一、第一部分
1、spark2.1与hadoop2.7.3集成,spark on yarn模式下,需要对hadoop的配置文件yarn-site.xml增加内容,如下:

<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2、spark的conf/spark-defaults.conf配置
spark.yarn.historyServer.address=node2:18080 spark.history.ui.port=18080 spark.eventLog.enabled=true spark.eventLog.dir=hdfs:///tmp/spark/events spark.history.fs.logDirectory=hdfs:///tmp/spark/events
如果你是运行在yarn之上的话,就要告诉yarn,你spark的地址,当我在yarn上点击一个任务,进去看history的时候,他会链接到18080里面,如果你配的是node1:18080,那么你就要在node1上启动spark的history server(见后面注①)
最下面两个配置是运行spark程序的时候配置的,一旦你运行spark,就会将日志等发送到那两个目录,有了这两个目录,spark的historyserver就可以读取spark的运行状态信息日志等读取并展示
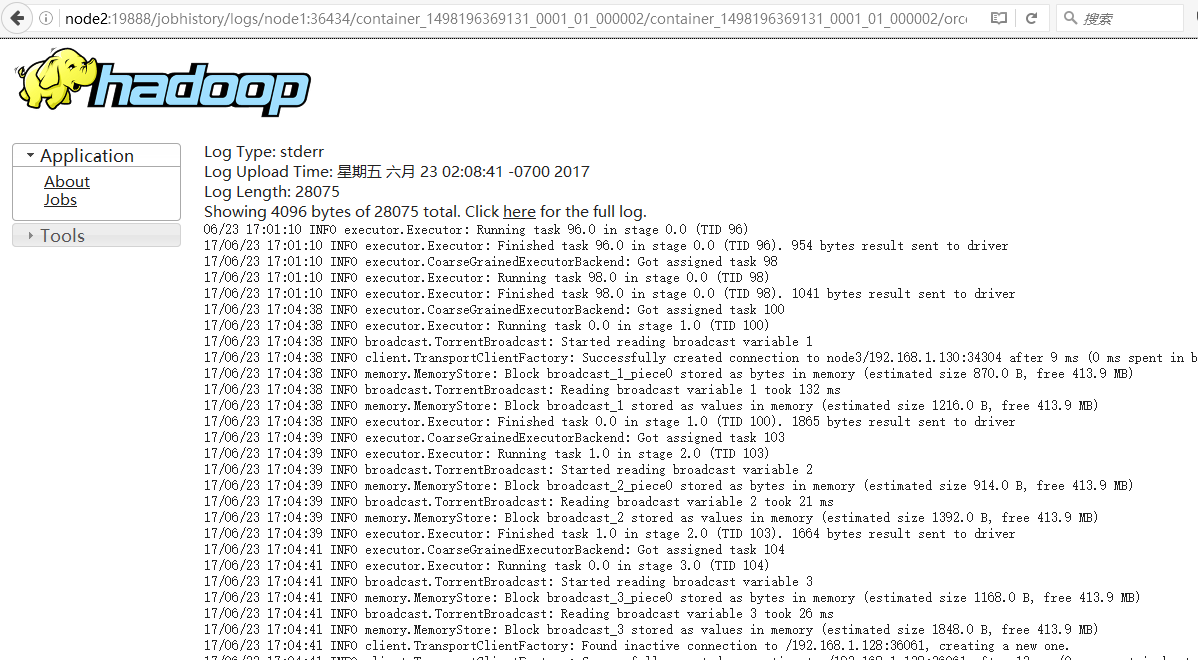
18080是spark的history server,会显示出你最近spark跑过的一些程序,点击execution后,点击最右边的日志(如果有的话),会重定向到19888(见后面注②),这个是mr的jobserver的地址(启动命令:mr-jobhistory-daemon.sh start historyserver)
spark.yarn.historyServer.address和spark.history.ui.port如果缺少其中一个,日志就看不到
综上,1和2两个配置齐全,才可以查看spark的stdout和stderr日志
二、第二部分

实际上,在spark程序运行的时候,会起一个driver程序和多个executor程序,他们都是跑在nodemanager之上的,在启动程序的时候,如果我们在默认的配置项里面,配置了参数spark.eventLog.enabled=true,spark.eventLog.dir=地址,那么driver上就会把所有的事件全部给记录下来,事件包括,executor的启动,executor执行的task等发送给driver
每当写日志的时候,都有一个写日志的组件将日志写进那个目录里面,这个目录下面每一个应用程序都会存在一个文件,然后将会由spark的history server(也就是配置在spark-default.conf里面),这个server会在18080启动一个进程,去扫描日志目录,并解析每一个文件,进行还原,就得到了整个应用的状态
在hadoop-2.7.3/etc/hadoop/mapred-site.xml配置文件中
<property> <name>mapreduce.jobhistory.done-dir</name> <value>/user/history/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/user/history/done_intermediate</value> </property>
stdlog和err是每一个nodemanager上的每一个executor都会产生的,如果当程序完成后,在这个节点上,跟这个应用相关的所有信息全部会被清除掉,包括这些日志,这样的话如果我们不把这个日志收集起来,那么后面在历史信息(18080 executord模块的stderr和out)里面就看不到这些日志
为了能够看到这些日志,我们要做的事情是,让nodemanager开启一个日志聚合的功能,这个功能的作用是,当应用程序终止的时候,需要将这个应用程序产生的所有日志全部聚集到远程hdfs上的一个目录,聚集之后,还需要通过一个http的接口去查看这些日志,查看日志的这个角色就叫做mr的history server,通过她的web ui接口,当我们点击std日志的时候,就会跳转到mr job history server这个地址上19888上,然后去把这个日志展示出来
三、总结
总的来说,yarn-site.xml和conf/spark-defaults.conf这两个配置文件中的地址比较关键
http://node2:19888/jobhistory/logs : 对应的是点击strout的时候跳转的地址
spark.yarn.historyServer.address=node2:18080 :对应的是在yarn里点击history,跳转的地址
注①:
1、进入yarn的web ui页面,点击左侧FINISHED,可查看运行完的作业,点击一个app id

2、进入下图页面,点击History
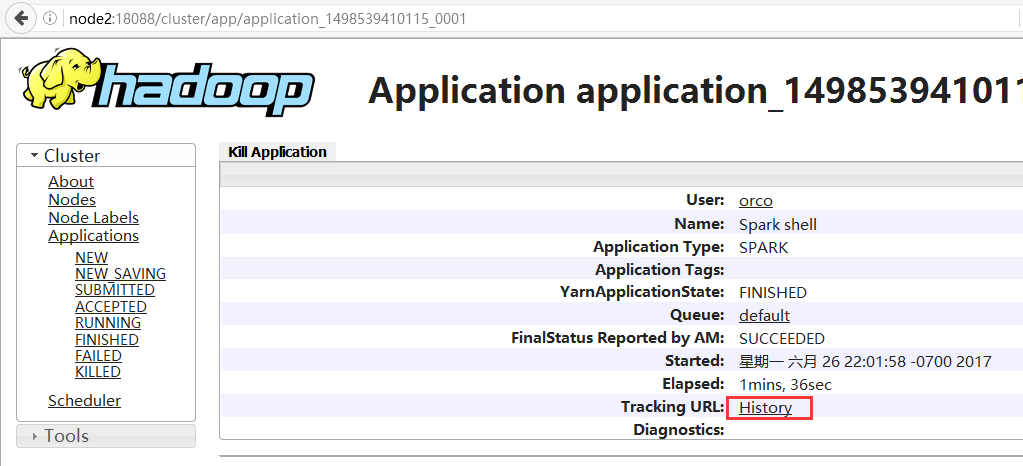
3、重定向到conf/spark-defaults.conf配置的地址

注②:
具体步骤如下:
1、我先运行一个spark程序
bin/spark-shell --master local
2、登录Spark History server的web ui
http://node1:18080/
3、如下图,找到我刚才运行的程序
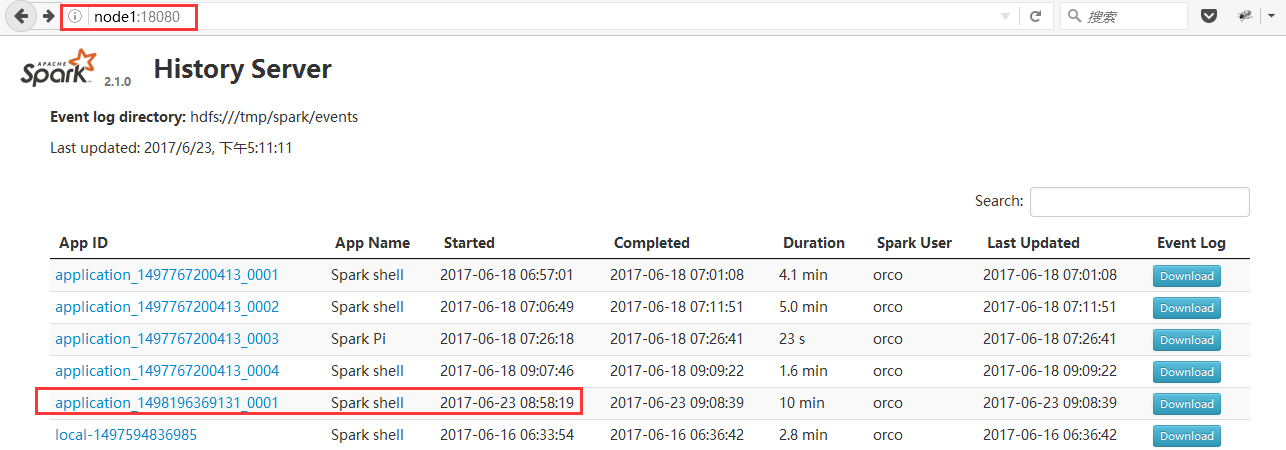 4、点击红框位置App ID,进入如下图页面
4、点击红框位置App ID,进入如下图页面
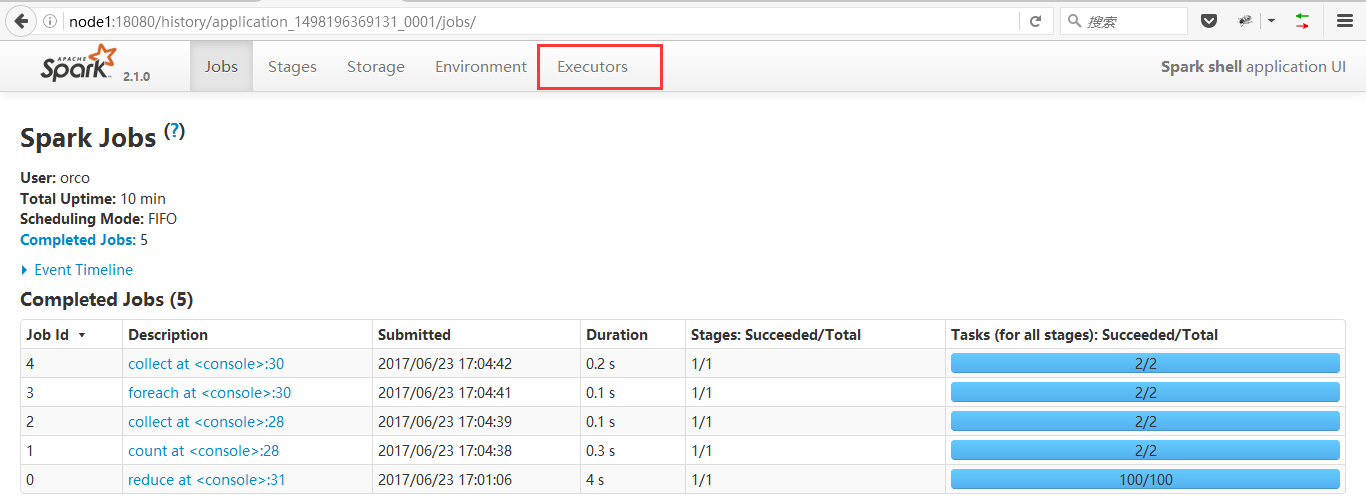
5、点击红框位置Executor,进入下图页面
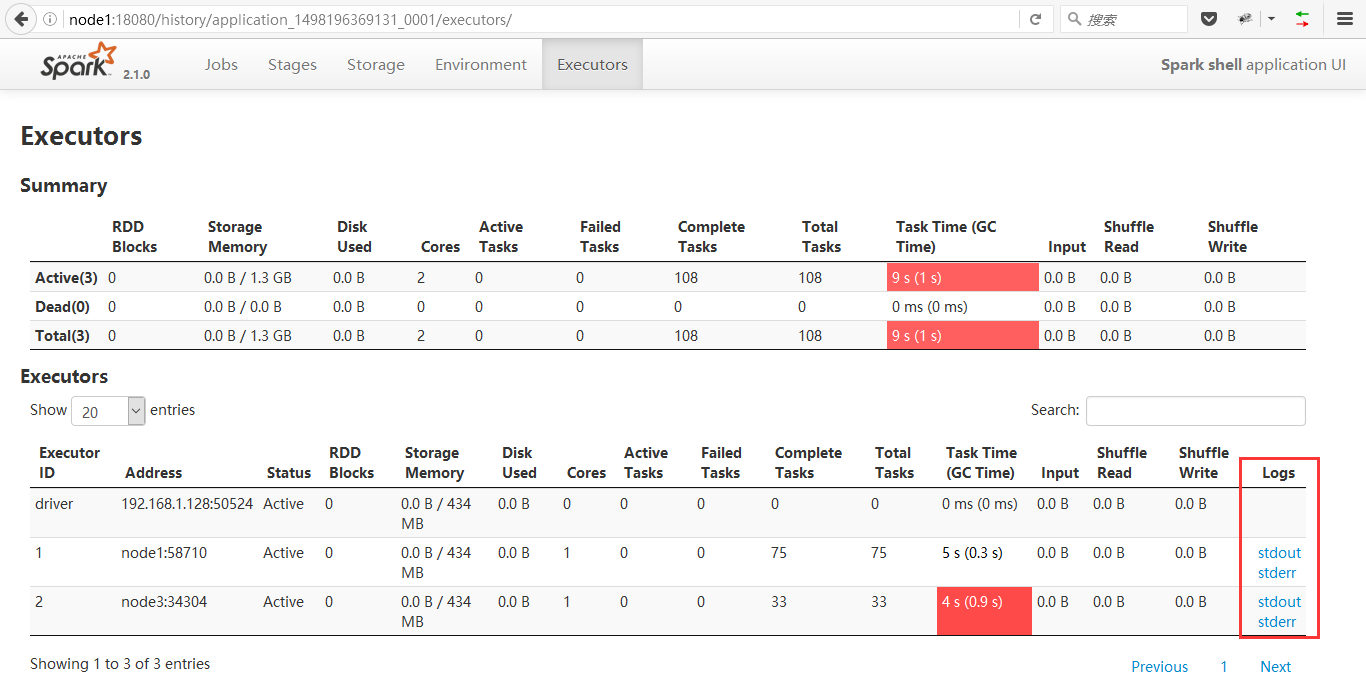
6、右下角的stderr和stdout就是我们此行的目标了
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
当你点击stderr或stdout,就会重定向到node2:19888,所以如果这里你配错了,那这两个日志你是看不了的
node2:19888是你的MapReduce job history server的启动节点地址
进入页面如下图