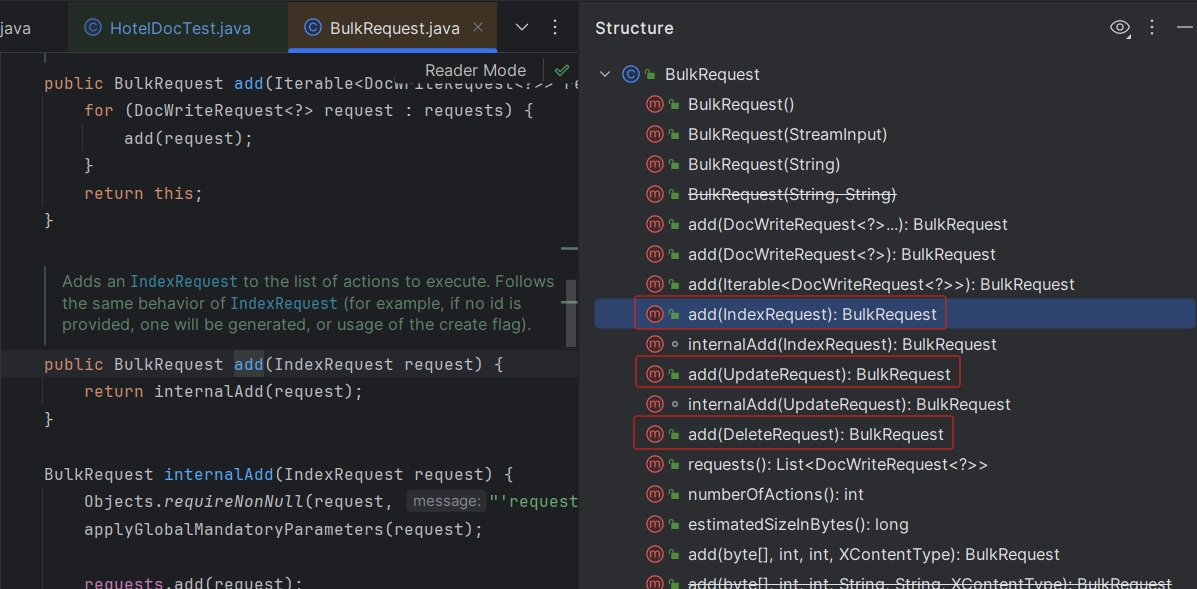
可见,能添加的请求包括IndexRequest(新增)、UpdateRequest(修改)、DeleteRequest(删除)等。
对应的Java代码如下:
@Test
public void testBulkHotelDoc() throws IOException {// 1.创建Request对象BulkRequest request = new BulkRequest();// 2.准备参数List<Hotel> hotelList = hotelService.list();for (Hotel hotel : hotelList) {HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
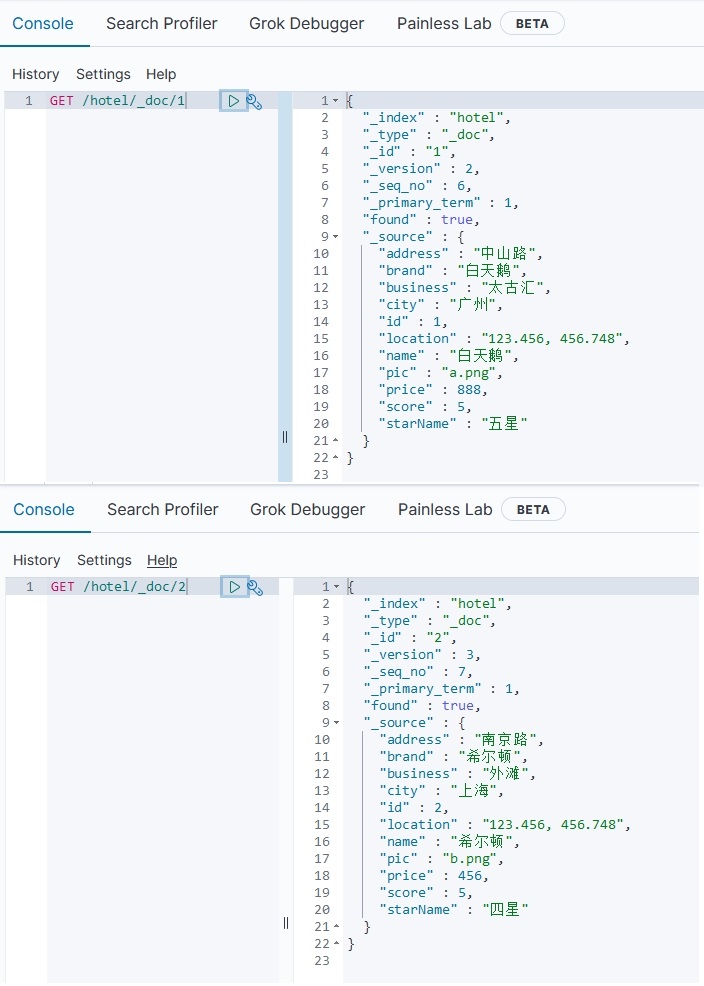
执行以上单元测试,在DevTools工具中查询该文档:
6 DSL查询文档
6.1 准备工作
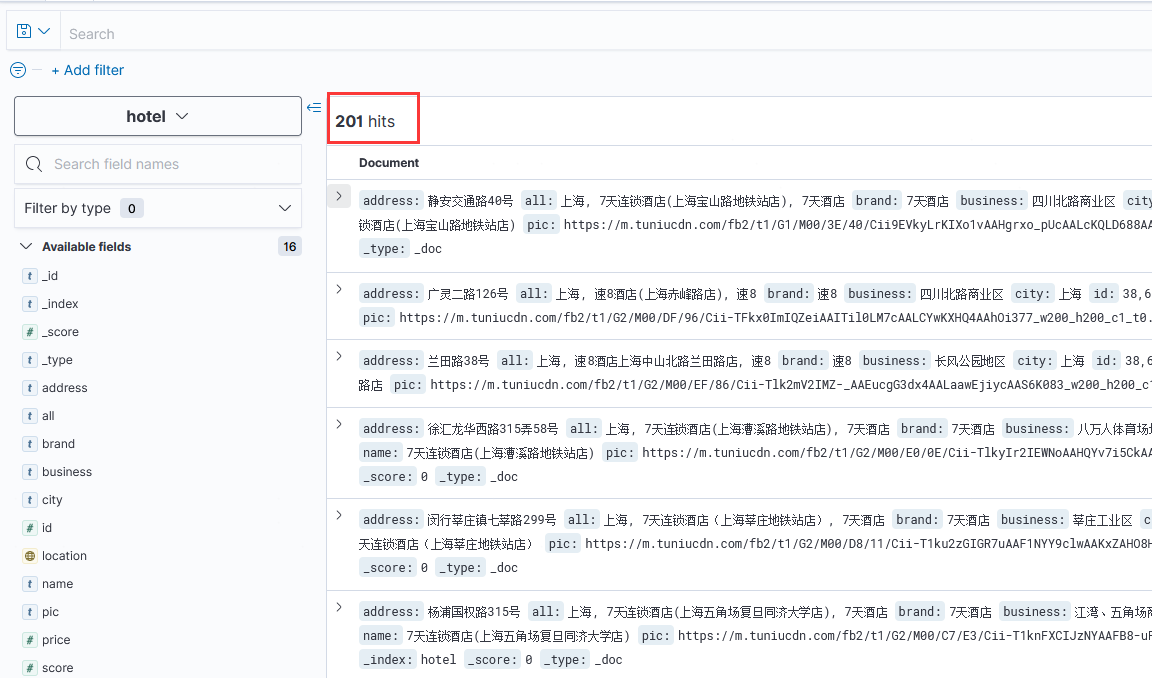
首先,向tb_hotel表插入大量数据,例如下图显示已经查了201条数据:

然后执行以下单元测试testSaveBatchHotelDoc()方法,将数据库的数据存储到ES中:
@Test
public void testSaveBatchHotelDoc() throws IOException {// 1.查询酒店数据,遍历处理List<Hotel> hotelList = hotelService.list();for (Hotel hotel : hotelList) {// 2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 3.将HotelDoc转jsonString json = JSON.toJSONString(hotelDoc);// 4.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 5.准备Json文档request.source(json, XContentType.JSON);// 6.发送请求client.index(request, RequestOptions.DEFAULT);}
}
执行完毕后,可以在Kibana中看到此时hotel索引中有201个文档:
6.2 全文检索查询
ES的查询是基于JSON的DSL查询。而全文检索查询就是利用分词器对用户输入的内容进行分词,然后去倒排索引库中匹配,例如电商系统的商品搜索、百度关键词搜索等。
其基本流程如下:
- 1)对用户输入的内容进行分词,得到词条;
- 2)根据词条去倒排索引中匹配,得到文档id;
- 3)根据文档id找到文档,返回给用户。
常见的全文检索查询包括:
- match:单字段查询
- multi_match:多字段查询,任意一个字段符合条件就算符合查询条件
其DSL语句示例如下:
# match查询
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}# multi_match查询
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand", "name", "business"]}}
}
例如:
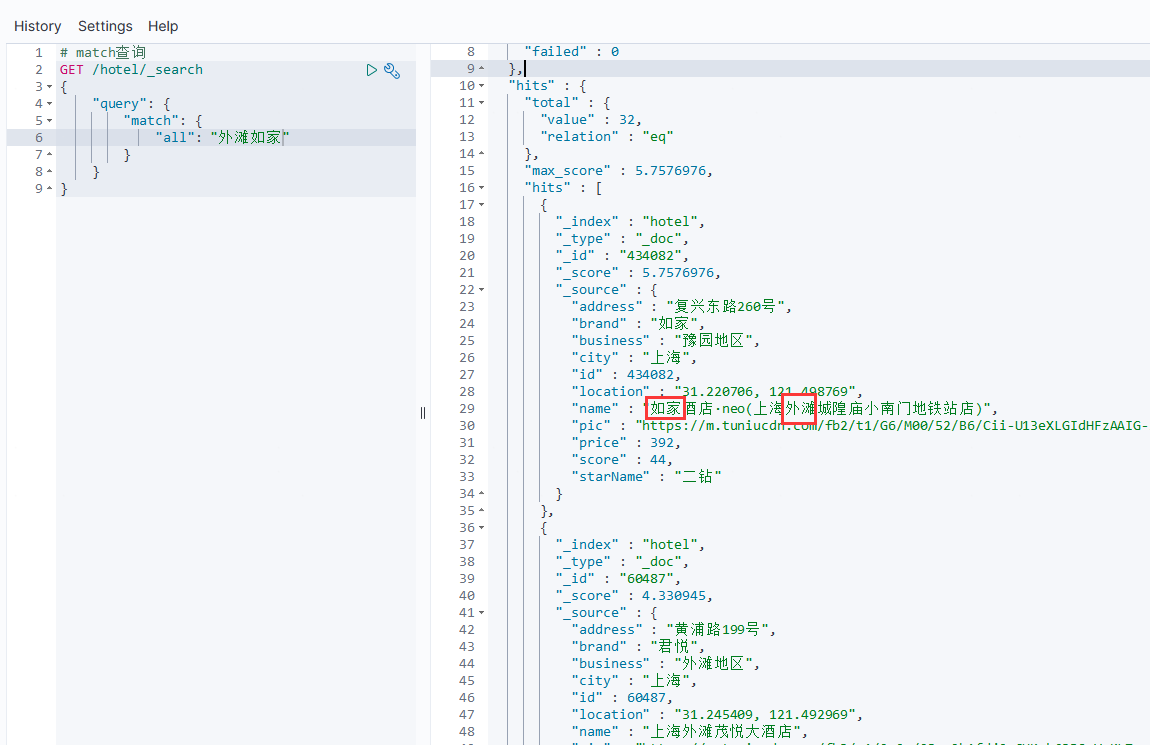
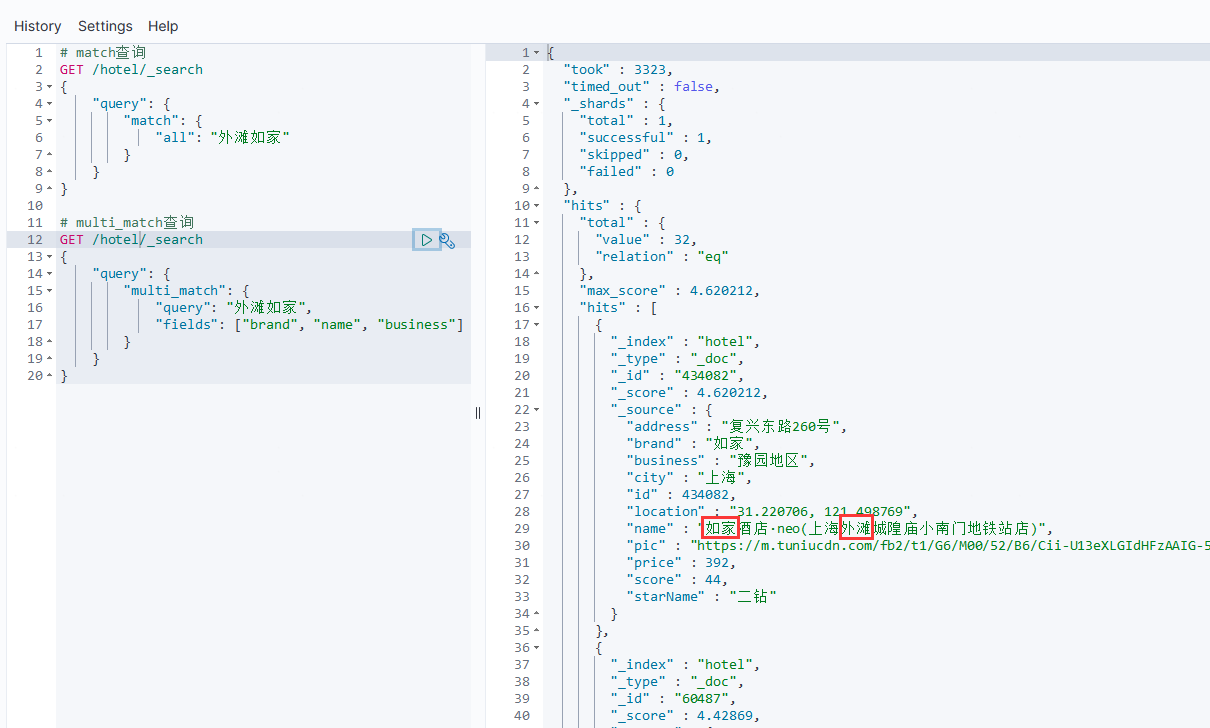
可以看到,两种查询结果是一样的,这是因为在索引hotel将brand、name、business三个字段利用copy_to复制到了all字段中。因此根据这三个字段搜索,和根据all字段搜索效果是一样的。
因此,使用multi_match查询时,搜索字段越多,对查询性能影响越大,建议采用copy_to将多个字段复制到一个字段中,然后单字段查询的方式。
6.3 精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型的字段,所以不会对搜索条件进行分词。
常见的精准查询类型有:
- term:根据词条精确值查询
- range:根据值的范围查询
其DSL语句示例如下:
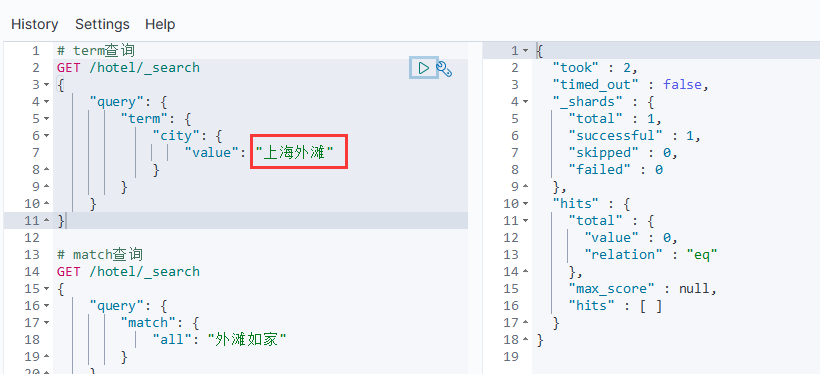
# term查询
GET /hotel/_search
{"query": {"term": {"city": { //要查询的字段"value": "上海" //字段值}}}
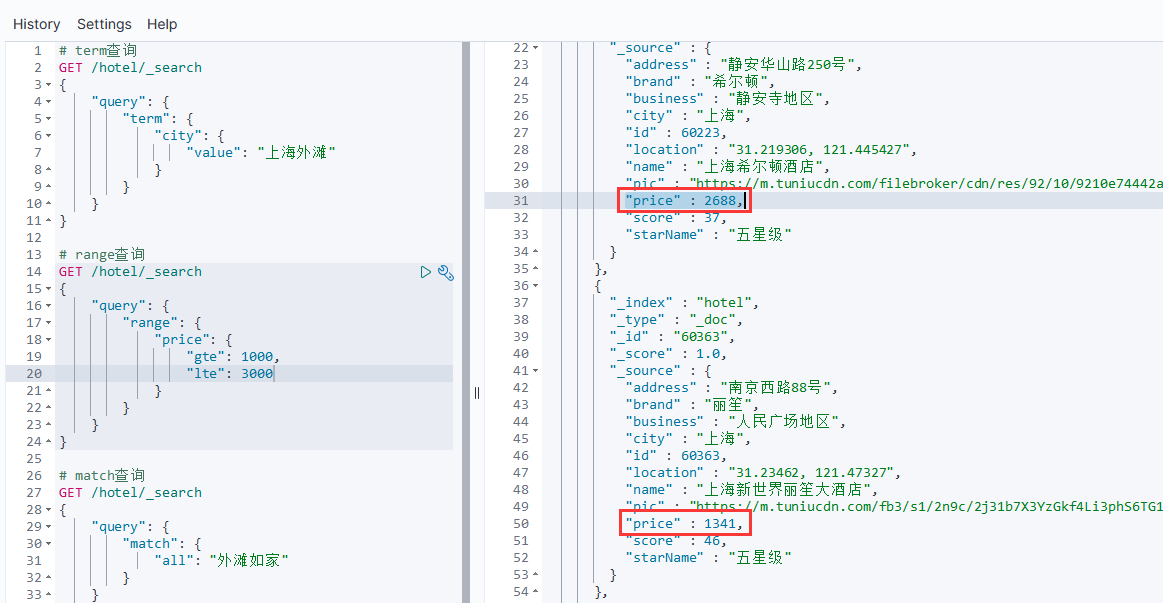
}# range查询
GET /{索引名}/_search
{"query": {"range": {"price": { //要查询的字段"gte": 1000, // >=1000"lte": 3000 // <=3000}}}
}
例如:
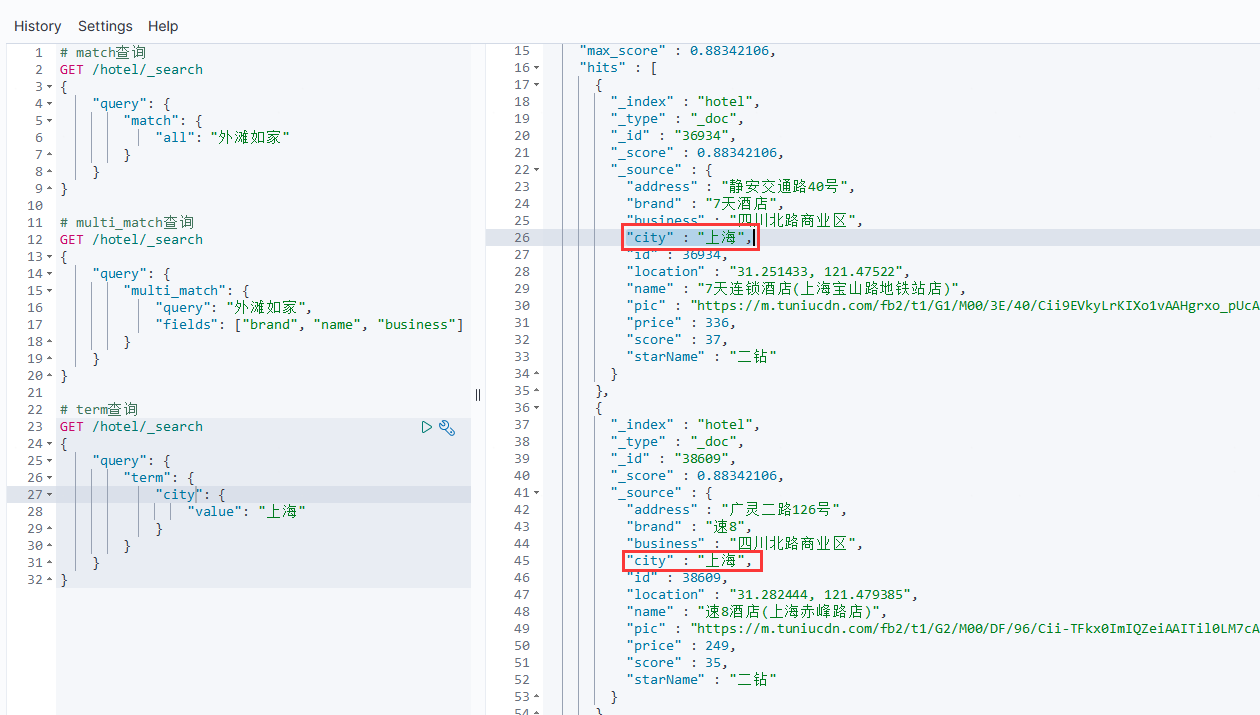
term查询时,当搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
range查询例子:
6.4 地理坐标查询
地理坐标查询,就是根据经纬度查询,常见的场景有滴滴搜索附近的出租车、微信搜索附近的人等。
常见的地理坐标查询类型有:
- geo_bounding_box:矩阵范围查询,即查询坐标落在某个矩形范围的所有文档。查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
- geo_distance:附近查询,也叫距离查询,查询到指定中心点小于某个距离值的所有文档。也就是在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件。
其DSL语句示例如下:
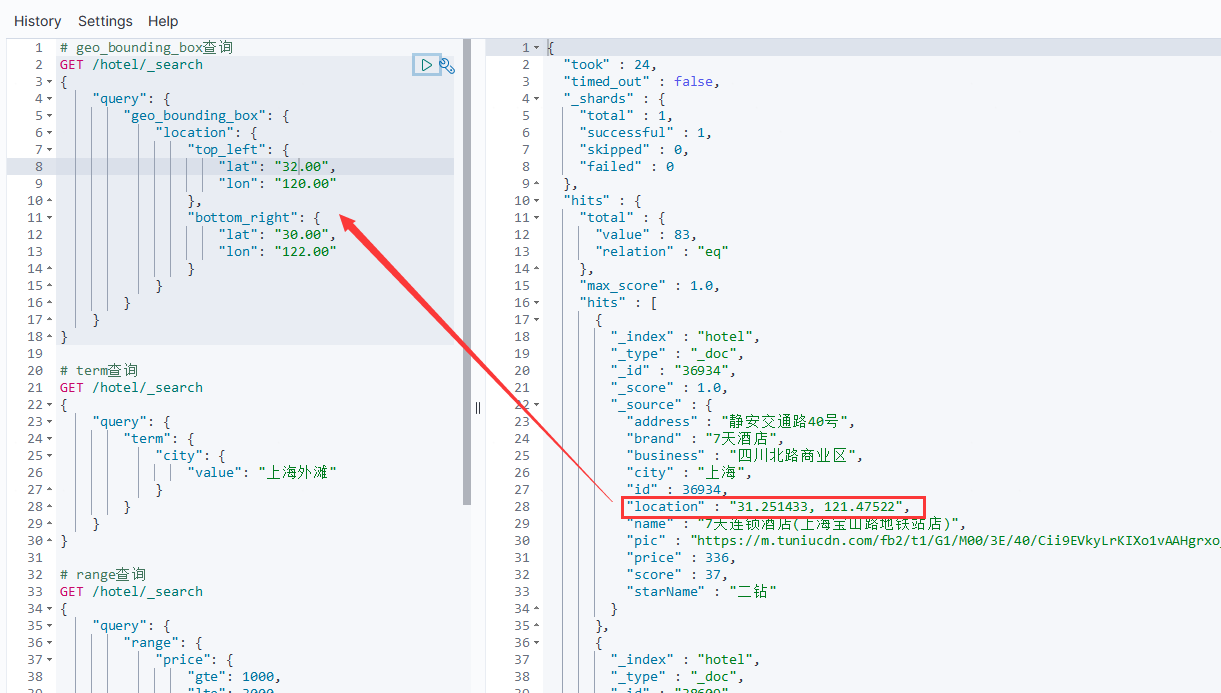
# geo_bounding_box查询
GET /hotel/_search
{"query": {"geo_bounding_box": {"location": { //要查询的字段"top_left": { //左上点"lat": "32.00", //左上点纬度"lon": "120.00" //左上点经度},"bottom_right": { //右下点"lat": "30.00", //右下点纬度"lon": "122.00" //右下点经度}}}}
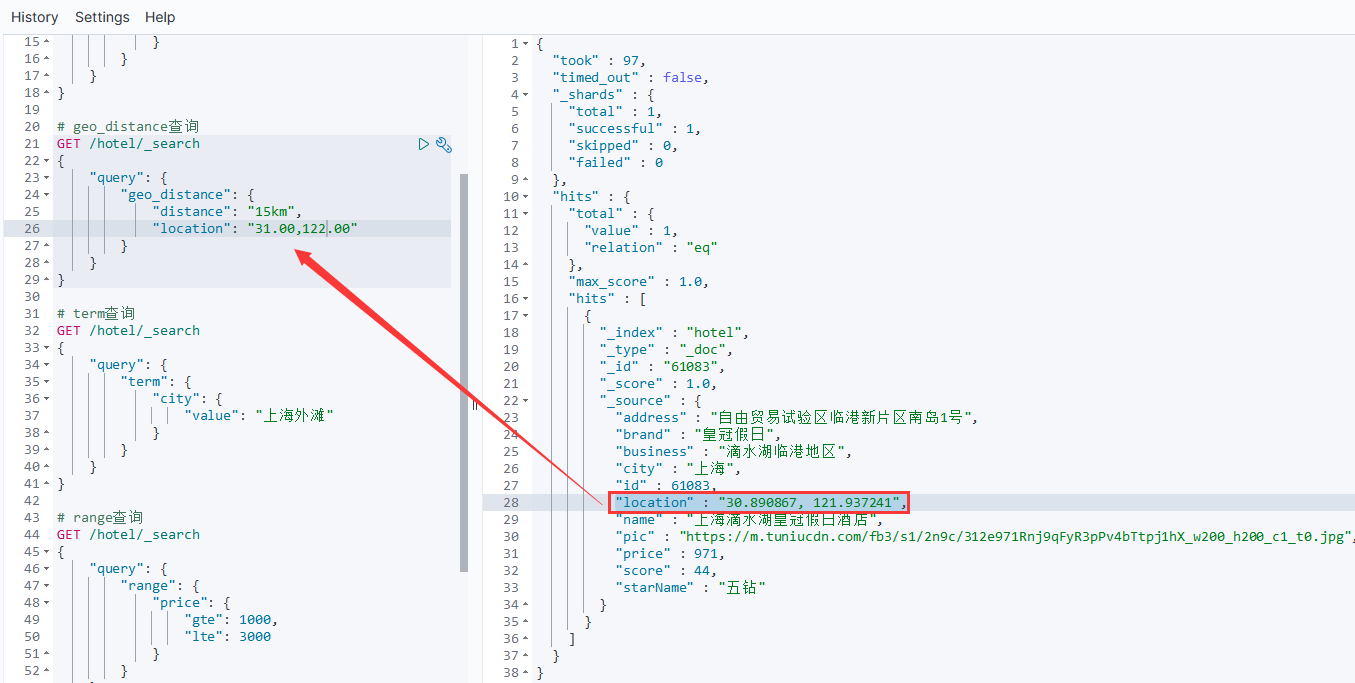
}# geo_distance查询
GET /hotel/_search
{"query": {"geo_distance": {"distance": "10km", //半径"location": "30.00,122.00" //要查询的字段:圆心坐标}}
}
例如:
6.5 复合查询
复合查询,就是将其它简单查询组合起来,实现更复杂的搜索逻辑。
常见的符合查询有两种:
- fuction_score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
6.5.1 相关性算分
在前面的match查询时,查询结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
根据相关度打分再进行排序是比较合理的,但并不一定是项目需要的。
如果想人为控制相关性算分,就需要利用ES中的function score查询。
其基本语法如下:
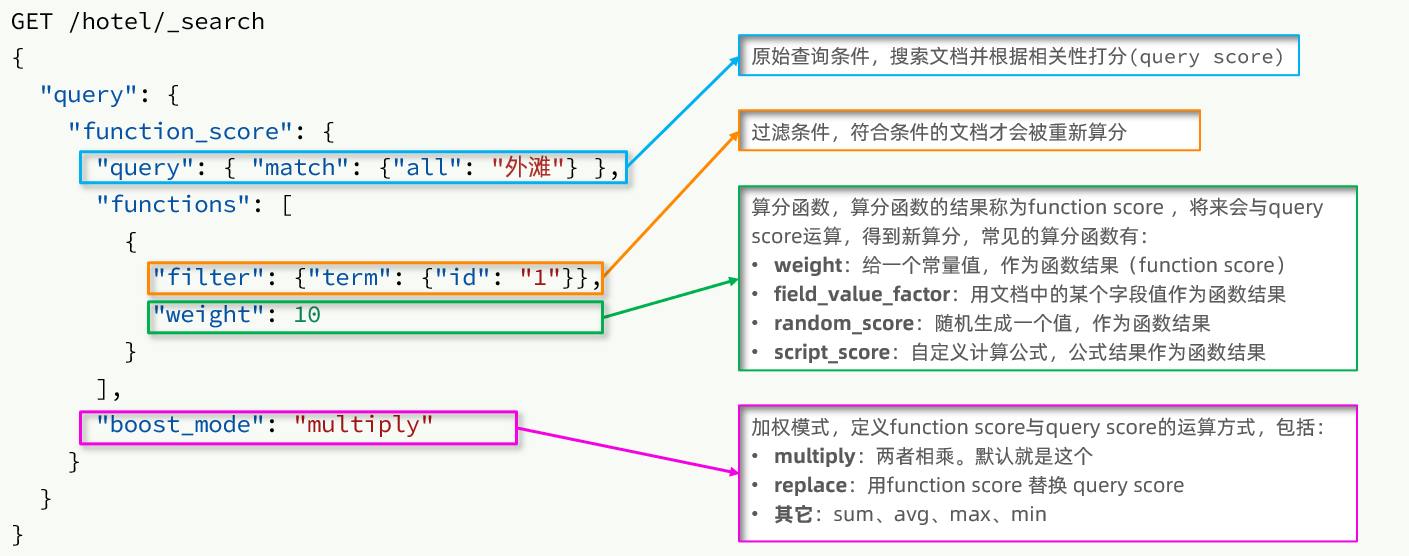
- query:原始查询条件,基于这个条件搜索文档并给文档打分,这个分数叫原始算分(query score)
- filter:过滤条件,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数:
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- boost_mode:运算模式,即原始算分和函数算分两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- sum、avg、max、min等
function score查询的基本流程如下:
- 1)根据原始条件搜索文档,并且计算原始算分(query score);
- 2)根据过滤条件,过滤文档;
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score);
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
例如有如下需求:让上海的“如家”这个品牌的酒店排名靠前一些。该需求转换为function score查询的要点如下:
- 原始条件:city = “上海”
- 过滤条件:brand = “如家”
- 算分函数:直接给固定的算分结果,weight
- 运算模式:求和
最终的DSL语句如下:
# function score查询
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"city": "上海"}},"functions": [{"filter": {"term": {"brand" : "如家"}},"weight": 2 //算分权重为2}],"boost_mode": "sum" //加权模式,求和}}
}
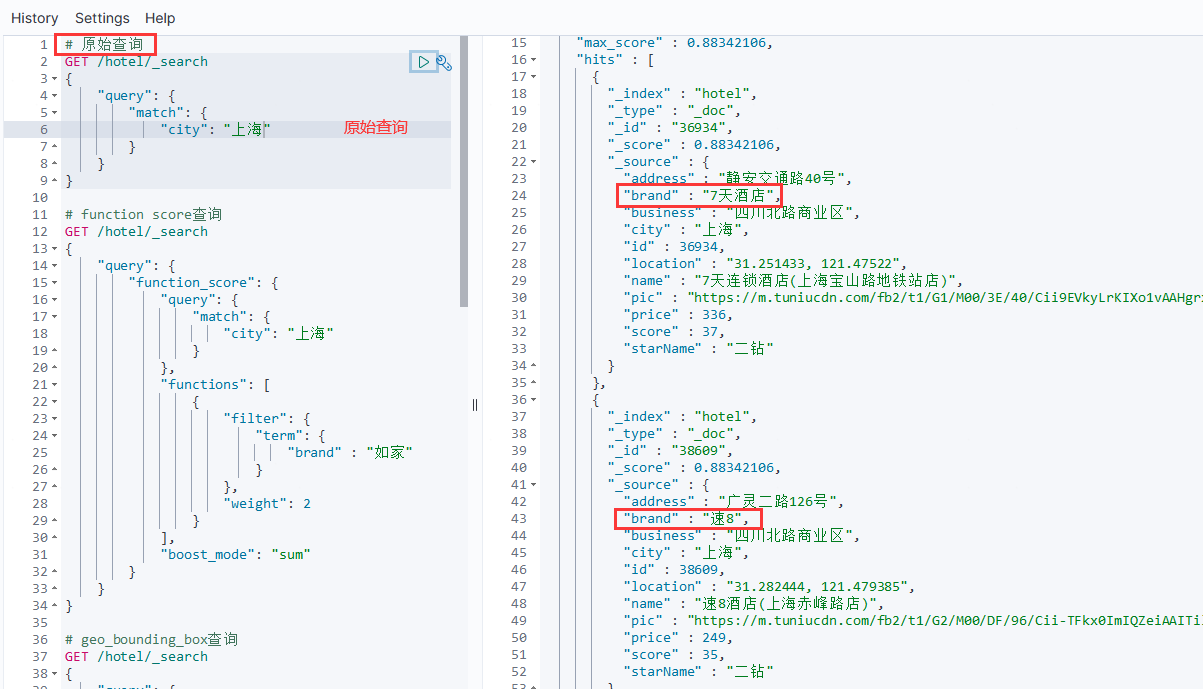
原始查询的结果如下:
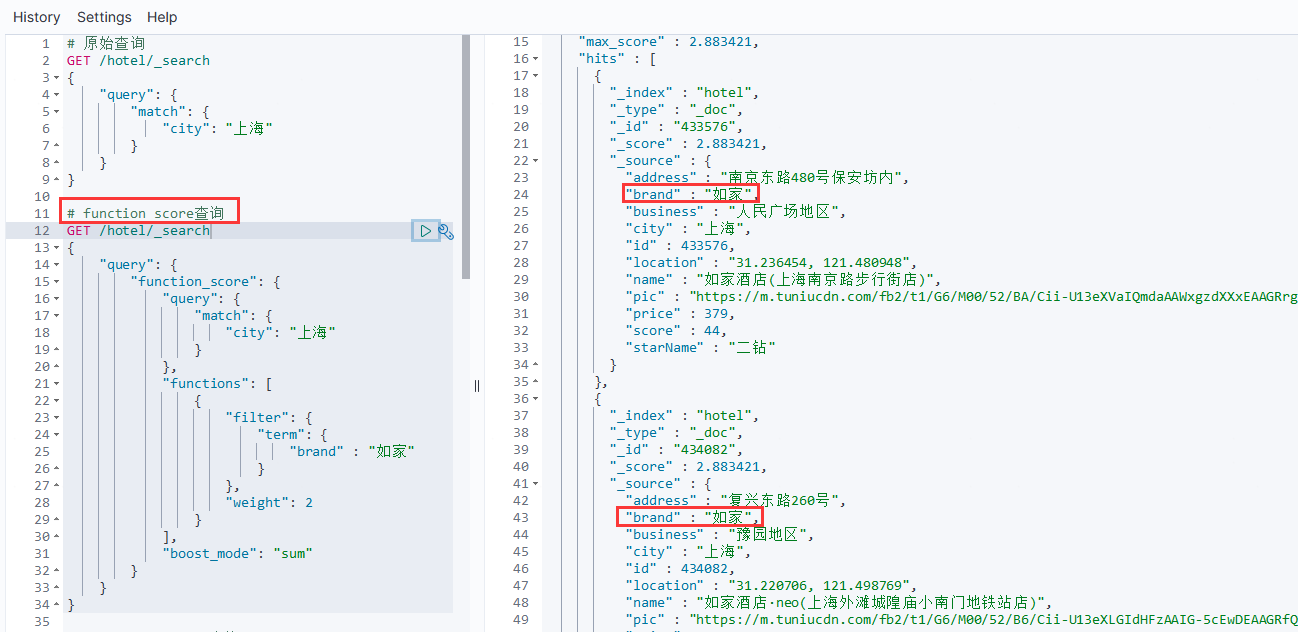
使用function score查询的结果如下:
6.5.2 布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。
子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了根据关键字搜索外,还可能根据品牌、价格、城市等字段进行过滤。由于这些字段的查询方式各不相同,因此就需要用到布尔查询。
需要注意的是,进行布尔搜索时,参与打分的字段越多,查询的性能也越差。因此布尔查询一般建议:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分;
- 其它过滤条件,采用filter查询,不参与算分。
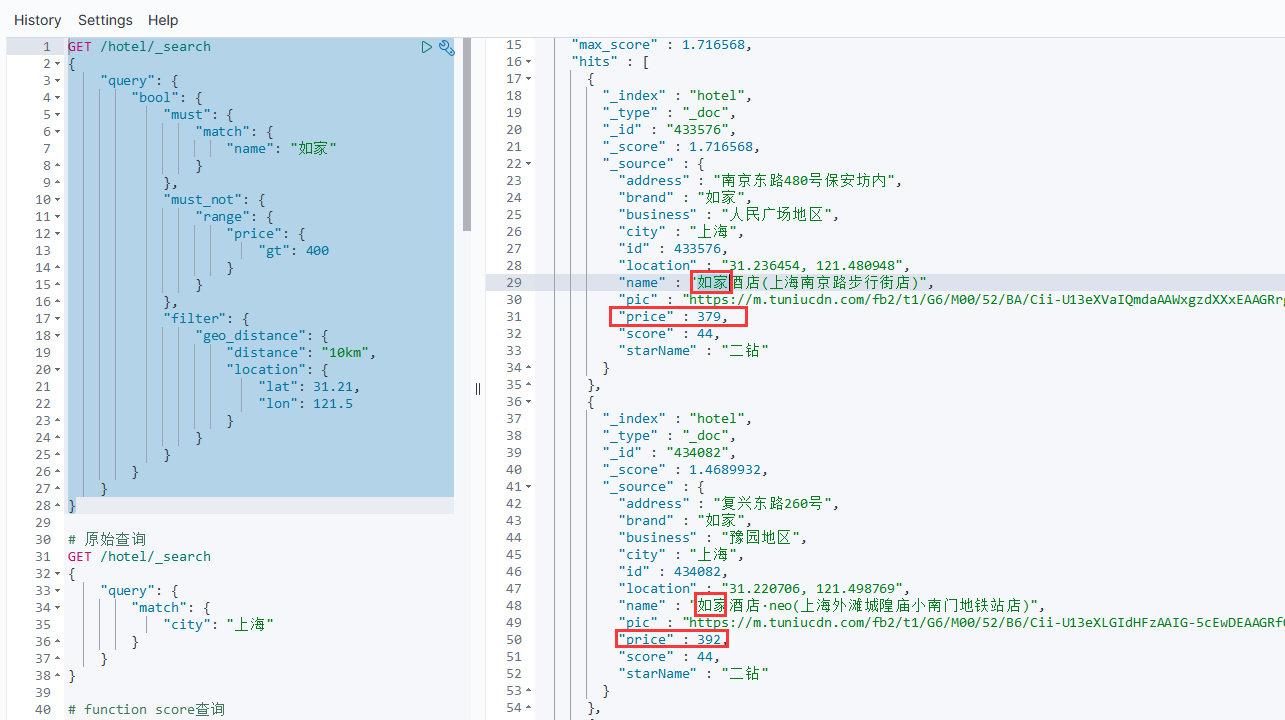
例如有如下需求:搜索名字包含“如家”,价格不高于400,在坐标(31.21,121.5)周围10km范围内的酒店。该需求转换为布尔查询的要点如下:
- 名称搜索,属于全文检索查询,应该参与算分,放到
must中; - 价格不高于400,用
range查询,属于过滤条件,不参与算分,放到must_not中; - 周围10km范围内,用
geo_distance查询,属于过滤条件,不参与算分,放到filter中。
最终的DSL语句如下:
# 布尔查询
GET /hotel/_search
{"query": {"bool": {"must": {"match": {"name": "如家"}},"must_not": {"range": {"price": {"gt": 400}}},"filter": {"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}}}
}
7 搜索结果处理
7.1 排序
ES默认是根据相关度算分(_score)来倒序排序的,但是也支持自定义方式对搜索结果进行排序。
支持排序的字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
7.1.1 普通字段排序
keyword、数值、日期类型排序的语法基本一致。
例如有以下需求:各酒店按照用户评分(score)降序排序,评分相同再按照价格(price)升序排序。其DSL语句如下:
# 普通字段排序
GET /hotel/_search
{"query": {"match_all": { //查询条件,这里指匹配全部}},"sort": [{"score": "desc" //按照用户评分(score)降序排序},{"price": "asc" //按照价格(price)升序排序}]
}
可见,排序条件是一个数组,也就是说可以同时写多个排序条件,此时会按照声明的顺序进行排序,当第1个排序条件相等时,则再按照第2个排序条件进行排序,以此类推。
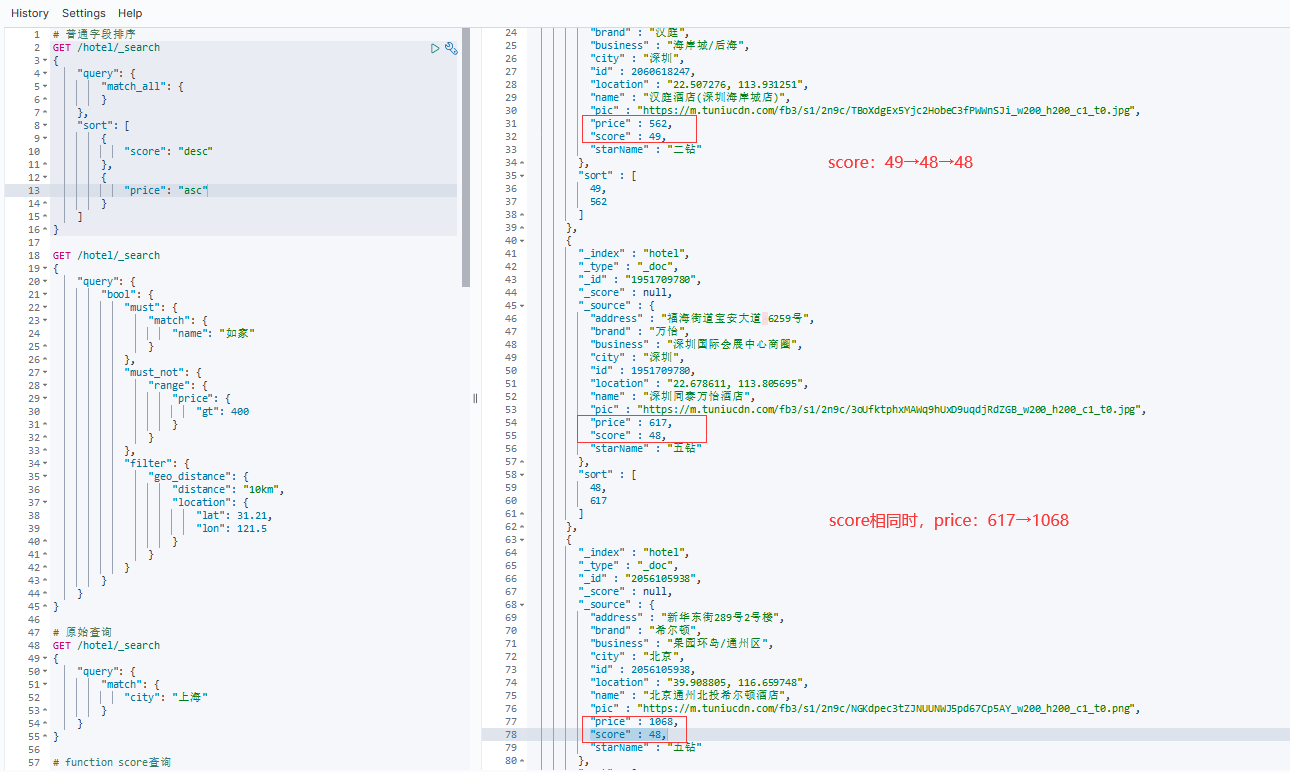
7.1.2 地理坐标排序
地理坐标排序需要指定一个坐标坐标作为目标点,然后计算文档中指定字段(必须是geo_point类型)的坐标到目标点的距离,根据距离进行排序。
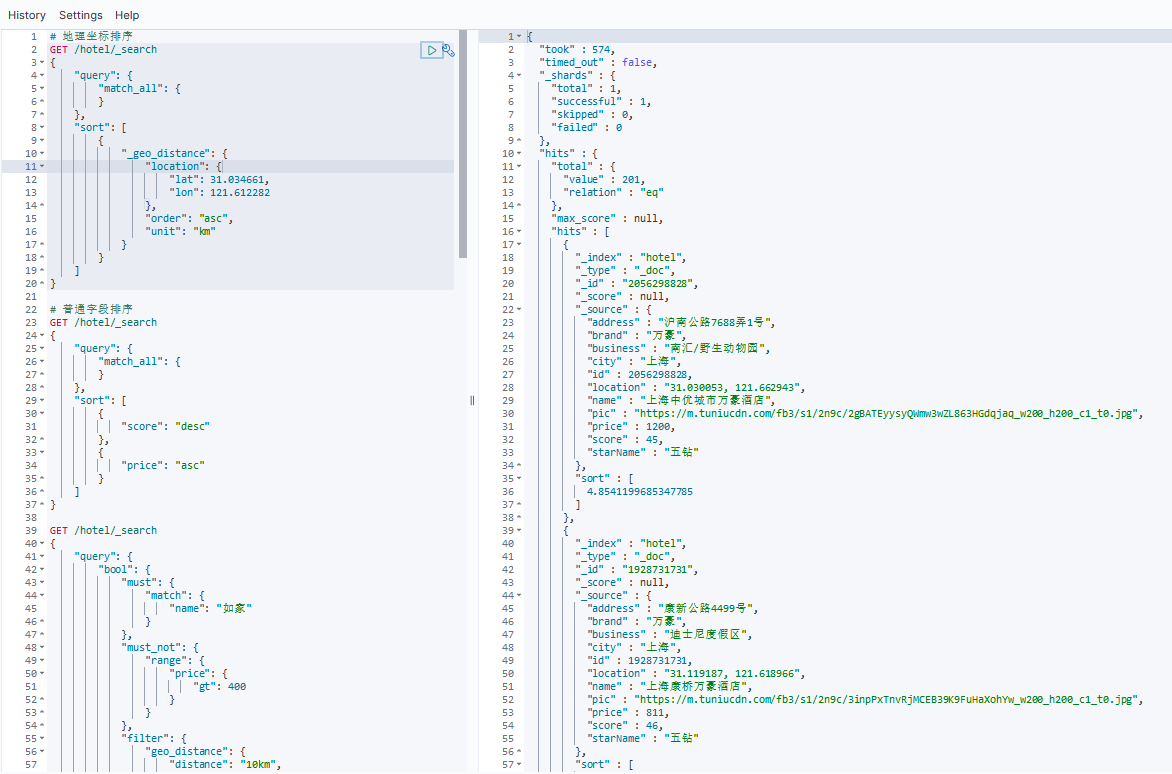
例如,有以下需求:实现对酒店按照到当前位置坐标的距离升序排序。其DSL语句如下:
# 地理坐标排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": { //指定的geo_point类型的字段"lat": 31.034661, //当前位置纬度"lon": 121.612282 //当前位置经度},"order": "asc", //asc、desc"unit": "km" //距离单位}}]
}
…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记