十七. Python基础(17)--正则表达式
1 ● 正则表达式
定义: Regular expressions are sets of symbols that you can use to create searches for finding and replacing patterns of text. |
零宽断言(zero width assertion): 零宽断言--不是去匹配字符串文本,而是去匹配位置(开头, 结尾也是位置)。 常见的: ① 起始位置^(单行)和/A(多行), ② 末尾位置 $(单行)和/Z(多行) ③ 单词边界/b, 非单词边界/B等等。 ④ (?=exp): 匹配后面是exp的位置 (?!exp): 匹配后面不是exp的位置 (?<=exp): 匹配前面是exp的位置 (?<!exp): 匹配前面不是exp的位置 (?#exp): 表示括号内是注释
※ 区别于异常处理中的"断言" |
参考文章: ① 正则基础 http://www.cnblogs.com/Eva-J/articles/7228075.html#_label10 http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html http://www.runoob.com/regexp/regexp-metachar.html ② 向后引用(回溯引用)以及零宽断言 http://www.cnblogs.com/linux-wangkun/p/5978462.html http://www.cnblogs.com/leezhxing/p/4333773.html |
2 ● 正则的难点示例
① \b匹配这样的位置: 简单来说: 单词边界(word boundary) 具体来说: 它的前一个字符和后一个字符不全是(一个是, 一个不是或不存在)\w. 例如: a!bc, 经过如下替换:
结果变成: !bc
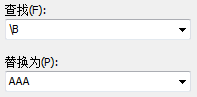
② \B匹配这样的位置: 简单来说: 非单词边界(not word boundary) 例如: ab cd ef, 经过如下替换:
结果变成: aAAAb cAAAd eAAAf
③ abc ab,c
AaAbAcA AaAb,AcA
④ 匹配不包括逗号的行 abcd abcd, ,abcd ab,cd
^((?!,).)*$表示不包括逗号","的行 ^((?<!,).)*$不能表示不包括逗号的行, 因为会把"abc,"这种情况也错误匹配上 ※ 不包括字母的行: ^((?![A-Za-z]).)*$
※ 不包括数字的行: ^((?!^[0-9]).)*$
※ 不是开头的''' (?<!(^))'''或者(?<!^)'''
※ 匹配括号中的内容, 但是不包括括号: (?<=\()\S+(?=\))
⑤(?#expr) 2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)
⑥ 贪婪(greedy)与非贪婪(non-greedy) 贪婪—尽可能多地重复
非贪婪—尽可能少地重复
|


3 ● python反向引用(back-reference)
import re text = "Hello Arroz, Nihao Arroz" rep = re.sub(r"Hello (\w+), Nihao \1", "GOOD", text) # GOOD rep = re.sub(r"Hello (\w+), Nihao \1", "\g<1>", text) # Arroz rep = re.sub(r"Hello (\w+), Nihao \1", "\g<0>", text) # Hello Arroz, Nihao Arroz |
※ (...) matches whatever regular expression is inside the parentheses, and indicates the start and end of a group. ※ \g<N> 是用来反向引用(backreferences)的; 如果N是正数, 那么\g<N> 匹配(对应) 从左边数起,第N个括号里的内容; 例如上面的\g<1>匹配Arroz 如果N是0,那么\g<N> 匹配(对应) 整个字符串的内容; 例如上面的\g<0>匹配Hello Arroz, Nihao Arroz |
详见: http://blog.5ibc.net/p/80058.html |
4 ● 反向引用的案例
match(pattern, string, flags=0) returns the first match(返回_sre.SRE_Match对象) from the beginning of the string, if any; otherwise, a "NoneType" object. search(pattern, string, flags=0) returns the first match(返回_sre.SRE_Match对象) within the whole string, if any; otherwise, a "NoneType" object. ※ flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
findall() returns a list of all non-overlapping matches(in the tuple form), if any; otherwise, an empty list. finditer() return an iterator yielding match objects over all non-overlapping matches for the RE pattern in string, if any; otherwise, an empty generator.
match(string[, pos[, endpos]])方法在字符串开头或指定位置进行搜索,模式必须出现在字符串开头或指定位置; search(string[, pos[, endpos]])方法在整个字符串或指定范围中进行搜索; findall(string[, pos[, endpos]])方法在字符串指定范围中查找所有符合正则表达式的字符串并以列表形式返回。 |
m.group() == m.group(0) == 返回模式(pattern)匹配的所有字符,与括号无关 m.group(N) 返回第N组括号(第N个子模式(subpattern))匹配的字符 m.groups() 以tuple的格式, 返回所有括号(子模式)匹配的字符,== (m.group(0), m.group(1), ...) |
import re pat = re.compile(r"(\d{4})-(\d{2})-(\d{2})") m1 = re.match(pat, "2017-09-10, 2017-09-11") print(m1.groups()) # ('2017', '09', '10') print(m1.group()) # '2017-09-10' print(m1.group(0)) #'2017-09-10' ''' m1.group(1) #'2017' m1.group(2) # '09' m1.group(1,2) #('2017', '09') m1.group(3) # '10' m1.group(4) Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group '''
m2 = re.search(pat, "2017-09-10, 2017-09-11") m2.groups() # ('2017', '09', '10') m2.group() # '2017-09-10' ''' m2.group(0) # '2017-09-10' m2.group(1) # '2017' m2.group(2) # '09' m2.group(3) # '10' m2.group(4) Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group '''
lst = re.findall(pat, "2017-09-10, 2017-09-11") print(lst) # [('2017', '09', '10'), ('2017', '09', '11')]
it = re.finditer(pat, "2017-09-10, 2017-09-11") print(it) # <callable_iterator object at 0x0000000002943A20> print('--------------')
for matchnum, match in enumerate(it): print(match.group()) print(match.groups()) for group_num in range(0, len(match.groups())): group_num +=1 print(match.group(group_num)) ''' 2017-09-10 ('2017', '09', '10') 2017 09 10 2017-09-11 ('2017', '09', '11') 2017 09 11 ''' |
5 ● 命名分组(named grouping)
反斜杠加g以及中括号内一个名字,即:\g<name>,对应着命了名的组,named group (?P<name>expr)是分组(grouping): 除了原有的编号外, 再给匹配到的字符串expr指定一个额外的别名 (?P=expr)是反向引用/回溯(back reference): 引用别名为<name>的分组匹配到的字符串
text = "Hello Arroz, Nihao Arroz" ret = re.sub(r"Hello (?P<name>\w+), Nihao (?P=name)", "\g<name>",text) print(ret) # Arroz 注意: (?P=name)是反向引用(reference), (?<name>) |
import re m = re.search(r"\d{4}-(?P<na>\d{2})-\d{2}", "2006-09-03") print(m.group('na')) # 09 |
import re m = re.search(r'(\d{4})-(?:\d{2})-(\d{2})', "2006-09-03") # Non-capturing group(非捕获组) m.groups() # ('2006', '03') m.group(1) # '2006' m.group(2) # '03' # (?:\d{2})这一组被忽略 m.group(3) ''' Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group ''' |
※ MatchObject的另外几个方法:
groupdict(default=None):返回包含匹配的所有命名子模式内容的字典 start([group]):返回指定子模式内容的起始位置 end([group]):返回指定子模式内容的结束位置的前一个位置 span([group]):返回一个包含指定子模式内容起始位置和结束位置前一个位置的元组。 |
import re text = "Hello Arroz, Nihao Alex" pat=re.compile(r"Hello (?P<name1>\w+), Nihao (?P<name2>\w+)") mo= re.search(pat, text) print(mo.group('name1')) # Arroz print(mo.groupdict()) # {'name1': 'Arroz', 'name2': 'Alex'} print(mo.span()) # (0, 23) print(mo.span(0)) # (0, 23) print(mo.span(1)) # (6, 11) print(mo.start(1)) # 6 print(mo.end(1)) # 11 print(mo.span(2)) # (19, 23) |
# fullmatch(pattern, string, flags=0) 尝试把模式作用于整个字符串,返回match对象或None import re text = "Hello Arroz, Nihao Alex" pat=re.compile(r"Hello (?P<name1>\w+), Nihao (?P<name2>\w+)") is_full_match = re.fullmatch(pat, text) print("isfullmatch:", is_full_match) # isfullmatch: <_sre.SRE_Match object; span=(0, 23), match='Hello Arroz, Nihao Alex'> # 如果不完全匹配, 返回:isfullmatch: None |
# escape(string) 将字符串中所有的非字母, 非数字字符转义(escape all non-alphanumerics) print(re.escape('http://www.py thon.org')) # http\:\/\/www\.py\ thon\.org→Pycharm的结果 # 'http\\:\\/\\/www\\.py\\ thon\\.org'→cmd的结果 |
# expand(template) 将匹配到的分组代入template中然后返回。template中可以使用 \id 、\g<id> 、\g<name> 引用分组。id为捕获组的编号,name为命名捕获组的名字。 import re s="abcdefghijklmnopqrstuvwxyz" pattern=r'(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)' m=re.search(pattern,s) print(m.expand(r'\1'), m.expand(r'\10'), m.expand(r'\g<10>')) # a j j
# purge() 清空正则表达式缓存 |
6 ● 文本编辑器(EmEditor, NotePad++)中匹配汉字字符
Python中匹配汉字字符, 用平时见到的统一字名的形式就可以了: [\u4e00-\u9fa5] 但是在文本编辑器(EmEditor, NotePad++)中, 需要把上面的形式改为(x表示十六进制): [\x{4e00}-\x{9fa5}] 或者: [一-龥] 就可以实现匹配中文了.
单独的统一字名加不加中括号都可以. |
详见:http://www.crifan.com/answer_question_notepadplusplus_regular_expression_match_chinese_character |
● 补充
\num 此处的num是一个正整数。例如,"(.)\1"匹配两个连续的相同字符, 如abccde \f 换页符匹配 |