问题:如何将pdf文件中指定的表格数据提取出来?
尝试过的工具包有:pdfbox、tabula。最终选用tabula
两种工具的比较
- pdfbox
其中,pdfbox能将pdf中的内容直接提取成String,代码片段:
public static void readPdf(String path) { try { PDDocument document = PDDocument.load(new File(path)); PDFTextStripper textStripper = new PDFTextStripper(); textStripper.setSortByPosition(true); String text = textStripper.getText(document); System.out.println(text); document.close(); } catch (IOException e) { e.printStackTrace(); } }
但是如果遇到类似以下表格数据时,会有格式损失。无论中间有几个空的单元格,最终只会转为1个制表位字符(/t)。
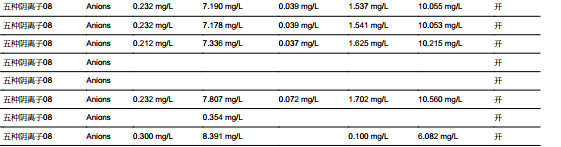
input1.pdf
转换为String后是这样的:

pdfbox优点:方便快捷,使用简单,maven添加依赖后,使用PDFTextStripper.getText()即可提取文本。
pdfbox缺点:提取带有连续的空单元格的表格数据时,有格式丢失。
- tabula
重点介绍tabula,虽然底层也是用pdfbox实现的,但是经过封装后的tabula更适合提取复杂格式的表格。
同样的pdf表格,转换为csv后,是这样的:

output1.csv
可以说是完美还原了。
继续尝试转换其他格式的表格。

input2.pdf
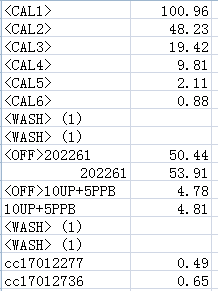
output2.csv

input3.pdf

output3.csv
测试结果:input1、input2基本可以还原,input3有部分差异,但通过BufferedReader读出来的值和pdf基本一致。
tabula的使用
1. 获取
1.1 获取源码
从https://github.com/tabulapdf/tabula-java下载tabula-java-master.zip,使用Eclipse将tabula打成jar包,然后将jar引用到自己的工程中。也可以直接下载tabula-1.0.2-jar-with-dependencies.jar到本地。
1.2 获取Windows客户端工具
从https://tabula.technology下载tabula-win-1.2.0.zip到本地,解压后运行tabula.exe即可使用。
2. 使用
2.1 解读README.md
## Usage Examples `tabula-java` provides a command line application: $ java -jar target/tabula-1.0.2-jar-with-dependencies.jar --help
usage: tabula [-a <AREA>] [-b <DIRECTORY>] [-c <COLUMNS>] [-d] [-f <FORMAT>] [-g] [-h] [-i] [-l] [-n] [-o <OUTFILE>] [-p <PAGES>] [-r] [-s <PASSWORD>] [-t] [-u] [-v]
Tabula helps you extract tables from PDFs -a,--area <AREA> Portion of the page to analyze. Accepts top, left,bottom,right. Example: --area 269.875,12.75,790.5,561. If all values are between 0-100 (inclusive) and preceded by '%', input will be taken as % of actual height or width of the page. Example: --area %0,0,100,50. To specify multiple areas, -a option should be repeated. Default is entire page -b,--batch <DIRECTORY> Convert all .pdfs in the provided directory. -c,--columns <COLUMNS> X coordinates of column boundaries. Example --columns 10.1,20.2,30.3 -d,--debug Print detected table areas instead of processing. -f,--format <FORMAT> Output format: (CSV,TSV,JSON). Default: CSV -g,--guess Guess the portion of the page to analyze per page. -h,--help Print this help text. -i,--silent Suppress all stderr output. -l,--lattice Force PDF to be extracted using lattice-mode extraction (if there are ruling lines separating each cell, as in a PDF of an Excel spreadsheet) -n,--no-spreadsheet [Deprecated in favor of -t/--stream] Force PDF not to be extracted using spreadsheet-style extraction (if there are no ruling lines separating each cell) -o,--outfile <OUTFILE> Write output to <file> instead of STDOUT. Default: - -p,--pages <PAGES> Comma separated list of ranges, or all. Examples: --pages 1-3,5-7, --pages 3 or --pages all. Default is --pages 1 -r,--spreadsheet [Deprecated in favor of -l/--lattice] Force PDF to be extracted using spreadsheet-style extraction (if there are ruling lines separating each cell, as in a PDF of an Excel spreadsheet) -s,--password <PASSWORD> Password to decrypt document. Default is empty -t,--stream Force PDF to be extracted using stream-mode extraction (if there are no ruling lines separating each cell) -u,--use-line-returns Use embedded line returns in cells. (Only in spreadsheet mode.) -v,--version Print version and exit.
其中一些附加参数可视情况选用。
-a:表示指定某个矩形区域,程序只会对此区域进行解析,类似pdfbox的PDFTextStripperByArea.addRegion()。-a后跟4个值,以逗号分隔。分别表示:
区域上边界到页面上边界的距离(或百分比)
区域左边界到页面左边界的距离(或百分比)
区域下边界到页面上边界的距离(或百分比)
区域右边界到页面左边界的距离(或百分比)
以%开头时表示百分比,比如-a %10,0,90,100。
-o:表示将结果输出到文件,后面跟文件路径
-p:表示提取指定页,后面跟数字,如果不指定则默认为1
-t:表示按流的方式提取,遇到合并单元格时使用
2.2 命令行运行
使用cmd命令行工具直接运行jar包
java -jar tabula-1.0.2.jar E:\tmp\input\input1.pdf -o E:\tmp\output\output1.csv

2.3 程序内调用
String cmd = "java -jar tabula-1.0.2.jar E:\tmp\input\input1.pdf -o E:\tmp\output\output1.csv";
Runtime.getRuntime().exec();