使用flashback query巧妙抽取指定数据(r5笔记第75天)
在生产环境中存在着大量的数据,和业务是密切相关的。比如系统中的某个业务流程出现了问题,如果想复现就会显得非常困难,甚至是不太可能的,比如电信系统中存在着大量的客户信息,相关联的表的数据量都基本在千万,亿级。如果要抽取,是全量抽取还是增量抽取。全量抽取可行,但是实际操作起来也不现实,如果要在测试环境中复现,可能需要大量的存储空间,而且相比来说也显得有些浪费,同事对于数据安全也是很大的隐患,毕竟我们不愿意客户信息这么轻易的暴露出来。如果增量的,问题的关键是怎么增量,比如从100万客户信息中抽取一个客户的信息,按照这个要求抽取某个表的数据还是可行,但是如果很多表之间存在依赖,存在关联,很多表抽取就会是一个很大的困扰,毕竟对于dba来说,要控制这个抽取过程而且还要兼顾业务,是很困难的。除此之外,还有一个主要问题就是在大批量数据中,怎么保证数据的事务一致性,比如存在表customer,subscriber,一个客户customer下可以对应多个用户subscriber,如果我们定位customer下的某个subscriber,这个时候,可能会有很多的事务在运行,我们需要同时保证subscriber相关的表的数据在同一个事务内是一致的。这对于抽取数据复现来说就是最基本的数据保证了。所以从抽取难度上和数据完整性上我们需要做一些工作。其实我们可以巧妙的利用flashback query来完成这个看似不可能完成的任务。我画了如下的图标进行解释。首先在数据源头的schema中存在着一些表,我们假设为table1,table2,table3...table1,table2,....这些表之间是存在着一些对应关系的。比如customer表的customer_id和subscriber表中的customer_id是对应的。subcriber表的subscriber_id和产品订购表是存在关联的,这些关联关系至关重要。即图中绿色的部分,这些都是一些表关系的定义,根据表中的字段进行映射。这样一个几百万数据的表根据映射关系可能就会过滤出来很少的数据来。这个抽取的过程怎么保证事务数据的完整性呢,这个时候就需要flashback query来完成。在抽取的时候我们会根据需要的时间戳来作为数据抽取的基准时间,所有的关联的表都会基于这个时间戳进行抽取。比如对于customer表,我们提供了customer_id=100抽取customer表就会是下面的样子。select * from customer as of timestamp xxxxx where customer_id=100;如果customer和subscriber的映射关系是customer_id则抽取subscriber就是select *from subscriber as of timestamp xxxxx where customer_id=100;以此类推,中间的蓝色柱子就代表抽取的基线时间。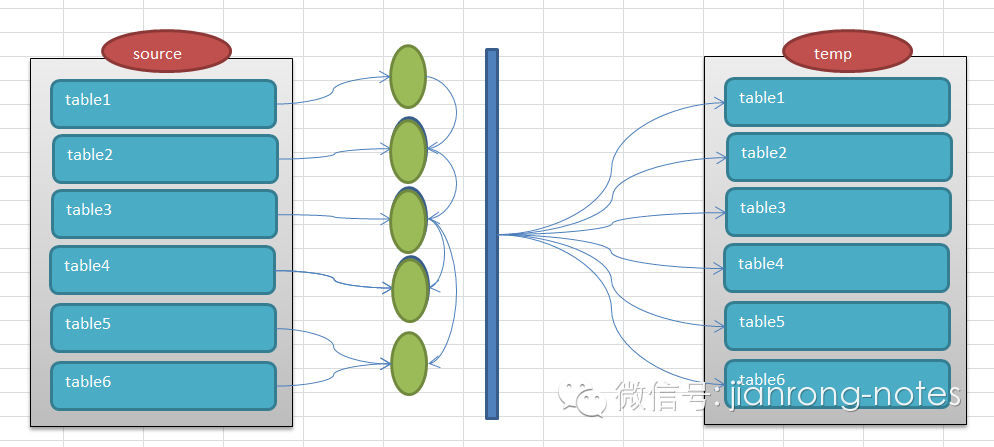 如果抽取的进展顺利,这些数据是能够很快抽取抽起来的,那么问题来了,怎么生成dump文件呢,这个时候我们可以考虑使用一个临时的schema来存在这些抽取的表数据,因为抽取的数据量是很小的,所以可以考虑使用一个临时的schema,直接在这个schema中导出数据即可。即图中右半边的temp schema。有了临时的schema,那么抽取的数据是怎么放到临时的schema中呢,还是使用最普通的ctas对于customer表使用create table customer nologging as select * from customer as of timestamp xxxxx where customer_id=100;select *from subscriber as of timestamp xxxxx where customer_id=100;
如果抽取的进展顺利,这些数据是能够很快抽取抽起来的,那么问题来了,怎么生成dump文件呢,这个时候我们可以考虑使用一个临时的schema来存在这些抽取的表数据,因为抽取的数据量是很小的,所以可以考虑使用一个临时的schema,直接在这个schema中导出数据即可。即图中右半边的temp schema。有了临时的schema,那么抽取的数据是怎么放到临时的schema中呢,还是使用最普通的ctas对于customer表使用create table customer nologging as select * from customer as of timestamp xxxxx where customer_id=100;select *from subscriber as of timestamp xxxxx where customer_id=100;