自然语言处理系列之: NLP中用到的机器学习算法
大纲
- 机器学习的一些基本概念:有/无监督学习、半监督学习、回归、降维等
- 机器学习常用分类算法:朴素贝叶斯、支持向量机、逻辑回归等
- 机器学习的聚类方法:k-means算法
- 机器学习的应用
9.1 简介
-
机器学习训练的要素
- 数据
- 转换数据的模型
- 衡量模型好坏的损失函数
- 调整模型权重以最小化损失函数的算法
-
机器学习中最重要的四类问题(按学习结果)
- 预测(Prediction):用回归(Regression,Arima)等模型;
- 聚类(Clustering):如K-means方法;
- 分类(Classification):支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistic Regression);
- 降维(Dimensional reduction):主成分分析法(Principal Component Analysis,即纯矩阵运算);
-
按学习方法分
- 监督学习(Supervised Learning):给定输入 x x x,如何通过在标注输入和输出的数据上训练模型而预测输出 y y y;
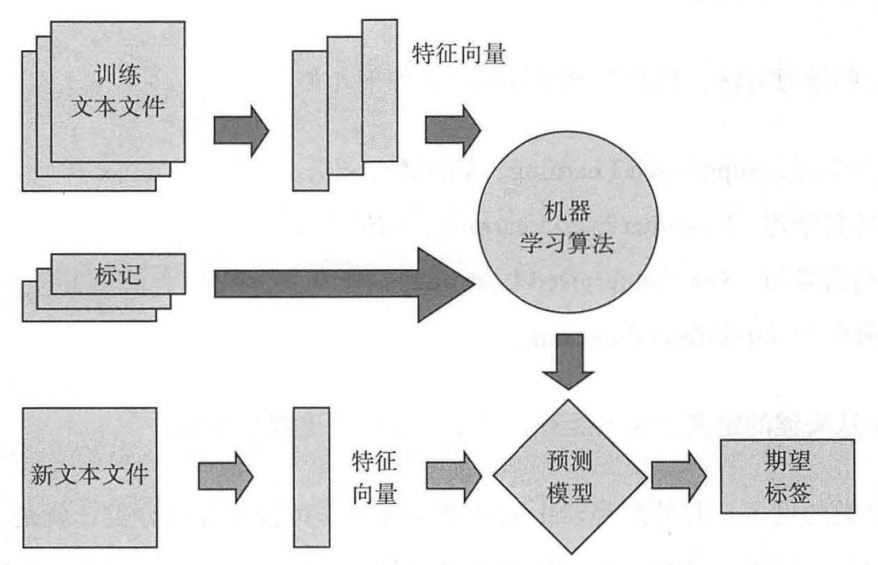
主要是先准备训练数据,然后抽取所需特征形成特征向量(Feature Vectors),将这些特征连同对应标记(label)一起给学习算法,训练出一个预测模型(Predictive Model),然后采用同样的特征提取方法对新测试数据进行特征提取,然后使用预测模型对将来的数据进行预测;- 无监督学习(Un-supervised Learning)
- 半监督学习(Semi-supervised Learning)
- 增强学习(Reinforced Learning)
9.2 几种常用机器学习方法
-
文本分类
大致分为以下步骤:
- 定义阶段:定义数据及分类体系,具体分为哪些类别,需要哪些数据;
- 数据预处理:对文档分词、去停用词等;
- 数据提取特征:对文档矩阵降维,提取训练集中最有用的特征;
- 模型训练阶段:选择具体分类模型及算法,训练文本分类器;
- 评测阶段:测试集上测试并评价分类器性能;
- 应用阶段:应用性能最高的分类模型对分类文档进行分类;
-
特征提取
- Bag-of-words:最原始的特征集,一个单词/分词即为一个特征;
- 统计特征:Term frequency(TF)、Inverse document frequency(IDF);
- N-Gram:考虑词汇顺序的模型,即N阶Markov链,每个样本转移为转移概率矩阵;
-
序列学习
- 语音识别
- 文本转语音
- 机器翻译
9.3 分类器方法
- 朴素贝叶斯