【烈日炎炎战后端】JAVA集合(1.8万字)
JAVA集合(18186字)
- 【HashMap问答】
- [1] HashMap是什么?
- [2] HashMap的底层是怎样的?
- [3] HashMap的树化及其链表化机制及其原因?
- [4] HashMap的扩容机制是怎样的?
- [5] 为什么HashMap初始容量是16?
- [6] 为什么HashMap加载因子(loadFactor)为0.75?
- [7] 为什么桶数组的长度是2^n
- [8] HashMap线程安全吗?为什么?
- [9] 关于HashMap的key值的数据类型不能为基础类型的原因?
- [10] 其他总结
- 【String】
- [1] String为什么设计成final的?
- [2] String 是不可变类为什么值可以修改?
- [3] 字符串拼接的方式有哪些?
- [4] String a = "a" + new String("b") 创建了几个对象?
- [5] String、StringBuilder、StringBuffer的区别?
- 1. 集合常用的有哪几种?
- 2. 集合里哪些是线程安全的?
- 3. list,set有什么区别?
- 4 HashMap, HashTable有什么区别?
- 5. ArrayList,LinkedList有什么区别?
- 6. HashSet,TreeSet是怎么保证元素唯一性的?
- 7. HashSet底层原理?
- 7. TreeMap底层原理?
- 8. LinkedHashMap 底层原理?
【HashMap问答】
图解 Java8 HashMap 常用方法源码
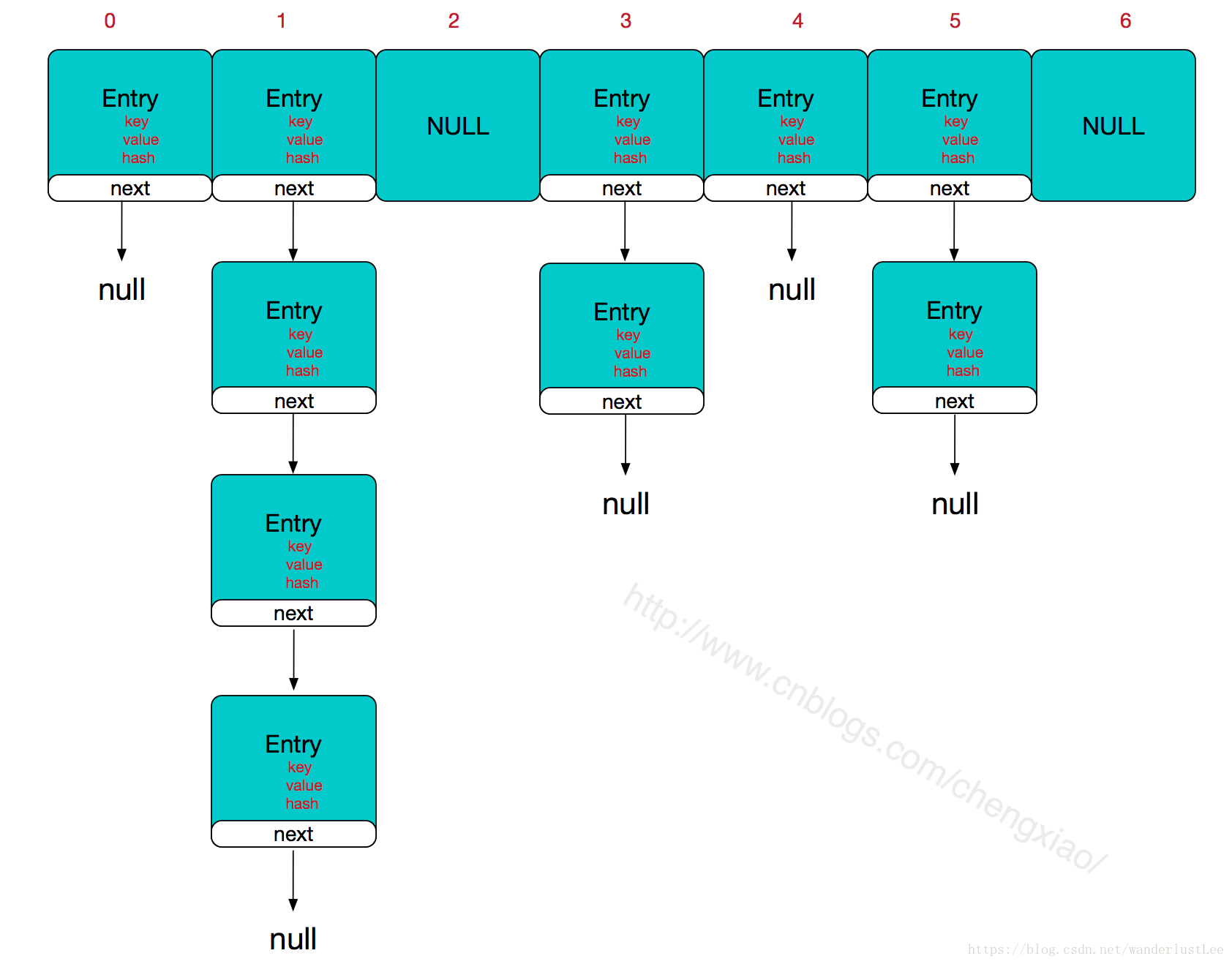
[1] HashMap是什么?
HashMap是map接口下常用的集合,它具有查询快,插入删除方便的优点。
[2] HashMap的底层是怎样的?
HashMap的底层是在JDK1.7的时候,是数组+链表;在JDK1.8的时候,底层是数组+链表+红黑树。
[3] HashMap的树化及其链表化机制及其原因?
一、链表树化的条件是:哈希桶数组的长度大于等于64且链表中节点的个数大于等于8,不满足哈希桶数组的长度大于等于64时执行扩容操作
1.链表长度大于8,官方源码如下:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
2.当满足条件1以后调用treeifyBin方法转化红黑树。该方法中,数组如果长度小于MIN_TREEIFY_CAPACITY(64)就选择扩容,而不是转化为红黑树。
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
原因:
通过复杂度分析,我们都知道,链表取元素是从头结点一直遍历到对应的结点,这个过程的复杂度是O(N) ,而红黑树基于二叉树的结构,查找元素的复杂度为O(logN) ,通过他们的曲线也可以看出来,数据越多红黑树查询次数越低,性能也就越高。所以,当元素个数过多时,用红黑树存储可以提高搜索的效率。
也可以通过泊松分布,我们应该在保证查询性能的情况下尽可能不要树化。冲突后的拉链长度和概率结果如下,可以看到第8个节点几率是滴7个节点的1/14。
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006既然红黑树的效率高,那怎么不一开始就用红黑树存储呢?
这其实是基于空间和时间平衡的考虑,JDK的源码里已经对这个问题做了解释:
* Because TreeNodes are about twice the size of regular nodes, we * use them only when bins contain enough nodes to warrant use * (see TREEIFY_THRESHOLD). And when they become too small (due to * removal or resizing) they are converted back to plain bins.看注释里的前面四行就不难理解,单个 TreeNode 需要占用的空间大约是普通 Node 的两倍,所以只有当包含足够多的 Nodes 时才会转成 TreeNodes,这个足够多的标准就是由 TREEIFY_THRESHOLD 的值(默认值8)决定的。而当桶中节点数由于移除或者 resize (扩容) 变少后,红黑树会转变为普通的链表,这个阈值是 UNTREEIFY_THRESHOLD(默认值6)
树链表化的条件是:树中节点数小于等于6。
**原因:**主要是一个过渡,避免链表和红黑树之间频繁的转换。如果阈值是7的话,删除一个元素红黑树就必须退化为链表,增加一个元素就必须树化,来回不断的转换结构无疑会降低性能,所以阈值才不设置的那么临界。
[4] HashMap的扩容机制是怎样的?
HashMap初始容量是16。
HashMap会使用size记录当前数组的占用个数,当size大于扩容阈值threshold时,将会使用resize()方法进行扩容操作,扩容增量是原容量的1倍(在put方法结束后就有这个函数)。
if (++size > threshold)//特别注意,此处的size是指键值对的个数,而不是当前哈希表的长度
resize(); //特别注意,此处的threshold=capacity*loadFactor,阀值=桶长*负载因子
**举个例子:**初始情况下,HashMap的初始容量(capacity)16,加载因子(loadFactor)为0.75,那么当前的扩容阀值(threshold)为16*0.75=12。当前键值对的个数(size)大于扩容阀值(threshold),扩容成原容量的2倍,即从16扩容到32、64、128 … 但是他不会无限制扩容下去,扩充阈值参数为Integer.MAX_VAULE=1 << 30; 。
[5] 为什么HashMap初始容量是16?
首先,length为2的整数次幂的话,h&(length-1)相当于对length取模,既保证了散列均匀,又提升了效率。
[6] 为什么HashMap加载因子(loadFactor)为0.75?
HashMap加载因子时真实数据和数组长度的比值。如果加载因子太小,就会造成过多的hash冲突,致使效率降低。太小,就会频繁扩容,浪费空间,降低效率。所以它不能太大也不能太小,为什么取(loadFactor)为0.75?与离散数学中的泊松分布有关。
加载因子过高,例如为1,虽然减少了空间开销,提高了空间利用率,hash冲突太多。但同时也增加了查询时间成本;
加载因子过低,例如0.5,虽然可以减少查询时间成本,但是空间利用率很低,同时提高了rehash操作的次数。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,减少扩容操作。
什么是泊松分布?
泊松分布是统计学和概率学常见的离散概率分布,适用于描述单位时间内随机事件发生的次数的概率分布。

等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量。等号的右边,λ 表示事件的频率。
在理想情况下,使用随机哈希码,在扩容阈值(加载因子)为0.75的情况下,节点出现在频率在Hash桶(表)中遵循参数平均为0.5的泊松分布。忽略方差,即X = λt,P(λt = k),其中λt = 0.5的情况,按公式:

计算结果如上述的列表所示,当一个bin中的链表长度达到8个元素的时候,概率为0.00000006,几乎是一个不可能事件。所以我们可以知道,其实常数0.5是作为参数代入泊松分布来计算的,而加载因子0.75是作为一个条件,当HashMap长度为length/size ≥ 0.75时就扩容,在这个条件下,冲突后的拉链长度和概率结果为:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
从上面的表中可以看到当桶中元素到达8个的时候,概率已经变得非常小,也就是说用0.75作为加载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。
那么为什么不可以是0.8或者0.6呢?
HashMap中除了哈希算法之外,有两个参数影响了性能:初始容量和加载因子。初始容量是哈希表在创建时的容量,加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。
**在维基百科来描述加载因子:**对于开放定址法,加载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了加载因子为0.75,超过此值将resize散列表。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少扩容rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,以便减少扩容操作。
选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。
[7] 为什么桶数组的长度是2^n
因为在计算元素该存放的位置的时候,用到的算法是将元素的hashcode与当前map长度-1进行与运算**(i=(n-1)&hash)**。如果map长度为2的幂次,那n-1的二进制一定为11111…的形式。这可以保证每一位参与有有意义的与运算,即可以把结果i控制在0~n-1之间。能够充分利用数组,有效减少哈希冲突。
[8] HashMap线程安全吗?为什么?
link,link
https://blog.csdn.net/swpu_ocean/article/details/88917958
https://blog.csdn.net/swpu_ocean/article/details/88917958
HashMap的线程不安全主要体现在下面两个方面:
- 在JDK1.7中,当并发执行扩容操作时会造成死链和数据丢失的情况。
在扩容时产生死链:。HashMap的线程不安全主要是发生在扩容函数中,即根源是在transfer函数。HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。假设两个线程同时进行resize, A->B 第一线程在处理过程中比较慢,第二个线程已经完成了倒序完成了B-A 那么就出现了循环,B->A->B.
**在扩容时数据丢失:**当多个线程同时进来,检测到总数量超过门限值的时候就会同时调用 resize 操作,各自生成新的数组并 rehash 后赋给该 map 底层的数组,结果最终只有最后一个线程生成的新数组被赋给该 map 底层,其他线程的均会丢失。
- 在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
数据覆盖导致的数据丢失:在JDK1.7中,hashmap的链表采用了尾插法。如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位置还没有其他的数据。假设一种情况,线程A通过if判断,该位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候CPU就把资源让给了线程B,线程A停在了if语句里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线程不安全情况。本来在HashMap中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能就直接给覆盖了。
[9] 关于HashMap的key值的数据类型不能为基础类型的原因?
HashMap是利用HashCode()来区别两个不同的对象。而HashCode()是本地方法,是用C或C++来实现的,即该方法是直接返回对象的内存地址。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
[10] 其他总结
HashMap 有什么特点?
JDK8 之前底层实现是数组 + 链表,JDK8 改为数组 + 链表/红黑树,节点类型从Entry 变更为 Node。主要成员变量包括存储数据的 table 数组、元素数量 size、加载因子 loadFactor。
table 数组记录 HashMap 的数据,每个下标对应一条链表,所有哈希冲突的数据都会被存放到同一条链表,Node/Entry 节点包含四个成员变量:key、value、next 指针和 hash 值。
HashMap 中数据以键值对的形式存在,键对应的 hash 值用来计算数组下标,如果两个元素 key 的 hash 值一样,就会发生哈希冲突,被放到同一个链表上,为使查询效率尽可能高,键的 hash 值要尽可能分散。
HashMap 默认初始化容量为 16,扩容容量必须是 2 的幂次方、最大容量为 1<< 30 、默认加载因子为 0.75。
HashMap 相关方法的源码
JDK8 之前
hash:计算元素 key 的散列值
① 处理 String 类型时,调用 stringHash32 方法获取 hash 值。
② 处理其他类型数据时,提供一个相对于 HashMap 实例唯一不变的随机值 hashSeed 作为计算初始量。
③ 执行异或和无符号右移使 hash 值更加离散,减小哈希冲突概率。
indexFor:计算元素下标
将 hash 值和数组长度-1 进行与操作,保证结果不会超过 table 数组范围。
get:获取元素的 value 值
① 如果 key 为 null,调用 getForNullKey 方法,如果 size 为 0 表示链表为空,返回 null。如果 size 不为 0 说明存在链表,遍历 table[0] 链表,如果找到了 key 为 null 的节点则返回其 value,否则返回 null。
② 如果 key 为 不为 null,调用 getEntry 方法,如果 size 为 0 表示链表为空,返回 null 值。如果 size 不为 0,首先计算 key 的 hash 值,然后遍历该链表的所有节点,如果节点的 key 和 hash 值都和要查找的元素相同则返回其 Entry 节点。
③ 如果找到了对应的 Entry 节点,调用 getValue 方法获取其 value 并返回,否则返回 null。
put:添加元素
① 如果 key 为 null,直接存入 table[0]。
② 如果 key 不为 null,计算 key 的 hash 值。
③ 调用 indexFor 计算元素存放的下标 i。
④ 遍历 table[i] 对应的链表,如果 key 已存在,就更新 value 然后返回旧 value。
⑤ 如果 key 不存在,将 modCount 值加 1,使用 addEntry 方法增加一个节点并返回 null。
resize:扩容数组
① 如果当前容量达到了最大容量,将阈值设置为 Integer 最大值,之后扩容不再触发。
② 否则计算新的容量,将阈值设为 newCapacity x loadFactor 和 最大容量 + 1 的较小值。
③ 创建一个容量为 newCapacity 的 Entry 数组,调用 transfer 方法将旧数组的元素转移到新数组。
transfer:转移元素
① 遍历旧数组的所有元素,调用 rehash 方法判断是否需要哈希重构,如果需要就重新计算元素 key 的 hash 值。
② 调用 indexFor 方法计算元素存放的下标 i,利用头插法将旧数组的元素转移到新数组。
JDK8
hash:计算元素 key 的散列值
如果 key 为 null 返回 0,否则就将 key 的 hashCode 方法返回值高低16位异或,让尽可能多的位参与运算,让结果的 0 和 1 分布更加均匀,降低哈希冲突概率。
put:添加元素
① 调用 putVal 方法添加元素。
② 如果 table 为空或长度为 0 就进行扩容,否则计算元素下标位置,不存在就调用 newNode 创建一个节点(node节点内存储的属性有hash,key,value,next)。
③ 如果存在且是链表,如果首节点和待插入元素的 hash 和 key 都一样,更新节点的 value。
④ 如果首节点是 TreeNode 类型,调用 putTreeVal 方法增加一个树节点,每一次都比较插入节点和当前节点的大小,待插入节点小就往左子树查找,否则往右子树查找,找到空位后执行两个方法:balanceInsert 方法,插入节点并调整平衡、moveRootToFront 方法,由于调整平衡后根节点可能变化,需要重置根节点。
⑤ 如果都不满足,遍历链表,根据 hash 和 key 判断是否重复,决定更新 value 还是新增节点。如果遍历到了链表末尾则添加节点,如果达到建树阈值 7,还需要调用 treeifyBin 把链表重构为红黑树。
⑥ 存放元素后将 modCount 加 1,如果 ++size > threshold ,调用 resize 扩容。
get :获取元素的 value 值
① 调用 getNode 方法获取 Node 节点,如果不是 null 就返回其 value 值,否则返回 null。
② getNode 方法中如果数组不为空且存在元素,先比较第一个节点和要查找元素的 hash 和 key ,如果都相同则直接返回。
③ 如果第二个节点是 TreeNode 类型则调用 getTreeNode 方法进行查找,否则遍历链表根据 hash 和 key 查找,如果没有找到就返回 null。
resize:扩容数组
重新规划长度和阈值,如果长度发生了变化,部分数据节点也要重新排列。
重新规划长度
① 如果当前容量 oldCap > 0 且达到最大容量,将阈值设为 Integer 最大值,return 终止扩容。
② 如果未达到最大容量,当 oldCap << 1 不超过最大容量就扩大为 2 倍。
③ 如果都不满足且当前扩容阈值 oldThr > 0,使用当前扩容阈值作为新容量。
④ 否则将新容量置为默认初始容量 16,新扩容阈值置为 12。
重新排列数据节点
① 如果节点为 null 不进行处理。
② 如果节点不为 null 且没有next节点,那么通过节点的 hash 值和 新容量-1 进行与运算计算下标存入新的 table 数组。
③ 如果节点为 TreeNode 类型,调用 split 方法处理,如果节点数 hc 达到6 会调用 untreeify 方法转回链表。
④ 如果是链表节点,需要将链表拆分为 hash 值超出旧容量的链表和未超出容量的链表。对于hash & oldCap == 0 的部分不需要做处理,否则需要放到新的下标位置上,新下标 = 旧下标 + 旧容量。
Q3:HashMap 为什么线程不安全?
JDK7 存在死循环和数据丢失问题。
数据丢失:
- 并发赋值被覆盖: 在
createEntry方法中,新添加的元素直接放在头部,使元素之后可以被更快访问,但如果两个线程同时执行到此处,会导致其中一个线程的赋值被覆盖。 - 已遍历区间新增元素丢失: 当某个线程在
transfer方法迁移时,其他线程新增的元素可能落在已遍历过的哈希槽上。遍历完成后,table 数组引用指向了 newTable,新增元素丢失。 - 新表被覆盖: 如果
resize完成,执行了table = newTable,则后续元素就可以在新表上进行插入。但如果多线程同时resize,每个线程都会 new 一个数组,这是线程内的局部对象,线程之间不可见。迁移完成后resize的线程会赋值给 table 线程共享变量,可能会覆盖其他线程的操作,在新表中插入的对象都会被丢弃。
死循环: 扩容时 resize 调用 transfer 使用头插法迁移元素,虽然 newTable 是局部变量,但原先 table 中的 Entry 链表是共享的,问题根源是 Entry 的 next 指针并发修改,某线程还没有将 table 设为 newTable 时用完了 CPU 时间片,导致数据丢失或死循环。
JDK8 在 resize 方法中完成扩容,并改用尾插法,不会产生死循环,但并发下仍可能丢失数据。可用 ConcurrentHashMap 或 Collections.synchronizedMap 包装成同步集合。
【String】
[1] String为什么设计成final的?
String 类和其存储数据的成员变量 value 字节数组都是 final 修饰的,final 修饰类则此类不可被继承,修饰数组则数组不可变。这是为了保证它的线程安全。
[2] String 是不可变类为什么值可以修改?
对一个 String 对象的任何修改实际上都是创建一个新 String 对象,再引用该对象。只是修改 String 变量引用的对象,没有修改原 String 对象的内容。
[3] 字符串拼接的方式有哪些?
-
直接用
+,底层用 StringBuilder 实现。只适用小数量,如果在循环中使用+拼接,相当于不断创建新的 StringBuilder 对象再转换成 String 对象,效率极差。 -
使用 String 的 concat 方法,该方法中使用
Arrays.copyOf创建一个新的字符数组 buf 并将当前字符串 value 数组的值拷贝到 buf 中,buf 长度 = 当前字符串长度 + 拼接字符串长度。之后调用getChars方法使用System.arraycopy将拼接字符串的值也拷贝到 buf 数组,最后用 buf 作为构造参数 new 一个新的 String 对象返回。效率稍高于直接使用+。 -
使用 StringBuilder 或 StringBuffer,两者的
append方法都继承自 AbstractStringBuilder,该方法首先使用Arrays.copyOf确定新的字符数组容量,再调用getChars方法使用System.arraycopy将新的值追加到数组中。StringBuilder 是 JDK5 引入的,效率高但线程不安全。StringBuffer 使用 synchronized 保证线程安全。
[4] String a = “a” + new String(“b”) 创建了几个对象?
常量和常量拼接仍是常量,结果在常量池,只要有变量参与拼接结果就是变量,存在堆。
使用字面量时只创建一个常量池中的常量,使用 new 时如果常量池中没有该值就会在常量池中新创建,再在堆中创建一个对象引用常量池中常量。因此 String a = "a" + new String("b") 会创建四个对象,常量池中的 a 和 b,堆中的 b 和堆中的 ab。
[5] String、StringBuilder、StringBuffer的区别?
String:不可变,故线程不安全
StringBuilder:可变,线程不安全
StringBuffer:可变,内部使用 synchronized 进行同步,线程安全
1. 集合常用的有哪几种?
从map,list,set三大接口下分类别回答
- map接口下的:
- HashMap(首先想起最常用的hashmap,无序,线程不安全,底层是数组加链表加红黑树),
- HashTable(然后想起线程安全的hashtable),
- HashTree(然后想起有序的hashtree,底层是红黑树),
- LinkedHashMap(然后想起有序的hashtree,底层是红黑树),
- ConcurrentHashMap(然后想起有序的hashtree,底层是双向链表加数组加链表加红黑树,线程安全)
ConcurrentHashMap结合了HashMap和Hashtable二者的优势
- List接口下的:
- ArrayList(底层为数组的arraylist,线程不安全),
- LinkedList(底层为链表的的LinkedList,线程不安全),
- Stack(常用的栈,继承自Vector,底层是通过数组实现的,线程安全)
- Vector(底层是通过数组实现的,线程安全)
-
Set接口下的:
- HashSet(HashSet底层使用了Hash表实现),
- TreeSet(TreeSet底层使用了红黑树来实现),
- LinkedHashSet( LinkedHashSet是具有可预知迭代顺序的Set接口的哈希表和链接列表实现)
2. 集合里哪些是线程安全的?
vector(syn锁), stack(syn锁), hashtable(syn锁),ConcurrentHashMap(segment分段锁或者细粒度锁)。
3. list,set有什么区别?
最主要的区别,list包含重复元素,set不包含重复元素。
4 HashMap, HashTable有什么区别?
- 跟HashMap相比Hashtable是线程安全的,适合在多线程的情况下使用,但是他在对数据操作的时候都会上synchronzied锁,所以效率比较低下。
- Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。这是因为Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,ConcurrentHashMap同理。
- 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。Dictionary 是 JDK 1.0 添加的,貌似没人用过这个,我也没用过。
- 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
所以,当其他线程改变了HashMap 的结构,如:增加、删除元素,将会抛出ConcurrentModificationException 异常,而 Hashtable 则不会。
fail-fast是啥?
**快速失败(fail—fast)**是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
他的原理是啥?
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
Tip:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。
因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
说说他的场景?
java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)算是一种安全机制吧。
5. ArrayList,LinkedList有什么区别?
ArrayList底层是数组,方便查找,不方便增加删除元素。LinkedList底层是链表,方便增删,但是查找不方便。
从名字可以推想出底层
从底层可以推想出其特点
Q1: 说一说 ArrayList
ArrayList 是容量可变的非线程安全列表,使用数组实现,集合扩容时会创建更大的数组,把原有数组复制到新数组。支持对元素的快速随机访问,但插入与删除速度很慢。ArrayList 实现了 RandomAcess 标记接口,如果一个类实现了该接口,那么表示使用索引遍历比迭代器更快。
elementData是 ArrayList 的数据域,被 transient 修饰,序列化时会调用 writeObject 写入流,反序列化时调用 readObject 重新赋值到新对象的 elementData。原因是 elementData 容量通常大于实际存储元素的数量,所以只需发送真正有实际值的数组元素。
size 是当前实际大小,elementData 大小大于等于 size。
**modCount **记录了 ArrayList 结构性变化的次数,继承自 AbstractList。所有涉及结构变化的方法都会增加该值。expectedModCount 是迭代器初始化时记录的 modCount 值,每次访问新元素时都会检查 modCount 和 expectedModCount 是否相等,不相等就会抛出异常。这种机制叫做 fail-fast,所有集合类都有这种机制。
Q2:说一说 LinkedList
LinkedList 本质是双向链表,与 ArrayList 相比插入和删除速度更快,但随机访问元素很慢。除继承 AbstractList 外还实现了 Deque 接口,这个接口具有队列和栈的性质。成员变量被 transient 修饰,原理和 ArrayList 类似。
LinkedList 包含三个重要的成员:size、first 和 last。size 是双向链表中节点的个数,first 和 last 分别指向首尾节点的引用。
LinkedList 的优点在于可以将零散的内存单元通过附加引用的方式关联起来,形成按链路顺序查找的线性结构,内存利用率较高。
6. HashSet,TreeSet是怎么保证元素唯一性的?
- HashSet利用的是hashmap中的key不能唯一的原则。通过判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true。
- TreeSet底层保证元素唯一性是通过Comparable或者Comparator接口实现。
7. HashSet底层原理?
1. add(Object obj)方法:用于向Set集合中添加元素,添加成功返回true,否则返回false。
public boolean add(E e) {
//map中put方法,如果添加成功返回null,添加失败返回oldValue(旧值)。
return map.put(e, PRESENT)==null;
}
在add方法中,实际上是HashMap对象在调用put方法,而在put方法中其实把我们在add方法中传入的元素赋给了HashMap对象中的key,而对于HashMap对象key不能重复,因此add方法无法添加重复的对象。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2. iterator():返回在此Set中的元素上进行迭代的迭代器。
public Iterator<E> iterator() {
return map.keySet().iterator();
}
3. hashset为什么没有put方法
因为它不能重复,你不能保证你不会存入相同的数据,那么当放入两个相同的数据时,顺序就乱了,所以无法通过下标索引,如果你想判断内部是否有元素时,可以用contains方法。
public boolean contains(Object o) {
return map.containsKey(o);
}
7. TreeMap底层原理?
1.TreeMap实现了SortedMap接口,保证了有序性。默认的排序是根据key值进行升序排序,也可以重写comparator方法来根据value进行排序具体取决于使用的构造方法。不允许有null值null键。TreeMap是线程不安全的。
2. TreeMap基于红黑树(Red-Black tree)实现。TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}
8. LinkedHashMap 底层原理?
https://www.cnblogs.com/xiaowangbangzhu/p/10445574.html
针对LinkedHashMap 的总结有一下几点
1.LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构。该结构由数组和链表+红黑树 在此基础上LinkedHashMap 增加了一条双向链表,保持遍历顺序和插入顺序一致的问题。
2. 在实现上,LinkedHashMap 很多方法直接继承自 HashMap(比如put remove方法就是直接用的父类的),仅为维护双向链表覆写了部分方法(get()方法是重写的)。
3.LinkedHashMap使用的键值对节点是Entity 他继承了hashMap 的Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表.
4.链表的建立过程是在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新
5.LinkedHashMap 允许使用null值和null键, 线程是不安全的,虽然底层使用了双线链表,但是增删相快了。因为他底层的Entity 保留了hashMap node 的next 属性。
6.如何实现迭代有序?
重新定义了数组中保存的元素Entry(继承于HashMap.node),该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。仍然保留next属性,所以既可像HashMap一样快速查找,
用next获取该链表下一个Entry,也可以通过双向链接,通过after完成所有数据的有序迭代.
7.竟然inkHashMap 的put 方法是直接调用父类hashMap的,但在 HashMap 中,put 方法插入的是 HashMap 内部类 Node 类型的节点,该类型的节点并不具备与 LinkedHashMap 内部类 Entry 及其子类型节点组成链表的能力。那么,LinkedHashMap 是怎样建立链表的呢?
虽然linkHashMap 调用的是hashMap中的put 方法,但是linkHashMap 重写了,了一部分方法,其中就有
newNode(int hash, K key, V value, Node<K,V> e)
linkNodeLast(LinkedHashMap.Entry<K,V> p)
这两个方法就是 第一个方法就是新建一个 linkHasnMap 的Entity 方法,而 linkNodeLast 方法就是为了把Entity 接在链表的尾部。
8.链表节点的删除过程
与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现,但是LinkHashMap 重写了removeNode()方法 afterNodeRemoval()方法,该removeNode方法在hashMap 删除的基础上有调用了afterNodeRemoval 回调方法。完成删除。
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点