java中垃圾回收算法+垃圾收集器
垃圾回收Garbage Collection,简称GC。GC中的垃圾指的是内存中不会再被使用的对象,而回收就是相当于把垃圾"倒掉"。垃圾回收有很多种算法:引用计数法、标记压缩法、复制算法、分代、分区。
在java堆中,新生代:老年代=1:2或1:3 比较合适
垃圾回收算法
引用计数法:这是个比较古老而经典的垃圾收集算法,其核心就是在对象被引用时计数器加1,而当引用失效时则减1,但是这种方式存在非常严重的问题,无法处理循环引用的情况,还有就是每次进行加减操作时比较浪费系统性能。
标记清除法:分为标记和清除两个阶段进行处理内存中的对象,这种方式也有非常大的弊端,就是空间碎片问题。垃圾回收后的空间不是连续的,不连续的内存空间的工作效率要低于连续的内存空间。
复制算法:其核心思想就是将内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的留存对象复制到未被使用的内存块中,之后去清除之前正在使用的内存块中所有的对象,反复去交换两块内存的角色,完成垃圾收集。
标记压缩法:标记压缩法在标记清除法的基础上做了优化,把存活的对象压缩到内存的一端,而后进行垃圾清理。
分代算法:根据对象的特点把内存分为N块,然后根据每个内存块的特点使用不同的算法。如java中新生代与老年代
分区算法:主要就是将整个内存分成N多个小的独立空间,每个小空间都可以独立使用,这样细粒度的控制一次回收多少个小空间和哪些小空间,而不是对整个内存进行GC,从而提高性能,并减少GC的停顿时间。
对于新生代和老年代来说,新生代回收频率很高,但是每次回收耗费的时间都很短;而老年代回收频率较低,每次回收耗费时间相对较长,所以应该尽量减少老年代的GC。
老年代中对象已经比较稳定,经过多次GC均未被回收,在GC垃圾回收时,清理的内存比较小,存活的对象占得比例非常大。因此,老年代使用的是标记压缩法。
垃圾回收时的停顿现象
为了让垃圾回收器高效的执行,大部分情况下,会要求系统进入一个停顿状态。停顿的目的是终止所有应用线程,只有这样系统才不会有新的垃圾产生,同时停顿保证了系统状态在某一个瞬间的一致性,也有益于更好的标记垃圾对象。
对象如何进入老年代
新创建的对象被放置在新生代的eden区,如果没有经历GC,该新创建的对象会一直放在eden区。经过一次GC之后,进入到新生代的s0或s1区,在新生代中对象每经过一次GC年龄就会增加1,在对象的年龄达到一定大小的时候,就会从新生代进入到老年代,对象的年龄是该对象经历的GC次数决定的。虚拟机提供了一个参数来控制新生代对象的最大年龄,当超过这个年龄范围就会晋升为老年代。另外,大对象即新生代eden区无法装入时,也会直接进入老年代,JVM中存在相关参数可以设置对象的大小超过指定的大小之后,直接晋升为老年代。
-XX:MaxTenuringThreshold 指定新生代对象经过多少次回收后进入到老年代,默认情况下为15
-XX:PretenureSizeThreshold 指定不经过新生代而直接晋升到老年代的对象大小
Test05.java
public class Test05 {
public static void main(String[] args) {
//初始的对象在eden区
//参数:-Xmx64M -Xms64M -XX:+PrintGCDetails
for(int i=0; i< 5; i++){
byte[] b = new byte[1024*1024];
}
}
}JVM参数
-Xmx64M -Xms64M -XX:+PrintGCDetails
Eclipse的console输出如下:
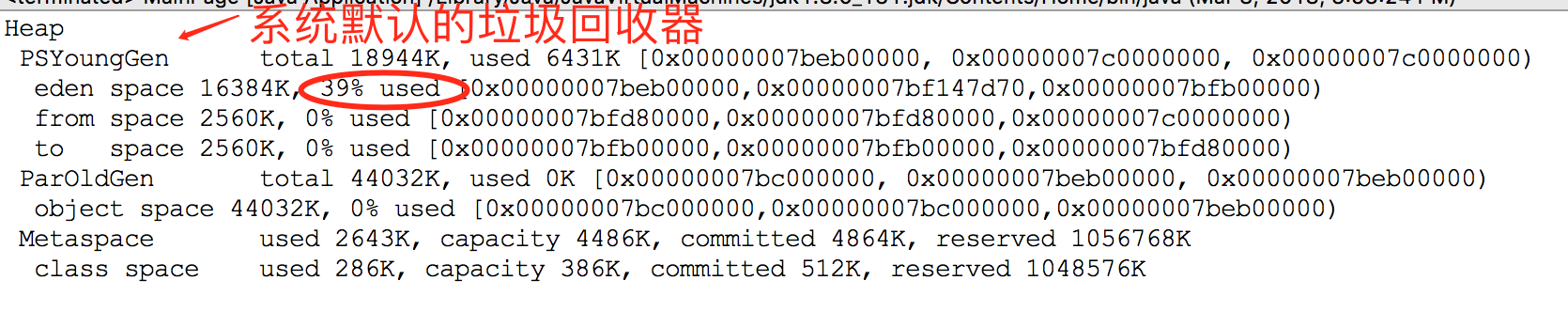
上图中,eden区使用率为39%,java程序运行时初始堆大小为64M,因此程序中分配的5个1M的空间创建的几个对象都放置到了eden区中。
Test06.java
import java.util.HashMap;
import java.util.Map;
public class Test05 {
public static void main(String[] args) {
//测试进入老年代的对象
//参数:-Xmx1024M -Xms1024M -XX:+UseSerialGC -XX:MaxTenuringThreshold=15 -XX:+PrintGCDetails
for(int k = 0; k<20; k++) {
for(int j = 0; j<300; j++){
byte[] b = new byte[1024*1024];
}
}
}
}JVM参数
-Xmx1024M -Xms1024M -XX:+UseSerialGC -XX:MaxTenuringThreshold=15 -XX:+PrintGCDetails
Eclipse的console输出如下:

经过多次GC之后,eden区使用率为12%。tenured老年代空间使用率为0%,说明进入到老年代的对象已经被回收掉了。
Test07.java
import java.util.HashMap;
import java.util.Map;
public class Test07 {
public static void main(String[] args) {
//参数:-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000
Map<Integer, byte[]> m = new HashMap<Integer, byte[]>();
for(int i=0; i< 5; i++){
byte[] b = new byte[1024*1024];
m.put(i, b);
}
}
}
JVM参数
-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000
Eclipse的控制台输出如下:

上述代码中设置-XX:PretenureSizeThreshold=1000,即指定不经过新生代而直接晋升到老年代的对象大小为1000字节,而代码中new byte[1024*1024]的大小为1M>1000字节,属于大对象直接放入到老年代中。因此,老年代used 5136k。
Test08.java
public class Test08 {
public static void main(String[] args) {
//
//参数:-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000
Map<Integer, byte[]> m = new HashMap<Integer, byte[]>();
for(int i=0; i< 5*1024; i++){
byte[] b = new byte[1024];
m.put(i, b);
}
}
}JVM参数
-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000
Eclipse的console输出如下:

老年代仅仅使用了16k,这是因为虚拟机对于体积不大的对象 会优先把数据分配到TLAB区域中,因此就失去了在老年代分配的机会。JVM中每个线程,默认是使用TLAB的。
若将JVM参数修改如下,禁用TLAB
-Xmx30M -Xms30M -XX:+UseSerialGC -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000 -XX:-UseTLAB
此时Eclipse的console输出如下:
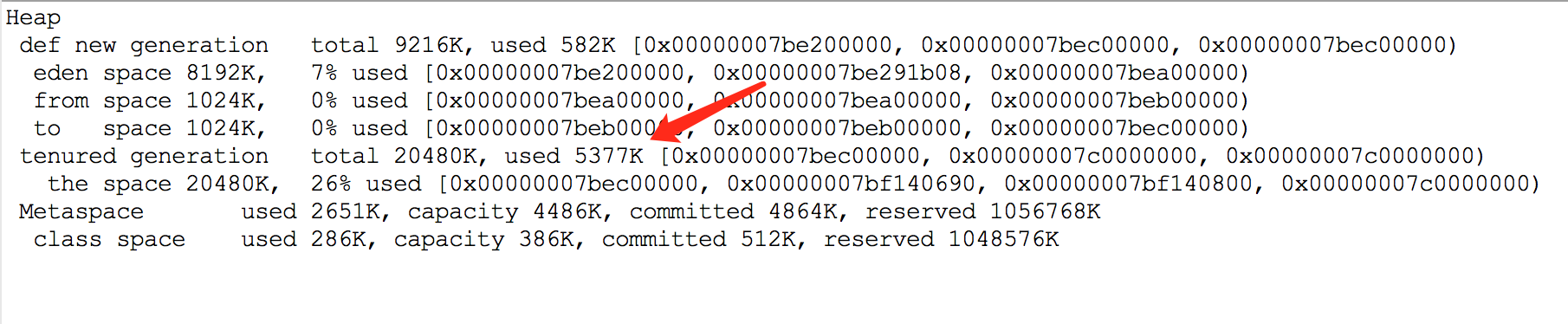
TLAB
TLAB即Thread Local Allocation Buffer 即线程本地分配缓存,每一个线程都会产生一个TLAB,是线程独享的工作区域。JVM使用TLAB来避免多线程冲突问题,提高对象分配的效率。TLAB空间一般不会太大,当大对象无法 在TLAB分配时,会直接分配到堆上。
-XX:+UseTLAB 使用TLAB
-XX:-UseTLAB 禁用TLAB
-XX:+TLABSize 设置TLAB大小
-XX:TLABRefillWasteFraction 设置维护进入TLAB空间的单个对象大小,它是一个比例,默认为64。即如果对象大于整个空间的1/64,则在堆创建对象。
-XX:+PrintTLAB 查看TLAB信息
-XX:ResizeTLAB 自动调整TLABRefillWasteFraction阀值。
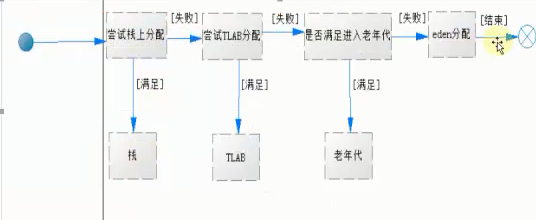
一个对象的创建流程
一个对象创建在什么位置,JVM会有一个比较细节的流程,根据数据的大小、参数的设置,决定如何创建分配,以及其位置。
垃圾收集器
在tomcat的catalina.sh中使用JAVA_OPT配置初始堆大小,最大堆大小。
在JVM中,垃圾回收器有多种:串行垃圾回收器、并行垃圾回收器、CMS回收器(主流)、G1回收器。
串行回收器:使用单线程进行垃圾回收的回收器。每次回收时,串行回收器只有一个工作线程,对于并行能力较弱的计算机来说,串行回收器的专注性和独占性往往有更好的性能表现。根据作用于不同的堆空间,可以分为新生代串行回收器和老年代串行回收器。
-XX:+UseSerialGC 设置使用新生代串行回收器和老年代串行回收器
并行回收器(新生代ParNew回收器):在串行回收器的基础上做了改进,可以使用多个线程同时进行垃圾回收,对于计算能力强的计算机而言,可以有效缩短垃圾回收所需要的时间。ParNew回收器是一个工作在新生代的垃圾回收器,它只是简单的将串行回收器多线程化,它的回收策略和算法与串行回收器一样。
-XX:+UseParNewGC 使用新生代ParNew垃圾回收器
-XX:ParallelGCThreads 指定ParNew回收器工作时的线程数量,一般最好和计算机CPU核数相当,避免过多线程影响性能
并行回收器(新生代ParallelGC):新生代ParallelGC回收器,它是使用了复制算法的回收器,也就是多线程独占形式的收集器,它有个非常重要的特点,即非常关注系统的吞吐量。提供了2个非常关键的参数控制系统的吞吐量。
-XX:MaxGCPauseMillis 设置最大垃圾收集停顿时间,可将虚拟机在GC的停顿时间控制在MaxGCPauseMillis范围内。如果希望减少GC停顿时间,可以将MaxGCPauseMillis设置的很小,但是会导致GC频繁,从而增加GC总时间,降低了吞吐量,所以需要根据实际情况设置该值。
-XX:GCTimeRatio 设置吞吐量大小,它是一个0到100之间的整数,默认情况下的取值为99,那么系统将花费不超过1/(1+n)的时间用于垃圾回收。
-XX:+UseAdaptiveSizePolicy 打开自适应模式,在这种模式下,新生代大小、eden与from/to的比例,以及晋升老年代的对象年龄参数都会被自动调整,以达到在堆大小、吞吐量、停顿时间之间的平衡点。
并行回收器(老年代ParallelOldGC回收器):老年代ParallelOldGC回收器也是一种多线程的回收器,和新生代的ParallelGC回收器一样,也是一种关注吞吐量的回收器,使用了标记压缩算法进行实现。
-XX:+UseParallelOldGC 设置老年代ParallelOldGC回收器
-XX:+ParallelGCThreads 设置垃圾收集时的线程数量
CMS回收器(主流):全称Concurrent Mark Sweep 意思为并发标记清除,使用的是标记清除法,主要关注系统停顿时间。
-XX:+UseConcMarkSweepGC 设置使用CMS垃圾回收器
-XX:ConcGCThreads 设置并发线程数量
CMS并不是独占的垃圾回收器,在其进行垃圾回收过程中,应用程序仍然在不停的工作,又会有新的垃圾不断的产生,所以在使用CMS的过程中应该确保应用程序的内存足够可用。CMS不会等到应用程序饱和的时候才去回收垃圾,而是在某一个阀值的时候就开始回收,回收阀值可以使用指定的参数进行配置-XX:CMSInitiatingOccupancyFraction来指定,默认为68,即当老年代的空间使用率达到68%的时候,会执行CMS回收。如果内存使用率增长的很快,在CMS执行过程中,已经出现了内存不足的情况,此时CMS回收就会失败,虚拟机将启动老年代串行回收器进行垃圾回收,这会导致应用程序中断,直到垃圾回收完成后才会正常工作,这个过程GC的停顿时间可能较长,所以-XX:CMSInitiatingOccupancyFraction的设置要根据实际的情况。
标记清除法有个缺点就是存在内存碎片的问题,在CMS中存在相关的参数如下:
-XX:+UseCMSCompactAtFullCollection 设置在CMS回收完成之后进行一次碎片整理
-XX:CMSFullGCsBeforeCompaction 设置进行多少次CMS回收之后,对内存进行一次压缩
G1回收器:全称Garbage-First,它是在jdk1.7中提出的垃圾回收器,长期目标是为了取代CMS回收器,G1回收器拥有独特的垃圾回收策略,G1属于分代垃圾回收器,区分新生代和老年代,依然有eden和from/to区,它并不要求整个eden区或者新生代、老年代空间都连续,它使用了分区算法。
并行性:G1回收期间可以多线程同时工作
并发性:G1拥有与应用程序交替执行能力,部分工作可以与应用程序同时执行,在整个GC期间不会完全阻塞应用程序
分代GC:G1是一个分代收集器,但是它兼顾新生代和老年代一起工作,之前的垃圾收集器他们或者在新生代工作,或者在老年代工作,这是一个很大的不同。
空间整理:G1在回收过程中,不会像CMS那样在若干次GC之后需要进行碎片整理,G1采用了有效复制对象的方式,减少空间碎片。
可预见性:由于分区的原因,G1可以只选择部分区域进行回收,缩小了回收的范围,提高了性能。
-XX:+UseG1GC 使用G1收集器
-XX:MaxGCPauseMillis 指定最大停顿时间
-XX:ParallelGCThreads 设置并行回收的线程数量
欢迎关注个人微信公众号“我爱编程持之以恒”
