斯坦福大学机器学习,EM算法求解高斯混合模型。一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的方法来融合高斯分量。从对比结果可以看出,基于聚类的高斯混合模型的说话人识别相对于传统的高斯混合模型在识别率上有所提高。
------------------------------
高斯模型有单高斯模型(SGM)和混合高斯模型(GMM)两种。
(1)单高斯模型:

为简单起见,阈值t的选取一般靠经验值来设定。通常意义下,我们一般取t=0.7-0.75之间。
![]()
二维情况如下所示:

(2)混合高斯模型:

对于(b)图所示的情况,很明显,单高斯模型是无法解决的。为了解决这个问题,人们提出了高斯混合模型(GMM),顾名思义,就是数据可以看作是从数个高斯分布中生成出来的。虽然我们可以用不同的分布来随意地构造 XX Mixture Model ,但是 GMM是 最为流行。另外,Mixture Model 本身其实也是可以变得任意复杂的,通过增加 Model 的个数,我们可以任意地逼近任何连续的概率密分布。
每个 GMM 由 K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
 (1)
(1)
其中,πk表示选中这个component部分的概率,我们也称其为加权系数。
根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:
(1)首先随机地在这 K 个 Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 πk,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。假设现在有 N 个数据点,我们认为这些数据点由某个GMM模型产生,现在我们要需要确定 πk,μk,σk 这些参数。很自然的,我们想到利用最大似然估计来确定这些参数,GMM的似然函数如下:
 (2)
(2)
在最大似然估计里面,由于我们的目的是把乘积的形式分解为求和的形式,即在等式的左右两边加上一个log函数,但是由上文博客里的(2)式可以看出,转化为log后,还有log(a+b)的形式,因此,要进一步求解。
我们采用EM算法,分布迭代求解最大值:
EM算法的步骤这里不作详细的介绍,可以参见博客:
http://blog.pluskid.org/?p=39
函数返回的 Px 是一个 的矩阵,对于每一个 ,我们只要取该矩阵第 行中最大的那个概率值所对应的那个 Component 为
所属的 cluster 就可以实现一个完整的聚类方法了。
------------------------------
EM算法(Expection-Maximizationalgorithm,EM)是一种迭代算法,通过E步和M步两大迭代步骤,每次迭代都使极大似然函数增加。但是,由于初始值的不同,可能会使似然函数陷入局部最优。辜丽川老师和其夫人发表的论文:基于分裂EM算法的GMM参数估计 改进了这一缺陷。下面来谈谈EM算法以及其在求解高斯混合模型中的作用。
一、 高斯混合模型(Gaussian MixtureModel, GMM)
高斯判别分析模型,利用参数估计的方法用于解决二分类问题。下面介绍GMM,它是对高斯判别模型的一个推广,也能借此引入EM算法。
假设样本集为并且样本和标签满足联合分布
。这里:
服从多项式分布,即
(
,
,
),且
;在
给定的情况下,
服从正态分布,即
。这样的模型称为高斯混合模型。
该模型的似然函数为:
如果直接令的各变量偏导为0,试图分别求出各参数,我们会发现根本无法求解。但如果变量
是已知的,求解便容易许多,上面的似然函数可以表示为:
利用偏导求解上述式,可分别得到参数的值:
其中,#{ }为指示函数,表示满足括号内条件的数目。
那么,变量无法通过观察直接得到,
就称为隐变量,就需要通过EM算法,求解GMM了。下面从Jensen不等式开始,介绍下EM算法:
二、 Jensen不等式(Jensen’s inequality)
引理:如果函数f的定义域为整个实数集,并且对于任意x或存在
或函数的Hessian矩阵
,那么函数f称为凹函数。
或函数的Hessian矩阵H>0,那么函数f为严格凹函数。
(存在或函数的Hessian矩阵
,那么函数f称为凸函数;如果
或函数的Hessian矩阵 H<0,那么函数f为严格凸函数。)
定理:如果函数f是凹函数,X为随机变量,那么:
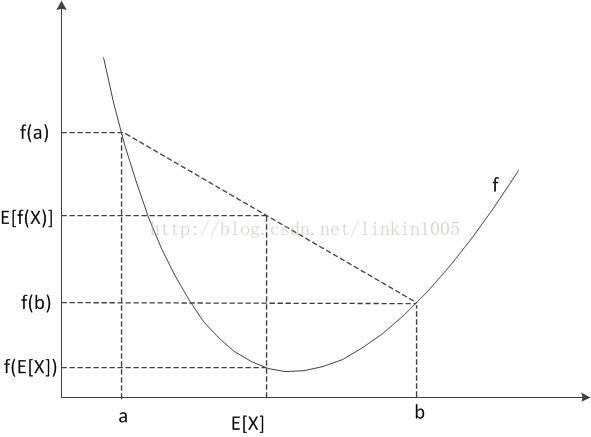
不幸的是很多人都会讲Jensen不等式记混,我们可以通过图形的方式帮助记忆。下图中,横纵坐标轴分别为X和f(X),f(x)为一个凹函数,a、b分别为变量X的定义域,E[X]为定义域X的期望。图中清楚的看到各个量的位置和他们间的大小关系。反之,如果函数f是凸函数,X为随机变量,那么:
Jensen不等式等号成立的条件为:,即X为一常数。
三、 EM算法
假设训练集是由m个独立的样本构成。我们的目的是要对
概率密度函数进行参数估计。它的似然函数为:
然而仅仅凭借似然函数,无法对参数进行求解。因为这里的随机变量是未知的。
EM算法提供了一种巧妙的方式,可以通过逐步迭代逼近最大似然值。下面就来介绍下EM算法:
假设对于所有i,皆为随机变量
的分布函数。即:
。那么:
其中第(2)步至第(3)步的推导就使用了Jensen不等式。其中:f(x)=log x,,因此为凸函数;
表示随机变量为
概率分布函数为
的期望。因此有:
这样,对于任意分布,(3)都给出了
的一个下界。如果我们现在通过猜测初始化了一个
的值,我们希望得到在这个特定的
下,更紧密的下界,也就是使等号成立。根据Jensen不等式等号成立的条件,当
为一常数时,等号成立。即:
由上式可得,又
,因此
。再由上式可得:
上述等式最后一步使用了贝叶斯公示。
EM算法有两个步骤:
(1)通过设置初始化值,求出使似然方程最大的
值,此步骤称为E-步(E-step)
(2)利用求出的值,更新
。此步骤称为M-步(M-step)。过程如下:
repeat until convergence{
(E-step) for each i, set
(M-step) set
}
那么,如何保证EM算法是收敛的呢?下面给予证明:
假设和
是EM算法第t次和第t+1次迭代所得到的参数
的值,如果有
,即每次迭代后似然方程的值都会增大,通过逐步迭代,最终达到最大值。以下是证明:
不等式(4)是由不等式(3)得到,对于任意和
值都成立;得到不等式(5)是因为我们需要选择特定的
使得方程
在
处的值大于在
处的值;等式(6)是找到特定的
的值,使得等号成立。
最后我们通过图形的方式再更加深入细致的理解EM算法的特点:
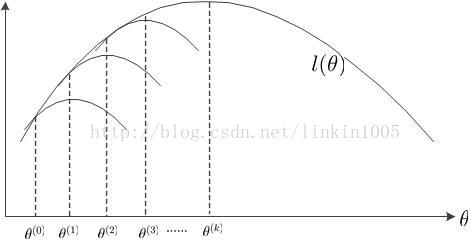
由上文我们知道有这样的关系:,EM算法就是不断最大化这个下界,逐步得到似然函数的最大值。如下图所示:
首先,初始化,调整
使得
与
相等,然后求出
使得到最大值的
;固定
,调整
,使得
与
相等,然后求出使
得到最大值的
;……;如此循环,使得
的值不断上升,直到k次循环后,求出了
的最大值
。
四、 EM算法应用于混合高斯模型(GMM)
再回到GMM:上文提到由于隐变量E-Step:
(1)参数
对期望的每个分量
求偏导:
令上式为0,得:
观察M-Step,可以看到,跟相关的变量仅仅有
。因此,我们仅仅需要最大化下面的目标函数:
又由于,为约束条件。因此,可以构造拉格朗日算子求目标函数:
求偏导:
令得:
将带入上式得:
最后将带入得:
(3)参数
令上式为零,解得:
五、 总结
EM算法利用不完全的数据,进行极大似然估计。通过两步迭代,逐渐逼近最大似然值。而GMM可以利用EM算法进行参数估计。
最后提下辜老师论文的思路:EM模型容易收敛到局部最大值,并且严重依赖初试值。传统的方法即上文中使用的方法是每次迭代过程中,同时更新高斯分布中所有参数,而辜老师的方法是把K个高斯分布中的一个分量,利用奇异值分解的方法将其分裂为两个高斯分布,并保持其他分量不变的情况下,对共这K+1个高斯分布的权值进行更新,直到符合一定的收敛条件。这样一来,虽然算法复杂度没有降低,但每轮只需要更新两个参数,大大降低了每轮迭代的计算量。
------------------------------
本人微信公众帐号: 心禅道(xinchandao)




本人微信公众帐号:双色球预测合买(ssqyuce)