Pytorch分布式训练/多卡训练(三) —— Model Parallel 并行
Model Parallel
数据并行是指,多张 GPUs 使用相同的模型副本,但采用不同 batch 的数据进行训练.
模型并行是指,多张 GPUs 使用同一 batch 的数据,分别训练模型的不同部分.
Part of the model on CPU and part on the GPU
class DistributedModel(nn.Module): def __init__(self): super().__init__( embedding=nn.Embedding(1000, 10), rnn=nn.Linear(10, 10).to(device), ) def forward(self, x): # Compute embedding on CPU x = self.embedding(x) # Transfer to GPU x = x.to(device) # Compute RNN on GPU x = self.rnn(x) return xBasic Usage
首先从包含两个线性层的toy model开始。 要在两个GPU上运行此模型,只需将每个线性层放在不同的GPU上,然后移动输入和中间输出以匹配设备。
import torch import torch.nn as nn import torch.optim as optim class ToyModel(nn.Module): def __init__(self): super(ToyModel, self).__init__() self.net1 = torch.nn.Linear(10, 10).to('cuda:0') self.relu = torch.nn.ReLU() self.net2 = torch.nn.Linear(10, 5).to('cuda:1') def forward(self, x): x = self.relu(self.net1(x.to('cuda:0'))) return self.net2(x.to('cuda:1')) model = ToyModel() loss_fn = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.001) optimizer.zero_grad() outputs = model(torch.randn(20, 10)) labels = torch.randn(20, 5).to('cuda:1') loss_fn(outputs, labels).backward() optimizer.step()除了5个 to(device) 调用将线性层和张量放置在适当的设备上之外,上面的ToyModel看起来非常类似于在单个GPU上实现它的方式。 to(device)是模型中唯一需要更改的地方。多GPU训练时 backward() 和torch.optim将自动处理梯度,就和模型在一个GPU上一样。 只需要注意在调用损失函数时,确保label与output位于同一设备上。
另一个例子
from torchvision.models.resnet import ResNet, Bottleneck num_classes = 1000 class ModelParallelResNet50(ResNet): def __init__(self, *args, **kwargs): super(ModelParallelResNet50, self).__init__( Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs) self.seq1 = nn.Sequential( self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2 ).to('cuda:0') self.seq2 = nn.Sequential( self.layer3, self.layer4, self.avgpool, ).to('cuda:1') self.fc.to('cuda:1') def forward(self, x): x = self.seq2(self.seq1(x).to('cuda:1')) return self.fc(x.view(x.size(0), -1))这就显示了如何将torchvision.models.resnet50()分解为两个GPU。 这个想法是继承现有的ResNet模块,并在构建过程中将层拆分为两个GPU。 然后,通过相应地移动中间输出,覆盖前向方法来连接两个子模块。
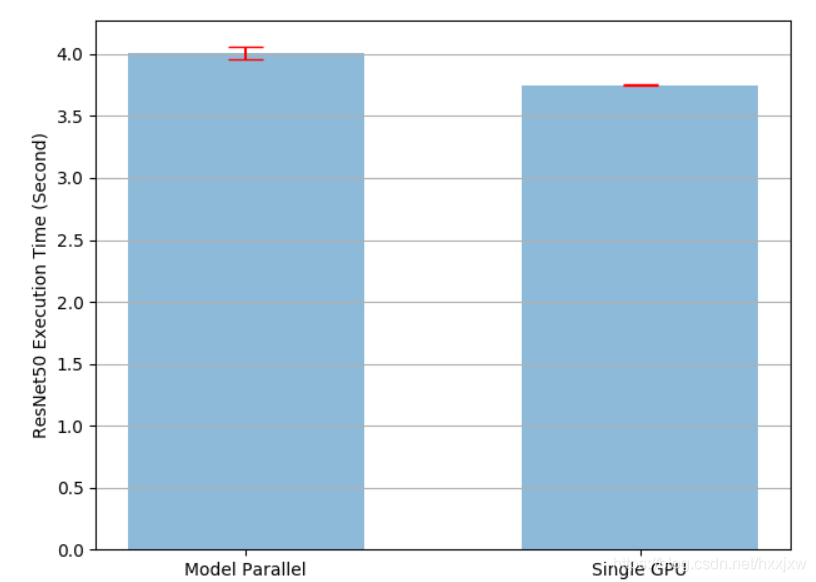
对于模型太大而无法放入单个GPU的情况,上述实现解决了该问题。 但是要注意到,它将比在单个GPU上运行要慢。 这是因为在任何时间点,两个GPU中只有一个在工作,而另一个在那儿什么也没做。 由于中间输出需要在第2层和第3层之间从cuda:0复制到cuda:1,因此性能进一步下降
我们可以对此改进,因为我们知道两个GPU之一在整个执行过程中都处于闲置状态。 一种选择是将每个批次进一步划分为拆分流水线,以便当一个拆分到达第二个卡时,可以将下一个拆分馈入第一张卡。 这样,两个连续的拆分可以在两个GPU上同时运行。
Speed Up by Pipelining Inputs
Single-Machine Model Parallel Best Practices — PyTorch Tutorials 1.11.0+cu102 documentation