viterbi算法_Lyft推出一种新的实时地图匹配算法
打车有时也会职业病发作,琢磨一下车辆调度是怎么做的,路径规划算法要怎么写,GPS偏移该怎么纠正等等。不过就是想想而已,并没有深究。这篇是Lyft(美帝第二大打车平台)工程师分享的最近上线的地图匹配算法,非常有参考价值。
作者:Marie Douriez
编译:McGL
公众号:PyVision(欢迎关注,专注CV,偶尔CS)
A New Real-Time Map-Matching Algorithm at Lyft
https://eng.lyft.com/a-new-real-time-map-matching-algorithm-at-lyft-da593ab7b006
当你要求打车时,Lyft 会试着找一个最适合你路线的司机。要做出调度决定,我们首先需要问: 司机在哪里?Lyft 使用司机手机的 GPS 数据来回答这个问题。然而,我们得到的 GPS 数据往往是有噪音的,和道路并不匹配。
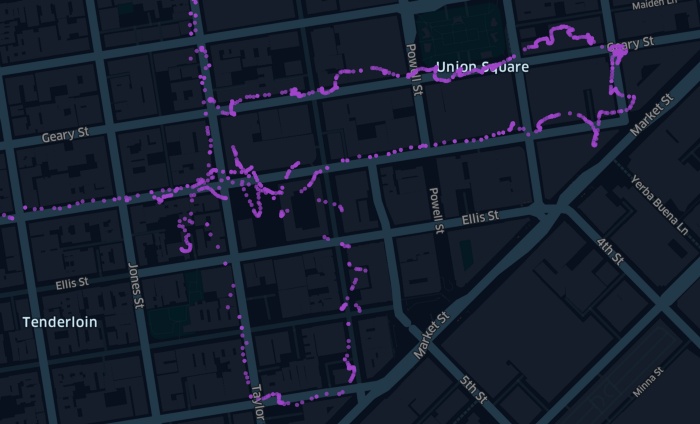
为了从这些原始数据中得到一个更清晰的图像,我们运行一个算法,输入原始位置并返回道路网中更准确的位置。这个过程称为地图匹配(map-matching)。我们最近开发并发布了一个全新的地图匹配算法,发现它提高了驾驶员定位的准确性,并使 Lyft 的市场更有效率。在这篇文章中,我们将讨论这个新模型的细节。
什么是地图匹配?
地图匹配是这样一个过程,匹配原始GPS的位置到道路网路段,以产生一个车辆路线的估计。
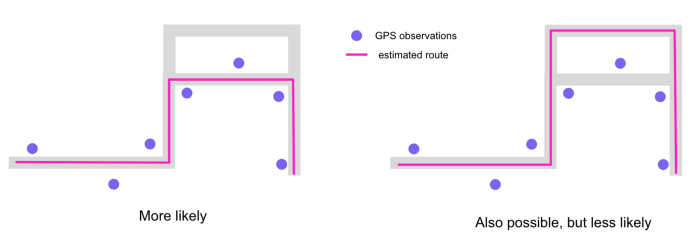
我们为什么需要地图匹配?
在 Lyft,我们有两个主要的地图匹配用例:
- 在行程结束时,计算司机所行驶的路程以计算车费。
- 为 ETA 团队实时地提供准确的位置,做出调度决定,并在乘客的app上显示司机的车。
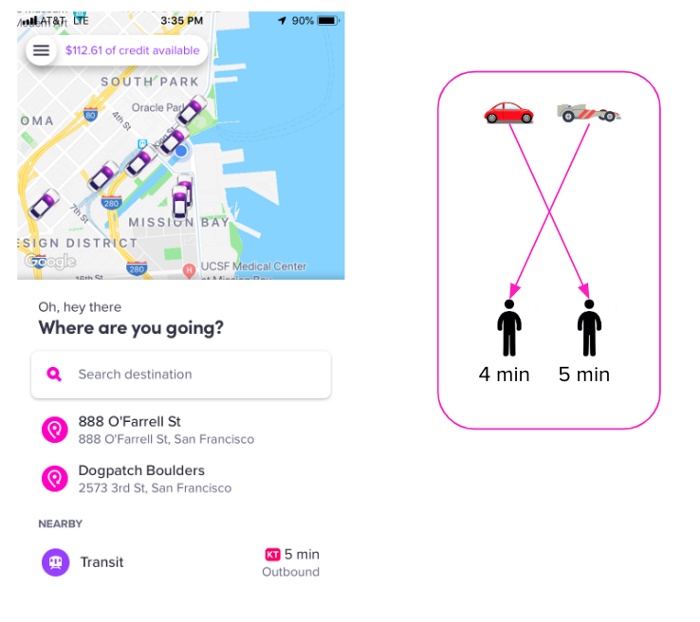
这两个用例的不同之处在于它们的约束: 实时的情况,我们需要快速地执行地图匹配(低延迟) ,并且当前时间及之前的位置已知。然而,在行程结束时,延迟要求没有那么严格,整个行程的历史对我们来说是可用的(允许我们从未来的位置“向后”执行)。结果表明,使用略有不同的方法可以解决行车终点地图匹配(EORMM)和实时地图匹配(RTMM)问题。在这篇文章中,我们将关注用于实时地图匹配的算法。
为什么地图匹配有挑战性?
差的地图匹配位置会导致不准确的预计到达时间(ETAs),然后导致错误的调度决策并令司机和乘客失望。因此,地图匹配直接影响 Lyft 的市场,并对用户体验产生重要影响。地图匹配有几个主要挑战。
首先,在城市峡谷(街道被高楼包围)、层叠的道路或隧道下面,通过手机收集的位置数据会变噪音很大。这些区域对于地图匹配算法来说尤其具有挑战性,而且由于很多 Lyft 搭乘都发生在那里,正确匹配就显得尤为重要。
除了噪音和道路几何形状,另一个挑战是缺乏ground truth: 我们实际上不知道司机开车时的真实位置,我们必须找到代理来评估模型的准确性。
最后,地图匹配算法的性能依赖于道路网数据的质量。这个问题正在由 Lyft 内部的 Mapping 团队解决。
那么,我们如何解决地图匹配问题呢?
我们不会介绍解决地图匹配的所有技术,但是为了回顾一下常见的方法,请参考 Quddus 等人的这项研究[1]。
解决这个问题的一个好方法是使用状态空间模型(state space models)。状态空间模型是时间序列模型,其中系统具有“隐藏”状态,不能直接观测到,但能产生可见的观察结果。这里,我们的隐藏状态是我们试图估计的汽车在道路网络上的实际位置。我们只观察隐藏状态的一个修改版本: 观察值(原始位置数据)。我们假设系统的状态以一种只依赖于当前状态的方式进化(马尔可夫假设) ,并进一步定义了一个隐状态到隐状态的转移密度和一个隐状态到观察的密度。
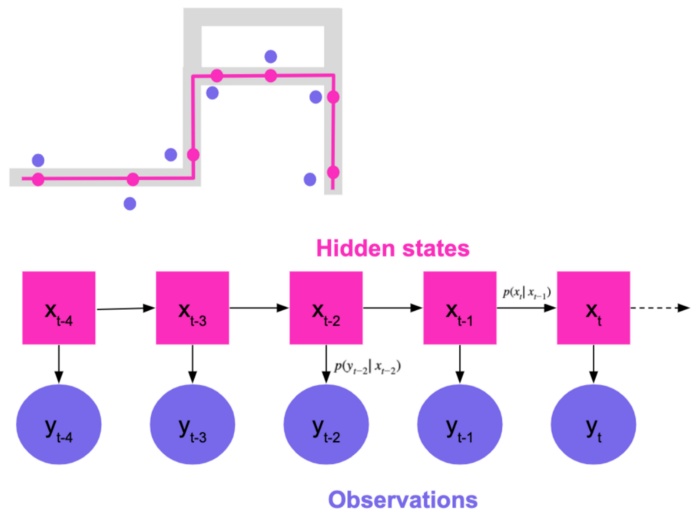
用于地图匹配的一个常用的状态空间模型是离散状态隐马尔可夫模型(Newson & Krumm [2], DiDi’s IJCAI-19 Tutorial [3], Map Matching @ Uber [4])。在这个系统中,我们通过查找路段上最接近的点来生成候选点,然后使用 Viterbi 算法来找出最可能的隐藏状态序列。
然而,隐马尔可夫模型(Hidden Markov Model / HMM)有几个局限性:
- 对于不同的建模选择和输入数据,它相对不够灵活
- 它的扩展很差 (O(N²), 其中 N 是每个状态可能的候选)
- 它不能很好的处理高频观察(见 Newson & Krumm [2])
基于这些原因,我们开发了一种新的实时地图匹配算法,该算法更加精确和灵活,可以融合额外的传感器数据。
一种基于(无迹)卡尔曼滤波器的新模型
卡尔曼滤波器(Kalman filter)基础
让我们首先回顾一下卡尔曼滤波器的基础知识。
与离散状态 HMM 不同,卡尔曼滤波器允许隐状态是连续分布的。卡尔曼滤波器的核心是一个简单的线性高斯模型,使用以下方程对系统进行建模:

利用这些方程,卡尔曼滤波器通过一个封闭的预测校正步骤(predict-correct step)迭代更新系统的状态表示,从 t-1步后验到 t 步后验。
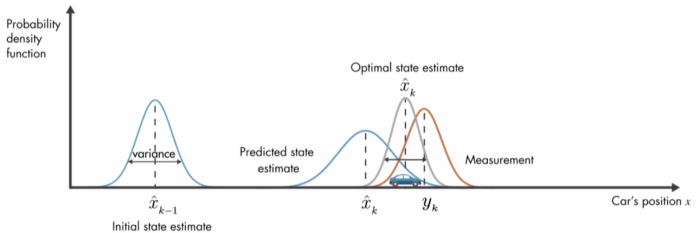
然而,卡尔曼滤波器的一个局限性是它只能处理线性问题。为了处理非线性问题,卡尔曼滤波器被推广应用,如扩展卡尔曼滤波器(EKF)和无迹卡尔曼滤波器(UKF)[5]。正如我们将在下一节中看到的,我们的新 RTMM 算法使用了 UKF 技术。对于本文剩下的部分,卡尔曼滤波器和 UKF 之间的技术差异并不重要: 我们可以简单地假设 UKF 就像标准的线性卡尔曼滤波器一样工作。
边缘化粒子滤波器(Marginalized Particle Filter)
现在让我们描述一下我们的新 RTMM 算法是如何工作的。我们把它称为边缘化粒子滤波器(MPF)。
在高层上看,我们的 MPF 算法跟踪多个“粒子” ,每个粒子代表道路网络中一个轨迹上的一个位置,并根据每个轨迹运行一个无迹卡尔曼滤波器。为了更准确的说明,让我们定义以下对象:
一个MPF 状态是粒子列表。
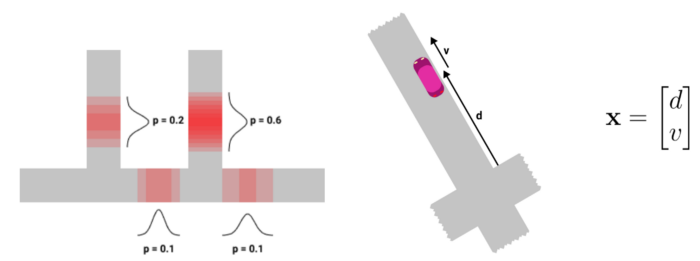
一个粒子代表汽车在地图上一个可能的道路位置,并伴随一定的概率。每个粒子有4个属性:
- 概率 p ∈[0,1]
- 轨迹(即地图交叉点的列表)
- 平均矢量 x = [ d v ]’ ,其中 d 是汽车在轨道上的位置(单位米) ,v 是汽车的速度(单位米/秒)
- 一个2x2的协方差矩阵 P 表示围绕汽车的位置和速度的不确定性
我们每次从司机的手机收到新的观察数据时,都会更新MPF状态,方法如下:

如果前一个 MPF 状态没有粒子(例如,如果司机刚刚登录到app) ,我们需要初始化一个新粒子。初始化步骤只是“捕捉”GPS 观察值到地图上,并返回最近的道路位置。每个粒子的概率是其到观察值的距离的函数。
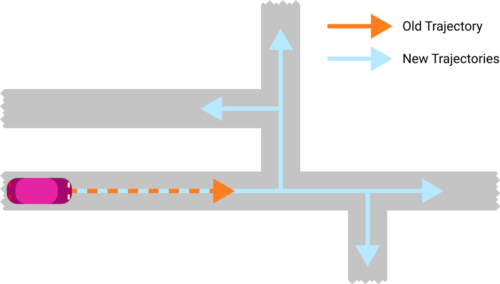
在下一次更新(新观察)中,我们迭代我们的状态(非空)粒子列表,并为每个粒子执行两个步骤。首先,轨迹延伸(trajectory extension)步骤从粒子在道路网中的当前位置寻找所有可能的轨迹。其次,我们循环遍历这些新的轨迹,在每一个轨迹上,我们运行 UKF 并更新新创建的粒子的概率。在这两个嵌套循环之后,我们得到了一个新的粒子列表。为了避免在MPF状态中跟踪太多粒子,我们简单地丢弃那些最不可能的(修剪)。
然后,下游的团队可以决定使用来自 MPF 状态的最可能的粒子作为地图匹配的位置,或者可以直接利用我们的概率输出(例如创建可能的 ETAs 分布)。
回顾一下,边缘化粒子滤波器维护了一组代表汽车在轨迹上可能位置的粒子,并使用卡尔曼滤波算法对每个粒子进行更新。新算法不仅提供了定位,而且还提供了速度估计和不确定性。在实践中,我们观察到,它比 HMM 产生的地图匹配位置更精确,特别是在市中心地区和路口附近(这些地方的错误会导致非常不准确的 ETAs)。
总结
在试验了这种新的实时地图匹配算法之后,我们发现在 Lyft 的市场上有了积极的效果。新的模型减少了 ETA 误差,这意味着我们可以更准确地匹配乘客和最适合的司机。这也减少了乘客取消订单,表明这增加了乘客对他们的司机会准时到达接送的信心。
然而,我们还在进化: 在未来的几个月里,我们计划通过很多种方式来改进这个模型。我们将整合其他手机传感器的数据,比如陀螺仪,它可以让我们检测到驾驶员何时转弯。我们还计划考虑司机的目的地(如果他们有目的地的话,例如在去接人的路上)作为一个优先事项。事实上,边缘化粒子滤波器的另一个优势是它允许我们以一种有原则的方式轻松地将这些新类型的信息添加到模型中,并且它是一个良好的基础,我们可以在此基础上继续为乘客和司机提供更加无缝的 Lyft 体验。
References
[1] Quddus M., Ochieng W. & Noland R., “Current map-matching algorithms for transport applications: State-of-the art and future research directions,” Transportation Research Part C: Emerging Technologies, 15(5), 312–328, 2007.
[2] Newson P. & Krumm J., “Hidden Markov map matching through noise and sparseness,” Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems GIS 09, 336, 2009
[3] DiDi’s IJCAI-19 Tutorial: Artificial Intelligence in Transportation (slides 28–40)
[4] Map Matching @ Uber
[5] E. A. Wan and R. Van Der Merwe, “The unscented Kalman filter for nonlinear estimation,” Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. №00EX373), Lake Louise, Alberta, Canada, 2000, pp. 153–158.