如何通过StackStorm自动支持2万多台服务器
在过去的三年中,我们的网络为成千上万次直播体育赛事、海量软件下载、数十亿小时流媒体视频内容以及数千个需要实时响应的Web应用程序提供支持。为了支持这种大规模的增长,从2015年开始,我们的全球网络已经增加到71 Tbps,我们在135个PoP中部署了数千台新服务器。
网络部署规模不断增长和变化,为了解决这方面的挑战,我们的运营团队使用StackStorm开发了一个IT自动化平台。这是一个巨大的飞跃,改变了我们部署、变更、修复和停用服务器的方式,这些服务器占到了我们全球网络95%以上的比例。
以下是这个自动化平台给我们带来的好处:
- 在三年内将12,000多台服务器添加到我们的网络中。
- 在某些情况下自动生成ticket,在没有ticket的情况下自动解决问题。
- 为团队提供工具,让他们可以进行实时的协作。
- 遵循一系列手动步骤为工程师节省时间。
基于StackStorm的自定义项目Crayfish
因为认识到IT自动化平台的价值以及这种平台的日益成熟,2015年,我们成立了基础设施自动化团队,并开始了Crayfish(小龙虾)项目,认真开发IT自动化解决方案——对于我们这样规模的企业来说,这是一项艰巨的任务。项目名称的选择——我们现在仍在使用——是有意而为之的。一直以来,我们的工具都以鱼类和航海为主题,我们之所以选择Crayfish,是因为小龙虾是滤食性动物,可以保持环境的清洁。
最开始我们也考虑过开发自己的IT自动化框架,后来决定使用StackStorm(https://stackstorm.com/),并通过增强功能来支持我们独特的需求和规模,让我们能够更高效地往前走。
StackStorm是一个开源的基于事件驱动的平台,支持“基础设施即代码”。它擅长基于事件运行工作流,可以与Slack集成,并提供了原生的ChatOps支持。
我们已经对StackStorm做出了一些配置变更来满足我们所需的规模。首先,我们需要增加服务实例的数量,并减少数据保留。在项目启动时,我们的网络有8,000台服务器,而现在服务器数量已经达到20,000台。可伸缩性的关键在于能够运行任意数量的StackStorm实例,并把它们作为worker运行,而不是让单个StackStorm实例处理所有的东西。如下图所示,我们开发的一个叫作Policy Engine的东西可以帮我们做到这一点,它会根据我们的业务逻辑将提交的请求转发给StackStorm。Policy Engine还可以将请求放在队列中,并在安全的情况下自动处理这些请求。这些策略用来监控并发、容量、流量、生产状态、基础设施、黑名单和故障率。
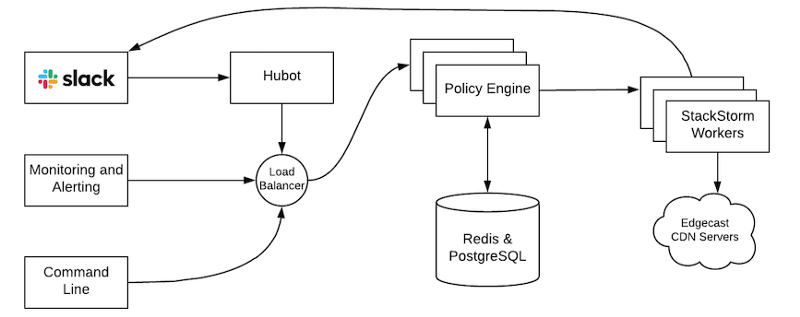
编撰部落知识
IT自动化项目的基本方法是捕获现有流程和工作流,然后将它们转换为可以在不需要人工干预的情况下实现工作流步骤的代码,并将它们存储在中央存储库中,然后作为自动化的一部分或通过ChatOps命令来调用它们。
项目开始后,Crayfish团队捕获了整个组织现有的工作流程和流程。所幸的是,不同部门使用的大多数重要的流程(例如网络运营中心、数据中心运营或SysOps)都有详细的记录,可以使用Python来快速编码并添加到Crayfish中。
例如,如果我们的网络运营中心想要实现一个重启工作流,它首先需要根据各种策略验证在机器上运行工作流是否安全。如果服务器处于生产环境中,系统将会采取措施来消耗连接并更新状态。接下来,它将执行实际的重启动作和必要的步骤来验证机器是否已经准备好进入生产状态。
可以肯定的是,我们遇到了很多边缘案例,其中最具挑战性的是那些还没有被记录到文档中的流程。为了搞定这些边缘案例,我们需要进行跨职能合作,并与正确的人沟通。自动化的一个好处是我们可以捕获到这些知识,确保它们在我们的组织中继续存在。
在某些情况下,我们甚至与一些了解特定任务或知道如何解决特定问题的工程师和技术人员一起合作,找出更有效处理特定任务的方法。我们发现,在某些情况下,不同团队成员的知识水平是不一样的。那时候,我们开始收集每个人的意见,提出一个每个人都同意的工作流,并将其作为最有效的解决方案。
按需部署新服务器
Crayfish已经从多个层面改变了我们的IT运营,例如简化服务器管理、减少服务器停机时间以及加快服务器部署。仅在2018年一年,ITOps就为我们的全球网络增加了22 Tbps的容量。如果没有Crayfish的自动化,就不可能新增数千台服务器,而且这是在不需要显著提高员工技术水平的情况下完成的。
目前,Crayfish为大约20种不同的服务器类型提供强大的自动化功能。我们将服务器类型定义为运行相似服务的一组服务器。不同的应用程序运行在不同的服务器类型上,因此每种服务器类型在生产环境中需要得到不同的支持。今天,Crayfish支持大约10种服务器类型的完整生命周期,并且还可以对大约10种其他服务器类型做出修复、更改和打补丁。它还为大约40或50多种服务器类型提供不同程度的支持。由于我们专注于部署使用最广泛的服务器类型,因此Crayfish可以为约96%服务器提供支持。
因为使用了Crayfish,CDN的整体性能得到了提升,并且具备了应对意外事件的能力。我们的网络设备齐全,可以支持来自主要体育赛事和峰值软件下载的流量,例如,将更多的服务器保留在生产环境中,减少在高峰期间从生产环境中移除服务器所造成的中断。
从性能的角度来看,因为我们的规模够大,所以才体现出Crayfish的重要性。如果你的公司有一个数据中心,并且你可以控制停机时间,那么你就完全可以掌控数据中心。但如果是像下图所示的那样,数据中心跨越了几乎所有的时区,那么你就不得不去应对不同的配置文件、使用情况和使用时间。如果把所有这些考虑因素考虑在内,具体情况可能会非常复杂,但Crayfish可以轻松处理它们。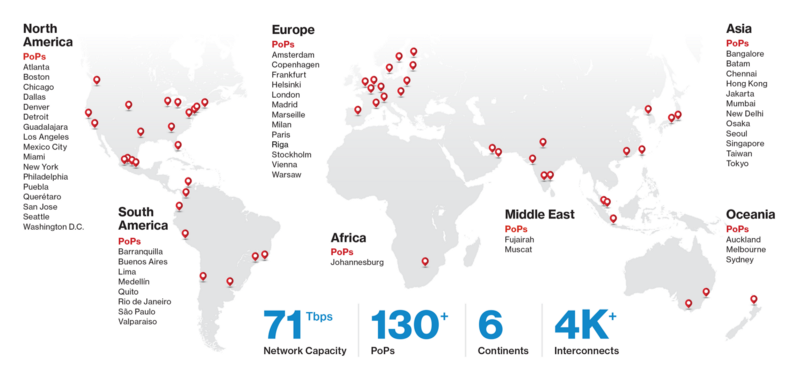
在使用Crayfish时,我们仍然可以调度任务,例如自动执行配置或升级,但系统可以智能地满足本地需求。例如,当我们想要重新配置拉脱维亚的所有服务器时,拉脱维亚的某个新闻事件会导致视频流量大幅增加。因为Crayfish与我们的度量收集系统集成在一起,所以系统将会看到流量增加,重新配置操作就会停止。如果有必要,甚至可以将更多服务器加入到生产环境中。
在服务中断之前捕获基础设施故障
Crayfish与其他监控系统相结合可以显著减少个别服务器的停机时间和维修时间。我们的系统持续监控网络是否出现了问题或故障,并且可以自动创建故障ticket或直接打补丁。有了自动化系统,我们的员工不需要通过“死盯”的方式来发现网络错误——计算机会永不疲倦地进行持续的监控。
我们可以通过这种方式完成的检查几乎没有数量上的限制。我们的度量系统不断运行硬件检查,不需要将机器撤出生产环境,而另一个系统会查找错误,并在发现问题时调用Crayfish对机器执行检查。通过这种方法,我们能够及早地发现硬件故障。
例如,如果有指标显示硬盘驱动器开始出现故障,自动化系统将启动Crayfish中的工作流,对受影响的计算机进行错误验证,并收集有关故障的详细信息,例如硬盘驱动器在哪个插槽中出现故障、屏蔽号码,等等。然后,它会为数据中心运维组创建ticket,运维组会派技术人员前往安装替换硬件。
根据经验,任何需要多个部门协作或多个步骤之间需要手动切换的工作流都会带来严重的延迟。有了自动化工作流,完成时间可以是几分钟,而不是几天。这给了每个运维团队更大的控制权,他们是最了解他们系统和应用程序的人。
为工程师提供可以让他们变得更高效的工具
我们以前都是向网络运营中心发出命令,然后等待事情发生。如果网络运营中心的技术人员花了10分钟、20分钟或30分钟等待服务器正常关闭,你必须要去问为什么。而Crayfish可以并行执行多个任务,而且支持横向扩展。因此,如果我们需要处理更多的工作负载,可以添加新节点。如果我们突然发现需要同时处理大量的工作负载,可以跨整个CDN扩展多个节点,在处理完成后再缩减节点。
而且,技术人员的工作记忆是有限的,他们在同一时间只能操作几台机器。只有最出色的多任务处理程序才能同时处理五六台处于不同状态的机器,而且保证不会丢失跟踪状态或出现错误。在使用Crayfish时,不需要在各种任务之间切换,它们发出命令,然后继续后续的处理。
Crayfish构建在由软件基础设施和系统运营团队开发的智能配置系统之上,所以完全支持服务器生命周期的其他方面,并在很大程度上是自治的,包括操作系统更新、服务器配置或重新配置、固件更新和安全补丁。当有新补丁发布时,Crayfish会快速进行验证,以确保补丁可以发布。
因为Crayfish与Slack进行了集成,所以它也支持一般性的IT流程,并在需求发生变化时能够促进团队之间的协作。现在,团队可以将手动流程定义为自动化工作流,而不需要等待某个部门实现变更。然后,他们可以为最终用户提供按需运行的工作流。现在还可以限制安全运行工作流的策略。在数据中心里工作的工程师也可以发出命令来修改服务器的生产状态。
最后的想法
由于成千上万的客户每天通过我们的20,000多台服务器推送数TB的数据,StackStorm已经成为保持服务健康和安全的重要运维工具。我们现在能够更快地扩展网络来满足客户的需求,同时在发生动态变化和意外流量激增的情况下提供更好的性能。这种运营灵活性让我们成为更可靠的服务提供商,并具备足够的伸缩性来满足流媒体和Web应用程序的需求。
虽然其他大多数企业的规模与我们不同,但仍然有很多东西可以进行自动化,包括:
- 让开发人员专注于能够带来更高回报的工作。
- 标准化普通的日常任务。
- 改善跨部门的协作。
- 减少服务器停机时间。
- 通过固件更新和安全补丁来提高安全性。
毫无疑问,向IT自动化的转变提供了非常有吸引力的投资回报,但最重要的是要确保你的初衷是正确的。我们可以将自动化视为一种为工程师提供工具的方法,这些工具可以提高他们的工作效率和熟练程度,并使他们能够专注于做出改进。
如果做得好,向基于工作流的自动化过渡是社交化和编撰部落知识的一种非常好的方式。我们将部落聚集在一起,提出一个共同的工作流,并让每个人都能在未来基于共同的基线贡献自己的知识。
英文原文:https://medium.com/@verizondigital/using-stackstorm-to-automate-support-for-20-000-servers-4b47ae3a4e98