介绍篇| 爬虫工具介绍
什么是网络爬虫
网络爬虫工具本质上是自动化从网站提取数据的软硬件或服务。它简化了网络爬虫,使信息收集变得更加容易。如今是数据和智能化时代, 如何快速、自动化获取数据, 成了个人或者企业进入智能化时代的第一步.
选择最佳网络爬虫工具时的关键因素
在选择最佳网络爬虫工具时,必须考虑几个关键因素:
功能:查找工具提供的功能。
成本:确定基础高级计划的价格。
优缺点:了解每个工具的优点和局限性。
主要目标:确定工具的主要用途。
平台:检查工具是否与您的操作系统兼容。
评论:参考Capterra等平台上的用户反馈。
集成:查看工具支持哪些技术和编程语言。
2024年网络爬虫工具
编制了一份网络爬虫工具,帮助一些初学者快速入门
| 平台名称 | 介绍 | 优点 | 缺点 | 推荐 |
| Bright Data | Bright Data凭借其全球广泛的代理网络在网络数据收集领域占据领先地位。其数百万的住宅代理使IP轮换变得高效,用于网络爬虫。Web Scraper API提供可定制的端点,用于从流行域中提取数据。它们确保了可扩展性和可靠性,能够应对常见的爬虫障碍,如反机器人机制。具有IP轮换、CAPTCHA解决方案和JavaScript渲染等功能,是一个全面的解决方案。 API将数据导出为用户友好的格式,使其成为寻求高效数据驱动项目的组织的首选。简而言之,Scraper API结合了其他工具的最佳功能,使其成为克服爬虫挑战、降低成本和节省时间的理想选择。 |
|
| 一些复杂系统或者有很强反爬虫机制的网站,可以使用这个方式 在Capterra上获得4.8/5的高评分 |
| Octoparse | Octoparse是无代码网络爬虫工具类别中的首选。它的软件可以轻松从任何网站提取非结构化数据,并将其组织成结构化的数据集。即使没有技术技能,用户也可以通过简单的点选界面定义数据提取任务。 |
|
| 提供一个桌面应用程序,使非技术用户能够执行网络爬虫任务,同时为开发者提供额外的集成选项。 对没有技术或者企业是一种选择, 毕竟养开发人员成本也很高. 在Capterra上获得4.5/5的评分 |
| ScrapingBee | ScrapingBee提供了一种高级的网络爬虫API,旨在简化在线数据提取。它处理代理和无头浏览器设置,使你可以专注于数据提取。这个API专为希望将爬虫端点集成到脚本中的开发人员设计。它依赖于庞大的代理池来绕过速率限制并降低被封锁的风险。 |
|
| 在Capterra上获得4.9/5的评分 |
| Scrapy | Scrapy是一个基于Python的开源框架,提供完整的网络爬虫和抓取API。使用Scrapy,你可以创建自动化任务来爬取网站并从其页面提取结构化数据。对于需要从各种在线来源收集信息的开发者来说,它是一个实用的工具。 无论你是在抓取文章、产品列表还是工作岗位,Scrapy都能帮助简化过程。它以其效率和灵活性而闻名,适用于广泛的抓取项目。此外,作为开源软件,它是免费的,并且可以根据你的特定需求进行定制。如果你想在Python中自动化网络爬虫任务,Scrapy值得一试。 |
|
| 非常适合程序员的开发工具, 分布式爬虫框架 |
| Playwright | Playwright是一个领先的无头浏览器库,由微软支持,在GitHub上获得了超过60,000颗星。它提供了一个为端到端测试和网络爬虫量身定制的强大API。 使用Playwright,用户可以轻松管理浏览器并在网页上模拟用户操作。它的优势在于能够从依赖JavaScript进行渲染或数据获取的动态内容网站中提取数据。Playwright的突出特点是其在各种编程语言、浏览器和操作系统之间的一致支持。 |
|
| 主要目标:通过编程模拟用户交互来自动化浏览器操作。 |
| Selenium | 类似playwright,通过编程模拟用户交互来自动化浏览器操作。 |
|
| 主要目标:通过编程模拟用户交互来自动化浏览器操作。 |
| Appium | Appium是一个开源项目和相关软件生态系统,旨在促进许多应用程序平台的UI自动化,包括移动端(iOS、Android、Tizen)、浏览器端(Chrome、Firefox、Safari)、桌面端(macOS、Windows)、电视端(Roku、tvOS、Android TV、三星)等! Appium旨在支持许多不同平台(移动端、网页端、桌面端等)的UI自动化。不仅如此,它还旨在支持用不同语言(JS、Java、Python等)编写的自动化代码。将所有这些功能结合到一个程序中是一项非常艰巨、甚至不可能的任务! | 支持pc端和移动端 |
| 主要目标:通过编程模拟用户交互来自动化浏览器操作。 虽然支持pc端,但是跟selenium、playwright比,还是差一点. |
还有一些平台基本都是付费:
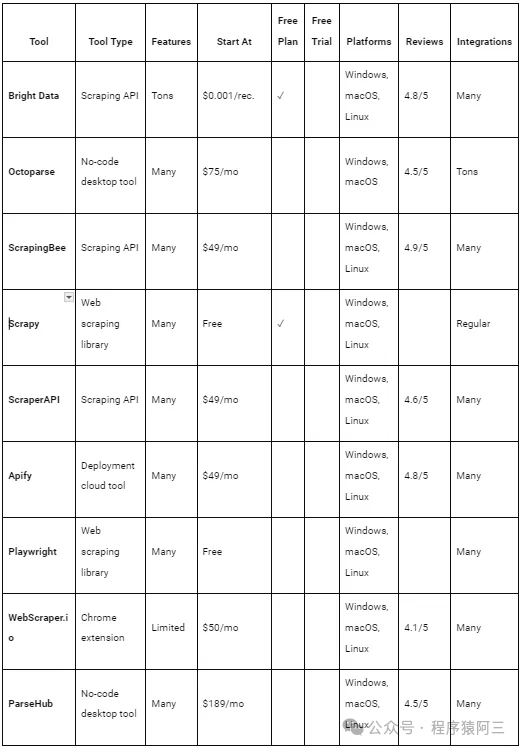
建议如果是程序员可以考虑scrapy、 playwright、Selenium、appium 等软件,支持定制化开发,如何涉及到分布式需求,可以考虑scrapy+palywright/selenium等方案, 如果企业或者非科班的人可以考虑付费平台.