通过python提取PDF文件指定页的图片
整体思路
要从 PDF 文件中提取指定页和指定位置的图片,可以分几个步骤来实现:
1.1 准备所需工具与库
在 Python 中处理 PDF 和图像时,需要使用几个库:
PyMuPDF (fitz):用于读取和处理 PDF 文件,可以精确获取指定页面内容。Pillow:处理图像,用于裁剪和保存图片。pdf2image:将 PDF 页面转换为图像格式,方便进一步处理。
1.2 基本流程
- 读取 PDF 文件:使用
PyMuPDF读取 PDF 文件,找到指定页。 - 获取页面图像:使用
pdf2image将目标页转换为图像。 - 确定图片区域:使用坐标来指定图像中的区域。该区域可以通过手动确定,或者通过图像识别技术(如 OCR)来定位。
- 提取并保存图片:使用
Pillow裁剪出指定区域,并保存图像。
1.3 处理步骤
- Step 1:使用
PyMuPDF打开 PDF,找到目标页。 - Step 2:将该页转换为图像。
- Step 3:根据坐标裁剪指定位置的图像。
- Step 4:保存裁剪后的图像。
代码示例:
import fitz # PyMuPDF
from pdf2image import convert_from_path
from PIL import Image# Step 1: 打开 PDF 文件并定位指定页面
def extract_image_from_pdf(pdf_path, page_number, crop_box, output_image_path):# Step 2: 将目标页转换为图像pages = convert_from_path(pdf_path, dpi=300)target_page = pages[page_number - 1] # Python的索引从0开始# Step 3: 使用 Pillow 裁剪图像left, top, right, bottom = crop_box # 指定区域的坐标cropped_image = target_page.crop((left, top, right, bottom))# Step 4: 保存裁剪后的图像cropped_image.save(output_image_path)print(f"图像已保存到: {output_image_path}")# 示例使用
pdf_path = "/Users/linql/Desktop/3.5_python/0001_26110523.pdf" # PDF 文件路径
page_number = 4 # 要提取的页码
crop_box = (10, 700,2800, 3100) # 图像的裁剪区域 (left, top, right, bottom)
output_image_path = "output_image.png" # 输出图像的路径extract_image_from_pdf(pdf_path, page_number, crop_box, output_image_path)
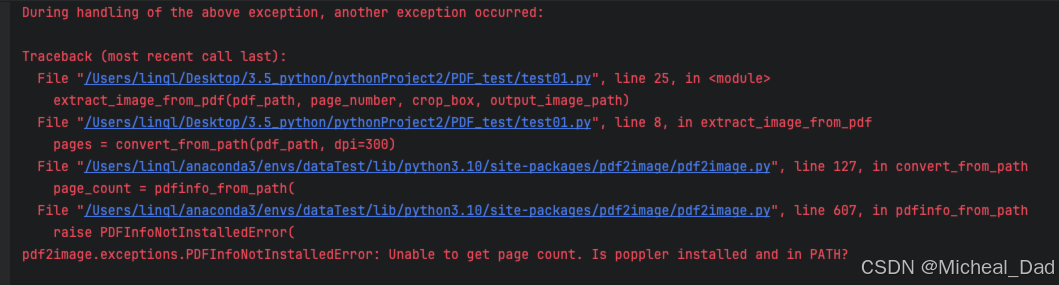
运行后,会提示:
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?是因为:# macOS 需要安装 poppler 用于 pdf2image
brew install poppler