Andrew Ng经典机器学习课程的Python实现(第1部分)
几个月前,我在Coursera(免费大型公开在线课程项目)上完成Andrew Ng机器学习的MOOC教学。对于任何一个想进入人工智能和机器学习世界的人来说,这都是一个很好的入门课程,但其中的项目是用Octave语言编写的。我一直想知道这门课如果用Python的话该有多么神奇,最终我决定重做一遍,这次用Python来完成。
在这一系列的博文中,我打算用Python编写程序。这么做有以下几个原因:
1、这会帮助那些想要Python版本课程的人;
2.、对于有些R语言爱好者来说,他们也愿意学习熟悉的那些算法的Python实现,那会受益匪浅;
基础知识
强烈建议你先看第1周的视频讲座,之后就应该对Python的体系结构有基本的了解。
在这一节中,我们将研究最简单的机器学习算法。
仅有一个变量的线性回归
首先是关于场景的描述。在这里,我们将仅用一个变量来执行线性回归以预测一个食品货车的收益。假设你是一家餐厅的CEO,正在考虑在每个不同的城市开设一家分店,并且在各个城市都有货车,你可以从这些分店获得收益和顾客的相关数据。
ex1data1.txt文件包含了我们线性回归练习的数据集。第一列表示城市的人口,第二列是该城市的食品货车的收益。如果收益为负则表示亏损。
首先,与执行任何机器学习任务一样,我们需要导入一些库
importnumpy as np
import pandas as pd
import matplotlib.pyplot as plt
读取数据并进行可视化
在开始任何任务之前,通过可视化数据来理解数据通常来说是非常有用的。对于这个数据集,可以利用散点图来可视化数据,然而它只有两个属性(收益和用户)。
(在现实生活中我们遇到的许多问题都是多维的,不能仅仅用二维图来表示。要创建多维的表达方式,必须要灵活地运用各种表现形式,如色彩、形状、深度等。)
data = pd.read_csv('ex1data1.txt', header = None) #read from dataset
X = data.iloc[:,0] # read first column
y = data.iloc[:,1] # read second column
m = len(y) # number of training example
data.head() # view first few rows of the data
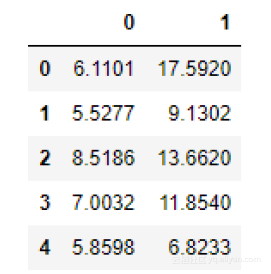
这里我们使用了pandas的read_csv函数来读取以逗号分隔的一组值。此外,我们还使用了head函数来查看数据的前几行。
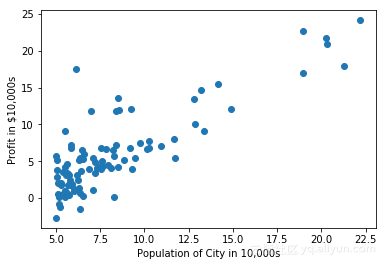
plt.scatter(X, y)
plt.xlabel('Population of City in 10,000s')
plt.ylabel('Profit in $10,000s')
plt.show()
添加拦截项
在下面的代码中,我们给数据添加另一个维度以适应拦截项(这么做的原因已在视频中进行了解释)。我们还将参数theta初始化为0,并把学习率alpha初始化为0.01。
X = X[:,np.newaxis]
y = y[:,np.newaxis]
theta = np.zeros([2,1])
iterations = 1500
alpha = 0.01
ones = np.ones((m,1))
X = np.hstack((ones, X)) # adding the intercept term
使用np.newaxis可以将一维数组(shape: N elements)转换为行向量(shape: N rows, 1 column)或列向量(shape: 1 row, N columns)。在这里,我们将X和y重新排列到列向量里。
下一步,我们将计算成本和梯度下降,Andrew Ng在视频讲座中很好地讲解了这一操作过程。这里我仅提供Andrew Ng在讲座中使用的基于Python的伪代码。
成本计算
defcomputeCost(X, y, theta):
temp = np.dot(X, theta) - y
return np.sum(np.power(temp, 2)) / (2*m)
J = computeCost(X, y, theta)
print(J)
你应该期望看到成本的计算结果是32.07。
用梯度下降法求最优参数
defgradientDescent(X, y, theta, alpha, iterations):
for _ in range(iterations):
temp = np.dot(X, theta) - y
temp = np.dot(X.T, temp)
theta = theta - (alpha/m) * temp
return theta
theta = gradientDescent(X, y, theta, alpha, iterations)
print(theta)
期望的theta值的范围是[-3.6303, 1.1664]。
我们现在有了优化的theta值,利用上面的theta值来计算:
J = computeCost(X, y, theta)
print(J)
上面的输出应该会给你一个比32.07更好的结果:4.483。
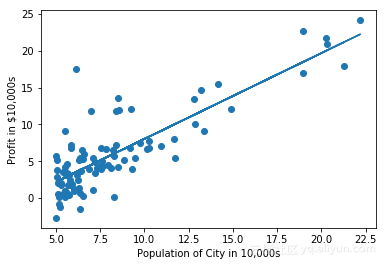
绘制最佳拟合线图
plt.scatter(X[:,1], y)
plt.xlabel('Population of City in 10,000s')
plt.ylabel('Profit in $10,000s')
plt.plot(X[:,1], np.dot(X, theta))
plt.show()
让我们用扩展线性回归的思路来处理多个独立的变量。
多元线性回归
情景描述:
假设你正在出售房子,你想知道近期比较好的市场价格。一个方式是首先收集最近房子买卖的信息,并创建一个房子价格模型。你的任务是基于其它的变量来预测房价:
文件ex1data2.txt包含一组俄勒冈州波特兰市的房子价格数据。第一列是房子的面积,第二列是卧室的数量,第三列是房子的价格。
在前一节中你已经创建了必要的基础环境,这些基础环境也可以很方便地应用在本节中。在这里,将使用我们在上一节中所给的公式进行计算。
Import numpy as np
import pandas as pd
data = pd.read_csv('ex1data2.txt', sep = ',', header = None)
X = data.iloc[:,0:2] # read first two columns into X
y = data.iloc[:,2] # read the third column into y
m = len(y) # no. of training samples
data.head()
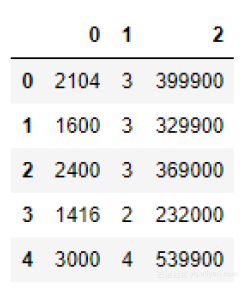
正如在上面看到的那样,我们正在处理的不止是一个独立变量(你在前一节中所学习的概念也适用于这里)。
特征标准化
通过观察这些数据,我们注意到房子的面积大约是卧室数量的1000倍。当特征量级不同的时候,首先执行特征比例缩放操作可以使梯度下降收敛地更快。
我们的任务是:
· 从数据集中减去每个特征的平均值;
· 在减去平均值之后,再按各自的“标准偏差”缩放(分配)特征值;
X = (X - np.mean(X))/np.std(X)
增加拦截项和初始化参数
ones = np.ones((m,1))
X = np.hstack((ones, X))
alpha = 0.01
num_iters = 400
theta = np.zeros((3,1))
y = y[:,np.newaxis]
成本计算
defcomputeCostMulti(X, y, theta):
temp = np.dot(X, theta) - y
return np.sum(np.power(temp, 2)) / (2*m)
J = computeCostMulti(X, y, theta)
print(J)
你应该期望看到一个输出的成本是65591548106.45744。
用梯度下降法求最优参数
defgradientDescentMulti(X, y, theta, alpha, iterations):
m = len(y)
for _ in range(iterations):
temp = np.dot(X, theta) - y
temp = np.dot(X.T, temp)
theta = theta - (alpha/m) * temp
return theta
theta = gradientDescentMulti(X, y, theta, alpha, num_iters)
print(theta)
你的最优参数应该是 [[334302.06399328],[ 99411.44947359], [3267.01285407]]。
我们现在有了优化过的theta值,使用上面输出的theta值。
J = computeCostMulti(X, y, theta)
print(J)
这应该会输出一个比65591548106.45744好很多的值:2105448288.6292474。
现在你已经学会如何用一个或多个独立变量执行线性回归了。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Python Implementation of Andrew Ng’s Machine Learning Course (Part1)》
作者:Srikar
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文