redis模糊查询key前缀_Redis内存数据监控实战
众所周知Redis是基于内存的数据库,其所有的数据都在内存中,而内存又是属于成本较高且容量有上限的硬件资源,因此需要时刻关注Redis内存的情况。特别是在生产环境,Redis内存占用过高会带来很多风险,甚至是灾难性的后果:
庞大的数据导致持久化时间冗长,期间大量消耗主机资源,服务器压力陡升
Redis启动过程变慢,主从全量同步耗时增加,需要较长时间才能达到可用状态
一旦达到Redis内存上限,轻则无法写入数据,重则直接宕机,且宕机后无法立即恢复,除非丢弃所有数据。
为了避免这种情况的发生,需要增加Redis内存数据分布的监控,如果发现内存异常持续升高,可以通过监控来排查是谁占用了内存并及时处理。特来电云平台为此做了两种监控方案:
内存数据分布准实时监控
数据写入流量实时监控
一、内存数据分布准实时监控
Redis为了避免进程退出导致内存数据的永久丢失,可以定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。Redis持久化分为RDB持久化和AOF持久化:
RDB(Redis DataBase)持久化:将当前内存中的Redis完整数据保存到硬盘
AOF(AppendOnly File)持久化:将写操作命令追加的保存到硬盘
数据分析可以选择使用RDB持久化生成的数据镜像文件。由于特来电云平台采用多数据中心多服务单元的部署架构,每个数据中心的服务单元都有一个或多个Redis集群,因此需要将各个集群的Redis数据镜像文件进行归集,然后进行统一分析,并将分析结果上报至特来电监控预警平台。这种做法还有一个好处是可以把归集的镜像文件当作数据备份,以备不时之需。
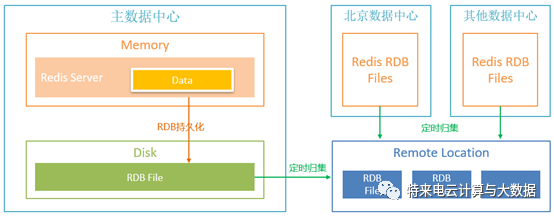
分析工具选择使用redis-rdb-tools + sqlite + 自研工具。redis-rdb-tools是一款开源的以python语言开发的解析redis的rdb文件的工具,它可以生成内存报告、转储文件到JSON以及对两个rdb文件进行比较。这里主要用它生成csv格式的内存报告,执行命令:
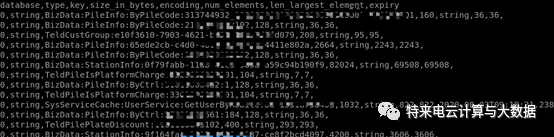
/redis-rdb-tools-rdbtools-0.1.14/build/lib/rdbtools/cli/rdb.py-c memory /redis/rdb/dump-main1.rdb > /redis/rdb/report-main1.csv生成的报告内容如下:
其中:
Database :key所在的数据库编号 Type :key的数据结构 key :key的名称 size_in_bytes :value的大小 encoding :底层存储的编码类型 num_elements :包含的元素数量,例如string里有多少字符、hash里面有多少项、set里面有多少元素 len_largest_element :包含的所有元素中的最大长度 expiry :key的过期时间接下来可以对这份报告进行统计,由于csv文件不方便进行各类统计查询,可以将其导入数据库。这里选择最轻量级的sqlite:
sqlite3/redis/sqlite/main1-memory.dbcreatetable memory(database int,type varchar(128),key varchar(128),size_in_bytesint,encoding varchar(128),num_elements int,len_largest_elementvarchar(128),expiry varchar(128));.modecsv memory.import/redis/rdb/report-main1.csv memory之后就可以进行下一步操作:统计数据并上报监控预警平台。在开发设计阶段对redis的key命名时,都会增加一个业务缩写前缀,例如:User:xxxxxx、Bill:xxxx,这样可以方便进行统计查询,能够快速得知每一块业务的key的数量和大小。因为所有的操作均在linux上,所以需要开发一个.netcore的统计上报工具部署在服务器上,进行统计和上报每一块业务的数据量。工具核心统计代码如下:
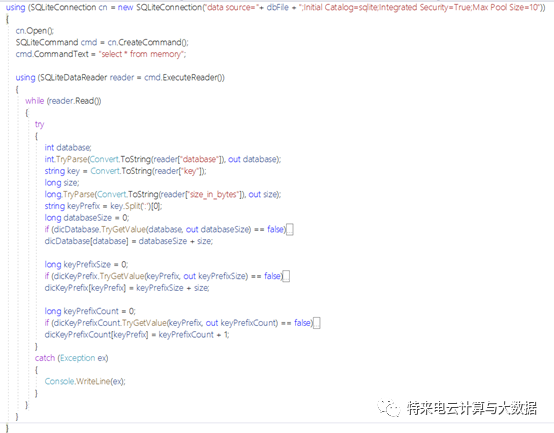
在服务器上执行一下该工具,便能够完成一次统计和上报了。可以把整个过程做成一个脚本,用定时任务每隔1小时跑一次,就基本实现了准实时的内存数据分布的监控,效果图如下:

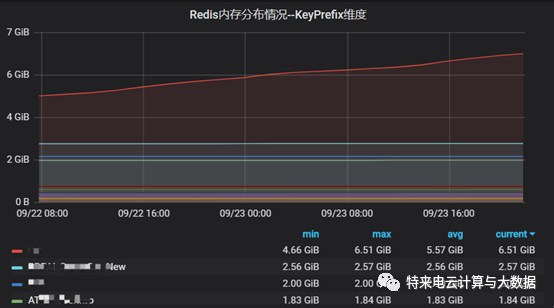
由图可见,一旦出现某块业务的数据持续上涨的情况,可以很快发现并及时处理。
二、数据写入流量实时监控
内存数据分布准实时监控可以做到小时级的数据监控,可以分析监控较慢增长的数据,但无法及时监控导短时间内数据量突增的情况。针对这种情况,采用服务端实时网络抓包、分析报文、统计上报的方案来实现数据写入流量实时监控。
网络抓包工具有很多,这里采用最常用wireshark。wireshark不仅可以快速抓包,还拥有强大的过滤器引擎,可以使用过滤器筛选出redis的数据包,排除无关信息的干扰。在redis服务器上执行以下命令:
/usr/sbin/tshark-i eth0 -n -f 'tcp port 6379' -a duration:10 -t ad -lT fields -Eseparator="," -E quote=n -e ip.src -e tcp.srcport -e ip.dst -etcp.dstport -e data.data -e data.len > /rdis-networkflow-reporter/data.txt此命令是抓取Redis服务的6379端口的报文,持续10秒,将报文中过滤出来源ip、来源端口、目标ip、目标端口、数据内容、报文长度等字段,并输出至一个文本文件。为什么只抓取10s?因为wireshark在抓取包并导出文本文件的过程会显著提高cpu,特别是在流量很高的情况,会对服务器性能产生影响。因此,可以根据服务器的实际情况进行持续时间的调整。需要注意的是,数据内容被转换成了十六进制,后面做统计的时候需要转换成字符串。
接下来对报文数据内容的解析,解析之前先要简单了解一下Redis的通信协议。Redis客户端使用RESP(Redis的序列化协议)协议与Redis的服务器端进行通信,在RESP协议中,数据类型取决于第一个字节:
对于简单字符串,第一个字节是“+”
对于错误,第一个字节是“ - ”
对于整数,第一个字节是“:”
对于批量字符串,第一个字节是“$”
对于数组,第一个字节是“*”
协议的不同部分始终以“ ”(CRLF)结尾
因为主要提取报文中的写入命令,而写入命令通常都是至少包含三部分:命令、key、value。对于协议来讲,这属于一个数组,因此会以*开头,后面跟着一个十进制的数字,该数字是数组中元素的个数。例如:字符串写入指令set hey helloworld,报文的前缀则是*3。接下来的命令本身作为一个字符串,报文则以“$”字节开始,后面是组成字符串的字节数(前缀长度),然后是命令本身。所以set对应的报文就是$3 set。同理hey helloworld也是字符串,因此,整个命令的报文便是*3 $3 set $3 hey $10 helloworld 。
下一步需要整理出哪些命令是要关注的,因为并不是所有的写入操作都值得去统计,比如DEL、INCR等操作就不会增加内存。这里在统计工具中进行了判断:

最后,在统计工具中对整个文本文件进行逐行解析,统计写入操作的来源ip、来源端口、key的前缀以及写入数据的大小,并上报至监控预警平台。把整个过程做成脚本,配上定时任务,即可实现数据写入流量实时监控,效果图如下:
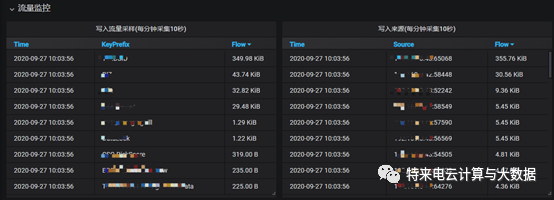
一旦出现写入流量突增,既可以立即定位到key的前缀,方便清理数据,还可以根据来源ip和端口定位到具体的应用进程,从根源上阻止异常流量。
三、总结
实时监控Redis流量的方式有很多,特来电在大规模使用的过程中也尝试了很多,例如引入第三方厂商的专业监控工具、引入专业的网卡层面的流量监控工具等。但无论从部署复杂度、维护成本以及投入资源成本来看,目前使用的这两套方案是最符合当下的实际情况并较好的解决了痛点问题的。后续随着云平台的不断发展,也将根据实际需求继续探索新的监控方案。逐步实现Redis内存监控的实时监控和自动化运维处理,让Redis的运维更智能、更简单。