本博文的主要内容有
.Storm的单机模式安装
.Storm的分布式安装(3节点)
.No space left on device
.storm工程的eclipse的java编写
http://storm.apache.org/

分布式的一个计算系统,但是跟mr不一样,就是实时的,实时的跟Mr离线批处理不一样。
离线mr主要是做数据挖掘、数据分析、数据统计和br分析。
Storm,主要是在线的业务系统。数据像水一样,源源不断的来,然后,在流动的过程中啊,就要把数据处理完。比如说,一些解析,业务系统里采集的一些日志信息、报文啊,然后呢,把它们解析成某一种格式,比如说解析过来的xml格式,然后呢,最后呢,要落到一个SQL或NoSQL数据库里去。
在这落进去之前,就得源源不断地,就要处理好,这一工具就是靠storm工具。
当然,hadoop也可以做,但是它那边是离线的批量。

Storm它自己,是不作任何存储的,数据有地方来,结果有地方去。一般是结合消息队列或数据库来用的,消息队列是数据源,数据库是数据目的地。











Bolts,可以理解为水厂里的处理的每个环节。
storm相关概念图

参考链接:http://www.xuebuyuan.com/1932716.html
http://www.aboutyun.com/thread-15397-1-1.html
Storm单机运行是不是不需要启动zookeeper、Nimbus、Supervisor ? About云开发
http://www.dataguru.cn/thread-477891-1-1.html
Storm单机+zookeeper集群安装
由于,Storm需要zookeeper,而,storm自带是没有zookeeper的。
需要依赖外部安装的zookeeper集群。业务里,一般都是3节点的zookeeper集群,而是这里只是现在入门,先来玩玩。
Zookeeper的单机模式安装,这里就不多赘述了。
见,我的博客
1 week110的zookeeper的安装 + zookeeper提供少量数据的存储
Storm的单机模式安装
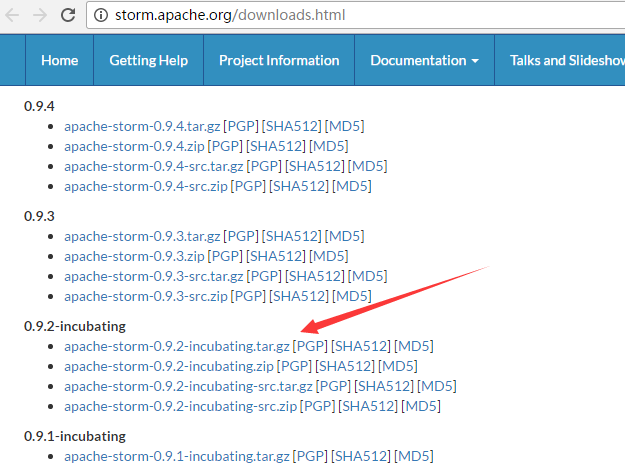
1、 apache-storm-0.9.2-incubating.tar.gz的下载
http://storm.apache.org/downloads.html
2、 apache-storm-0.9.2-incubating.tar.gz的上传

sftp> cd /home/hadoop/app/
sftp> put c:/apache-storm-0.9.2-incubating.tar.gz
Uploading apache-storm-0.9.2-incubating.tar.gz to /home/hadoop/app/apache-storm-0.9.2-incubating.tar.gz
100% 19606KB 6535KB/s 00:00:03
c:/apache-storm-0.9.2-incubating.tar.gz: 20077564 bytes transferred in 3 seconds (6535 KB/s)
sftp>

[hadoop@weekend110 app]$ ls
hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1
[hadoop@weekend110 app]$ ls
apache-storm-0.9.2-incubating.tar.gz hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1
3、 apache-storm-0.9.2-incubating.tar.gz的压缩
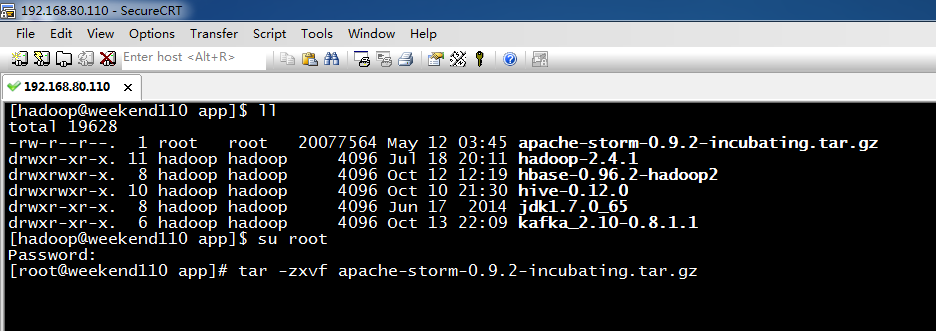
[hadoop@weekend110 app]$ ll
total 19628
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[hadoop@weekend110 app]$ su root
Password:
[root@weekend110 app]# tar -zxvf apache-storm-0.9.2-incubating.tar.gz
4、 apache-storm-0.9.2-incubating.tar.gz的权限修改和删除压缩包

[root@weekend110 app]# ll
total 19632
drwxr-xr-x. 9 root root 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[root@weekend110 app]# chown -R hadoop:hadoop apache-storm-0.9.2-incubating
[root@weekend110 app]# ll
total 19632
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
-rw-r--r--. 1 root root 20077564 May 12 03:45 apache-storm-0.9.2-incubating.tar.gz
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[root@weekend110 app]# rm apache-storm-0.9.2-incubating.tar.gz
rm: remove regular file `apache-storm-0.9.2-incubating.tar.gz'? y
[root@weekend110 app]# ll
total 24
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[root@weekend110 app]#
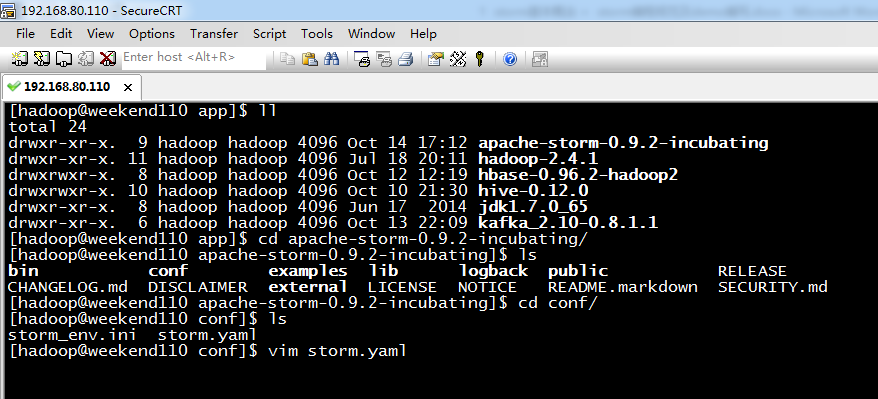
5、 apache-storm-0.9.2-incubating.tar.gz的配置
[hadoop@weekend110 app]$ ll
total 24
drwxr-xr-x. 9 hadoop hadoop 4096 Oct 14 17:12 apache-storm-0.9.2-incubating
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 6 hadoop hadoop 4096 Oct 13 22:09 kafka_2.10-0.8.1.1
[hadoop@weekend110 app]$ cd apache-storm-0.9.2-incubating/
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ ls
bin conf examples lib logback public RELEASE
CHANGELOG.md DISCLAIMER external LICENSE NOTICE README.markdown SECURITY.md
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ cd conf/
[hadoop@weekend110 conf]$ ls
storm_env.ini storm.yaml
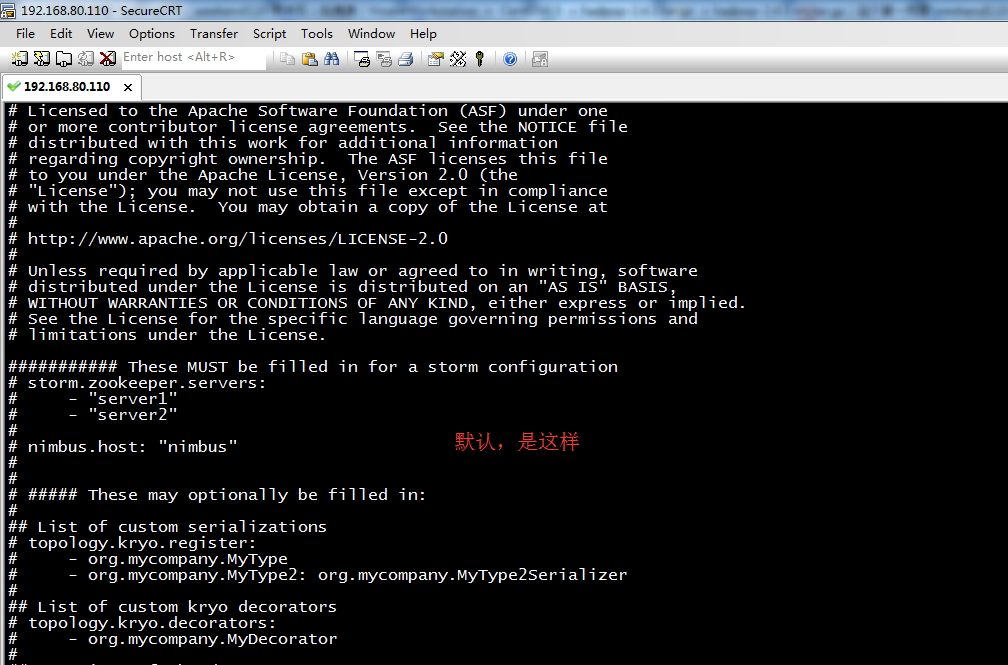
[hadoop@weekend110 conf]$ vim storm.yaml
# storm.zookeeper.servers:
# - "server1"
# - "server2"
#
# nimbus.host: "nimbus"
修改为
#storm所使用的zookeeper集群主机
storm.zookeeper.servers:
- "weekend110"
#nimbus所在的主机名
nimbus.host: " weekend110"

# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########### These MUST be filled in for a storm configuration
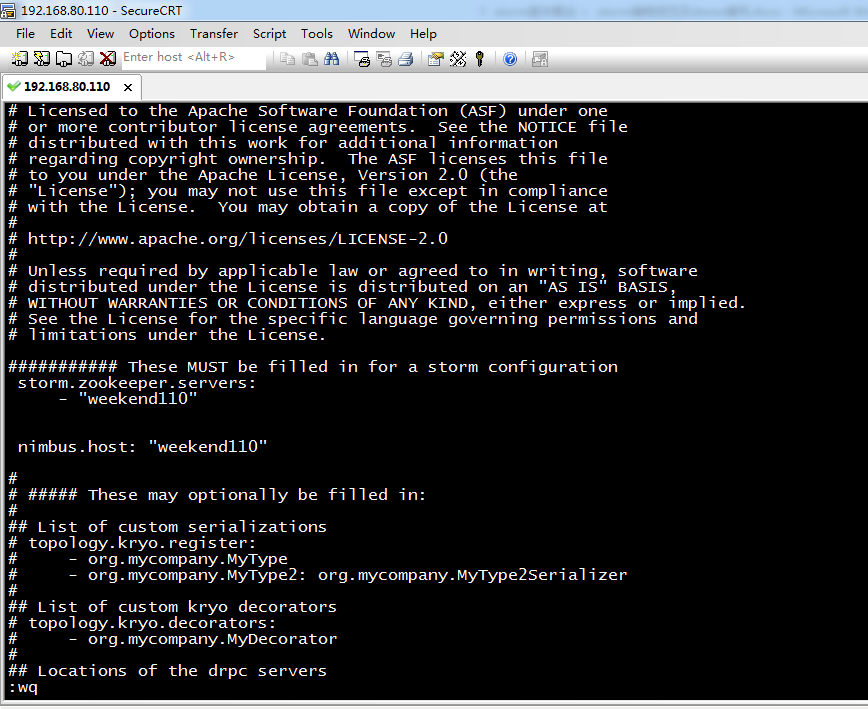
storm.zookeeper.servers:
- "weekend110"
nimbus.host: "weekend110"
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"
## Metrics Consumers
# topology.metrics.consumer.register:
# - class: "backtype.storm.metric.LoggingMetricsConsumer"
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
在这里,也许,修改不了,就换成root权限。
6、apache-storm-0.9.2-incubating.tar.gz环境变量
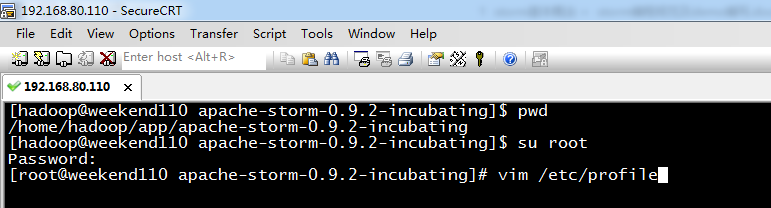
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ su root
Password:
[root@weekend110 apache-storm-0.9.2-incubating]# vim /etc/profile
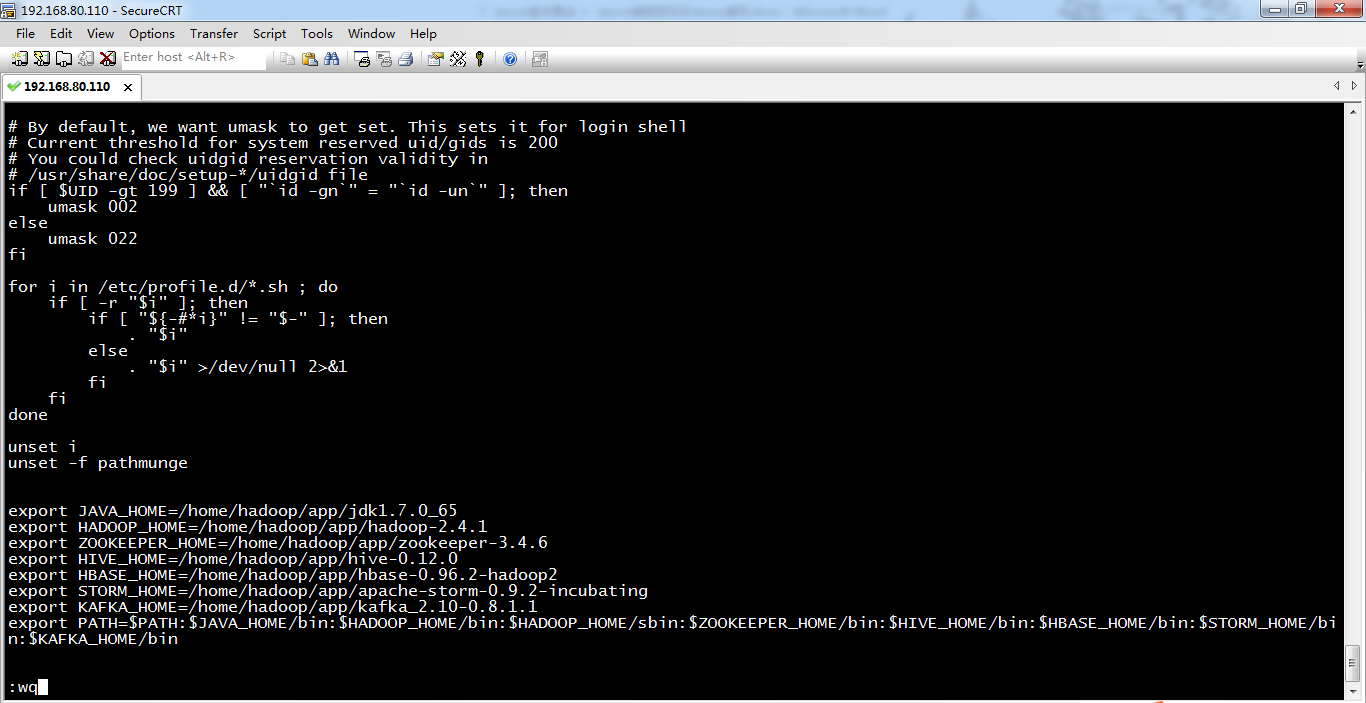
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper-3.4.6
export HIVE_HOME=/home/hadoop/app/hive-0.12.0
export HBASE_HOME=/home/hadoop/app/hbase-0.96.2-hadoop2
export STORM_HOME=/home/hadoop/app/apache-storm-0.9.2-incubating
export KAFKA_HOME=/home/hadoop/app/kafka_2.10-0.8.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin
[root@weekend110 apache-storm-0.9.2-incubating]# source /etc/profile
[root@weekend110 apache-storm-0.9.2-incubating]#
启动
先启动,外部安装的zookeeper,
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
4640 Jps
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ cd /home/hadoop/app/zookeeper-3.4.6/
[hadoop@weekend110 zookeeper-3.4.6]$ pwd
/home/hadoop/app/zookeeper-3.4.6
[hadoop@weekend110 zookeeper-3.4.6]$ cd bin
[hadoop@weekend110 bin]$ ./zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/app/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@weekend110 bin]$ jps
4675 Jps
4659 QuorumPeerMain
[hadoop@weekend110 bin]$ cd /home/hadoop/app/apache-storm-0.9.2-incubating/
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ cd bin
[hadoop@weekend110 bin]$ ls
storm storm.cmd storm-config.cmd
[hadoop@weekend110 bin]$ ./storm nimbus
参考:
http://zhidao.baidu.com/link?url=GXpabgBPsQQERdSalEw5f2KC1YH4vo7xQlZzsz5xR7gongO2CspeezWxq1_Gg94ijSiner42flaJQBsONonxOjQwpDLKr-y4bNmDMyUoQiO
一般,推荐
在nimbus机器上,执行
[hadoop@weekend110 bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
//意思是,启动主节点
[hadoop@weekend110 bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
//意思是,启动ui界面

启动,报错误。
http://blog.csdn.net/asas1314/article/details/44088003
参考这篇博客。
storm.zookeeper.servers:
- "192.168.1.117"
nimbus.host: "192.168.1.117"
storm.local.dir: "/home/chenny/Storm/tmp/storm"
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
topology.debug: "true"
需要注意的是Storm读取此配置文件,要求每一行开始都要有一个空格,每一个冒号后面也要有一个空格,否则就会出现错误,造成启动失败。我们同样可以为Storm添加环境变量,来方便我们的启动、停止。
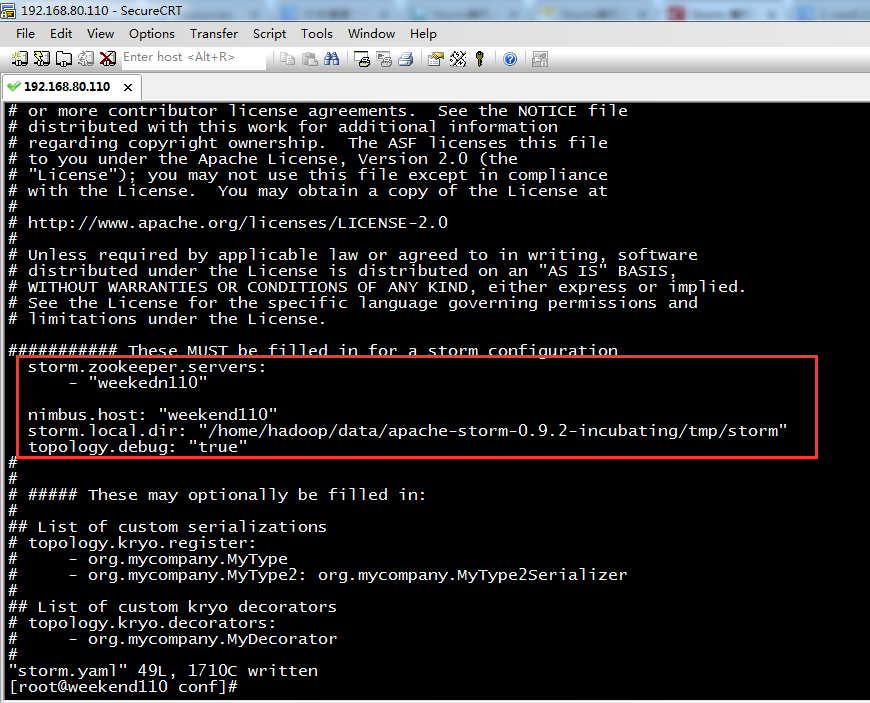
storm.zookeeper.servers:
- "weekedn110"
nimbus.host: "weekend110"
storm.local.dir: "/home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm"
topology.debug: "true"

[hadoop@weekend110 apache-storm-0.9.2-incubating]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ mkdir -p /home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm
mkdir: cannot create directory `/home/hadoop/data/apache-storm-0.9.2-incubating': No space left on device
[hadoop@weekend110 apache-storm-0.9.2-incubating]$
磁盘清理
经过,这个问题,依然还是解决不了。。
为此,我把storm的路径,安装到了,/usr/local/下,
吸取了,教训,就是,在系统安装之前。分区要大些。
特别对于/和/home/,这两个分区。因为是常安装软件的目录啊!!!呜呜~~
在这里,我依然还是未解决问题。
记本博文于此,为了方便日后的再常阅和再解决!
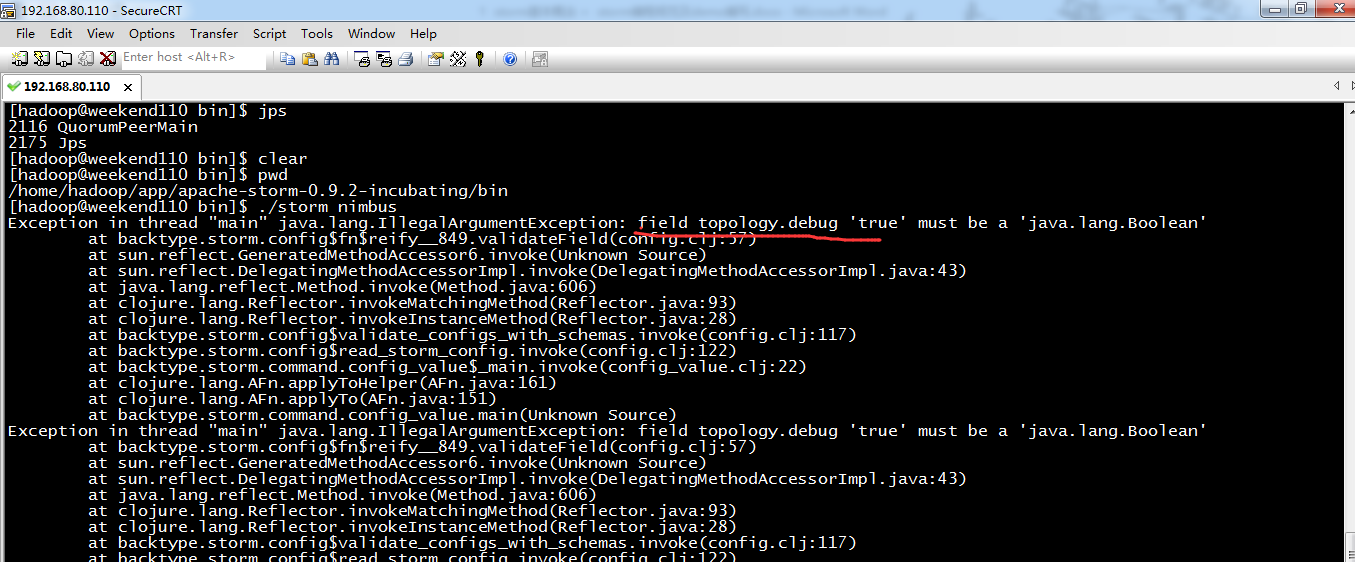
错误:
Exception in thread "main" java.lang.IllegalArgumentException: field topology.debug 'true' must be a 'java.lang.Boolean'

但是,这是前台程序,把这个窗口一关,就不行了。
一般,推荐
[hadoop@weekend110 bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
//意思是,启动主节点
[hadoop@weekend110 bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
//意思是,启动ui界面
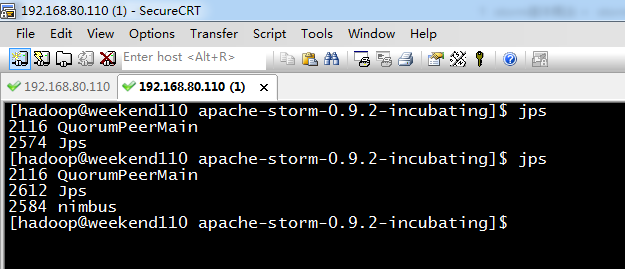

[hadoop@weekend110 bin]$ pwd
/home/hadoop/app/apache-storm-0.9.2-incubating/bin
[hadoop@weekend110 bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
[1] 2700
[hadoop@weekend110 bin]$ nohup ./storm ui 1>/dev/null 2>&1 &
[2] 2742
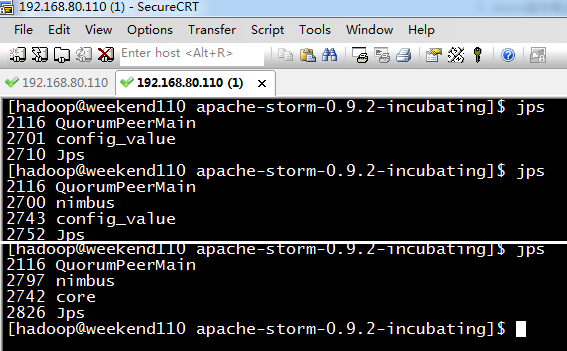
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2701 config_value //代表,正在启动,是中间进程,这里是nimbus的中间进程
2710 Jps
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2700 nimbus
2743 config_value //代表,正在启动,是中间进程,这里是core的中间进程
2752 Jps
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2797 nimbus
2742 core
2826 Jps
[hadoop@weekend110 apache-storm-0.9.2-incubating]$
启动storm
在nimbus主机上
nohup ./storm nimbus 1>/dev/null 2>&1 &
nohup ./storm ui 1>/dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1>/dev/null 2>&1 &

[hadoop@weekend110 bin]$ nohup ./storm nimbus 1>/dev/null 2>&1 &
[3] 2864
[hadoop@weekend110 bin]$ nohup ./storm supervisor 1>/dev/null 2>&1 &
[4] 2875

[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2855 Jps
2742 core
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2903 config_value
2885 config_value
2742 core
2894 Jps
[hadoop@weekend110 apache-storm-0.9.2-incubating]$ jps
2116 QuorumPeerMain
2937 Jps
2742 core
2875 supervisor
2947 nimbus
[hadoop@weekend110 apache-storm-0.9.2-incubating]$
进入,
http://weekend110:8080
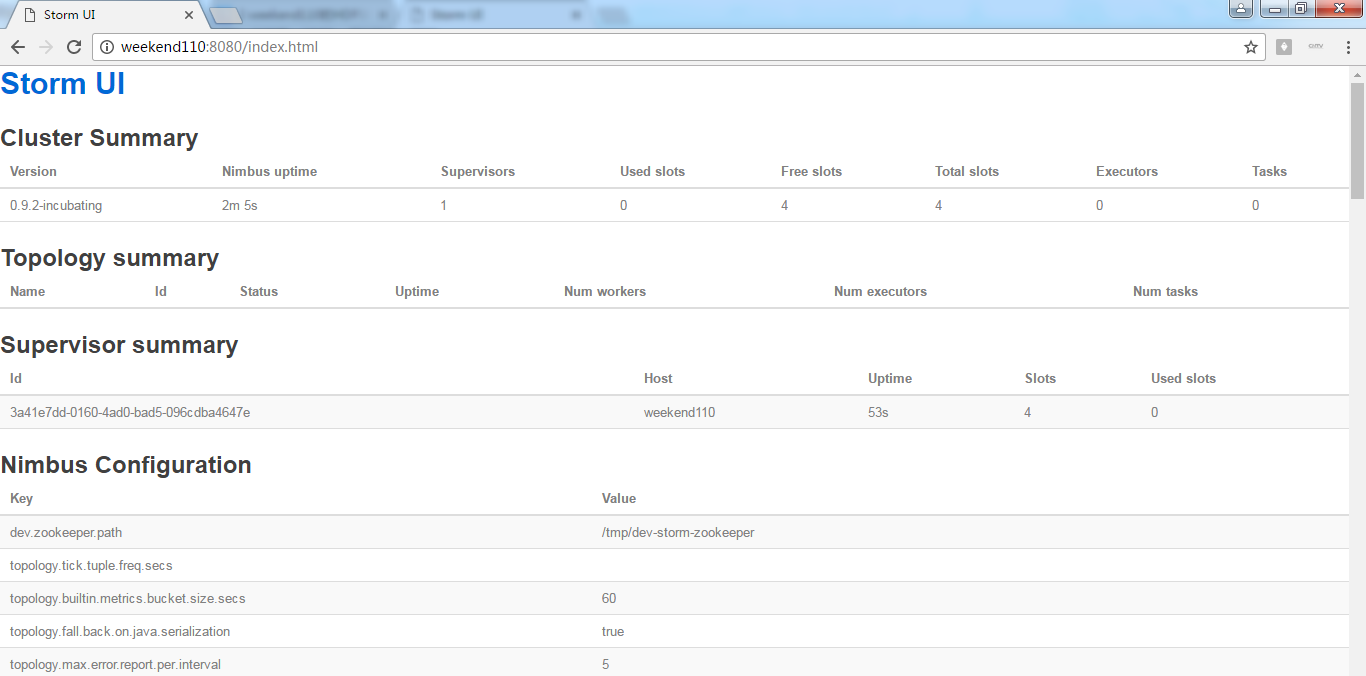
Storm UI
Cluster Summary
| Version | Nimbus uptime | Supervisors | Used slots | Free slots | Total slots | Executors | Tasks |
| 0.9.2-incubating | 10m 41s | 1 | 0 | 4 | 4 | 0 | 0 |
Topology summary
Supervisor summary
| Id | Host | Uptime | Slots | Used slots |
| 3a41e7dd-0160-4ad0-bad5-096cdba4647e | weekend110 | 9m 30s | 4 | 0 |
Nimbus Configuration
| Key | Value |
| dev.zookeeper.path | /tmp/dev-storm-zookeeper |
| topology.tick.tuple.freq.secs | |
| topology.builtin.metrics.bucket.size.secs | 60 |
| topology.fall.back.on.java.serialization | true |
| topology.max.error.report.per.interval | 5 |
| zmq.linger.millis | 5000 |
| topology.skip.missing.kryo.registrations | false |
| storm.messaging.netty.client_worker_threads | 1 |
| ui.childopts | -Xmx768m |
| storm.zookeeper.session.timeout | 20000 |
| nimbus.reassign | true |
| topology.trident.batch.emit.interval.millis | 500 |
| storm.messaging.netty.flush.check.interval.ms | 10 |
| nimbus.monitor.freq.secs | 10 |
| logviewer.childopts | -Xmx128m |
| java.library.path | /usr/local/lib:/opt/local/lib:/usr/lib |
| topology.executor.send.buffer.size | 1024 |
| storm.local.dir | /home/hadoop/data/apache-storm-0.9.2-incubating/tmp/storm |
| storm.messaging.netty.buffer_size | 5242880 |
| supervisor.worker.start.timeout.secs | 120 |
| topology.enable.message.timeouts | true |
| nimbus.cleanup.inbox.freq.secs | 600 |
| nimbus.inbox.jar.expiration.secs | 3600 |
| drpc.worker.threads | 64 |
| topology.worker.shared.thread.pool.size | 4 |
| nimbus.host | weekend110 |
| storm.messaging.netty.min_wait_ms | 100 |
| storm.zookeeper.port | 2181 |
| transactional.zookeeper.port | |
| topology.executor.receive.buffer.size | 1024 |
| transactional.zookeeper.servers | |
| storm.zookeeper.root | /storm |
| storm.zookeeper.retry.intervalceiling.millis | 30000 |
| supervisor.enable | true |
| storm.messaging.netty.server_worker_threads | 1 |
| storm.zookeeper.servers | weekend110 |
| transactional.zookeeper.root | /transactional |
| topology.acker.executors | |
| topology.transfer.buffer.size | 1024 |
| topology.worker.childopts | |
| drpc.queue.size | 128 |
| worker.childopts | -Xmx768m |
| supervisor.heartbeat.frequency.secs | 5 |
| topology.error.throttle.interval.secs | 10 |
| zmq.hwm | 0 |
| drpc.port | 3772 |
| supervisor.monitor.frequency.secs | 3 |
| drpc.childopts | -Xmx768m |
| topology.receiver.buffer.size | 8 |
| task.heartbeat.frequency.secs | 3 |
| topology.tasks | |
| storm.messaging.netty.max_retries | 30 |
| topology.spout.wait.strategy | backtype.storm.spout.SleepSpoutWaitStrategy |
| nimbus.thrift.max_buffer_size | 1048576 |
| topology.max.spout.pending | |
| storm.zookeeper.retry.interval | 1000 |
| topology.sleep.spout.wait.strategy.time.ms | 1 |
| nimbus.topology.validator | backtype.storm.nimbus.DefaultTopologyValidator |
| supervisor.slots.ports | 6700,6701,6702,6703 |
| topology.debug | false |
| nimbus.task.launch.secs | 120 |
| nimbus.supervisor.timeout.secs | 60 |
| topology.message.timeout.secs | 30 |
| task.refresh.poll.secs | 10 |
| topology.workers | 1 |
| supervisor.childopts | -Xmx256m |
| nimbus.thrift.port | 6627 |
| topology.stats.sample.rate | 0.05 |
| worker.heartbeat.frequency.secs | 1 |
| topology.tuple.serializer | backtype.storm.serialization.types.ListDelegateSerializer |
| topology.disruptor.wait.strategy | com.lmax.disruptor.BlockingWaitStrategy |
| topology.multilang.serializer | backtype.storm.multilang.JsonSerializer |
| nimbus.task.timeout.secs | 30 |
| storm.zookeeper.connection.timeout | 15000 |
| topology.kryo.factory | backtype.storm.serialization.DefaultKryoFactory |
| drpc.invocations.port | 3773 |
| logviewer.port | 8000 |
| zmq.threads | 1 |
| storm.zookeeper.retry.times | 5 |
| topology.worker.receiver.thread.count | 1 |
| storm.thrift.transport | backtype.storm.security.auth.SimpleTransportPlugin |
| topology.state.synchronization.timeout.secs | 60 |
| supervisor.worker.timeout.secs | 30 |
| nimbus.file.copy.expiration.secs | 600 |
| storm.messaging.transport | backtype.storm.messaging.netty.Context |
| logviewer.appender.name | A1 |
| storm.messaging.netty.max_wait_ms | 1000 |
| drpc.request.timeout.secs | 600 |
| storm.local.mode.zmq | false |
| ui.port | 8080 |
| nimbus.childopts | -Xmx1024m |
| storm.cluster.mode | distributed |
| topology.max.task.parallelism | |
| storm.messaging.netty.transfer.batch.size | 262144 |
这里呢,我因为,是方便入门和深入理解概念。所以,玩得是单机模式。
storm分布式模式
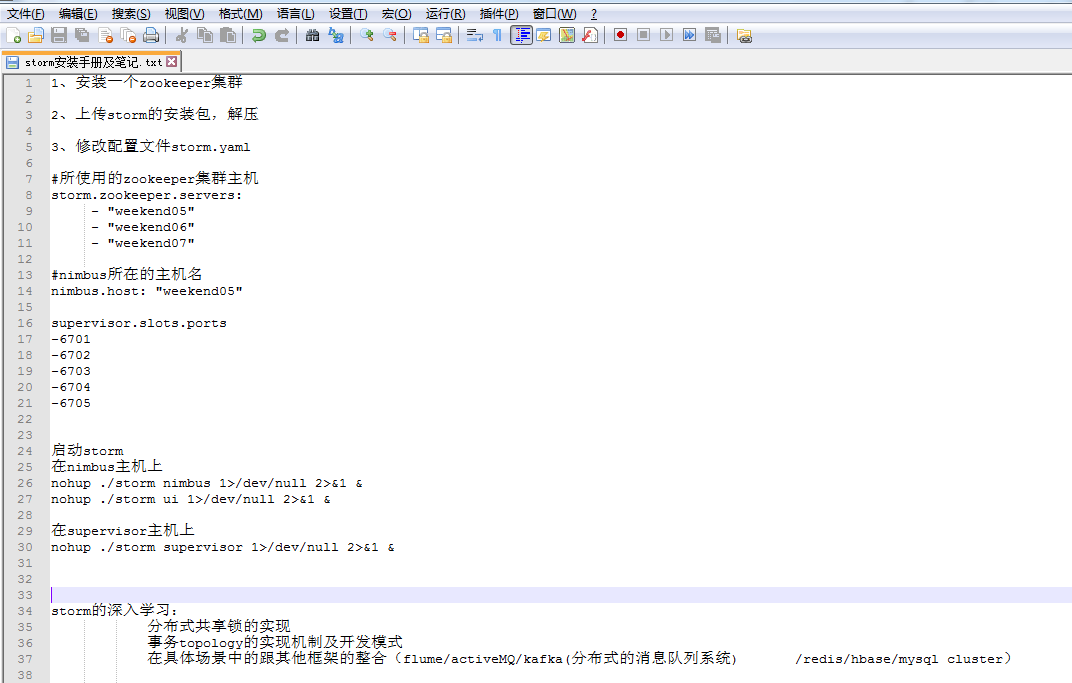
1、安装一个zookeeper集群
2、上传storm的安装包,解压
3、修改配置文件storm.yaml
#所使用的zookeeper集群主机
storm.zookeeper.servers:
- "weekend05"
- "weekend06"
- "weekend07"
#nimbus所在的主机名
nimbus.host: "weekend05"
supervisor.slots.ports
-6701
-6702
-6703
-6704
-6705
启动storm
在nimbus主机上
nohup ./storm nimbus 1>/dev/null 2>&1 &
nohup ./storm ui 1>/dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1>/dev/null 2>&1 &
storm的深入学习:
分布式共享锁的实现
事务topology的实现机制及开发模式
在具体场景中的跟其他框架的整合(flume/activeMQ/kafka(分布式的消息队列系统) /redis/hbase/mysql cluster)
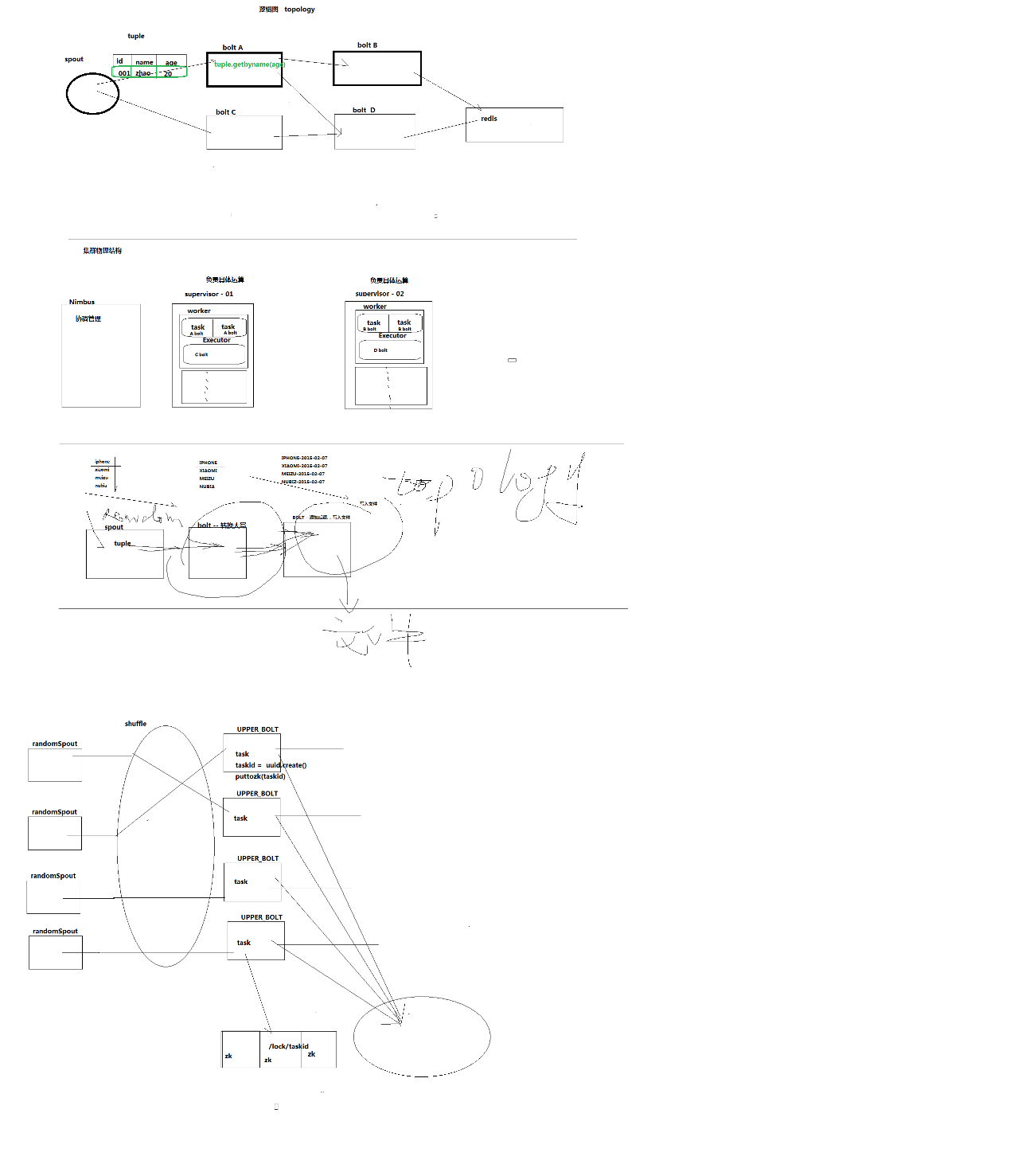
手机实时位置查询。
新建storm工程
这里,推荐用新建Maven工程,多好!
当然,为了照顾初学者,手工添加导入依赖包。
同时,各位来观看我本博客的博友们,其实,在生产是一定要是Maven的啊!何止能出书的人。
weekend110-storm -> Build Path -> Configure Build Path
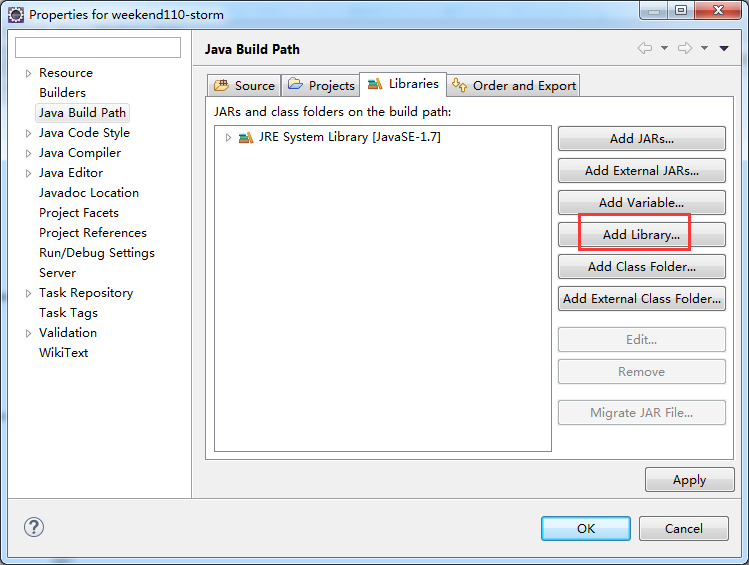

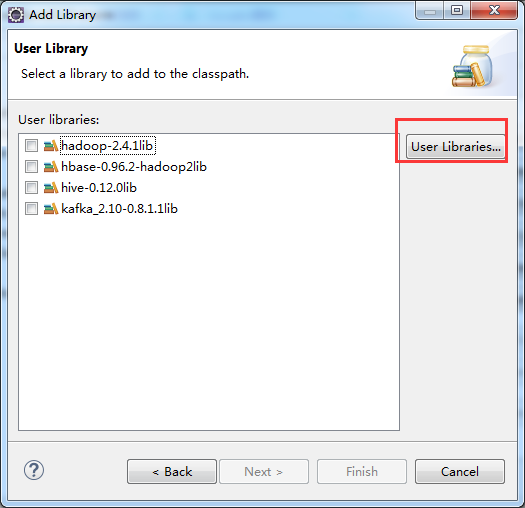

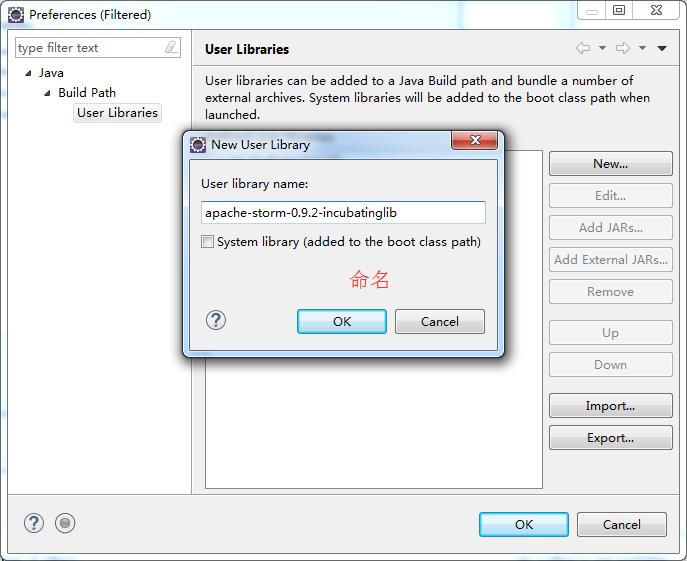
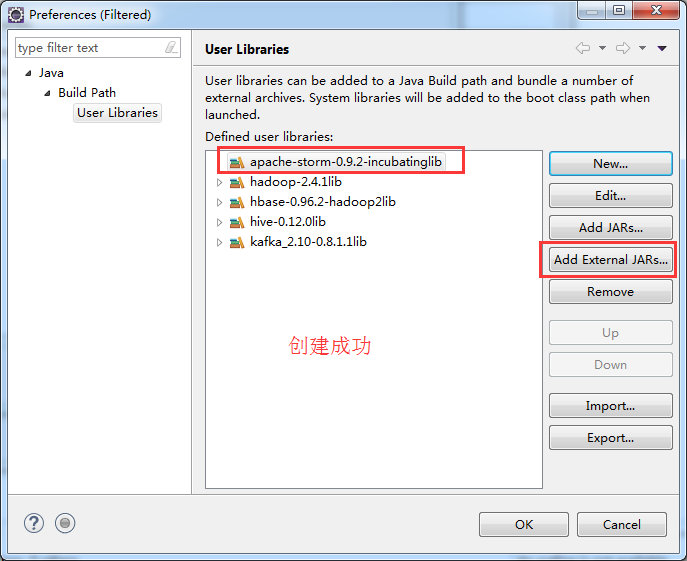

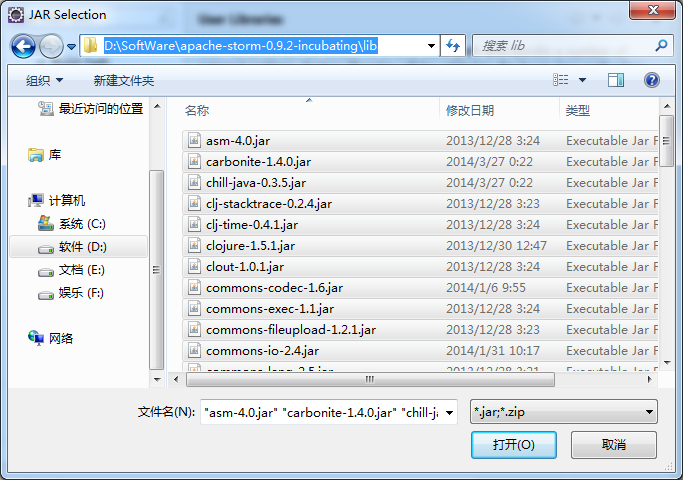
D:\SoftWare\apache-storm-0.9.2-incubating\lib

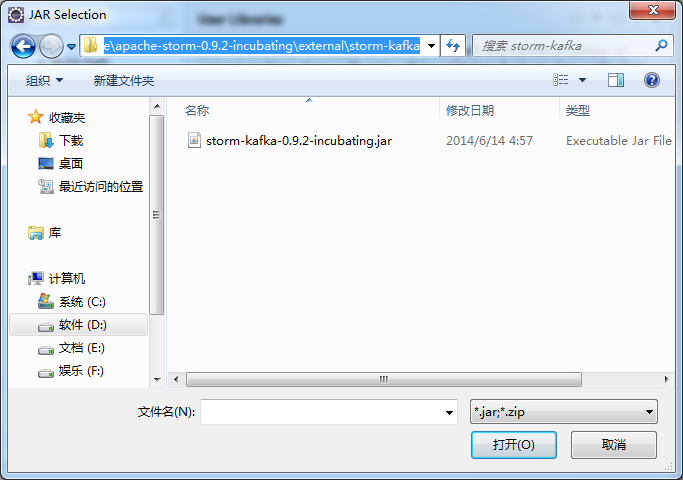
D:\SoftWare\apache-storm-0.9.2-incubating\external\storm-kafka
这个很重要,一般storm和kafka,做整合,是必须要借助用到这个jar包的。
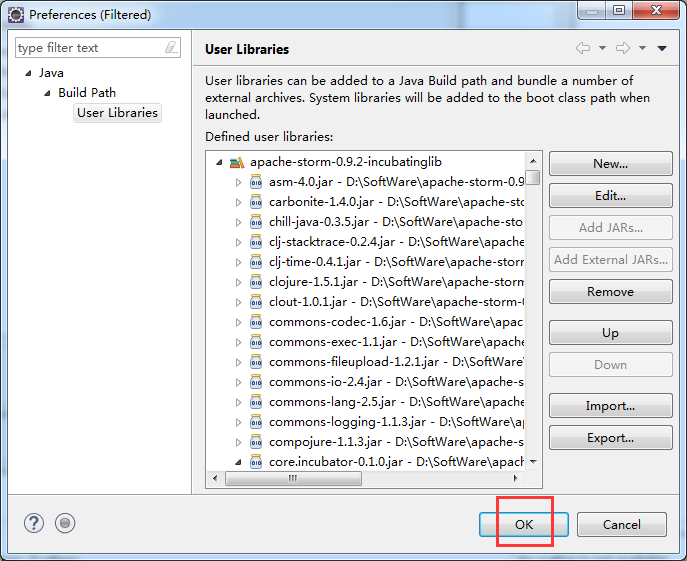

新建包cn.itcast.stormdemo
新建类RandomWordSpout.java

新建类UpperBolt.java
新建类 SuffixBolt.java
新建类 TopoMain.java
编写代码
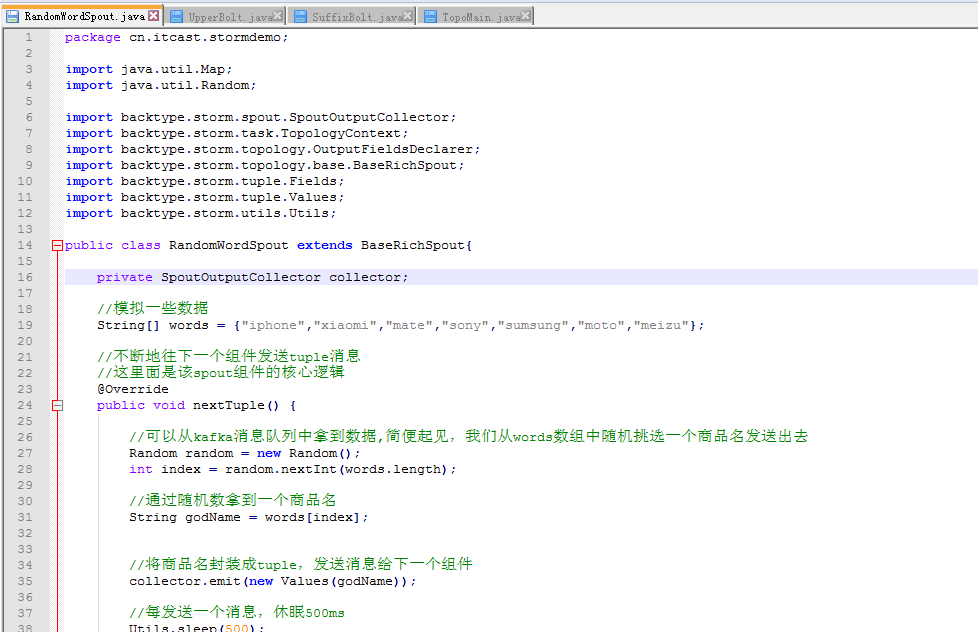


RandomWordSpout.java
package cn.itcast.stormdemo;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class RandomWordSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
//模拟一些数据
String[] words = {"iphone","xiaomi","mate","sony","sumsung","moto","meizu"};
//不断地往下一个组件发送tuple消息
//这里面是该spout组件的核心逻辑
@Override
public void nextTuple() {
//可以从kafka消息队列中拿到数据,简便起见,我们从words数组中随机挑选一个商品名发送出去
Random random = new Random();
int index = random.nextInt(words.length);
//通过随机数拿到一个商品名
String godName = words[index];
//将商品名封装成tuple,发送消息给下一个组件
collector.emit(new Values(godName));
//每发送一个消息,休眠500ms
Utils.sleep(500);
}
//初始化方法,在spout组件实例化时调用一次
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
//声明本spout组件发送出去的tuple中的数据的字段名
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("orignname"));
}
}
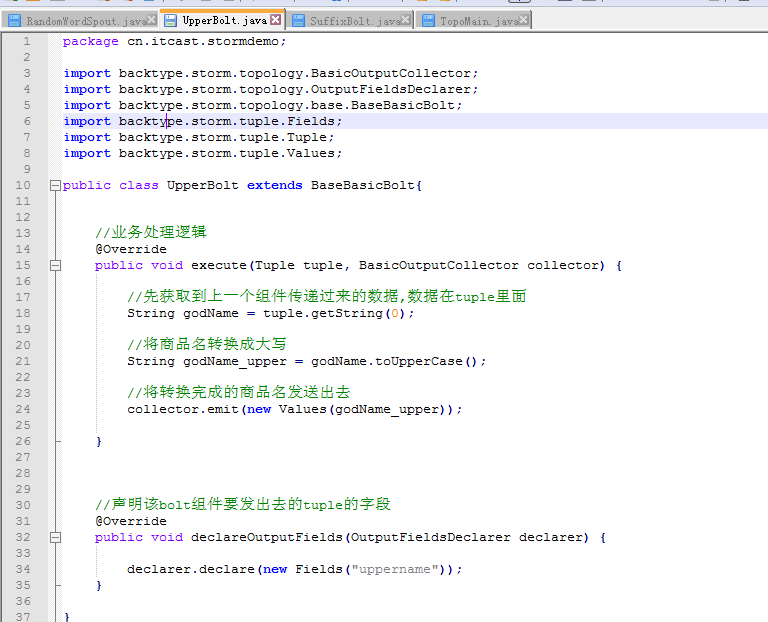
UpperBolt.java
package cn.itcast.stormdemo;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class UpperBolt extends BaseBasicBolt{
//业务处理逻辑
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先获取到上一个组件传递过来的数据,数据在tuple里面
String godName = tuple.getString(0);
//将商品名转换成大写
String godName_upper = godName.toUpperCase();
//将转换完成的商品名发送出去
collector.emit(new Values(godName_upper));
}
//声明该bolt组件要发出去的tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("uppername"));
}
}
SuffixBolt.java
package cn.itcast.stormdemo;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class SuffixBolt extends BaseBasicBolt{
FileWriter fileWriter = null;
//在bolt组件运行过程中只会被调用一次
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
fileWriter = new FileWriter("/home/hadoop/stormoutput/"+UUID.randomUUID());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//该bolt组件的核心处理逻辑
//每收到一个tuple消息,就会被调用一次
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先拿到上一个组件发送过来的商品名称
String upper_name = tuple.getString(0);
String suffix_name = upper_name + "_itisok";
//为上一个组件发送过来的商品名称添加后缀
try {
fileWriter.write(suffix_name);
fileWriter.write("\n");
fileWriter.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//本bolt已经不需要发送tuple消息到下一个组件,所以不需要再声明tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}
TopoMain.java
package cn.itcast.stormdemo;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
/**
* 组织各个处理组件形成一个完整的处理流程,就是所谓的topology(类似于mapreduce程序中的job)
* 并且将该topology提交给storm集群去运行,topology提交到集群后就将永无休止地运行,除非人为或者异常退出
*
*
*/
public class TopoMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
//将我们的spout组件设置到topology中去
//parallelism_hint :4 表示用4个excutor来执行这个组件
//setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task
builder.setSpout("randomspout", new RandomWordSpout(), 4).setNumTasks(8);
//将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息
//.shuffleGrouping("randomspout")包含两层含义:
//1、upperbolt组件接收的tuple消息一定来自于randomspout组件
//2、randomspout组件和upperbolt组件的大量并发task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping
builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout");
//将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt");
//用builder来创建一个topology
StormTopology demotop = builder.createTopology();
//配置一些topology在集群中运行时的参数
Config conf = new Config();
//这里设置的是整个demotop所占用的槽位数,也就是worker的数量
conf.setNumWorkers(4);
conf.setDebug(true);
conf.setNumAckers(0);
//将这个topology提交给storm集群运行
StormSubmitter.submitTopology("demotopo", conf, demotop);
}
}
补充:
在eclipse中运行storm-starter
http://www.cnblogs.com/vincent-vg/p/5850852.html
