常用的集成学习方法
集成学习是构建一组基学习器,并将它们综合作为最终的模型,在很多集成学习模型中,对基学习器的要求很低,集成学习适用于机器学习的几乎所有的领域:
1、回归
2、分类
3、推荐
4、排序
集成学习有效的原因
多样的基学习器可以在不同的模型中取长补短
每个基学习器都犯不同的错误,综合起来犯错的可能性不大
但是想同的多个基学习器不会带来任何提升
集成学习示例: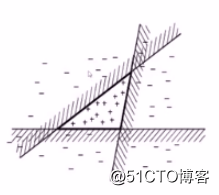
例如在上图中每个线性模型都不能成功将该数据集分类
但是三个线性模型的简单综合即可将数据集成功分类,每个模型犯不同的错,但是在综合时能够取长补短,使得综合后的模型性能更好。
那么如何构建不同的基学习器?如何将基学习器综合起来?
如何构建不同的学习器
1、采用不同的学习算法
2、采用相同的学习算法,但是使用不同的参数
3、采用不同的数据集,其中采用不同的样本子集,在每个数据集中使用不同的特征
如何综合不同的基学习器
1、投票法
每个基学习器具有相同的权重
2、有权重的投票
可用不同的方法来确定权重
3、训练一个新模型来确定如何综合
stacking
我们一般偏好简单的模型(线性回归)
主要的集成学习模式有以下几种
1、bagging random forest(随机森林)
2、boosting
adaboost
GBDT
3、stacking
bagging
在集成算法中,bagging 方法会在原始训练集的随机子集上构建一类黑盒估计器的多个实例,然后把这些估计器的预测结果结合起来形成最终的预测结果。 该方法通过在构建模型的过程中引入随机性,来减少基估计器的方差(例如,决策树)。 在多数情况下,bagging 方法提供了一种非常简单的方式来对单一模型进行改进,而无需修改背后的算法。 因为 bagging 方法可以减小过拟合,所以通常在强分类器和复杂模型上使用时表现的很好(例如,完全决策树,fully developed decision trees),相比之下 boosting 方法则在弱模型上表现更好(例如,浅层决策树,shallow decision trees)。
bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同:
如果抽取的数据集的随机子集是样例的随机子集,我们叫做 Pasting 。
如果样例抽取是有放回的,我们称为 Bagging 。
如果抽取的数据集的随机子集是特征的随机子集,我们叫做随机子空间 (Random Subspaces)。
最后,如果基估计器构建在对于样本和特征抽取的子集之上时,我们叫做随机补丁 (Random Patches) 。
在 scikit-learn 中,bagging 方法使用统一的 BaggingClassifier 元估计器(或者 BaggingRegressor ),输入的参数和随机子集抽取策略由用户指定。max_samples 和 max_features 控制着子集的大小(对于样例和特征), bootstrap 和 bootstrap_features 控制着样例和特征的抽取是有放回还是无放回的。 当使用样本子集时,通过设置 oob_score=True ,可以使用袋外(out-of-bag)样本来评估泛化精度。
采样概率
在Bagging中,一个样本可能被多次采样,也可能一直不被采样,假设一个样本一直不出现在采样集的概率为(1-1/N) ** N,那么对其求极限可知,原始样本数据集中约有63.2%的样本出现在了,Bagging使用的数据集中,同时在采样中,我们还可以使用袋外样本(out of Bagging)来对我们模型的泛化精度进行评估.
最终的预测结果
对于分类任务使用简单投票法,即每个分类器一票进行投票(也可以进行概率平均)
对于回归任务,则采用简单平均获取最终结果,即取所有分类器的平均值
基于KNN的Bagging算法
关于参数和方法要注意的是:
首先控制特征子采样与样本子采样是否采用,采用的话是否要注意控制比例(一般而言,不要采取较小的数值,太小的特征子采样和样本子采样都会造成子学习器的性能太差.一般而言特征选择越少,方差越大,这点可以与最后的实验方差偏差分解对比分析).
其次控制Bagging中的随机数参数random_state固定,不然不同实验的结果将不一致,同时要注意的很多时候random_state对于测试误差的影响很大,因此加入你想要在某一个数据集上使用Bagging,那么建议多尝试几个不同的Random_state
oob_score = True 对性能有一定的提升(使用袋外样本进行泛化能力的评估,但是很多时候效果并不明显,或者看不出什么效果)
其他参数一般默认即可
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# load data from sklearn import datasets,model_selection
def load_data():
iris=datasets.load_iris() # scikit-learn 自带的 iris 数据集
X_train=iris.data
y_train=iris.target
return model_selection.train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train)
bagging = BaggingClassifier(KNeighborsClassifier(),max_samples=0.1,max_features=0.5,random_state=1)
X_train,X_test,y_train,y_test=load_data()
bagging.fit(X_train,y_train)
y_pre = bagging.predict(X_test)
print(accuracy_score(y_test,y_pre))boosting
Boosting主要是Adaboost(Adaptive Boosting),它与Bagging的不同在于他将权重赋予每个训练元组,生成基分类器的过程为迭代生成。每当训练生成一个分类器M(i)时要进行权重更新,使得M(i+1)更关注被M(i)分类错误的训练元组。最终提升整体集合的分类准确率,集成规则是加权投票,每个分类器投票的权重是其准确率的函数。
继续详细介绍的话,假设数据集D,共有d类。(X1,Y1)…(Xd,Yd),Yi是Xi的类标号,假设需要生成k的分类器。其步骤为:
1、对每个训练元组赋予相等的权重1/d。
2、for i=1:k
从D中进行有放回的抽样,组成大小为d的训练集Di,同一个元组可以被多次选择,而每个元组被选中的几率由权重决定。利用Di训练得到分类器Mi,然后使用Di作为测试集计算Mi的误差。然后根据误差调整权重。
当元组没有被正确分类时,则权重增加;反之权重减少。然后利用新的权重为下一轮训练分类器产生训练样本。使其更“关注”上一轮中错分的元组。
3、进行加权投票集成
Bagging与Boosting的差异
通过上述简单的介绍,可以看出这两种集成算法主要区别在于“加没加权”。Bagging的训练集是随机生成,分类器相互独立;而Boosting的分类器是迭代生成,更关注上一轮的错分元组。因此Bagging的各个预测函数可以并行生成;而Boosting只能顺序生成。因此对于像一些比较耗时的分类器训练算法(如神经网络等)如果使用Bagging可以极大地解约时间开销。
但是通过在大多数数据集的实验,Boosting的准确率多数会高于Bagging,但是也有极个别数据集使用Boosting反倒会退化。
stacking
stakcing常常在各大数据挖掘竞赛中被广泛使用,号称“大杀器”。是数据挖掘竞赛高端玩家必备技能,本篇文章就对stakcing的一些基本原理进行介绍。
首先,在我看来stacking 严格来说不能称为一种算法,我理解的是一种非常精美而复杂的对模型的集成策略。大家都知道,在给定了数据集的情况下,数据内部的空间结构和数据之间的关系是非常复杂的。而不同的模型,其实很重要的一点就是在不同的角度去观测我们的数据集。比如说,KNN 可能更加关注样本点之间的距离关系(包括欧几里得距离(Euclidean Distance)、明可夫斯基距离(Minkowski Distance 等等),当样本距离相对较近, KNN 就把他们分为一类;而决策树,可能更加关注分裂节点时候的不纯度变化,有点像我们自己找的规则,在满足某个条件且满足某个条件的情况下,决策树把样本分为一类等等。也就是说,不同的算法模型,其实是在不同的数据空间角度和数据结构角度来观测数据,然后再依据它自己的观测,结合自己的算法原理,来建立一个模型,在新的数据集上再进行预测。这样大家就会有个疑问了,俗话说:三人行必有我师。既然是不同的算法对数据有不同的观测,那么我们能不能相互取长补短,我看看你的观测角度,你看看我的观测角度,咱俩结合一下,是不是可以得到一个更加全面更加优秀的结果呢?答案是肯定的。在我当初学基础算法的时候就有这么一个疑问,但是不知道怎么结合,直到有一天看到了 stacking的框架,瞬间感觉找到了一片新天地~~~~下面我从以下几个方面介绍 stacking。
一、stacking 的框架结构与运行过程:
刚开始看 stacking 好像是交叉检验的既视感,其实并不是这样。假设是五折的stacking,我们有一个train 数据集和一个test 数据集,那么一个基本的stacking 框架会进行如下几个操作:
1、选择基模型。我们可以有 xgboost,lightGMB,RandomForest,SVM,ANN,KNN, LR 等等你能想到的各种基本算法模型。
2、把训练集分为不交叉的五份。我们标记为 train1 到 train5。
3、从 train1 开始作为预测集,使用 train2 到 train5 建模,然后预测 train1,并保留结果;然后,以 train2 作为预测集,使用 train1,train3 到 train5 建模,预测 train2,并保留结果;如此进行下去,直到把 train1 到 train5 各预测一遍;
4、在上述建立的五个模型过程中,每个模型分别对 test 数据集进行预测,并最终保留这五列结果,然后对这五列取平均,作为第一个基模型对 test 数据的一个 stacking 转换。
5、把预测的结果按照 train1 到 trian5 的位置对应填补上,得到对 train 整个数据集在第一个基模型的一个 stacking 转换。
6、选择第二个基模型,重复以上 2-5 操作,再次得到 train 整个数据集在第二个基模型的一个 stacking 转换。
7、以此类推。有几个基模型,就会对整个train 数据集生成几列新的特征表达。同样,也会对test 有几列新的特征表达。
8、一般使用LR 作为第二层的模型进行建模预测。
bagging的优点:
易于并行计算
可以使用不在训练集中的样本来估计基学习器的性能
boosting的优点:
学习速度快能够有效利用弱学习器构建强大的学习器
boosting缺点与bagging相比更激进,更容易受噪声影响过拟合,不易并行
stacking多用于最终综合多个性能较好的模型,最易于过拟合
如何避免过拟合:
1、引入随机性
是机器学习中一个广为使用的避免过拟合的方法
stacking示例代码
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label)) 转载于:https://blog.51cto.com/yixianwei/2116117