dataframe 筛选_python—变量筛选
撰文 Yotsunoha
编辑 袁老师
这里我们使用logit回归和OLS(最小二乘回归)回归展示一下python的变量筛选过程。
from scipy import statsfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmfrom statsmodels.stats.multicomp import pairwise_tukeyhsdimport warningswarnings.filterwarnings("ignore")import itertoolsdata = pd.read_csv("完整数据.csv")读取数据,加载所需要的包。
columns = ['age', 'bicarbonate_max','rdw_max', 'phosphate_max', 'alf', 'af','stroke', 'map_mean', 'aki', 'calcium_max', 'sodium_max','phosphate_max','ck_max']column_P_2 = [] # 保存p值小于0.2的变量for column in columns: sts, p_val = stats.ttest_ind(data.loc[(data.hosp_mortality == 1), column].values , data.loc[(data.hosp_mortality == 0), column].values) if p_val < 0.2: column_P_2.append(column)print(column_P_2)这里是选取了p值小于0.2的变量进行下一步分析。多元回归分析中的变量筛选标准的争论从未停止。临床医生和统计学家之间对于变量的筛选标准各有建议。下面这篇文章中对于这个问题讲述的非常清晰,建议围观。
https://cloud.tencent.com/developer/article/1628699
一、logit回归
# Logit回归import statsmodels.api as smimport pylab as pldf = data[(data['hosp_mortality'] == 0) | (data['hosp_mortality'] == 1)]label_df = df['hosp_mortality']train_df = df[column_P_2]logit = sm.Logit(label_df, train_df)result = logit.fit()result.summary()结果展示
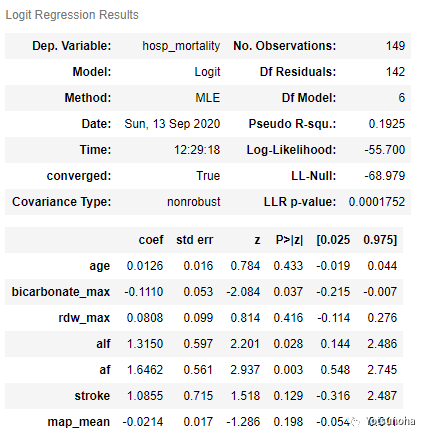
计算OR值及可信区间
import numpy as npnp.set_printoptions(suppress=True)params = result.paramsconf = result.conf_int()conf['OR'] = paramsconf.columns = ['2.5%', '97.5%', 'OR']np.exp(conf)结果保存
dt = pd.DataFrame(np.exp(conf))dt.to_csv("conf-mortality.csv")二、OLS回归
# OLS回归temp = 'hosp_mortality~'for col in column_P_2:# if col in categorical:# temp += 'C(' + col + ')' + '+'# else: temp += col + '+'# print(temp[:-1])model = ols(temp[:-1] ,data=pd.concat([data[column_P_2], data['hosp_mortality']], axis=1)).fit()model.summary()结果展示
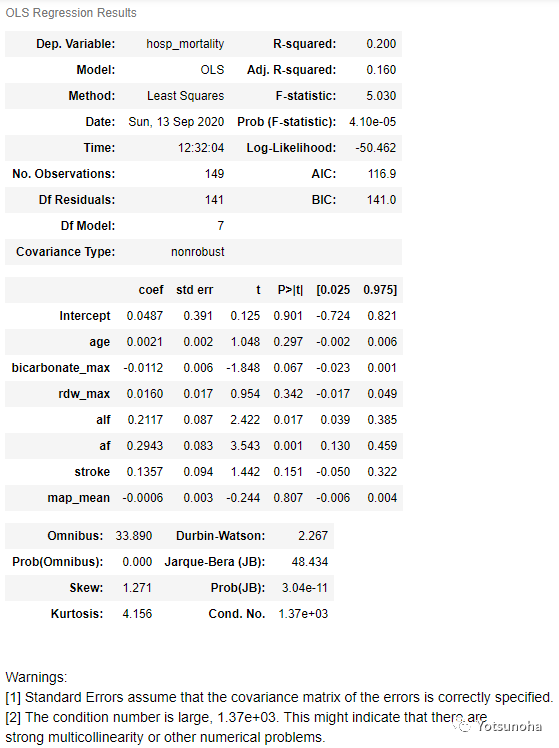
这里只是展示了一下计算过程,具体该根据什么标准纳入什么变量需要结合数据实际和临床实践。
既往文章
Python的下载与安装
python数据可视化-相互关系及分布
python数据可视化-小提琴图
临床研究中Table 1的五步生成法
Python在医学领域中的应用
MIMIC-IV数据库
预印本来袭,投还是不投?
重症数据库知多少?除了MIMIC和eICU,AMDS和HiRID你知道吗