一个MySQL连接问题的优化过程
这是学习笔记的第 2008 篇文章
今天有一个开发同事反馈说通过sqoop在大数据和MySQL之间同步数据的时候,报了一个连接失败的错误。
org.apache.hadoop.mapred.YarnChild: Exception running child : java.io.IOException: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.
顺着这些错误日志定位发现是大数据集群的新增节点无法访问MySQL导致。
经过梳理,发现这个连接的问题竟然和大数据集群操作有关。问题的过程是这样的:
大数据集群管理员新增了集群节点,对于分布式系统来说这是对业务透明的。
sqoop做数据流转的时候,恰好数据就在新增的节点上面,但是新增节点是没有访问MySQL的权限的,也就导致了我们开始时所说的问题。
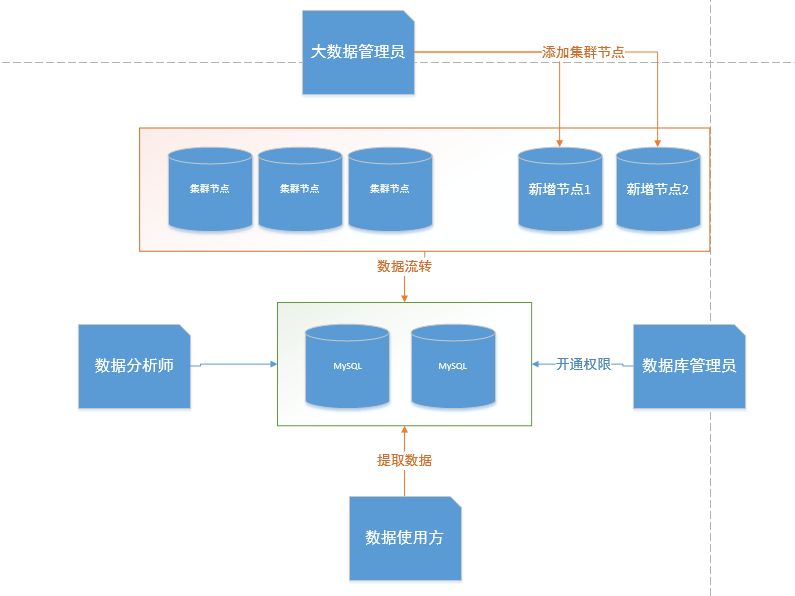
对于这个问题,我们划分了4个角色,也是归属于4个不同的小组,彼此独立:
1)大数据管理组,集群节点的操作对于业务来说应该是透明的。
2)数据分析组,他们使用大数据集群,同时做数据流转的工作,对他们来说对于大数据集群的节点也是不关心的
3)数据库管理组,因为涉及到大数据到数据库的数据流转,DBA不知道大数据新增节点会涉及哪些数据库的权限变更。
4)数据业务组,他们使用最终的数据,对于他们来说只识别MySQL端
通过上面的一些角色和基本的分工,我们发现看起来是一个简单的问题,实际上是一个流程化的工作。上游不关心下游的使用,下游不知晓上游的变更,信息在流转中出现了缺失。
所以这个问题只是冰山一角,这映射出权限管理的一个通用的问题。对于上下游之间如何衔接和有效配合,我们多个小组做了讨论,初步的想法就是通过邮件的方式来建立这个流程,我们可以叫它是一个邮件链。信息由变更发起方通知,在这里就是大数据管理组,他们发布变更通知的时候,需要同时附带关联的MySQL集群,而这个信息显然不是大数据管理组来获得,而是应该有数据分析组来提供,对于他们来说应该需要明确数据流转的细节,而这个邮件信息初步确认之后,DBA收到这个邮件信息之后就会根据提供的信息开通相应的权限,而这个操作对于数据使用方来说是无感知的。
而这个问题仅仅是个开始,我们在处理权限问题的时候发现这个数据流转相关的单表有近400G,数据量在17亿左右。 对于MySQL来说,这个表的数据操作就是一颗不定时炸弹,一旦出现慢查询,那执行时间都会无限放大。
经过分析,我们大体理解了这几个大表的业务逻辑,大数据集群会去做计算,把计算后的结果数据导入MySQL中,这个导入的频率是T+1,也就意味着这是一个延迟1天的数据流转操作,比如今天是6月13日,那么流转的数据是6月12日这一天的。 所以按照数据的生成规律来看,使用典型的周期表业务就可以支持这种数据管理方式。
假设表为test_data,则周期表为:test_data_20190601,test_dat_20190602,test_data_20190603
和业务方做了初步的沟通,会发现周期表可以实现这个需求,但是对于目前的问题来说,需要相关的多方都改动业务逻辑代码,要完成这个联调还是需要花费一些时间的。 所以业务同学是倾向于通过删除数据的方式,尽可能保留原来的表名,我们经过沟通提出了潜在的问题,即数据流转写入的时候,假设数据有300万,则在binlog中会记录这300万的数据变化,而要删除以前的数据,假设也有300万,则binlog也会记录这300万的数据变化,这样一来数据的代价就是600万,而使用周期表的方式,我们就可以很容易的控制表的数据,确认删除的数据使用drop产生的binlog很少,所以从功能和性能角度来说,我们是不建议在一张大表中存放数据按照时间维度来删除的。
在当前的情况下,尽可能让双方都不做变更,我们可以间接的实现周期表,即表test_data名字不变,在20190603的这一天,写入test_data的数据是20190602的数据,则DBA在数据流转之后,就可以把表test_data改名为20190602,而复制完整的表结构信息新建表test_data.
这样一来整个数据库中的列表信息如下:
test_data
test_data_20190601
test_data_20190602
test_data_20190603
使用这种方式之后,对于业务使用经过确认是不需要改动的,但是对于DBA来说可以更加有效的管理数据。
下午的时候经过确认把原来的近400G的大表做了rename操作,整个数据流转的过程就更加轻量了。
