大数据hadoop领域技术总体介绍(各个组件的作用)
2019/2/16 星期六
大数据领域技术总体介绍(各个组件的作用)
1、大数据技术介绍
大数据技术生态体系:
Hadoop 元老级分布式海量数据存储、处理技术系统,擅长离线数据分析
Hbase 基于hadoop 的分布式海量数据库,离线分析和在线业务通吃
Hive sql 基于hadoop 的数据仓库工具,使用方便,功能丰富,使用方法类似SQL
Zookeeper 集群协调服务
Sqoop 数据导入导出工具
Flume 数据采集框架 //经常会结合kafka+flume数据流 或者用于大量的日志收集到hdfs上 日志收集分析大多数企业用elk
Storm 实时流式计算框架,流式处理领域头牌框架
Spark 基于内存的分布式运算框架,一站式处理all in one,新秀,发展势头迅猛
sparkCore //应用开发
SparkSQL //sql操作 类似hive
SparkStreaming //类似于storm
机器学习:
Mahout 基于mapreduce 的机器学习算法库
MLLIB 基于spark 机器学习算法库
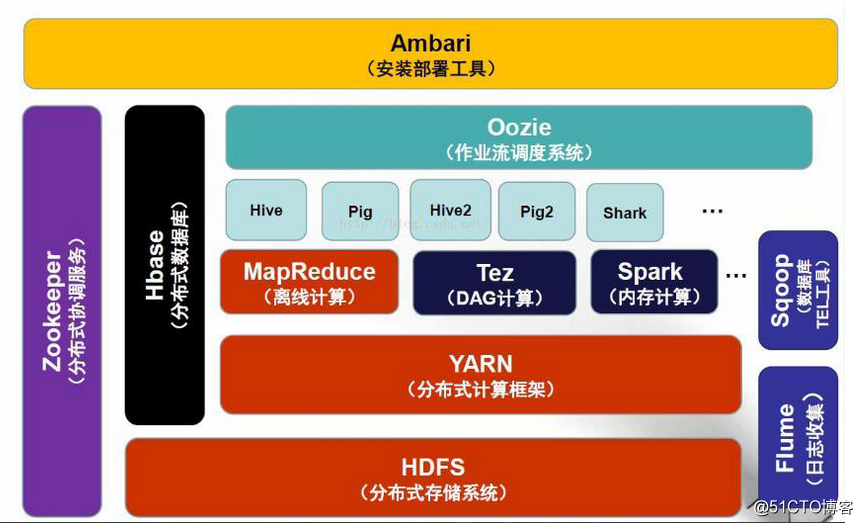
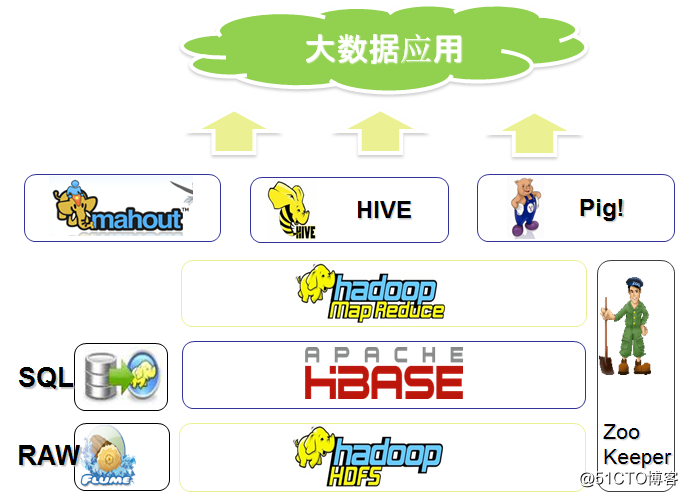
由上图可以看出,大数据hadoop生态圈中类似于一个动物园,zookeeper组件就类似于一个管理者,管理这些动物。//大数据生态圈的组件很多,不知我们上面提到的组件,图中展示的为基本组件。
2、需要由潜到深
一、理解该框架的功能和适用场景
二、使用(安装部署,编程规范,API)
三、运行机制
四、结构原理
五、源码
3、hadoop基本介绍
(1)hadoop 是用于处理(运算分析)海量数据的技术平台,且是采用分布式集群的方式;
(2)hadoop 两个大的功能:
提供海量数据的存储服务;
提供分析海量数据的编程框架及运行平台;
(3)Hadoop 有3大核心组件:
HDFS---- hadoop 分布式文件系统海量数据的存储(集群服务),
MapReduce----分布式运算框架(编程框架)(导jar 包写程序),海量数据运算分析(替代品:storm /spark 等)
Yarn ----资源调度管理集群(可以理解为一个分布式的操作系统,管理和分配集群硬件资源)
(4)使用Hadoop:
可以把hadoop 理解为一个编程框架(类比:structs、spring、hibernate/mybatis),有着自己特定的API 封装和用户编程规范,用户可借助这些API 来实现数据处理逻辑;从另一个角度,hadoop 又可以理解为一个提供服务的软件(类比:数据库服务
oracle/mysql、索引服务solr,缓存服务redis 等),用户程序通过客户端向hadoop集群请求服务来实现特定的功能;
(5)Hadoop 产生的历史
最早来自于google 的三大技术论文:GFS/MAPREDUCE/BIG TABLE
(为什么google 会需要这么一种技术?)
后来经过doug cutting 的“山寨”,出现了java 版本的hdfs mapreduce 和hbase
并成为apache 的顶级项目hadoop ,hbase
经过演化,hadoop 的组件又多出一个yarn(mapreduce+ yarn + hdfs)
而且,hadoop 外围产生了越来越多的工具组件,形成一个庞大的hadoop 生态体系
为什么需要hadoop
在数据量很大的情况下,单机的处理能力无法胜任,必须采用分布式集群的方式进行处理,而用分布式集群的方式处理数据,实现的复杂度呈级数增加,所以,在海量数据处理的需求下,一个通用的分布式数据处理技术框架能大大降低应用开发难度和减少工作量。
hadoop业务的整体开发流程:见图
flume数据采集--->MapReduce清洗---->存入hbase或者hdfs---->hive统计分析---->存入hive表中--->sqoop导入导出--->mysql数据库--->web展示
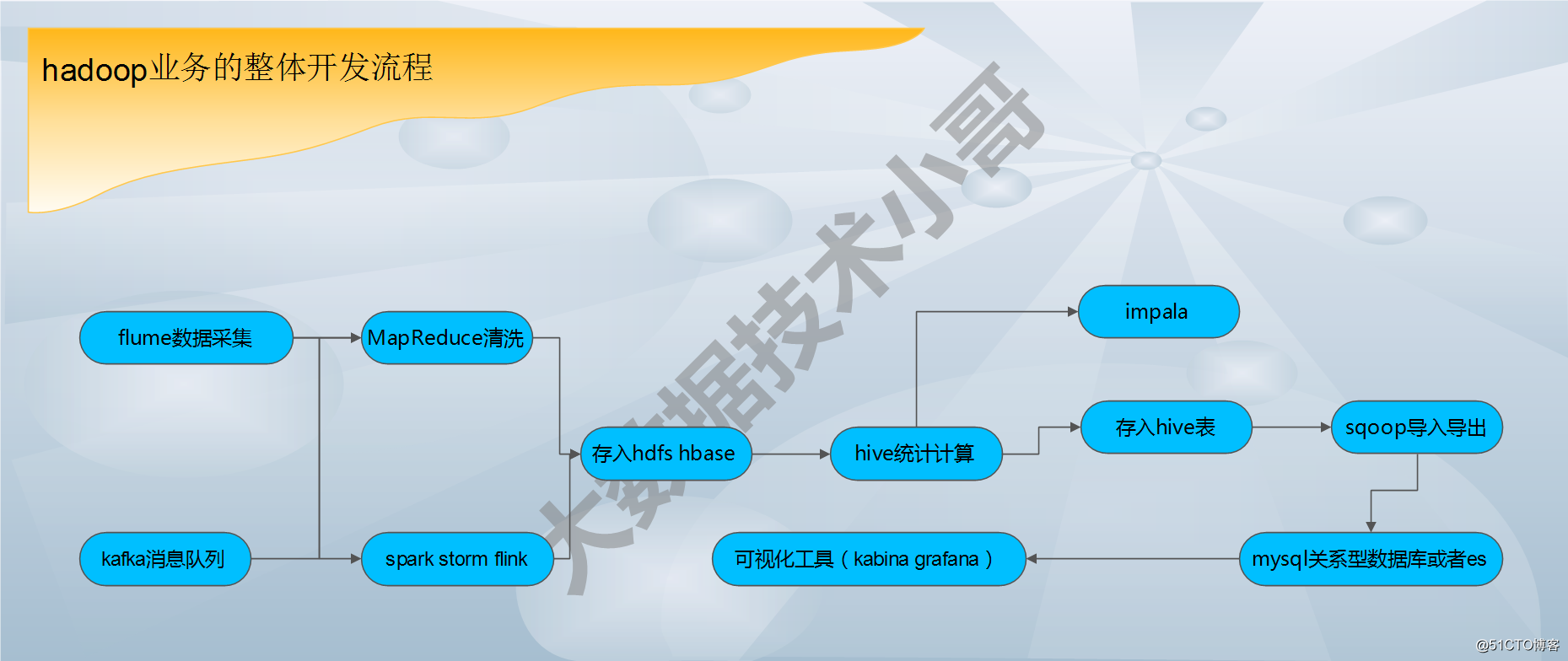
提示:其中我们当数据量非常大的时候,我们可以在flume数据采集节点加入kafka消息队列形成缓存区;在数据清洗阶段我们可以用spark 或者storm flink等内存和实时流算法框架(针对不同的业务场景);存入hadoop中的HBASE或者hdfs中;在数据分析阶段,我们可以用hive或者impala等计算工具;web展示的时候,可以把数据用elk中kabina//数据可视化工具kabina或者Grafana
转载于:https://blog.51cto.com/12445535/2350948