模块知识储备:
1、定义
用来从逻辑上组织python代码(变量、函数、类、逻辑 实现一个功能)。本质上就是 .py结尾的python文件
2、导入方法
Import module_test #导入一个模块
Import module1_test,module2._test #导入两个模块
From module_test import * #表示如果module_test中有几个方法,全部导入 不建议使用
#不建议使用的原因:因为如果在main函数中,如果有一个同方法名的函数调用时,就只执行当前文件
区别:From module_test import * 相当于拷贝了一份都当前文件,直接调用不用带前缀,而Import module_test只是简单导入,需要通过前缀module_test.logger() 才可以调用
From module_test import logger 调用了这个函数,如果在main中也有一个logger函数,两个都要使用的话,通过给module_test中的logger另起别名调用如下:
From module_test import logger as logger_module 这样要调用module中的logger函数时,直接调用别名: logger_module 就是执行调入函数中的logger函数
From . import test1 # 从当前目录下导入test1文件
From module_test import A,B,C导入多个方法
3、import的本质
执行 import module_test就是将module_test解释了一遍,然后将其中的所有的代码都付给了module_test这个变量(module_test =all code)。
这时调用时,就通过变量名.变量,Module_test.logger()、module_test.name就可以调用,故而from module_test import logger 就是通过解释module_test中的logger ,将其中的logger(函数)方法代码全部赋给变量logger此时就相当将logger代码有付给了logger代码,故而就不需要在通过前缀调用,直接调用就可以
导入模块的本质就是把python文件解释(执行)一遍
导入包的本质:就是执行该包下面的__init__.py文件
如果想导入包package_test 就运行下面的__init__.py
如果在__init__.py中写入:print(“from package package_test ”)
和package_test 不在同一个包下面,并且在调用该包的上面一级,只有单独一个.py文件中写入:Import package_test
直接执行 结果为:from package package_test
如果要调用package_test包下面的.py文件,只需要在__init__.py直接调用包下的.py文件
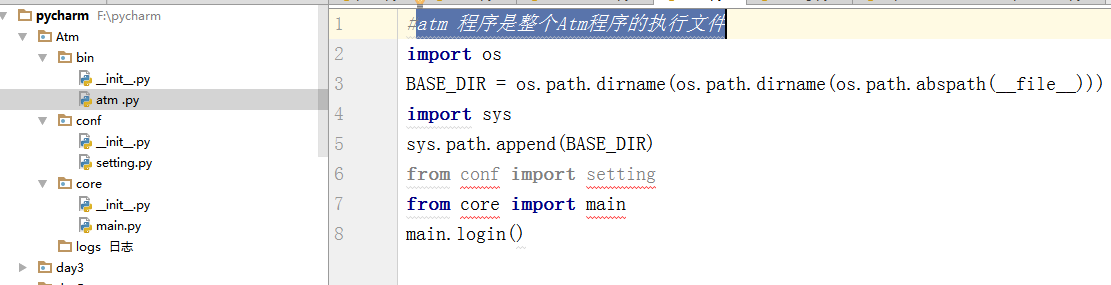
图片解释


"""代码解释 三个文件夹:bin {__init__.py atm.py (atm 程序是整个Atm程序的执行文件)} conf { __init__.py setting.py } core(核心代码){ __init__.py main.py(程序的入口) } logs(日志){ 存放日志 } 在atm.py 文件中写代码 如果要调用 setting.py 和main.py 两个文件 就必须先找到当前(atm.py)文件的 路径,然后通过模块os来一步步向上走,找到要调用文件的上一个路径,atm 然后,再通过 from conf import setting 和 from core import main 来调用函数package包下的setting和main模块文件 将你正在编写的.py文件通过os的方式退到要调用的模块的上一级 """
路径知识
1 import os 2 #print(__file__)#相对路径 3 #print(os.path.abspath( __file__))#绝对路径 4 #print(os.path.dirname(os.path.abspath(__file__)))# 往上返回一级 到 bin 返回目录名,不要文件名( 指的是专拣目录结构规范.py文件) 5 print(os.path.dirname( os.path.dirname( os.path.abspath( __file__ ) ) ) )#再往上返回一级到Atm 6 import sys #用于添加环境变量 文件会在这个由环境变量生成的list中去找 7 BASE_DIR =os.path.dirname( os.path.dirname( os.path.abspath( __file__ ) ) ) #此时将返回到Atm的路径赋给变量BASE_DIR 8 sys.path.append(BASE_DIR) #再将找到的这个路径 追加到 sys.path路径模块中去 但是会追加到list的最后一位 9 #万一在sys.path的list中有一个这样的文件,就会执行这个文件,所以可以通过sys.path.insert()查到前面 10 #import conf,core #标红是因为pycharm启动时,不知道这个conf,core 11 from conf import setting 12 from core import main #表示从一个package包下找到.py文件的模块 13 main.login() 14 #调用的模块在package包外面,直接用 import module_test调用,如果在包里面就必须要通过 15 from core import main 来调用 如上: 16 import sys,os 17 #os 用来调用路径 18 print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) 19 res =os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 20 21 sys.path.append(res) 22 from xixi import module_test 23 module_test.logger()
4、导入优化
如果要调用一个包下的test方法,但要在模块中多次调用,这样每次都要去找module_test.Test这个方法,所以花费时间
解决方法:通过将上面的 import module_test 换成 form module_test import test这样就直接省略了每次都去找module_test.Test的方法,节约时间
5、模块的分类
- 标准库、内置模块
- 开源模块
- 自定义模块
标准库
1、time 和 datetime
在python中,通常有这几种方法来表示时间:1.)时间戳 2.)格式化的时间字符串 3.)元组(struct_time)共九个元素,由于python的time模块实现主要调用C库,所以各个平台可能不同
UTC(coordinated Univerval Time,世界协调时)也成格林威治天文时间,世界标准时间,在中国为UTC+8
DST(Daylight Saving Time)即夏令时
时间戳(timestamp)的方法:通常来说,时间戳表示1970年1月1日00:00:00开始按秒计算的偏移量,我们运行 “ type(time.time() ) ”返回的是float类型,返回时间戳方式的函数主要有time()、clock()等
元组 (struct_time)方式:struct_time()元组共有9个元素,返回struct_time的函数有gmtime()、localtime()、strptime()
时区:将一个地球球体,分成360度,每15度为一个时区,刚好24个时区,以英国刚好在0度,然后中国刚好在东边第8个时区,所以时间要加8,比UTC早了8个小时
import time
help(time)查询时间帮助
时间戳:time.time() 以秒为单位 并且是从1970开始记时
Time.gmtime()讲一个时间戳转换成元祖形式的时间
——如果不加参数就显示现在UTC(标准)的时间,比中国时间迟了8个小时
——如果加上参数,显示的就是所传入时间戳的 元祖表示时间
Time.localtime()
——如果不传,当地的时间(UTC+8时区)
——如果传入,就会显示所传入时间戳转换成元祖的时间
如果要取出元祖表示的时间
Time.mktime()
——讲一个元组形式的变量转换成时间戳形式 因此 一般就是将一个元祖形式的时间赋给一个变量,然后再传值
1 import time 2 x =time.localtime()#表示将本地的时间赋给 x 变量 3 print(x) 4 print(time.strftime("%Y-%m-%d %H:%M:%S",x)) 5 print(time.strptime('2018-02-02 12:26:50',"%Y-%m-%d %H:%M:%S")) 6 print(x.tm_year) 7 #print(learn module.mktime(x)) #将一个元祖形式的时间转换成时间戳形式的时间 8 #print(help(x))#表示 x所有的方法 9 #print(x.tm_year)#通过上面 print(help(x)) 就可以知道要去除年就通过x.tm_year 10 #print(help(learn module.strftime))
struct_time、timestamp、 format string 之间的关系

Datetime
Datetime.date #包含的是 年-月-日
Datetime.time #包含的是时-分-秒
Datetime.datetime #包含的是 年-月-日-时-分-秒
1 Import datetime 2 Datetime.datetime.now()#表示现在的时间 3 函数datetime.timedelta(3)不能单独使用,必须与Datetime.datetime.now()连用如下: 4 Datetime.datetime.now()+datetime.timedelta(3)#现在时间的三天后 5 Datetime.datetime.now()+datetime.timedelta(-3)#现在时间的三天前 默认单位为天 6 Datetime.datetime.now()+datetime.timedelta(hours =3)#现在时间的三个小时后 7 Datetime.datetime.now()+datetime.timedelta(hours =-3)#现在时间的三个小时前 8 Datetime.datetime.now()+datetime.timedelta(minute =30)#现在时间的30分钟后 9 Datetime.datetime.now()+datetime.timedelta(minute =-30)#现在时间的30分钟前
2、random
1 Random.random()#随机数表示在[0,1)之间的随浮点数 2 Random.randint(1,3)#表示[1,3] 1,2,3这三个随机整数 3 Random.randrange(1,3)#表示[1,2) 1,2 这两个随机整数 4 Random.choice( )#括号中可为:序列、tuple、list、dictionary 随机在括号中选择 5 Random.choice(‘hello,world’)#表示在hello,world中随机选择 其他同理 6 Random.sample(‘ ……’ , 数字)#第一个写序列,同上一样,后面写数字表示随机的在前面写的序列中选择几位
随机验证码程序例子:
1 # import random 2 # s =[1,2,3,4,5,6] 3 # random.shuffle(s) #表示将上面的数据随机洗乱依次 洗牌 4 # print(s) 5 # random.shuffle(s) 6 # print(s) 7 import random 8 checkcode =''#先写一个空字符串来存放生成的验证码值 9 for i in range(4): #如果有四位验证码 10 current =random.randrange(0,4) #先随机产生四个数字,来分成两部分 11 if current==i:#如果循环的次数和产生的数字相同 12 tmp =chr(random.randint(65,90)) #就在大写字母A—Z中随机产生 13 # chr()是将ascii表中的数字变成字母 14 else: 15 tmp =random.randint(0,9)#如果循环的次数和产生的数字不相同,就在数字0-9中产生 16 checkcode+=str(tmp) #将生成全部存在checkcode空字符串中 17 print(checkcode) #然后输出
在运行过程出现的错误:
#如果所起的模块名字和标准库中模块的名字相同时,会出现以下情况:
例子: 当在通过import random调用random模块时,把文件名写成了random
1、在文件中就无法调用random标准库中的方法,如果调用会报错
2、如果没有调用到random模块下的方法时,顺利运行程序后,会出现两个相同的输出,就是文件中只有一处有print 如上
3、os模块
1 >>> os.stat(r"f:\pycharm\heihei")#获取文件/目录 2 >>> os.rename(r"f:\pycharm\shiyan",r"f:pycharm\heihei")#重命名 3 >>> os.makedirs(r"d:a\b\c\d")#可生成多层递归目录 4 >>> os.removedirs(r"d:a\b\c\d")#若目录为空则删除,且返回到上一级目录,若为空仍删除以此类推 5 就是将多个路径拼接在一起如下: 6 >>> os.path.join(r'f:',r'\b',r'a.txt') #结果为:'f:\\b\\a.txt' 7 Os.path.getatime() #返回path所指向的文件或者目录的最后存取时间 8 Os.path.getmtime() # 返回path所指向的文件或者目录的最后修改时间
View Code
4.sys.模块
1 sys.argv #命令行参数list,第一个元素是程序本身路径 2 sys.exit(n) #退出程序,正常退出时exit(0) 3 sys.version #获取python解释程序的版本信息 4 sys.path #返回模块的搜索路径初始化时使用pythonpath环境变量的值 5 sys.platform #返回操作系统平台名称 6 sys.stdout.write('please:')#返回结果: please:7
5、shutil模块
功能:高级文件、文件夹、压缩包、处理模块
1 Shutil.copy(src,dst) #拷贝文件和权限 2 def copy(src, dst): 3 """Copy data and mode bits ("cp src dst"). 4 The destination may be a directory. """ 5 shutil.copymode(src, dst)# 仅拷贝权限。内容、组、用户均不变 6 def copymode(src, dst): 7 """Copy mode bits from src to dst""" 8 shutil.copystat(src, dst) 9 拷贝状态的信息,包括:mode bits, atime, mtime, flags 10 def copystat(src, dst): 11 """Copy all stat info (mode bits, atime, mtime, flags) from src to dst""" 12 shutil.copy2(src, dst)#拷贝文件和状态信息 13 def copy2(src, dst): 14 """Copy data and all stat info ("cp -p src dst"). 15 The destination may be a directory. """ 16 shutil.copytree(src, dst, symlinks=False, ignore=None) 17 #递归的去拷贝文件,旧目录拷贝到新目录 连下面的子目录都一起拷贝 18 Shutil.copytree(“test4”,”new_test4”)#其中test4和new_test4都是一个包 19 shutil.rmtree(path[, ignore_errors[, onerror]]) 20 递归的去删除文件 21 Shutil.rmtree(“new_test4”)#删除new_test4整个包以及下面的子目录 22 shutil.move(src, dst)#递归的去移动文件
shutil.make_archive(base_name, format,...) 创建压缩包并返回文件路径,例如:zip、tar
1 #自己测试 2 shutil.make_archive("压缩测试","zip","F:\pycharm\day5")#第一个为压缩的名称;第二个为压缩的类型;第三个为要压缩文件的路径 3 4 shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细: 5 6 zipfile 压缩解压 7 import zipfile 8 # 压缩 9 z = zipfile.ZipFile('laxi.zip', 'w') 10 z.write('a.log') 11 z.write('data.data') 12 z.close() 13 14 # 解压 15 z = zipfile.ZipFile('laxi.zip', 'r') 16 z.extractall() 17 z.close() 18 Eg: 19 import zipfile 20 #压缩单个压缩.zip 21 z =zipfile.ZipFile('单个压缩.zip','w')#压缩包名:单个压缩.zip 操作为:写 默认为:读 22 z.write('F:\pycharm\day3\\test.py')#写上路径 23 print('-----中间可以干别的事情-------') 24 z.write('F:\pycharm\day6\module_test1\path.py') 25 z.close() 26 #解压单个压缩.zip 27 z = zipfile.ZipFile('单个压缩.zip','r') 28 z.extractall() 29 z.close() 30 31 zipfile 压缩解压 32 33 import tarfile 34 # 压缩 35 tar = tarfile.open('your.tar','w') 36 tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip') 37 tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip') 38 tar.close() 39 # 解压 40 tar = tarfile.open('your.tar','r') 41 tar.extractall() # 可设置解压地址 42 tar.close()
5、json&pickle
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
由于在python中,通过json和pickle多次dumps之后如果在load的时候,就会出现错误,因为在通过load要取出某一次值的时候就必须要记住dump了几次,否则就无法顺利取出,为了解决这个问题就引入了shelve模块
6、shelve 模块
1 import shelve,datetime 2 d = shelve.open("shelve_test")#通过shelve方法将文件名为shelve_test的文件打开,方法和file一样 3 info ={'age':23,'job':'it'} 4 name =['zhangsan','lisi','wangwu'] 5 """以关键字key的形式 将 字典、列表、数据等 写入文件保存, 6 之后后面会出现数字,就是用来进行序列化,这样就会很快查找""" 7 d['info']=info #持久的dictionary 8 d['name']=name#持久的list 9 d['date']=datetime.datetime.now()#持久的date 10 """ 11 通过d.get(key)就可以将存入的东西取出文件 12 """ 13 print(d.get("info")) 14 print(d.get("name")) 15 print(d.get("date")) 16 d.close()
7、xml处理文件
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
1 <data> 2 <country name="Liechtenstein"> 3 <rank updated="yes">2</rank> 4 <year updated="yes" updated_by="zss">2012</year> 5 <gdppc>141100</gdppc> 6 <neighbor direction="E" name="Austria" /> 7 <neighbor direction="W" name="Switzerland" /> 8 </country> 9 <country name="Singapore"> 10 <rank updated="yes">5</rank> 11 <year updated="yes" updated_by="zss">2015</year> 12 <gdppc>59900</gdppc> 13 <neighbor direction="N" name="Malaysia" /> 14 </country> 15 <country name="Panama"> 16 <rank updated="yes">69</rank> 17 <year updated="yes" updated_by="zss">2015</year> 18 <gdppc>13600</gdppc> 19 <neighbor direction="W" name="Costa Rica" /> 20 <neighbor direction="E" name="Colombia" /> 21 </country> 22 </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
1 import xml.etree.ElementTree as ET 2 tree = ET.parse("xml_test.xml") 3 root = tree.getroot() 4 #print(root)#表示 xml_test.xml 的根目录date的内存地址 5 print(root.tag) #root.tag 表示在xml_test.xml 中root的名称 6 7 #遍历xml文档 8 for child in root: #child是root的下一级目录的内存地址 9 # print(child.tag)#root的下一级目录 (即country) 10 print(child.tag,child.attrib)#root的下一级目录 country的内存地址 11 for i in child: #root的下一级目录的下一级目录 12 print(i.tag, i.text)#i.tag是root的下一级目录的下一级目录标题, 13 # i.text#root的下一级目录的下一级目录的内容 14 15 # 只遍历year 节点 16 for node in root.iter('year'): 17 print(node.tag, node.text)#遍历year这个节点并且和year的参数
Xml_test修改和删除
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xml_test.xml") 4 root = tree.getroot() 5 6 # 修改 7 for node in root.iter('year'):#通过root.iter()找到year这个目录 8 new_year = int(node.text) + 1 #因为node.text中的year是一个字符串,先转成int类型再加 1 9 node.text = str(new_year) #要将int类型的new_year转化成str(new_year)在存储 10 node.set("updated", "yes")"""<year updated="yes" updated_by="zss">2012</year> 11 其中等于yes说明已经修改,而后面的updated_by="zss"表示由谁修改 12 node.set("updated_by", "zss") #可以再将year后加上任何属性(可以是自己随便定义的)""" 13 tree.write("xml_test.xml")#再将上面修改的内容存储到xml_test.xml文档中 14 15 # 删除node 16 for country in root.findall('country'):#找到所有的country并循环country 17 rank = int(country.find('rank').text)#并且找到所有country下的'rank',将其后面的字符串数字转换成int类型的数字并赋值rank变量 并且为一个.text的文件 18 if rank > 50:#在判断rank的值是否大于50 19 root.remove(country)#如果小于50则移除这个rank所在的country标签以及下面的所有内容 20 21 tree.write('output.xml')#在将其写入新建立的一个output.xml文件中
Xml文件的创建
1 import xml.etree.ElementTree as ET#先找到ET的内存对象,然后最后在生成一个文档 2 3 new_xml = ET.Element("namelist") #namelist为根节点 4 z = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "yes"})#在根节点new_xml下,创建一个name的子节点,属性为字典中的值 5 age = ET.SubElement(z, "age", attrib={"checked": "no"})#在name的子节点下在创建一个子节点age,属性为attrib之后的内容 6 name1 = ET.SubElement(z, "name", attrib={"checked": "no"}) 7 name1.text ="zss" 8 sex = ET.SubElement(z, "sex")#再在name的子节点下创建一个sex的子节点 9 age.text = '33' #年龄为33 10 s = ET.SubElement(new_xml, "personinfo2", attrib={"enrolled": "no"})#其中的括号中的personinfo2为namelist根节点的子节点,前面的personinfo2是一个变量代表了personinfo2这个子节点 11 age = ET.SubElement(s, "age") 12 age.text = '19' 13 name2 = ET.SubElement(s, "name", attrib={"checked": "no"}) 14 name2.text="zhangsan" 15 et = ET.ElementTree(new_xml) # new_xml为生成文档对象 16 et.write("test.xml", encoding="utf-8", xml_declaration=True)#文件名为test.xml 编码格式为utf-8 为一个版本号 17 18 ET.dump(new_xml) # 打印生成的格式
要在python中添加一个标签有下列的要求
变量名=ET,ElementTree(父节点,“要添加的标签”,要添加的属性)
变量名.text ="标签包起来要显示的内容"
8、ymal语法 需要下载库
9、Configparser模块
写一个配置文件
1 import configparser 2 #写一个配置文件config 3 config = configparser.ConfigParser()#先把对象调进来然后在赋给变量config 4 5 config["DEFAULT"] = {'ServerAliveInterval': '45', #第一个节点 6 'Compression': 'yes', 7 'CompressionLevel': '9'} 8 9 config['bitbucket.org'] = {} #第二个节点 10 config['bitbucket.org']['User'] = 'hg' 11 config['topsecret.server.com'] = {} #第三个节点 12 13 topsecret = config['topsecret.server.com'] #点三个节点 14 topsecret['Host Port'] = '50022' # mutates the parser 15 topsecret['ForwardX11'] = 'no' # same here 16 config['DEFAULT']['ForwardX11'] = 'yes' 17 with open('example.ini', 'w') as configfile: 18 config.write(configfile)
配置文件的读和删
1 '''用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。 2 如果要生成一个以.config为后缀的文档时,先在其中建立一个.py文件,输入完成后在重命名为.config''' 3 import configparser 4 config=configparser.ConfigParser() 5 print(config.sections())# 因为没有读文件,所以输出一个空的list 6 print(config.read('example.ini')) 7 print(config.sections())#但是打印了两个 因为default是默认的,所以只打印节点 而不打印defalut 8 print(config.defaults())#读defaults中的文档内容 9 print(config['bitbucket.org']['user'])#读bitbucket.org下user的信息
10、hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 md5值是不能反解的
1 import hashlib 2 m =hashlib.md5()#要加密对象存放的地方 3 m.update(b"Hello")#b'hello' bytes 类型 4 print(m.hexdigest())#表示十六进制来加密 bytes类型的 hello 5 # m =hashlib.md5() 6 m.update(b"It's me" ) 7 print(m.hexdigest()) #表示用十六进制来加密helloit's me这两句 8 """验证是否相同 将两个bytes类型的东西全部放在一起打印出来 9 如果结果相同的话就表示是将上面两个连起来加密 10 但是如果是通过两个m.update(b'')来起来的话,共用一个 11 m=hashlib.md5() 结果相同,但是两个分别用了一次 m=hashlib.md5() 12 那么结果就不相同,因为相同时通过共用一个 m=hashlib.md5(),使得 13 m是完全相同的,之后的就是m的更新""" 14 m2 = hashlib.md5() 15 m2.update(b"HelloIt's me") 16 print(m2.hexdigest()) 17 18 # 如果有中文就必须要通过下列方式进行加密 19 m2 = hashlib.md5() 20 m2.update("天王盖地虎,宝塔镇河妖".encode(encoding="utf-8"))#可以运行 顺利加密 21 print(m2.hexdigest())
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密 散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
更多关于md5,sha1,sha256等介绍的文章看这里 https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
1 import hmac 2 s2 =hmac.new(b"124",b"sdfsdf") 3 s2 =hmac.new(b"124","我放假死灵法师".encode(encoding="utf-8"))#可以运行 并顺利加密 4 s2 =hmac.new(b"jkhj","我放假死灵法师".encode(encoding="utf-8"))#可以运行并顺利加密 5 s2 =hmac.new("网址之王".encode(encoding="utf-8"))#可以运行 并且顺利加密 6 s2 =hmac.new("网址之王","我放假死灵法师".encode(encoding="utf-8")) #不可以运行 出错 7 print(s2.hexdigest())
11、re模块(正则表达式) 用于匹配字符串
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 '{m}' 匹配前一个字符m次 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的 '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] '\s' 匹配空白字符、\t、\n、\r , re.search ("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果: {'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
总结:
+ 表示 会按照它前面字符的样式来打印多个 . 表示 打印除\n(换行)外的所有字符 .+ 组合才会全部包括后面的数字 打印之后的所有字符 [a-z] 表示 打印一个小写字母;[A-Z]表示:打印一个大写字母 [a-z] + [A-Z] 可以组合起来用 ("z[a-z]+[A-Z]+","jiang123zhongzHenzhongzhen1232424124zhongzhen") Eg: 一、z[a-z]+[A-Z]+.+ 就是将上面从z开始打印完 结果:zhongzHenzhongzhen1232424124zhongzhen 二、"z[a-zA-Z]+\d+" 就是将上面从z开始打印到结果:zhongzHenzhongzhen1232424124
重点知识
1 res=re.search("aaaaz?","azhangaaaa")# 表示 ?前面的那个 z有和没有都可以 但是z?前面的那些a必须都要匹配到,如果匹配不到就 报错,可以匹配到就输出 2 res =re.findall("[0-9]{1,3}","z1h23a456n7g8") re.findall() 没有group方法 3 print(res) #结果为:['1', '23', '456', '7', '8'] 4 res =re.findall("[0-9]{1,2}","z1h23a456n7g8") 5 print(res) #结果为:['1', '23', '45', '6', '7', '8'] 6 res =re.findall("[0-9]{3}","z1h23a456n7g8") 7 print(res) #结果为:['456'] 8 9 '''重点''' 10 res=re.search("(?P<province>[0-9]{2})(?P<shi>[0-9]{2})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242") 11 print(res.groupdict()) #其中的 ?P 表示语法 <key>[范围]{几位} 结果为:{'province': '37', 'shi': '14', 'city': '81', 'birthday': '1993'} 并且还可以再加几组字典 12 print(res.groupdict()['city']) # 相当于取出字典中的key=’city’结果为:81
re.sub()知识使用
re.sub(pattern,repl,string,count=0,flags =0) 替换
pattern:表示要匹配的值
repl:要替换成什么 这里是写定值,不能比正则表达式
string:在“”中进行匹配
count:表示替换几次
eg:res =re.sub("[0-9]","|","ab2h4h35g42g",count=2)
print(res) #结果为: ab|h|h35g42g
扩展:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
re模块用法案例:
1 Eg:res =re.search("[a-z]+","zhangSHuai",flags =re.I)# flag =re.I 忽略大小写 结果为:zhangSHuai 2 print(res.group()) 3 4 """re(正则表达式)就是用于动态匹配的 如果是一个固定值,就不需要通过re来进行 直接通过 wang in wangmazi:就可以进行匹配 """ 5 6 7 import re 8 """re.match 的用法:就是默认从头开始的, 9 ^ 表示要匹配字符开头 故而 ^ 在match中没有用 10 第一个""写的是要匹配的内容,后面的""写的是匹配度的范围 11 res =re.match("^wang","wang mazi") 12 print(res) #如果有返回结果 就表示匹配到了 如果没有匹配到就返回 None 13 print(res.group())#通过res.group()来查看匹配到什么""" 14 15 """ \d+的用法 16 \ 表示后面是用于正则的语法,\d表示一个数字 结果为:wang2, 17 \d+表示一个或多个数字结果为:wang234 18 res =re.match("wang\d+","wang234 mazi ") 19 print(res.group()) 20 """ 21 22 """ . 的用法 23 res =re.match(".","@wang234 mazi ")# . 默认匹配除\n之外的任意一个字符 在此处打印 @ 24 # res =re.match(".+","wang234 mazi ")# + 表示打印后面的多个 故而: .+ 打印全部 25 # res =re.match(".\d","w1ang234 mazi ")#如果第一位是 w 第二个为数字就可以执行,否则就会报错 26 # res =re.match("^w","wang234 mazi ") 27 print(res.group())""" 28 29 30 """re.serach的用法 表示从整个内容中搜查 这是会用到 ^ 符号""" 31 #res = re.search("z.+n","jiang123zhongzhen123a")#从z开始 通过.+就z之后一直到 32 #后面的 n 如果前面+之后没有n就会包括123 33 34 #res =re.search("z[a-z]+.+2","jiang123zhong zhen123a") 35 """ 36 [a-z]输出一个在a到z之间的一个字符, + 表示多个字符,第一个 + 从o取到g 37 然后 . 表示一个除\n(换行)外的任意一个字符取出空格, 第二个加号表示 38 从 z 一直往后取到加号后面的截止字符 结果为:zhong zhen12 39 res =re.search("z[a-z]+[A-Z]+.+","jiang123zhongzHenzhongzhen1232424124zhongzhen")#输出结果为:zhongZhenzhongzhen 40 #res =re.search("z[a-zA-Z]+\d+","jiang123zhongzHenzhongzhen1232424124zhongzhen") 41 res =re.search("#.+#","123#hello#")#结果为:#hello# 42 print(res.group())""" 43 # res=re.search("aaaaa?","azhangaaaa")#表示?前面的那个a有和没有都可以 但是a?前面的那些a必须要匹配到 44 # print(res.group()) 45 46 47 """re.findall() 匹配不相连的多个数字 并且没有group()方法 48 #res =re.findall("[0-9]{1,2}","z1h23a456n7g8")#结果为:['1', '23', '45', '6', '7', '8'] 49 #res =re.findall("[0-9]{1,3 }","z1h23a456n7g8")#结果为:['1', '23', '456', '7', '8'] 50 res =re.findall("[0-9]{3}","z1h23a456n7g8")#结果为:['456'] 51 52 print(res)""" 53 54 res=re.search("abc|ABC","ABCBabcdB")#先匹配小写或者再匹配大写 返回结果:ABC 55 res=re.search("abc{2}","abccadf") #匹配abc并且c匹配两次 即:必须要有abcc才可以才返回,否则报错 56 res =re.search("(abc){2}","abcabcadf")#同上 将abc当做一个小组,同时匹配两次 即:abcabc 否则报错 57 res =re.search("(abc){2}\|","abcabcadf")#同理 \ 表示转义符,代表不要将 |当做或l来处理 有abcabc| 时才输出,否则报错 58 res =re.search("(abc){2}(\|\|=){2}","sdabcabc||=||=adf")# 每一个 \| 都要用输出结果为:abcabc||=||= 59 res =re.search("\A[0-9]+[a-z]+\Z","123sdf")#\A等同于 ^ ,表示从第一个元素开始,从第一个为数字,然后经过几个数,然后经过几个字母\Z表示以 字母结束 60 res =re.search("\D+","123&%*- A@ \\n") #\D匹配不是数字的任意一个字符 特殊字符可以 换行也可以 结果为:&%*- A@ \n 61 res =re.search("\w+","123&%*- A@ \\n")# 小写的 \w只匹配数字和字母 结果为:123 62 res =re.search("\W+","123&%*- A@ \\n")#只匹配特殊字符 结果为:&%*- 63 #res =re.search("\s+","\r\t\n123&%*- A@ ") 64 res=re.search("(?P<province>[0-9]{2})(?P<shi>[0-9]{2})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242") 65 #其中的 ?P 表示语法 <key>[范围]{几位} 结果为:{'province': '37', 'shi': '14', 'city': '81', 'birthday': '1993'} 66 print(res.groupdict()['city']) 67 res =re.split("[0-9]+","ab2h4h35g42g") # 因为[0-9]只是一个字符,故而表示将后面的内容# 以数字分隔开,然后是单个数字的去掉, 68 多个数字的就以空字符显示出来并与分隔开的字母形成列表 结果为:['ab', 'h', 'h', '', 'g', '', 'g'] 69 res =re.sub("[0-9]+","|","ab2h4h35g42g",count=2) 70 print(res) 71 res =re.search("[a-z]+","zhangSHuai",flags =re.I)# flag =re.I 忽略大小写 结果为:zhangSHuai 72 print(res.group())
参考文献
http://www.cnblogs.com/alex3714/articles/5161349.html
http://www.cnblogs.com/wupeiqi/articles/4963027.html