2019独角兽企业重金招聘Python工程师标准>>> 
To build a processor topology using the Streams DSL, developers can apply the KStreamBuilder class, which is extended from the TopologyBuilder. A simple example is included with the source code for Kafka in the streams/examples package. The rest of this section will walk through some code to demonstrate the key steps in creating a topology using the Streams DSL, but we recommend developers to read the full example source codes for details.
使用Streams DSL,开发者可以使用KStreamBuilder类,它时TopologyBuilder的子类。在Kafka元码的streams/examples包中可以找到简单示例。下面通过一些代码来一步步地路正如何创建一个拓扑的关键步骤。
Duality of Streams and Tables流和表的对偶性
Before we discuss concepts such as aggregations in Kafka Streams we must first introduce tables, and most importantly the relationship between tables and streams: the so-called stream-table duality. Essentially, this duality means that a stream can be viewed as a table, and vice versa. Kafka's log compaction feature, for example, exploits this duality.
在讨论Kafka Streams中aggregation概念之前,我们需要介绍tables的概念,以及tables和streams最重要的关系:所谓的流-表对偶性。本质上,对偶性意味着一个流可以被看作一个表,反之亦然。例如,Kafka‘s log compaction feature利用了这种对偶性。
A simple form of a table is a collection of key-value pairs, also called a map or associative array. Such a table may look as follows:
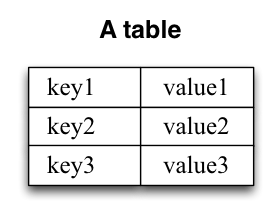
The stream-table duality describes the close relationship between streams and tables.流-表对偶性描述了streams和tables之间的密切联系。
- Stream as Table: A stream can be considered a changelog of a table, where each data record in the stream captures a state change of the table. A stream is thus a table in disguise, and it can be easily turned into a "real" table by replaying the changelog from beginning to end to reconstruct the table. Similarly, in a more general analogy, aggregating data records in a stream - such as computing the total number of pageviews by user from a stream of pageview events - will return a table (here with the key and the value being the user and its corresponding pageview count, respectively).一个stream可以被看作一张表的变更记录,stream中的每条数据记录获取表中的每次状态改变。一个流可以“装扮”为表,它可以轻易地转换成一张”real“表,通过从头到尾重新操作变更记录来重构这张表。类似地,更一般性的类比,在一个stream中聚合数据记录,比如从一个pageview时间流中根据用户来计算pageviews的记录数-将返回一张表(这里的键和值分别是用户和其对应的页面数).
- Table as Stream: A table can be considered a snapshot, at a point in time, of the latest value for each key in a stream (a stream's data records are key-value pairs). A table is thus a stream in disguise, and it can be easily turned into a "real" stream by iterating over each key-value entry in the table.一个表可以被看作一个快照,某个时间点,在流中对于每个key最新的value(每个stream的数据记录是key-value对)。一个表可以“装扮”为表,它可以轻易地转换为一个“real”流,通过迭代表中的每个key-value条目。
Let's illustrate this with an example. Imagine a table that tracks the total number of pageviews by user (first column of diagram below). Over time, whenever a new pageview event is processed, the state of the table is updated accordingly. Here, the state changes between different points in time - and different revisions of the table - can be represented as a changelog stream (second column).
让我们使用一个例子来说明。想象一张表来跟中用户的pageviews数。随着时间流逝,当一个新的pageview 时间执行,表的状态会随之更新。这里,两个时间点上的状态更新-表的不同更新-可以被看作是日志变更流。
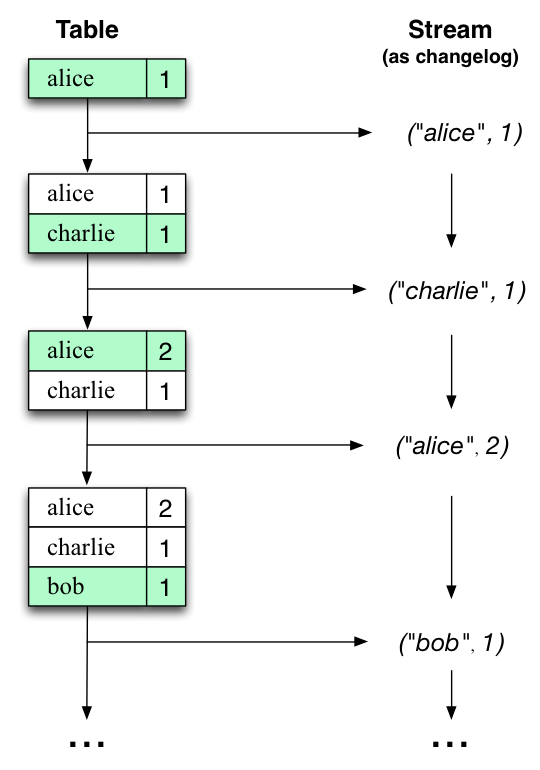
Interestingly, because of the stream-table duality, the same stream can be used to reconstruct the original table (third column):
有趣的是,由于stream-table对偶性,流也可以被用来重构原始表。
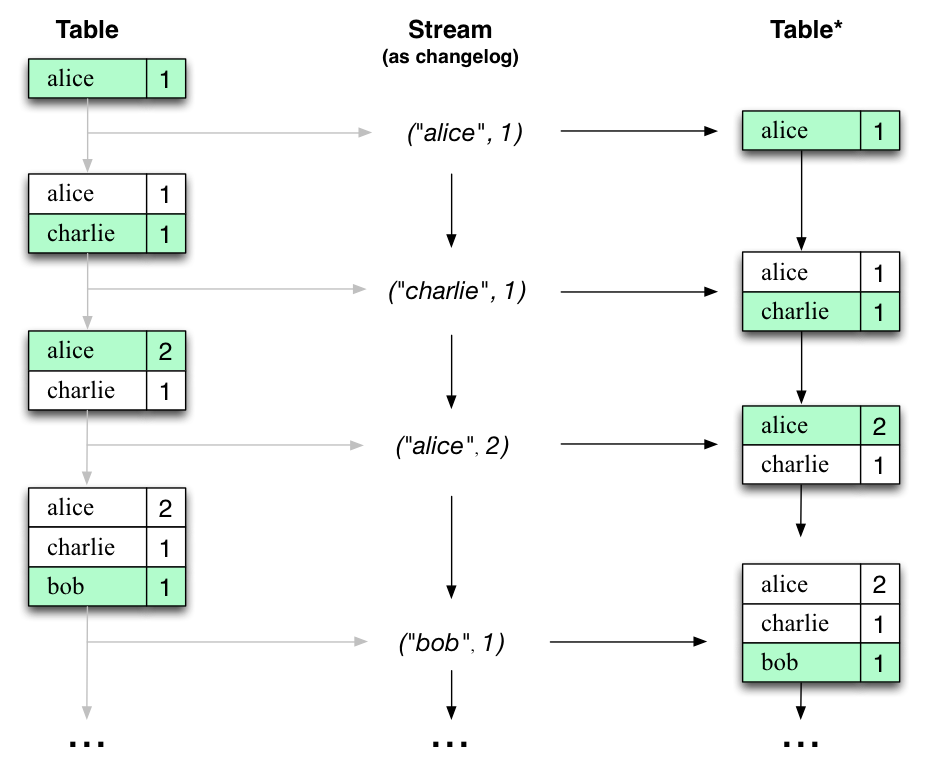
The same mechanism is used, for example, to replicate databases via change data capture (CDC) and, within Kafka Streams, to replicate its so-called state stores across machines for fault-tolerance. The stream-table duality is such an important concept that Kafka Streams models it explicitly via the KStream, KTable, and GlobalKTableinterfaces, which we describe in the next sections.
KStream, KTable, and GlobalKTable
The DSL uses three main abstractions. A KStream is an abstraction of a record stream, where each data record represents a self-contained datum in the unbounded data set. AKTable is an abstraction of a changelog stream, where each data record represents an update. More precisely, the value in a data record is considered to be an update of the last value for the same record key, if any (if a corresponding key doesn't exist yet, the update will be considered a create). Like a KTable, a GlobalKTable is an abstraction of a changelog stream, where each data record represents an update. However, a GlobalKTable is different from a KTable in that it is fully replicated on each KafkaStreams instance.GlobalKTable also provides the ability to look up current values of data records by keys. This table-lookup functionality is available through join operations. To illustrate the difference between KStreams and KTables/GlobalKTables, let's imagine the following two data records are being sent to the stream:
DSL使用最重要的三种抽象。KStream是记录流的抽象,在无边界数据集合中,每个数据记录代表独立的数据。KTable是一个变更记录流,每条数据记录代表一次更新。更确切地说,数据记录的value是对于每条记录key的最新value的更新;如果相应的键不存在,更新将变为一个创建操作。跟KTable类似,GlobalKTable是一个变更记录流的抽象,每条记录也代表一次更新。但是GlobalKTable与KTable不同的地方是,它复制到每个KafkaStreams instance中(有点向mapreduce的mapjoin、distributed)。GlobalKTable提供了通过key查找当前value的功能。table-lookup功能在进行 join operations时是有用的。为了说明KStreams 和 KTables/GlobalKTables之间的区别,我们想象下面两个发送到流的数据记录:
("alice", 1) --> ("alice", 3) |
If these records a KStream and the stream processing application were to sum the values it would return 4. If these records were a KTable or GlobalKTable, the return would be 3, since the last record would be considered as an update.
在Kstream程序处理会将value进行sum,返回值为4。如果是KTable是GlobalKTable中的数据,返回值为3,因为最后一条记录至被看作为一次更新操作。
Create Source Streams from Kafka
Either a record stream (defined as KStream) or a changelog stream (defined as KTable or GlobalKTable) can be created as a source stream from one or more Kafka topics (for KTable and GlobalKTable you can only create the source stream from a single topic).
不管是record stream (defined as KStream) 还是 a changelog stream (defined as KTable or GlobalKTable)都能从一个和多个Kafka topics中创建,但是KTable and GlobalKTable只能从单独的topic中创建source straem。
KStreamBuilder builder = new KStreamBuilder();
KStream<String, GenericRecord> source1 = builder.stream("topic1", "topic2");
KTable<String, GenericRecord> source2 = builder.table("topic3", "stateStoreName");
GlobalKTable<String, GenericRecord> source2 = builder.globalTable("topic4", "globalStoreName"); |
Windowing a stream
A stream processor may need to divide data records into time buckets, i.e. to window the stream by time. This is usually needed for join and aggregation operations, etc. Kafka Streams currently defines the following types of windows:
stream processor可能需要将数据记录分散到时间段内,将流按时间切分成窗口。这通常对与join和aggregation操作是需要的。Kafka Streams现在定义了如下几种类型的窗口:
- Hopping time windows are windows based on time intervals. They model fixed-sized, (possibly) overlapping windows. A hopping window is defined by two properties: the window's size and its advance interval (aka "hop"). The advance interval specifies by how much a window moves forward relative to the previous one. For example, you can configure a hopping window with a size 5 minutes and an advance interval of 1 minute. Since hopping windows can overlap a data record may belong to more than one such windows.
跳跃时间窗是基于时间间隔的窗口。此模式窗口固定大小,(可能)出现重叠。通过两个属性来定义跳跃窗口:窗口的大小和其前进时间间隔(又叫“跳跃”)。前进时间间隔指定窗口距前一个窗口向前移动多少。例如,你可以配置一个跳跃窗口,其中窗口大小为五分钟,前进时间间隔是一分钟。由于跳跃窗口可以覆盖重叠,因此数据记录可以属于多个这样的窗口。
- Tumbling time windows are a special case of hopping time windows and, like the latter, are windows based on time intervals. They model fixed-size, non-overlapping, gap-less windows. A tumbling window is defined by a single property: the window's size. A tumbling window is a hopping window whose window size is equal to its advance interval. Since tumbling windows never overlap, a data record will belong to one and only one window.滚动时间窗是跳跃时间窗口的特殊情况,并且像后者一样,也是基于时间间隔。但是其模型中时间间隔固定大小,时间窗口不会重叠,相互之间也不会产生间隔。
滚动时间窗是通过单个属性来定义的:时间窗口的大小。滚动时间窗等于其前进间隔的跳跃窗口大小。由于滚动时间窗不会重叠,因此每条数据记录仅属于一个窗口。 - Sliding windows model a fixed-size window that slides continuously over the time axis; here, two data records are said to be included in the same window if the difference of their timestamps is within the window size. Thus, sliding windows are not aligned to the epoch, but on the data record timestamps. In Kafka Streams, sliding windows are used only for join operations, and can be specified through the
JoinWindowsclass.滑动时间窗是基于时间轴连续滑动的固定大小时间窗口。如果它们时间戳的差在窗口大小内,则两个数据记录包含在同一个窗口中。因此,滑动时间窗不和epoch对准,而是以数据的时间戳对准。在Kafka Streams中,滑动时间窗仅用于join操作,并且可通过JoinWindows类指定。 - Session windows are used to aggregate key-based events into sessions. Sessions represent a period of activity separated by a defined gap of inactivity. Any events processed that fall within the inactivity gap of any existing sessions are merged into the existing sessions. If the event falls outside of the session gap, then a new session will be created. Session windows are tracked independently across keys (e.g. windows of different keys typically have different start and end times) and their sizes vary (even windows for the same key typically have different sizes); as such session windows can't be pre-computed and are instead derived from analyzing the timestamps of the data records.会话时间窗是基于key事件聚合成会话。
会话表示一个活动期间,由不活动间隔分割定义的。在任何现有会话的不活动间隔内处理的任何事件都将合并到现有的会话中。如果事件在会话间隔之外,那么将创建新的会话。会话窗口独立的跟踪的key(即,不同key的窗口通常开始和结束时间不同)和它们大小的变化(即使相同的key的窗口大小通常都不同)。因为这样session窗口不能被预先计算,而是从数据记录的时间戳分析获取的。
In the Kafka Streams DSL users can specify a retention period for the window. This allows Kafka Streams to retain old window buckets for a period of time in order to wait for the late arrival of records whose timestamps fall within the window interval. If a record arrives after the retention period has passed, the record cannot be processed and is dropped.在Kafka Streams DSL中,用户可以指定时间窗的保留周期。这允许Kafka Streams保留旧的窗口段一段时间,为了等待晚到达的数据记录(它们的时间戳可能落在窗口间隔内的)。如果记录在保留周期之后到达,则不能处理,并舍弃掉。
Late-arriving records are always possible in real-time data streams. However, it depends on the effective time semantics how late records are handled. Using processing-time, the semantics are "when the data is being processed", which means that the notion of late records is not applicable as, by definition, no record can be late. Hence, late-arriving records only really can be considered as such (i.e. as arriving "late") for event-time or ingestion-time semantics. In both cases, Kafka Streams is able to properly handle late-arriving records.在实时数据流中,总是可能出现晚到达的记录,这取决于数据记录持有的有效时间语义。使用processing-time,语义是何时处理数据,这意味着延迟记录的概念并不适用这个;因为根据定义,没有记录会晚到达。因此,晚到的记录实际上可以被认为是event-time或ingestion-time语义。在这两种情况下,Kafka Streams能正常处理晚到的记录。
Join multiple streams
A join operation merges two streams based on the keys of their data records, and yields a new stream. A join over record streams usually needs to be performed on a windowing basis because otherwise the number of records that must be maintained for performing the join may grow indefinitely. In Kafka Streams, you may perform the following join operations:
join操作基于其数据记录的key来合并两个流,并产生一个新的流。在记录流上执行join操作通常需要在时间窗基础上操作,因为如果不这样的化,执行join操作需要保持无限增长的记录(这是不现实的)。在Kafka Streams中,可以执行以下连接操作:
- KStream-to-KStream Joins are always windowed joins, since otherwise the memory and state required to compute the join would grow infinitely in size. Here, a newly received record from one of the streams is joined with the other stream's records within the specified window interval to produce one result for each matching pair based on user-provided
ValueJoiner. A newKStreaminstance representing the result stream of the join is returned from this operator.KStream-to-KStream Joins始终基于窗口进行,如果不这样的话,用于计算的内存和状态需要无限增长。这里,从流中接收的新记录与指定时间窗的其他流中记录进行join操作,每个匹配会生成一个结果(基于用户提供的ValueJoiner)。新KStream实例代表从此操作返回join流的结果。
- KTable-to-KTable Joins are join operations designed to be consistent with the ones in relational databases. Here, both changelog streams are materialized into local state stores first. When a new record is received from one of the streams, it is joined with the other stream's materialized state stores to produce one result for each matching pair based on user-provided ValueJoiner. A new
KTableinstance representing the result stream of the join, which is also a changelog stream of the represented table, is returned from this operator.KTable-to-KTable Joins设计成与关系型数据库中的join操作一致。这里,两个日志变更流具象成本地状态存储。当从流中接收新记录时,它与其他流的状态存储进行join操作,每个匹配生成一个结果(基于用户提供的ValueJoiner)。新KTable实例表示
join流的结果,它也是一个显示表的变更日志流。 - KStream-to-KTable Joins allow you to perform table lookups against a changelog stream (
KTable) upon receiving a new record from another record stream (KStream). An example use case would be to enrich a stream of user activities (KStream) with the latest user profile information (KTable). Only records received from the record stream will trigger the join and produce results viaValueJoiner, not vice versa (i.e., records received from the changelog stream will be used only to update the materialized state store). A newKStreaminstance representing the result stream of the join is returned from this operator.
KStream-to-KTable Joins允许当你从另一个记录流(KStream)接受到新记录时,针对变更日志流(KTabloe)执行表查询。例如,用最新的用户个人信息(KTable)来填充丰富用户的活动流(KStream)。只有从记录流接受的记录会触发join并通过ValueJoiner生成结果,反之(即,从日志变更流接收的记录将只更新具象状态存储)。新的KStream表示该操作者返回的接入结果流。 - KStream-to-GlobalKTable Joins allow you to perform table lookups against a fully replicated changelog stream (
GlobalKTable) upon receiving a new record from another record stream (KStream). Joins with aGlobalKTabledon't require repartitioning of the inputKStreamas all partitions of theGlobalKTableare available on every KafkaStreams instance. TheKeyValueMapperprovided with the join operation is applied to each KStream record to extract the join-key that is used to do the lookup to the GlobalKTable so non-record-key joins are possible. An example use case would be to enrich a stream of user activities (KStream) with the latest user profile information (GlobalKTable). Only records received from the record stream will trigger the join and produce results viaValueJoiner, not vice versa (i.e., records received from the changelog stream will be used only to update the materialized state store). A newKStreaminstance representing the result stream of the join is returned from this operator.
KStream-to-GlobalKTable Joins允许你基于从其他记录流(KStream)接受到新记录时,针对一个完整复制的变更日志流(GlobalKTable)执行表查询。连接GlobalKTable不需要repartition输入KStream,因为GlobalKTable的所有分区在每个KafkaStreams实例中都可用。与join操作一起提供的KeyValueMapper应用到每条KStream记录,提取用于查找GlobalKTable的连接key,从而可以进行非记录key连接。例如,用最新的用户个人信息(GlobalKTable)来丰富用户活跃流(KStream)。只有从记录流接收的记录会触发join并产生结果(通过ValueJoiner),反之(即,从变更日志流接收的记录仅被用于更新状态仓库)。新的KStream实例代表从该操作者返回的连接结果流。
Depending on the operands the following join operations are supported: inner joins, outer joins and left joins. Their semantics are similar to the corresponding operators in relational databases.
基于支持如下计算方式: inner joins, outer joins 和 left joins.这些语义与关系型数据库的计算方式保持一致。.
Aggregate a stream
An aggregation operation takes one input stream, and yields a new stream by combining multiple input records into a single output record. Examples of aggregations are computing counts or sum. An aggregation over record streams usually needs to be performed on a windowing basis because otherwise the number of records that must be maintained for performing the aggregation may grow indefinitely.
aggregation操作接入一个输入流,通过合并多条输入记录到一条输入记录来生成一个新的stream。aggregations例如计算counts或者sum。在记录流上的aggregation操作一般需要使用时间窗口,如果不这样的话aggregation的记录条数可能增长到无限多。
In the Kafka Streams DSL, an input stream of an aggregation can be a KStream or a KTable, but the output stream will always be a KTable. This allows Kafka Streams to update an aggregate value upon the late arrival of further records after the value was produced and emitted. When such late arrival happens, the aggregating KStream orKTable simply emits a new aggregate value. Because the output is a KTable, the new value is considered to overwrite the old value with the same key in subsequent processing steps.
在Kafka Streams DSL中,aggregation的输入流可以是KStream或者KTable,但是输出流总是一个KTable。这使得Kafka Streams在value产生和提交后可以通过之后来的最新记录更新aggregate值。当这个之后的record到达时, KStream或者KTable继续aggregate发送新的aggregate值。由于输出是一个KTable,后续处理步骤中这个新value将覆盖相同key的记录。
Transform a stream
Besides join and aggregation operations, there is a list of other transformation operations provided for KStream and KTable respectively. Each of these operations may generate either one or more KStream and KTable objects and can be translated into one or more connected processors into the underlying processor topology. All these transformation methods can be chained together to compose a complex processor topology. Since KStream and KTable are strongly typed, all these transformation operations are defined as generics functions where users could specify the input and output data types.
除了join(连接)和aggregation(聚合)操作之外,KStream和KTable各自提供了其他的转换操作。这些操作的每一个都可以生成一个或多个KStream和Ktable对象,并可以转换成一个或多个连接处理器到基础处理器拓扑中。所有这些transformation方法可以链接在一起构成一个复杂的处理器拓扑。由于KSteram和KTable是强类型的,所有转换操作都被定义为泛型,用户可以在其中指定输入和输出的数据类型。
Among these transformations, filter, map, mapValues, etc, are stateless transformation operations and can be applied to both KStream and KTable, where users can usually pass a customized function to these functions as a parameter, such as Predicate for filter, KeyValueMapper for map, etc:
在这些transformations中,filter,map,myValues等是无状态transformation操作,可应用于KStream和KTable,用户通常可以自定义函数作为参数传递给这些函数,如Predicate的filter,MapValueMapper的map等:
// written in Java 8+, using lambda expressions
KStream<String, GenericRecord> mapped = source1.mapValue(record -> record.get("category")); |
Stateless transformations, by definition, do not depend on any state for processing, and hence implementation-wise they do not require a state store associated with the stream processor; Stateful transformations, on the other hand, require accessing an associated state for processing and producing outputs. For example, in join and aggregateoperations, a windowing state is usually used to store all the received records within the defined window boundary so far. The operators can then access these accumulated records in the store and compute based on them.
无状态transformations,不依赖任何其他的处理状态。因此在实现上它们不需要流处理器的状态存储。另一方面,有状态的transformations,需要状态存储来执行和产生输出。例如,在join和aggregate操作中,使用窗口状态通常用来存储所有目前为止在定义窗口边界内接收到的记录。然后,operators可以访问这些存储记录,并基于它们进行计算。
// written in Java 8+, using lambda expressions
KTable<Windowed<String>, Long> counts = source1.groupByKey().aggregate(
() -> 0L, // initial value
(aggKey, value, aggregate) -> aggregate + 1L, // aggregating value
TimeWindows.of("counts", 5000L).advanceBy(1000L), // intervals in milliseconds
Serdes.Long() // serde for aggregated value
);
KStream<String, String> joined = source1.leftJoin(source2,
(record1, record2) -> record1.get("user") + "-" + record2.get("region");
); |
Write streams back to Kafka
At the end of the processing, users can choose to (continuously) write the final resulted streams back to a Kafka topic through KStream.to and KTable.to.
在处理的最后阶段,用户可以选择通过KStream.to和KTable.to将最终的结果流(连续不断的)写回Kafka主题。
joined.to("topic4"); |
If your application needs to continue reading and processing the records after they have been materialized to a topic via to above, one option is to construct a new stream that reads from the output topic; Kafka Streams provides a convenience method called through:
如果这些记录已经通过上面的to方法写入到一个topic中,但是如果你还需要继续读取和处理这些记录,可以从输出topic中重新构建一个新流,Kafka Streams提供了一个便利的方法,through:
// equivalent to
//
// joined.to("topic4");
// materialized = builder.stream("topic4");
KStream<String, String> materialized = joined.through("topic4"); |
Interactive Queries
Interactive queries let you get more from streaming than just the processing of data. This feature allows you to treat the stream processing layer as a lightweight embedded database and, more concretely, to directly query the latest state of your stream processing application, without needing to materialize that state to external databases or external storage first. As a result, interactive queries simplify the architecture of many use cases and lead to more application-centric architectures. For example, you often no longer need to operate and interface with a separate database cluster -- or a separate infrastructure team in your company that runs that cluster -- to share data between a Kafka Streams application (say, an event-driven microservice) and downstream applications, regardless of whether these applications use Kafka Streams or not; they may even be applications that do not run on the JVM, e.g. implemented in Python, C/C++, or JavaScript. The following diagrams juxtapose two architectures: the first does not use interactive queries whereas the second architecture does. It depends on the concrete use case to determine which of these architectures is a better fit -- the important takeaway is that Kafka Streams and interactive queries give you the flexibility to pick and to compose the right one, rather than limiting you to just a single way.
交互式查询可以使你从streaming中获取更多,而不只是数据处理。这个特效可以使你将流处理层当作一个轻量级的数据库;而且更具体的是,可以directly query the latest state 流处理程序,而不需要将状态具象化到另外的数据库或者存储中。因此,交互式查询简化了许多应用案例的架构,产生了更多以应用程序为中心的架构。例如,你不再需要操作数和与一个独立的数据库集群交互,并且可以在一个Kafka Streams程序和下游程序中分享数据(例如微服务),无论这些程序是否使用KafkaStreams;它们甚至不是JVM程序,而是通过Python,C/C++,或者JavaScript实现。下面的图列出了两种架构:第一个是没有使用交互式查询,第二种使用。
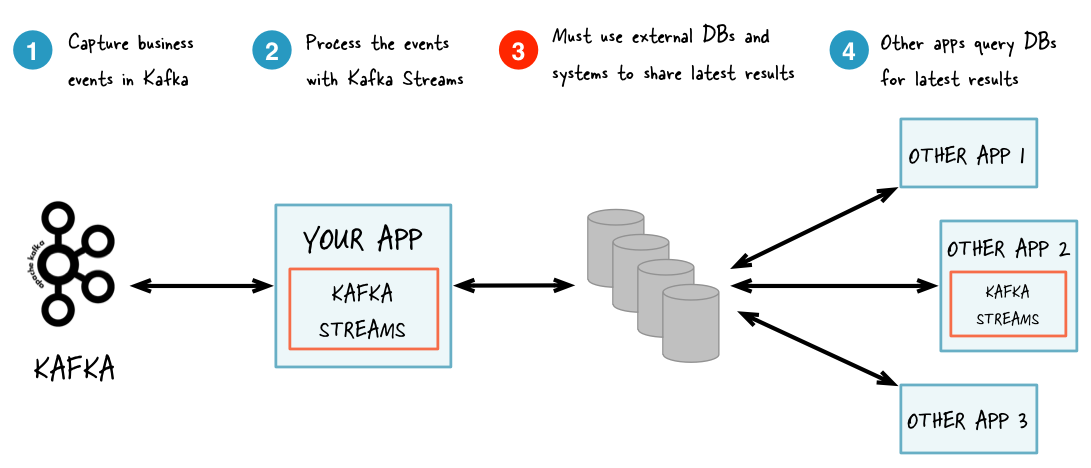
Without interactive queries: increased complexity and heavier footprint of architecture
没有使用交互式查询:提高了架构的复杂度和繁重
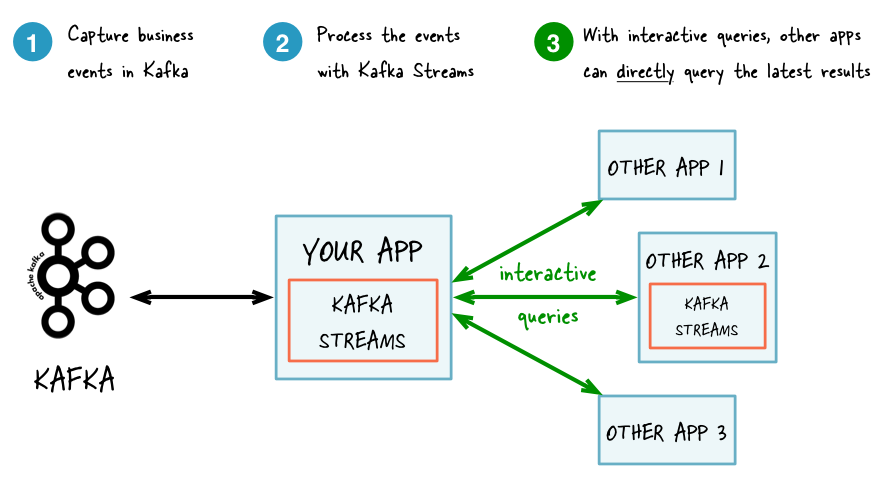
With interactive queries: simplified, more application-centric architecture
使用交互式查询:简洁,更以程序为中心的架构
Here are some use case examples for applications that benefit from interactive queries:
这里是一些从交互式查询中获利的一些使用案例:
- Real-time monitoring: A front-end dashboard that provides threat intelligence (e.g., web servers currently under attack by cyber criminals) can directly query a Kafka Streams application that continuously generates the relevant information by processing network telemetry data in real-time.
实时监控:前端仪表板,提供预警(例如web服务器正在被网络罪犯攻击),通过Kafka Streams程序来不断产生网络实时遥测数据处理的相关信息,并提供直接查询。 - Video gaming: A Kafka Streams application continuously tracks location updates from players in the gaming universe. A mobile companion app can then directly query the Kafka Streams application to show the current location of a player to friends and family, and invite them to come along. Similarly, the game vendor can use the data to identify unusual hotspots of players, which may indicate a bug or an operational issue.
视频游戏:Kafka Streams程序不断地跟踪游戏世界中玩家的地址更新。移动app可以直接从Kafka Streams查询来显示一个玩家与朋友、家人之间的现有位置,并邀请他们。类似地,游戏厂商可以利用这些数据来识别玩家不同寻常的热点,可能他们象征着一个bug或者操作问题。 - Risk and fraud: A Kafka Streams application continuously analyzes user transactions for anomalies and suspicious behavior. An online banking application can directly query the Kafka Streams application when a user logs in to deny access to those users that have been flagged as suspicious.
风险和欺诈:Kafka Streams程序不断地分析用户交易异常情况和可疑行为。当用户登录在线银行时,查询Kafka Streams应用程序可以直接拒绝那些被标记为可疑的用户访问。 - Trend detection: A Kafka Streams application continuously computes the latest top charts across music genres based on user listening behavior that is collected in real-time. Mobile or desktop applications of a music store can then interactively query for the latest charts while users are browsing the store.
趋势检测:Kafka Streams程序根据用户收听的实时行为,实时计算音乐流派中最新排行榜。音乐商店的移动或桌面应用程序可以在用户浏览商店时提供最新排行榜的交互式查询。
Your application and interactive queries
Interactive queries allow you to tap into the state of your application, and notably to do that from outside your application. However, an application is not interactively queryable out of the box: you make it queryable by leveraging the API of Kafka Streams.
交互式查询允许你使用程序地状态,尤其是来自程序之外进行查询。但是应用程序可以通过暴露Kafka Streams中的API来提供可查询功能。
It is important to understand that the state of your application -- to be extra clear, we might call it "the full state of the entire application" -- is typically split across many distributed instances of your application, and thus across many state stores that are managed locally by these application instances.
理解你程序的状态是关键的--为了理清楚,我们称它为"the full state of the entire application"--可能分割在许多分布式应用程序的实例,因此这些应用程序实例本地管理许多状态存储。
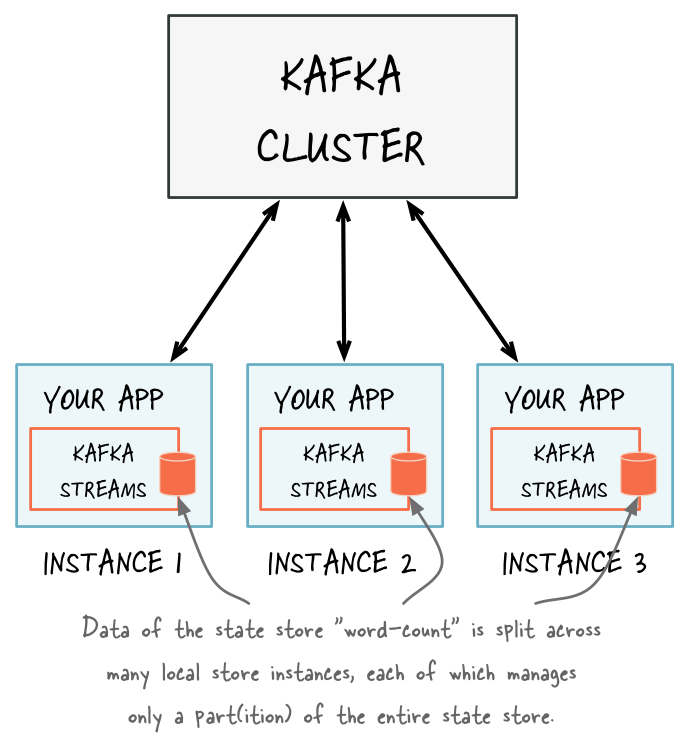
Accordingly, the API to let you interactively query your application's state has two parts, a local and a remote one:
因此,提供对应用程序状态进行查询的API有两种,local和remote
- Querying local state stores (for an application instance): You can query that (part of the full) state that is managed locally by an instance of your application. Here, an application instance can directly query its own local state stores. You can thus use the corresponding (local) data in other parts of your application code that are not related to calling the Kafka Streams API. Querying state stores is always *read-only* to guarantee that the underlying state stores will never be mutated out-of-band, e.g. you cannot add new entries; state stores should only ever be mutated by the corresponding processor topology and the input data it operates on.
从本地状态进行查询(对于一个应用程序实例):你可以查询一个本地应用程序实例管理的状态(全部中的一部分)。这里,应用程序实例可以直接查询他自己的本地状态存储。你因此调用Kafka Streams API来可以使用与程序代码其他部分没有关系的相应本地状态。查询状态存储总是“只读的”来保证状态存储不会突变为外部数据,例如你不能增加条目。状态存储只能被相应的处理器拓扑修改,并且只能操作输入数据。 - Querying remote state stores (for the entire application): To query the full state of your entire application we must be able to piece together the various local fragments of the state. In addition to being able to (a) query local state stores as described in the previous bullet point, we also need to (b) discover all the running instances of your application in the network, including their respective state stores and (c) have a way to communicate with these instances over the network, i.e. an RPC layer. Collectively, these building blocks enable intra-app communcation (between instances of the same app) as well as inter-app communication (from other applications) for interactive queries.
从远端状态存储查询(对于整个程序来说):为了查询整个程序的全部状态,我们必须能拼凑状态的各个部分。除了能够查询上一部分介绍的本地状态查询,我们还需要发现网络中整个程序的所有运行实例,并且能够跟网络中的这些实例进行通信,例如RPC层。总的来说,这些构建块使内应用程序通信(同一应用的实例之间)以及跨应用程序的通信(从其他应用程序)进行交互查询。
| WHAT OF THE BELOW IS REQUIRED TO ACCESS THE STATE OF ... | ... AN APP INSTANCE (LOCAL STATE) | ... THE ENTIRE APPLICATION (FULL STATE) |
|---|---|---|
| Query local state stores of an app instance | Required (but already built-in) | Required (but already built-in) |
| Make an app instance discoverable to others | Not needed | Required (but already built-in) |
| Discover all running app instances and their state stores | Not needed | Required (but already built-in) |
| Communicate with app instances over the network (RPC) | Not needed | Required user must provide |
Kafka Streams provides all the required functionality for interactively querying your application's state out of the box, with but one exception: if you want to expose your application's full state via interactive queries, then -- for reasons we explain further down below -- it is your responsibility to add an appropriate RPC layer (such as a REST API) to your application that allows application instances to communicate over the network. If, however, you only need to let your application instances access their own local state, then you do not need to add such an RPC layer at all.
Kafka Streams提供了非常好的对应用程序状态进行交互式查询的功能,但有一个例外:如果你想将你的应用程序全状态暴露出来进行交互式查询,然后--原因我们进一步解释下,你需要加上适当的RPC层(如REST API)到你的应用程序,并允许应用程序实例可以在网络上进行通信。但是,如果您只需要让应用程序实例访问自己的本地状态存储,那么您根本不需要添加这样的RPC层。
Querying local state stores (for an application instance)
A Kafka Streams application is typically running on many instances. The state that is locally available on any given instance is only a subset of the application's entire state. Querying the local stores on an instance will, by definition, only return data locally available on that particular instance. We explain how to access data in state stores that are not locally available in section Querying remote state stores (for the entire application).
Kafka Streams通常在许多实例是运行。本地状态是应用程序全状态的自己。查询本地状态只会返回独立实例的本地可用状态。
The method KafkaStreams#store(...) finds an application instance's local state stores by name and by type.
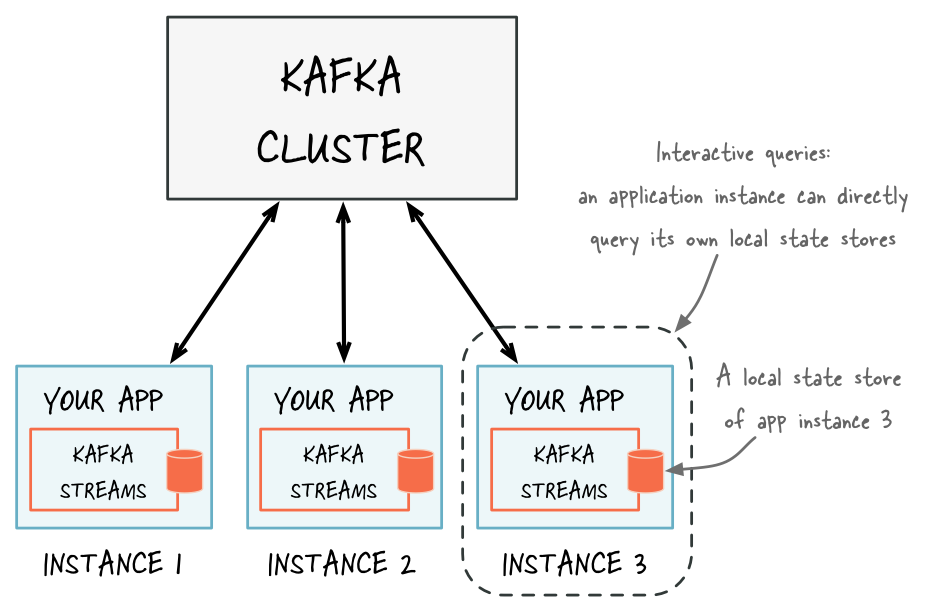
Every application instance can directly query any of its local state stores
The name of a state store is defined when you are creating the store, either when creating the store explicitly (e.g. when using the Processor API) or when creating the store implicitly (e.g. when using stateful operations in the DSL). We show examples of how to name a state store further down below.
状态存储的名字是在我们创建它时就定义的,或者明确的创建状态存储(使用Processor API),或者隐式创建(使用DSL中的有扎ungtai操作)。下面我们展示了一个如何命名一个状态存储的例子。
The type of a state store is defined by QueryableStoreType, and you can access the built-in types via the class QueryableStoreTypes. Kafka Streams currently has two built-in types:
状态存储的类型使用QueryableStoreType定义,你可以通过QueryableStoreTypes来使用内建的类型。Kafka Streams现在有两种内建类型:
- A key-value store
QueryableStoreTypes#keyValueStore(), see Querying local key-value stores. - A window store
QueryableStoreTypes#windowStore(), see Querying local window stores.
Both store types return read-only versions of the underlying state stores. This read-only constraint is important to guarantee that the underlying state stores will never be mutated (e.g. new entries added) out-of-band, i.e. only the corresponding processing topology of Kafka Streams is allowed to mutate and update the state stores in order to ensure data consistency.
两种存储类型都是只读的。只读限制对于保证状态存储不被篡改很重要。状态存储只能被相应的处理器拓扑修改和更新,来确保数据一致性。
You can also implement your own QueryableStoreType as described in section Querying local custom stores
你也能实现自己的QueryableStoreType
Kafka Streams materializes one state store per stream partition, which means your application will potentially manage many underlying state stores. The API to query local state stores enables you to query all of the underlying stores without having to know which partition the data is in. The objects returned from KafkaStreams#store(...) are therefore wrapping potentially many underlying state stores.
Kafka Streams在stream的每个部分都具象一个状态存储,这意味着你的程序将可能管理很多基本状态存储。查询本地状态存储的API可以使你不需要知道数据时哪一部分的情况下查询基本存储的全部。KafkaStreams#store(...) 可能包装了很多基本状态存储。
Querying local key-value stores
To query a local key-value store, you must first create a topology with a key-value store:
为了查询一个本地key-value存储,你需要首先创建一个包含key-value存储的拓扑。
StreamsConfig config = ...;
KStreamBuilder builder = ...;
KStream<String, String> textLines = ...;
// Define the processing topology (here: WordCount)
KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, stringSerde, stringSerde);
// Create a key-value store named "CountsKeyValueStore" for the all-time word counts
groupedByWord.count("CountsKeyValueStore");
// Start an instance of the topology
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start(); |
Above we created a key-value store named "CountsKeyValueStore". This store will hold the latest count for any word that is found on the topic "word-count-input". Once the application has started we can get access to "CountsKeyValueStore" and then query it via the ReadOnlyKeyValueStore API:
上面我们创建名为CountsKeyValueStore的key-value存储。状态存储保留word-count-input的topic中words的最新统计数。一旦程序启动,我们可以通过ReadOnlyKeyValueStore API查询“CountsKeyValueStore”。
// Get the key-value store CountsKeyValueStore
ReadOnlyKeyValueStore<String, Long> keyValueStore =
streams.store("CountsKeyValueStore", QueryableStoreTypes.keyValueStore());
// Get value by key
System.out.println("count for hello:" + keyValueStore.get("hello"));
// Get the values for a range of keys available in this application instance
KeyValueIterator<String, Long> range = keyValueStore.range("all", "streams");
while (range.hasNext()) {
KeyValue<String, Long> next = range.next();
System.out.println("count for " + next.key + ": " + value);
}
// Get the values for all of the keys available in this application instance
KeyValueIterator<String, Long> range = keyValueStore.all();
while (range.hasNext()) {
KeyValue<String, Long> next = range.next();
System.out.println("count for " + next.key + ": " + value);
} |
Querying local window stores
A window store differs from a key-value store in that you will potentially have many results for any given key because the key can be present in multiple windows. However, there will ever be at most one result per window for a given key.
window store返回的是不同的key-value存储,你可能在一个key上得到多个结果,因为不同的窗口中key的结果是不同的。然而,在同一个窗口中,一个key只会返回一个value结果。
To query a local window store, you must first create a topology with a window store:
为了查询一个本地window存储,你需要首先创建一个包含window存储的拓扑。
StreamsConfig config = ...;
KStreamBuilder builder = ...;
KStream<String, String> textLines = ...;
// Define the processing topology (here: WordCount)
KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, stringSerde, stringSerde);
// Create a window state store named "CountsWindowStore" that contains the word counts for every minute
groupedByWord.count(TimeWindows.of(60000), "CountsWindowStore"); |
Above we created a window store named "CountsWindowStore" that contains the counts for words in 1-minute windows. Once the application has started we can get access to "CountsWindowStore" and then query it via the ReadOnlyWindowStore API:
上面我们创建了一个名为“CountsWindowStore”的window存储,它包含一个一分钟时间窗口的单词计数。一旦程序启动,我们可以通过ReadOnlyWindowStore API来查询“CountsWindowStore”。
// Get the window store named "CountsWindowStore"
ReadOnlyWindowStore<String, Long> windowStore =
streams.store("CountsWindowStore", QueryableStoreTypes.windowStore());
// Fetch values for the key "world" for all of the windows available in this application instance.
// To get *all* available windows we fetch windows from the beginning of time until now.
long timeFrom = 0; // beginning of time = oldest available
long timeTo = System.currentTimeMillis(); // now (in processing-time)
WindowStoreIterator<Long> iterator = windowStore.fetch("world", timeFrom, timeTo);
while (iterator.hasNext()) {
KeyValue<Long, Long> next = iterator.next();
long windowTimestamp = next.key;
System.out.println("Count of 'world' @ time " + windowTimestamp + " is " + next.value);
} |
Querying local custom state stores
Any custom state stores you use in your Kafka Streams applications can also be queried. However there are some interfaces that will need to be implemented first:
你在Kafka Streams程序中你使用的自定义存储也是可以被查询的。然后你需要先实现一些接口:
- Your custom state store must implement
StateStore.你自定义的状态存储需要先实现StateStore - You should have an interface to represent the operations available on the store.你应该有一个接口来表示存储的操作。
- It is recommended that you also provide an interface that restricts access to read-only operations so users of this API can't mutate the state of your running Kafka Streams application out-of-band.推荐提供一个接口来限制操作只能是只读操作,所以这个API的用户不会篡改状态。
- You also need to provide an implementation of
StateStoreSupplierfor creating instances of your store.需要提供一个StateStoreSupplier的实现来创建存储实例。
The class/interface hierarchy for your custom store might look something like:
public class MyCustomStore<K,V> implements StateStore, MyWriteableCustomStore<K,V> {
// implementation of the actual store
}
// Read-write interface for MyCustomStore
public interface MyWriteableCustomStore<K,V> extends MyReadableCustomStore<K,V> {
void write(K Key, V value);
}
// Read-only interface for MyCustomStore
public interface MyReadableCustomStore<K,V> {
V read(K key);
}
public class MyCustomStoreSupplier implements StateStoreSupplier {
// implementation of the supplier for MyCustomStore
} |
To make this store queryable you need to:为了状态存储可查询,你需要:
- Provide an implementation of
QueryableStoreType.提供一个QueryableStoreType的实现 - Provide a wrapper class that will have access to all of the underlying instances of the store and will be used for querying.提供一个包装类,使用存储实例来进行查询。
Implementing QueryableStoreType is straight forward:
public class MyCustomStoreType<K,V> implements QueryableStoreType<MyReadableCustomStore<K,V>> {
// Only accept StateStores that are of type MyCustomStore
public boolean accepts(final StateStore stateStore) {
return stateStore instanceOf MyCustomStore;
}
public MyReadableCustomStore<K,V> create(final StateStoreProvider storeProvider, final String storeName) {
return new MyCustomStoreTypeWrapper(storeProvider, storeName, this);
}
} |
A wrapper class is required because even a single instance of a Kafka Streams application may run multiple stream tasks and, by doing so, manage multiple local instances of a particular state store. The wrapper class hides this complexity and lets you query a "logical" state store with a particular name without having to know about all of the underlying local instances of that state store.
由于即使是一个Kafka Streams程序可能同时运行多个stream task任务,因此包装类是需要的。这么做,可以管理一个独立状态存储的多个本地实例。包装类隐藏了复杂性,并且让我们可以使用一个独立的名字来查询“logical”状态存储,而不用必须知道状态存储的所有本地实例。
When implementing your wrapper class you will need to make use of the StateStoreProvider interface to get access to the underlying instances of your store.StateStoreProvider#stores(String storeName, QueryableStoreType<T> queryableStoreType) returns a List of state stores with the given storeName and of the type as defined by queryableStoreType.
当实现你的包装类的时候,你需要使用StateStoreProvider接口来查询你的状态存储的实例。StateStoreProvider#stores(String storeName, QueryableStoreType<T> queryableStoreType) 返回的拥有给定storeName的状态存储列表,以及queryableStoreType定义的类型。
An example implemention of the wrapper follows (Java 8+):
// We strongly recommended implementing a read-only interface
// to restrict usage of the store to safe read operations!
public class MyCustomStoreTypeWrapper<K,V> implements MyReadableCustomStore<K,V> {
private final QueryableStoreType<MyReadableCustomStore<K, V>> customStoreType;
private final String storeName;
private final StateStoreProvider provider;
public CustomStoreTypeWrapper(final StateStoreProvider provider,
final String storeName,
final QueryableStoreType<MyReadableCustomStore<K, V>> customStoreType) {
// ... assign fields ...
}
// Implement a safe read method
@Override
public V read(final K key) {
// Get all the stores with storeName and of customStoreType
final List<MyReadableCustomStore<K, V>> stores = provider.getStores(storeName, customStoreType);
// Try and find the value for the given key
final Optional<V> value = stores.stream().filter(store -> store.read(key) != null).findFirst();
// Return the value if it exists
return value.orElse(null);
}
} |
Putting it all together you can now find and query your custom store:
StreamsConfig config = ...;
TopologyBuilder builder = ...;
ProcessorSupplier processorSuppler = ...;
// Create CustomStoreSupplier for store name the-custom-store
MyCustomStoreSuppler customStoreSupplier = new MyCustomStoreSupplier("the-custom-store");
// Add the source topic
builder.addSource("input", "inputTopic");
// Add a custom processor that reads from the source topic
builder.addProcessor("the-processor", processorSupplier, "input");
// Connect your custom state store to the custom processor above
builder.addStateStore(customStoreSupplier, "the-processor");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
// Get access to the custom store
MyReadableCustomStore<String,String> store = streams.store("the-custom-store", new MyCustomStoreType<String,String>());
// Query the store
String value = store.read("key"); |
Querying remote state stores (for the entire application)
Typically, the ultimate goal for interactive queries is not to just query locally available state stores from within an instance of a Kafka Streams application as described in the previous section. Rather, you want to expose the application's full state (i.e. the state across all its instances) to other applications that might be running on different machines. For example, you might have a Kafka Streams application that processes the user events in a multi-player video game, and you want to retrieve the latest status of each user directly from this application so that you can display it in a mobile companion app.
通常,交互式查询的终极目标并不是只查询Kafka Streams中单一实例的本地可用状态存储。更进一步,你想要查看程序的全部状态(比如所有实例的全状态),程序中的其他实例运行在不同的机器上。例如,你可能有一个Kafka Streams程序来处理一个多用户视频游戏中的用户事件,而且你想要从程序中直接检索到每个用户的最新状态,然后就可以在移动app中显示。
Three steps are needed to make the full state of your application queryable:
- You must add an RPC layer to your application so that the instances of your application may be interacted with via the network -- notably to respond to interactive queries. By design Kafka Streams does not provide any such RPC functionality out of the box so that you can freely pick your favorite approach: a REST API, Thrift, a custom protocol, and so on.
你必须在程序中增加一个RPC层,这样才能使程序中的实例通过网络相互作用--尤其是相应交互式查询。将KafkaStreams设计成不需要提供这样的RPC功能,你可以自由选择你的偏好:a REST API,Thrift,a custom protocol等等。 - You need to expose the respective RPC endpoints of your application's instances via the
application.serverconfiguration setting of Kafka Streams. Because RPC endpoints must be unique within a network, each instance will have its own value for this configuration setting. This makes an application instance discoverable by other instances.
你需要通过KafkaStreams配置application.server来暴露各自的RPC端点。因为RPC端点必须是网络上是唯一的,每个实例在配置中拥有自己的值(相互之间值是不同的)。这可以使一个程序实例可以被其他实例发现。 - In the RPC layer, you can then discover remote application instances and their respective state stores (e.g. for forwarding queries to other app instances if an instance lacks the local data to respond to a query) as well as query locally available state stores (in order to directly respond to queries) in order to make the full state of your application queryable.
在RPC层,你可以发现远程程序实例以及他们各自的状态存储(如果一个实例中缺少本地状态数据来相应查询,会将查询指向其他程序实例),而且查询本地可用状态存储(为了直接来相应查询)是为了使得整个程序全状态可查询。
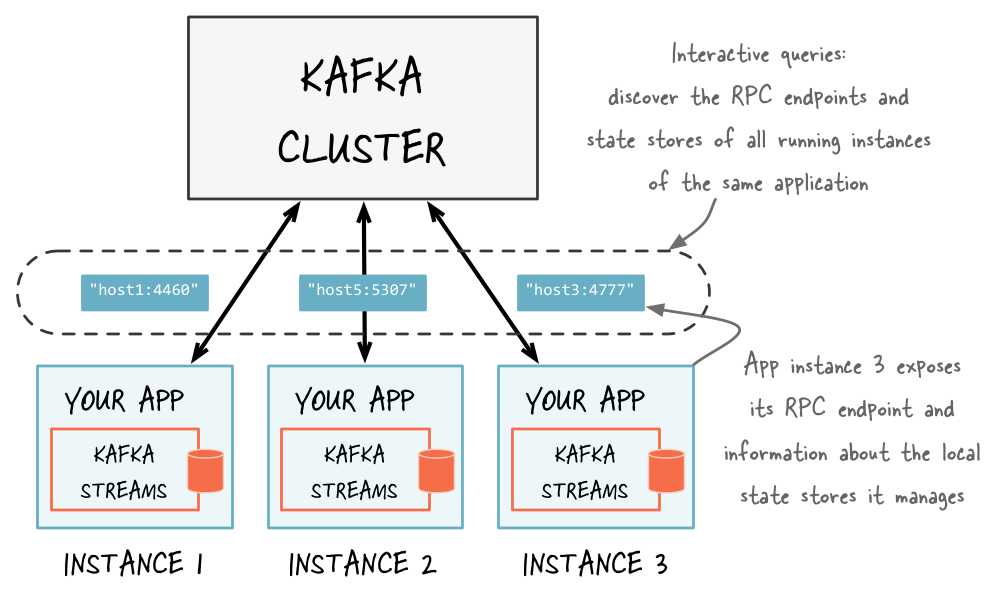
Discover any running instances of the same application as well as the respective RPC endpoints they expose for interactive queries
Adding an RPC layer to your application
As Kafka Streams doesn't provide an RPC layer you are free to choose your favorite approach. There are many ways of doing this, and it will depend on the technologies you have chosen to use. The only requirements are that the RPC layer is embedded within the Kafka Streams application and that it exposes an endpoint that other application instances and applications can connect to.
Kafka Streams没有提供一个RPC层,你可以自由选择你的偏好。有很多方式可以实现这个,主要依赖与你使用的技术。唯一的要求是RPC层需要嵌入Kafka Streams程序中,并且它需要暴露其他程序实例的端点,并且程序可被连接。
Exposing the RPC endpoints of your application
To enable the remote discovery of state stores running within a (typically distributed) Kafka Streams application you need to set the application.server configuration property in StreamsConfig. The application.server property defines a unique host:port pair that points to the RPC endpoint of the respective instance of a Kafka Streams application. It's important to understand that the value of this configuration property varies across the instances of your application. When this property is set, then, for every instance of an application, Kafka Streams will keep track of the instance's RPC endpoint information, its state stores, and assigned stream partitions through instances of StreamsMetadata
为了能远程发现一个Kafka Streams程序(通常分布式)中的状态存储,你需要在StreamsConfig中设置application.server。参数application.server定义一个唯一的host:port对应相应实例的RPC端口。理解分布在各程序实例中的参数配置是重要的。对每个程序实例,当参数配置被设置,Kafka Streams将跟踪实例的RPC端点信息,状态存储,并指定stream partitions到StreamsMetadata的实例中。
Below is an example of configuring and running a Kafka Streams application that supports the discovery of its state stores.
Properties props = new Properties();
// Set the unique RPC endpoint of this application instance through which it
// can be interactively queried. In a real application, the value would most
// probably not be hardcoded but derived dynamically.
String rpcEndpoint = "host1:4460";
props.put(StreamsConfig.APPLICATION_SERVER_CONFIG, rpcEndpoint);
// ... further settings may follow here ...
StreamsConfig config = new StreamsConfig(props);
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde, "word-count-input");
KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, stringSerde, stringSerde);
// This call to `count()` creates a state store named "word-count".
// The state store is discoverable and can be queried interactively.
groupedByWord.count("word-count");
// Start an instance of the topology
KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration);
streams.start();
// Then, create and start the actual RPC service for remote access to this
// application instance's local state stores.
//
// This service should be started on the same host and port as defined above by
// the property `StreamsConfig.APPLICATION_SERVER_CONFIG`. The example below is
// fictitious, but we provide end-to-end demo applications (such as KafkaMusicExample)
// that showcase how to implement such a service to get you started.
MyRPCService rpcService = ...;
rpcService.listenAt(rpcEndpoint); |
Discovering and accessing application instances and their respective local state stores
With the application.server property set, we can now find the locations of remote app instances and their state stores. The following methods return StreamsMetadata objects, which provide meta-information about application instances such as their RPC endpoint and locally available state stores.
设置application.server参数,我们现在可以找出远程程序实例的位置和他们的状态存储。下面的方法返回的是一个StreamsMetadata对象,这个对象提供了关于程序实例的元信息:比如RPC端点,以及本地可用状态存储。
KafkaStreams#allMetadata(): find all instances of this application找出程序的所有实例KafkaStreams#allMetadataForStore(String storeName): find those applications instances that manage local instances of the state store "storeName"找出那么管理名为“storeName”状态存储“实例的程序实例KafkaStreams#metadataForKey(String storeName, K key, Serializer<K> keySerializer): using the default stream partitioning strategy, find the one application instance that holds the data for the given key in the given state store使用默认流分区策略,找出给定状态存储名字、指定key的那个程序实例。KafkaStreams#metadataForKey(String storeName, K key, StreamPartitioner<K, ?> partitioner): usingpartitioner, find the one application instance that holds the data for the given key in the given state store使用分区器,找到给定状态存储名字、指定key的那个程序实例。
If application.server is not configured for an application instance, then the above methods will not find any StreamsMetadata for it.
如果application.server在程序实例中没有配置,那么上述方法不会找到它(这个程序实例)的任何StreamsMetadata。
For example, we can now find the StreamsMetadata for the state store named "word-count" that we defined in the code example shown in the previous section:
KafkaStreams streams = ...;
// Find all the locations of local instances of the state store named "word-count"
Collection<StreamsMetadata> wordCountHosts = streams.allMetadataForStore("word-count");
// For illustrative purposes, we assume using an HTTP client to talk to remote app instances.
HttpClient http = ...;
// Get the word count for word (aka key) 'alice': Approach 1
//
// We first find the one app instance that manages the count for 'alice' in its local state stores.
StreamsMetadata metadata = streams.metadataForKey("word-count", "alice", Serdes.String().serializer());
// Then, we query only that single app instance for the latest count of 'alice'.
// Note: The RPC URL shown below is fictitious and only serves to illustrate the idea. Ultimately,
// the URL (or, in general, the method of communication) will depend on the RPC layer you opted to
// implement. Again, we provide end-to-end demo applications (such as KafkaMusicExample) that showcase
// how to implement such an RPC layer.
Long result = http.getLong("http://" + metadata.host() + ":" + metadata.port() + "/word-count/alice");
// Get the word count for word (aka key) 'alice': Approach 2
//
// Alternatively, we could also choose (say) a brute-force approach where we query every app instance
// until we find the one that happens to know about 'alice'.
Optional<Long> result = streams.allMetadataForStore("word-count")
.stream()
.map(streamsMetadata -> {
// Construct the (fictituous) full endpoint URL to query the current remote application instance
String url = "http://" + streamsMetadata.host() + ":" + streamsMetadata.port() + "/word-count/alice";
// Read and return the count for 'alice', if any.
return http.getLong(url);
})
.filter(s -> s != null)
.findFirst(); |
At this point the full state of the application is interactively queryable:
- We can discover the running instances of the application as well as the state stores they manage locally.我们可以发现程序实例以及他们本地管理的状态存储。
- Through the RPC layer that was added to the application, we can communicate with these application instances over the network and query them for locally available state通过添加到程序地RPC层,我们可以通过网络在程序实例之间进行通信,并且查询他们的本地状态存储
- The application instances are able to serve such queries because they can directly query their own local state stores and respond via the RPC layer由于他们可以查询本地状态存储以及通过RPC层进行响应,程序实例能够服务与这种查询
- Collectively, this allows us to query the full state of the entire application总的来说,这使得我们可以查询整个程序的全状态。
Application Configuration and Execution
Besides defining the topology, developers will also need to configure their applications in StreamsConfig before running it. A complete list of Kafka Streams configs can be found here. Note, that different parameters do have different "levels of importance", with the following interpretation:
除了定义拓扑,开发者还需要程序运行前,通过StreamsConfig来配置他们的应用程序。
- HIGH: you would most likely change the default value if you go to production
- MEDIUM: default value might be ok, but you should double-check it
- LOW: default value is most likely ok; only consider to change it if you hit an issues when running in production
Specifying the configuration in Kafka Streams is similar to the Kafka Producer and Consumer clients. Typically, you create a java.util.Properties instance, set the necessary parameters, and construct a StreamsConfig instance from the Properties instance.
在Kafka Streams指定配置与Kafka Producer、 Consumer客户端的类似。通常你创建一个java.util.Properties实例,设置必要的属性,并通过Properties实例来构建一个StreamsConfig实例。
import java.util.Properties; import org.apache.kafka.streams.StreamsConfig; Properties settings = new Properties(); // Set a few key parameters settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-first-streams-application"); settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092"); // Set a few user customized parameters settings.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE); settings.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, MyTimestampExtractor.class); // Any further settings settings.put(... , ...); // Create an instance of StreamsConfig from the Properties instance StreamsConfig config = new StreamsConfig(settings); |
Producer and Consumer Configuration
Apart from Kafka Streams' own configuration parameters you can also specify parameters for the Kafka consumers and producers that are used internally, depending on the needs of your application. Similar to the Streams settings you define any such consumer and/or producer settings via StreamsConfig. Note that some consumer and producer configuration parameters do use the same parameter name. For example, send.buffer.bytes or receive.buffer.bytes which are used to configure TCP buffers;request.timeout.ms and retry.backoff.ms which control retries for client request (and some more). If you want to set different values for consumer and producer for such a parameter, you can prefix the parameter name with consumer. or producer.:
除了设置Kafka Streams自有属性,你也可以根据程序需要指定内部Kafka consumers and producers的属性。跟Streams设置类似,你通过StreamsConfig来定义consumer and/or producer设置。注意,部分consumer and producer的属性使用相同的属性名。例如send.buffer.bytes 或 receive.buffer.bytes配置TCP buffers;request.timeout.ms and retry.backoff.ms来控制客户端请求的重试。如果你想要consumer和producer设置不同的参数值,你可以在属性名字前面加上前缀名字"consumer."或者"producer."。
Properties settings = new Properties();
// Example of a "normal" setting for Kafka Streams
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker-01:9092");
// Customize the Kafka consumer settings
streamsSettings.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 60000);
// Customize a common client setting for both consumer and producer
settings.put(CommonClientConfigs.RETRY_BACKOFF_MS_CONFIG, 100L);
// Customize different values for consumer and producer
settings.put("consumer." + ConsumerConfig.RECEIVE_BUFFER_CONFIG, 1024 * 1024);
settings.put("producer." + ProducerConfig.RECEIVE_BUFFER_CONFIG, 64 * 1024);
// Alternatively, you can use
settings.put(StreamsConfig.consumerPrefix(ConsumerConfig.RECEIVE_BUFFER_CONFIG), 1024 * 1024);
settings.put(StreamsConfig.producerConfig(ProducerConfig.RECEIVE_BUFFER_CONFIG), 64 * 1024); |
Broker Configuration
Introduced in 0.11.0 is a new broker config that is particularly relevant to Kafka Streams applications, group.initial.rebalance.delay.ms. This config specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance. The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as each new member joins the consumer group, up to a maximum of the value set by max.poll.interval.ms. The net benefit is that this should reduce the overall startup time for Kafka Streams applications with more than one thread. The default value for group.initial.rebalance.delay.ms is 3 seconds.
在0.11.0版本中我们介绍一个与Kafka Streams程序有关的broker配置,group.initial.rebalance.delay.ms。这个配置指定了时间(毫秒),GroupCoordinator将会推迟initial consumer rebalance(初次cosumer rebalance)。每个新的用户加入consumer group,rebalance将被推迟group.initial.rebalance.delay.ms,直到达到max.poll.interval.ms设置的最大值。这样做的网络收益是减少多与一个线程的Kafka Streams程序的启动时间。参数group.initial.rebalance.delay.ms默认是是3秒。
In practice this means that if you are starting up your Kafka Streams app from a cold start, then when the first member joins the group there will be at least a 3 second delay before it is assigned any tasks. If any other members join the group within the initial 3 seconds, then there will be a further 3 second delay. Once no new members have joined the group within the 3 second delay, or max.poll.interval.ms is reached, then the group rebalance can complete and all current members will be assigned tasks. The benefit of this approach, particularly for Kafka Streams applications, is that we can now delay the assignment and re-assignment of potentially expensive tasks as new members join. So we can avoid the situation where one instance is assigned all tasks, begins restoring/processing, only to shortly after be rebalanced, and then have to start again with half of the tasks and so on.
实践中,当你冷启动一个Kafka Streams程序时,当第一个成员加入group时,在给它分配任务之前至少等待3秒。如果其他成员在这3秒中加入group,那么会再产生3秒延迟。一旦新用户加入到group就产生3秒推迟,直到达到最大时间max.poll.interval.ms,group rebalance可以完成并且所有现在的成员都被分配任务。这种方法的好处是,特别是对于Kafka Streams程序来说,我们现在可以在新用户加入组时,推迟任务分配和潜在重分配(花费昂贵)。所以我们可以避免如下情况,当一个程序实例被分配了所有任务,开始存储状态/处理计算,不久之后有要rebalance(新增加一个实例),然后重新启动被分配一半的任务。
Executing Your Kafka Streams Application
You can call Kafka Streams from anywhere in your application code. Very commonly though you would do so within the main() method of your application, or some variant thereof.
你可以在程序代码的任何位置使用Kafka Streams。通常,你会使用程序的main()方法,也可以使用其他方式。
First, you must create an instance of KafkaStreams. The first argument of the KafkaStreams constructor takes a topology builder (either KStreamBuilder for the Kafka Streams DSL, or TopologyBuilder for the Processor API) that is used to define a topology; The second argument is an instance of StreamsConfig mentioned above.
首先,你必须创建KafkaStreams实例,KafkaStreams构造器的第一个参数是一个拓扑建造器 (either KStreamBuilder for the Kafka Streams DSL, or TopologyBuilder for the Processor API)。第二个参数是上面说的StreamsConfig实例。
import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.kstream.KStreamBuilder; import org.apache.kafka.streams.processor.TopologyBuilder; // Use the builders to define the actual processing topology, e.g. to specify // from which input topics to read, which stream operations (filter, map, etc.) // should be called, and so on. KStreamBuilder builder = ...; // when using the Kafka Streams DSL // // OR // TopologyBuilder builder = ...; // when using the Processor API // Use the configuration to tell your application where the Kafka cluster is, // which serializers/deserializers to use by default, to specify security settings, // and so on. StreamsConfig config = ...; KafkaStreams streams = new KafkaStreams(builder, config); |
At this point, internal structures have been initialized, but the processing is not started yet. You have to explicitly start the Kafka Streams thread by calling the start() method:
// Start the Kafka Streams instance streams.start(); |
To catch any unexpected exceptions, you may set an java.lang.Thread.UncaughtExceptionHandler before you start the application. This handler is called whenever a stream thread is terminated by an unexpected exception:
streams.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public uncaughtException(Thread t, throwable e) {
// here you should examine the exception and perform an appropriate action!
}
); |
To stop the application instance call the close() method:
// Stop the Kafka Streams instance streams.close(); |
Now it's time to execute your application that uses the Kafka Streams library, which can be run just like any other Java application - there is no special magic or requirement on the side of Kafka Streams. For example, you can package your Java application as a fat jar file and then start the application via:
# Start the application in class `com.example.MyStreamsApp` # from the fat jar named `path-to-app-fatjar.jar`. $ java -cp path-to-app-fatjar.jar com.example.MyStreamsApp |
When the application instance starts running, the defined processor topology will be initialized as one or more stream tasks that can be executed in parallel by the stream threads within the instance. If the processor topology defines any state stores, these state stores will also be (re-)constructed, if possible, during the initialization period of their associated stream tasks. It is important to understand that, when starting your application as described above, you are actually launching what Kafka Streams considers to be one instance of your application. More than one instance of your application may be running at a time, and in fact the common scenario is that there are indeed multiple instances of your application running in parallel (e.g., on another JVM or another machine). In such cases, Kafka Streams transparently re-assigns tasks from the existing instances to the new instance that you just started. See Stream Partitions and Tasks and Threading Model for details.