我所理解的DirectX Ray Tracing
我所理解的DirectX Ray Tracing
https://zhuanlan.zhihu.com/p/96636069
我所理解的DirectX Ray Tracing
![]()
xiaocai
0 前言
经过三个月对DirectX Ray Tracing(DXR)[1]的反复阅读,对DXR的流程有了较全面的的理解。这篇文章记下自己已有的一些理解,顺便梳理下引入Ray Tracing对GPU底层架构的可能影响,作为备忘。
1 什么是DXR?
1.1 先从光栅化说起
我们知道,在window上微软制定和维护着一系列GPU的3D渲染标准,包括DirectX 9,DirectX 10和DirectX11,都属于光栅化流水线。

图1 DirectX11 流水线
渲染的结果是一张图像,光栅化和Ray Tracing最大的不同在于生成每个像素的方式。光栅化流水线是依次把每个Primitive(以三角形为主)的的顶点投影到屏幕上,然后算出三条边的方程,进而得知哪些像素在其内部,最后将它们进一步做shading。

图2 三角形的光栅化:将三个顶点投影到屏幕,计算边方程,算出内部像素,
在光栅化流水线上,应用根据需要把每一帧场景拆分成一个或多个Draw。每个Draw负责渲染一系列三角形,同一个Draw所有渲染在相同的Context下进行,即Draw与Draw之间可能会发生Context切换,但同一个Draw内不会有Context的切换。这里的Context是指广义上API设置的可以影响GPU内部渲染的一切状态,例如使用什么Shader,是否开启Multi-Sample,使用了哪张Texture和对应的sampler等等。
1.2 然后再说Ray Tracing
基于Ray Tracing的渲染方式则采用截然不同的方法——给定一帧图像中所有的场景Geometry,通过在Camera的位置向屏幕每个像素位置各发出一条光线,并对每条光线hit到的最近物体做渲染,获得的Color即每个像素的结果。

图3 三角形的Ray Tracing
Rasterizer作为一个GPU固定硬件已久,而相比之下,Ray Tracing并没有所谓的配套硬件或一套标准去支持它。一直以来,Ray Tracing的实现以CPU为主,也可通过GPU的ALU加速完成部分功能,各种实现手段五花八门。
光栅化最显著的优点是性能高,一个是渲染速度快(高帧速率),再一个是Memory的Coherence好(低功耗)。在芯片工艺不成熟,架构不完善的过往,光栅化无疑是GPU最佳选择,但光栅化的渲染原理与人眼的视觉感知并不相符,以至于需要用shadow mapping等方法去模拟阴影效果,而类似Global Illumination或Ambient Occlusion复杂些的效果则捉襟见肘。
Ray Tracing则天然符合人的视觉特点,例如只需要从物体往光源发出一条光线,看看是否被场景中的任何物体挡住,就知道是否在阴影之中;通过发出反射、折射光线实现Global Illumination;通过发出多条随机光线看看是否被周围物体挡住来实现Ambient Occlusion等等。Ray Tracing更具有真实感,然而光栅化的两个优点却对应地是Ray Tracing的两个硬伤:
- Ray Tracing的渲染速度不快,因为每条光线都需要与整个场景求交(尽管有诸如BVH/kd-tree的优化手段)。
- 一旦光线间的相关性不强,Memory的Coherence会变差。
当然,Ray Tracing不止这两个硬伤(后面会慢慢提到)。随着条件的成熟(说白了就是如果市场上有买家愿意支付),成熟到允许通过ALU的大量堆叠,辅以各种优化来降低这些硬伤,那么在GPU中支持Ray Tracing便是一种趋势。
1.3 进入正题——DXR的流水线
啰嗦了一段无用的套话,终于进入正题了。DXR是DirectX12里面一个可选的标准,规范GPU中如何实现Ray Tracing。其目的是辅助光栅化(光栅化依旧是渲染主力),在需要的场合实现更真实的光影渲染。

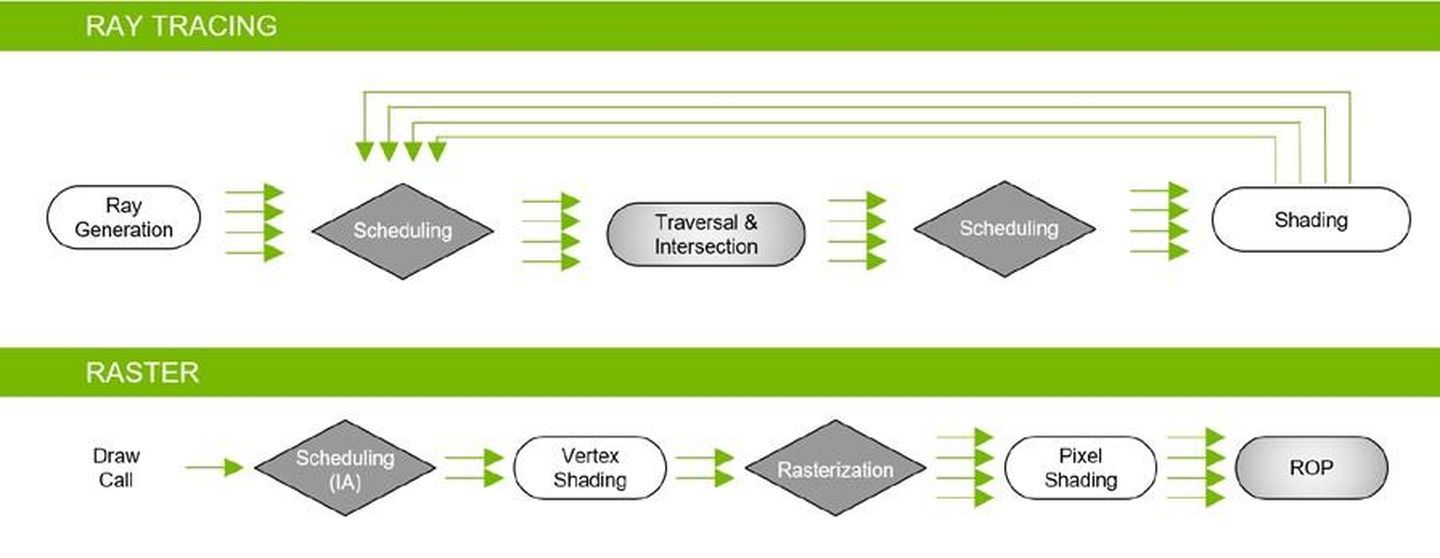
图4 基本的DXR流水线,只出现一次TraceRay()调用
在图4的DXR流水线中,可以看到它所包含的五个Shader(蓝色方框)。
- Ray Generation Shader
Ray Generation Shader负责向执行Traversal & Intersection的硬件(即遍历加速结构&求出光线与几何体交点,不妨称其为T&I硬件)发出追踪光线的请求,并把shading结果保存到framebuffer中对应的像素上。我们看下DXR specification给的简单例子
struct SceneConstantStructure { ... };
ConstantBuffer<SceneConstantStructure> SceneConstants;
RaytracingAccelerationStructure MyAccelerationStructure : register(t3);
struct MyPayload { ... };
[shader("raygeneration")]
void raygen_main()
{
RayDesc myRay = {
SceneConstants.CameraOrigin,
SceneConstants.TMin,
computeRayDirection(SceneConstants.LensParams, DispatchRaysIndex(),
DispatchRaysDimensions()),
SceneConstants.TMax
};
MyPayload payload = { ... }; // init payload
TraceRay(
MyAccelerationStructure,
SceneConstants.RayFlags,
SceneConstants.InstanceInclusionMask,
SceneConstants.RayContributionToHitGroupIndex,
SceneConstants.MultiplierForGeometryContributionToHitGroupIndex,
SceneConstants.MissShaderIndex,
myRay,
payload);
WriteFinalPixel(DispatchRaysIndex(), payload);
}
其中TraceRay()是发出追踪光线请求的函数,接收的参数如下
Template<payload_t>
void TraceRay(RaytracingAccelerationStructure AccelerationStructure,
uint RayFlags,
uint InstanceInclusionMask,
uint RayContributionToHitGroupIndex,
uint MultiplierForGeometryContributionToHitGroupIndex,
uint MissShaderIndex,
RayDesc Ray,
inout payload_t Payload);这些参数与后面的流水线密切相关,不妨详细地理解它们:
1)AccelerationStructure
这个是BVH的地址,很好理解,有了它T&I硬件就可以读到BVH根节点,而BVH每个节点都含有子节点的Id,所以有了这个地址,T&I硬件就能读取任意节点。
2)Ray
描述光线的原点,方向和可见区间(Tmin, Tmax),给T&I硬件做ray-box或ray-triangle相交测试。通常原点即Camera的位置,可以由应用指定并给到Shader里。而方向则由原点指向对应的像素。需要注意的是,T&I要的是世界坐标系的方向,所以需要把每个像素的屏幕坐标先转化为NDC坐标,然后再做反投影变换,得到像素在世界坐标系下的坐标,从而得到最终的光线方向,如下面的这段简单的代码
// Generate a ray in world space for a camera pixel corresponding to an index from
//the dispatched 2D grid.
inline Ray GenerateCameraRay(uint2 index, in float3 cameraPosition,
in float4x4 projectionToWorld)
{
float2 xy = index + 0.5f; // center in the middle of the pixel.
float2 screenPos = xy / DispatchRaysDimensions().xy * 2.0 - 1.0;
// Invert Y for DirectX-style coordinates.
screenPos.y = -screenPos.y;
// Unproject the pixel coordinate into a world positon.
float4 world = mul(float4(screenPos, 0, 1), projectionToWorld);
world.xyz /= world.w;
Ray ray;
ray.origin = cameraPosition;
ray.direction = normalize(world.xyz - ray.origin);
return ray;
}
3)Payload
Payload属于inout类型,所以本质上是一个地址,这个地址会沿着流水线一直传到最后,Closest Hit Shader或Miss Shader会将shading的结果往这个地址里填,当光线完成TraceRay()所有工作返回,Ray Generation Shader便可以从payload中读出像素的shading结果。
4)MultiplierForGeometryContributionToHitGroupIndex和 RayContributionToHitGroupIndex
这两个参数的名字有点花哨费解,它们指的不过是光线类型的数量和当前光线的类型。到这里,有必要开始解释下DXR挑选shader执行渲染的机制。前面在光栅化的介绍中提到,光栅化的Shading Context是Per-Draw的,每个draw所用到的shader对所有三角形而言是固定,一个场景如果需要使用不同的shader,需要将其分成多个draw。而DXR的Shading Context是Per-Geometry的——每个Geometry可以有自己的Intersection Shader,Any Hit Shader和Closest Hit Shader,DXR将这三种Shader统称为Hit Group。让这三种Shader Per-Geometry分别使得每个Geometry可以有各自的几何形状,透明属性,Shading过程。除了Hit Group,Shading Context还包含shader使用到的resource,例如texture,sampler,constant等,DXR将这些resource称为Root Arguments,Hit Group和Root Argument统称为Shader Record。在进入流水线之前,应用要为每个Gemotry指定各自的Shader Record,这些Shader Record放在一段叫Shader Table的Memory中:
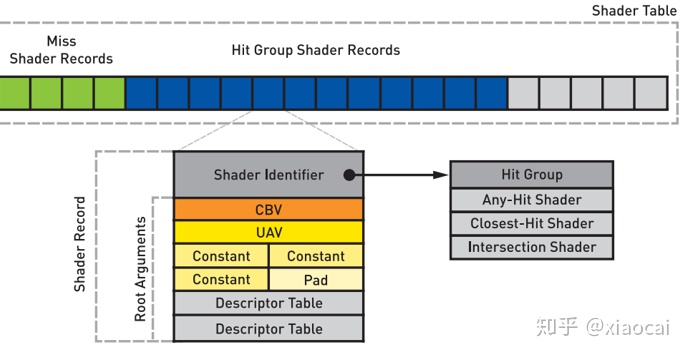
图5 Hit Group的Shader Table由Shader Record组成,每个Shader Record包括三个shader的地址和Root Argument
而Ray Tracing可以有多种光线类型,它们Hit到同一个Geometry时原则上需要触发的行为也是不同的。例如对于从Ray Generation Shader发出的Primary Ray,如果hit到某个Geometry,它在Closest Hit Shader可能需要往光源发出一条Shadow Ray;而对于Shadow Ray而言,它在Closest Hit Shader可以很简单,比如往PayLoad写个标记,表示被挡住了没被照到。所以,应用为每个Geometry指定的Shader Record数量,等于光线类型的数量。到这里,Shader Table的layout就出来了(假设光线类型数量为N):
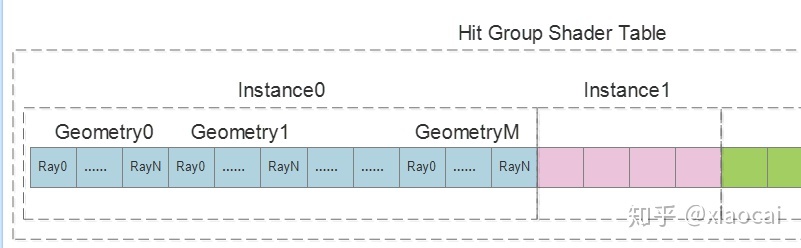
图6 每个Instance由一个或多个Geometry,而每个Geometry可以指定多个Shader Record,其数量等于光线类型的数量
这里有个Instance的概念在后面会提到,当T&I硬件找到了光线hit到的最近三角形后,它会根据该三角形所属的Instance读出该Instance在Shader Table中的地址偏移IOffset,根据所属的Geometry在Instance内的Id知道该Geometry的地址偏移:GOffset=N*GeomtryId,不妨用ROffset表示当前的光线类型,则最终需要使用的Hit Group Shader Record在Shader Table中的序数为:IOffset + GOffset + ROffset。好的,回头看,前面两个参数的作用也就清楚了。
5)MissShaderIndex
Miss Shader不是Per-Geomotry,所以它的寻址很简单,只需要提供MissShaderIndex对应其光线类型。如果未发现任何hit,T&I硬件直接在Miss Shader的Shader Table中选择第MissShaderIndex个Shader Record,交给SM去执行。
6)RayFlags/InstanceInclusionMask
这两个标记涉及一些细节问题,在这里就不展开了。
- Intersection Shader
Intersection Shader用于测试光线是否和自定义几何体相交。DXR支持两种图元类型:三角形和自定义图元。每当Traversal经过遍历找到一个被光线hit到的叶子节点时,对于三角形,T&I硬件会利用固定的ALU测试光线是否跟节点里的三角形相交并计算重心坐标;对于自定义图元,T&I硬件发出一个执行Intersection Shader的请求,由Intersection Shader负责执行自定义的相交测试并计算自定义的attribute。Intersection Shader每当找到一次hit时会通过ReportHit()函数把该Hit的距离以及attribute告知T&I硬件:
template<attr_t>
bool ReportHit(float THit, uint HitKind, attr_t Attributes);
T&I硬件用该距离跟当前最近的hit做比较(在这之前可能会调用Any Hit Shader确认是否为有效的hit,详见后文),如果是更近的hit,则更新hit的状态,在更新状态时会结合Ray/Instance的标记,最终可能的状态是:接受/接受并停止搜索/忽略。注意,ReportHit的返回类型是bool,因此T&I硬件需要把这个状态反馈给Intersection Shader。对于接受和忽略,Instersection按true和false执行对应的控制分支路径,对于接受并停止搜索,则提前退出Shader。如果想简单了解Intersection Shader的代码细节,微软提供的这个例子值得一读[2]

图7 通过Intersection Shader实现复杂的参数化几何体
- Any Hit Shader
当T&I找到(或者Intersection Shader找到)一个更近的hit,且对应三角形(或自定义图元)并不是opaque,同时Hit Group里指定了Any Hit Shader,那么T&I需要发出一个执行Any Hit Shader的请求,确认这次hit是否真的有效。Any Hit Shader通常会执行Alpha Test之类的操作,然后告知T&I一个状态:接受/接受并停止搜索/忽略,一个简单的例子:
[shader("anyhit")]
void anyhit_main( inout MyPayload payload, in MyAttributes attr )
{
float3 hitLocation = ObjectRayOrigin() + ObjectRayDirection() *
RayTCurrent();
float alpha = computeAlpha(hitLocation, attr, ...);
// Processing shadow and only care if a hit is registered?
if (TerminateShadowRay(alpha))
AcceptHitAndEndSearch(); // aborts function
// Save alpha contribution and ignoring hit?
if (SaveAndIgnore(payload, RayTCurrent(), alpha, attr, ...))
IgnoreHit(); // aborts function
// do something else
// return to accept and update closest hit
}
我们看到,Any Hit Shader接收PayLoad和attribute两个参数:
(1) PayLoad
在上面的例子中,如果测试发现光线hit到是透明的位置,在发出忽略状态之前,Any Hit Shader把alpha保存到PayLoad里,Closest Hit Shader可能用来做alpha blending。
(2) Attribute
自定义的attribute,给Closest Hit Shader做shading用,一般不建议自定义过大的attribute。
- Closest Hit Shader/Miss Shader
对于每条光线,如果在遍历BVH的过程中找到了有效的hit,T&I硬件会保存最近的hit,并在整个遍历结束后发出Closest Hit Shader的请求;如果没有找到任何hit,T&I硬件会发出Miss Shader请求。除了常规的Shading,这两个Shader最强大的功能在于它们也能调用TraceRay()请求追踪新的光线,满足阴影判断,反射,折射等效果需求。
1.4 再谈DXR流水线的“硬伤”
DXR的五种主要的Shader本质上是一种Compute Shader,运行在现有的硬件ALU上面(例如NVidia GPU中的SM)。在了解各种硬伤之前,先粗略了解下SIMD的特点,使用Nvidia的术语,以一个含有16条车道的SM为例,它允许48个Warp在调度单元的控制交替地使用这16条车道执行指令。每个Warp=32个线程(例如对于Vertex Shader/Pixel Shader而言,1个warp对应32个vertex/Pixel,实际上要分成两组在SM执行)。当某个Warp执行了带有延迟的指令(通常是访问memory)时,调度单元会让当前优先级最高并且准备就绪的Warp继续使用这16条车道,从而尽可能地藏住延迟。
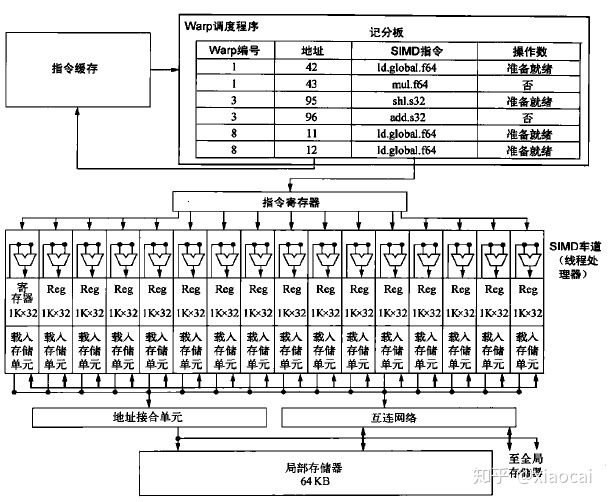
图8 SM(Stream Multiprocessor,流处理器)的简化图,图片来自《计算机体系结构量化研究方法》
硬伤1. 同一个Warp内光线的收敛一致性较差
SIMD上每条车道对应一条光线,我们知道,SIMD的特点在于它的执行时间取决于最久的车道。不同于光栅化流水线执行Shader的一气呵成,DXR的Shader存在依赖关系——例如,当Ray Generation Shader调用TraceRay()后,它需要等待后面的Closest Hit Shader或Miss Shader执行完后才能继续下一行代码;当Intersection shader调用了ReportHit()后,它可能需要等待Any Hit Shader返回一个状态。跨度越长,意味着一个Warp的光线收敛性越可能不一致。
硬伤2. Warp间的访存一致性较差
对于随机发出或递归深度较大的光线,通常所hit到的Geometry不一致。在一方面,这直接导致访问Texture时的数据Coherence不高。另一方面,前面提到,DXR的特点在于每个Geometry拥有自己的Context,这些Context通常需要在Shader执行之前加载到on-chip上面,以获得尽可能高的效率。而如果不同的Warp间hit到的Geometry不一致,则Warp切换时意味着存在on-chip的Context需要频繁被更新,这导致了更多的Memory访问。
硬伤3. 藏不住延时的TraceRay(),增加了切换Warp的代价
在光栅化的流水线里,最耗时的sample/load指令,需要的时间是从memory load数据到CRF所消耗的时间,而一般可以通过L1/L2 Cache,Tiling等优化方法降低平均时间。除此之外,SM中为每个Warp准备了各自的CRF(Common Register File)用于存储shader执行过程中的数据,当一个Warp被高延迟操作挡住,则调度其他Warp使用ALU。对于就绪的Warp,借助CRF,可低开销地被重新唤醒。
而DXR流水线则复杂很多,除了Ray Generation Shader,DXR还允许Closest Hit Shader/Miss Shader调用TraceRay()发出新的光线,以实现光线的路径追踪功能,这种递归性增加了shader切换的复杂度。想象一下,那么当Ray Generation Shader/Cloest Hit Shader/Miss Shader调用TraceRay()发出新的光线后,接下去就是漫长的等待——负责Traveral和Intersection的硬件(例如NVidia的RT Core)会多次从memory中load BVH的数据,然后执行相交测试,这个过程还可能发起Intersection Shader或Any Hit Shader,其必然发起Closest Hit Shader/Miss Shader,甚至可能继续调用TraceRay(),也就是递归跟踪。
DXR支持的最深递归深度是32,所以如果没有特殊处理,那么最多有32层Shader在同时在占用CRF,但从官方数据[3]看,RTX并没有因为支持Ray Tracing而增加了很多CRF。所以我猜想(只是猜想,有熟悉RTX架构的感谢指出),当一个Warp调用TraceRay()后,CRF的所有数据需要被保存到Memory里;当这个Warp被再次唤醒,则从Memory读回数据到CRF。所以,这无疑增加了切换Warp的代价。
2. T&I
关于Traversal&&Intersection,由于之前已经写过了笔记。这里就不重复细节了,简单得补充几点DXR的特点。DXR的BVH分为Top Level和Bottom Level[4],每个Top Level BVH的叶子节点为一个Instance,对应一个Bottom Level BVH的根节点。这种结构允许Geometry的Instancing,以及performance和灵活性的折中。Top Level处于世界空间,而Bottom Level处于Object空间,应用需要为每个Geometry指定一个ObjectToWorld的矩阵。
- Bottom Level的每个BVH完成构建后,需要把根节点的包围盒从Object转换到世界空间(注意,这可能会导致包围盒变大,可能有优化的方法吧,我暂时是没研究过)。然后在世界空间中构建Top Level。
- 在Traversal的过程中,我们知道TraceRay()给的光线是世界坐标系的,所以一开始光线直接在Top Level做遍历,当它找到了一个hit到的叶子节点时,则将光线从世界空间变换到Object空间中(乘以ObjectToWorld的逆矩阵),进入到Bottom Level的BVH中继续遍历。
3. BVH的构建
Traversal的目的找出光线hit到的最近三角形,BVH是将整个场景中所有三角形的包围盒组织成具有等级结构的树状结构,来减少Traversal的计算量。
3.1 BVH构造算法
在应用提交BVH的构造请求后,Driver负责调度构造的工作,构造过程中并行度很高的工作(例如计算包围盒,排序等)可以通过GPU加速。另外,利用异步计算有可能隐藏构造消耗BVH消耗的时间[5]。构造本质上是由软件完成的,因此允许厂商不断优化BVH的质量或修复bug,用户只需更新Driver。
给定整个场景所有三角形,支持DXR的GPU至少需要有3种不同特点的BVH构造算法。
- 当应用指定PREFER_FAST_BUILD标记时,则使用构造速度尽可能快的算法;
- 当应用指定PREFER_FAST_TRACE标记时,GPU使用能取得高质量的算法,适用于构建静态几何体的BVH;
- 若不指定以上标记,则GPU使用默认的构造方法,该方法在构造速率和质量上取折中。
那么究竟什么算法称得上高速率或者高质量?RTX用什么算法我当然是不知道的,这里我参考了embree[6]来讲解下。embree是Intel开发的CPU Ray Tracing开源框架,它刚好支持上述三种不同要求的BVH构造算法,我们以二叉树为例介绍下这三种方法。
3.1.1 高速率构造算法——LBVH
LBVH算法[7](Linear BVH,也叫Morton BVH),其思想是在xyz三个维度上交替地将包围盒等分成两个子空间,将两个子空间上的三角形分到两个子节点,下图是一个二维的例子:
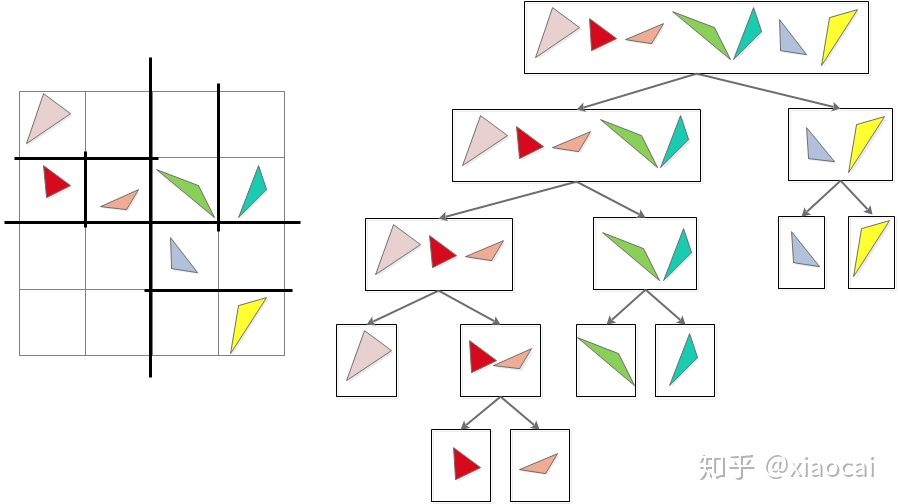
图9 LBVH通过二分空间分割每个节点的三角形
LBVH算法的高效性在于它能借助Morton Code快速分割。什么是Morton Code呢?这里以二维为例,对于任意包围盒,我们在xy维度上分别四等分,每个区间的坐标依次为0,1,2,3,从而得到16个格子的二维坐标:
对于每个坐标,将x和y的二进制位做interleave(你一位我一位交替拼起来)后,便得到4比特的Morton Code: (这里的下标k表示第k比特),结果如下图:
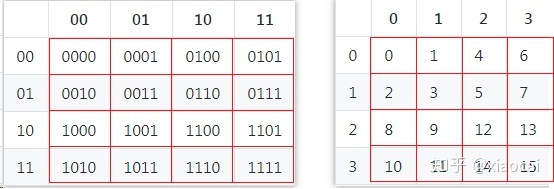
图10 Morton Code由坐标的Interleave获得
可以看到,把这些格子按照Morton Code进行排序后,将得到一种Z字形路径,如下图左1。如果把等分区间的粒度提高,比如分成 个区间,那么结果如下图左2,左3。

图11 左1为4比特Morton顺序(含16格); 左2为6比特Morton顺序(含64格);左3为8比特Morton顺序(含256格)
按Z字形排序后的Morton Code,有一个有用的特点:前一半Code和后一半Code的最高位分别都是0和1。这说明只要在这条路径上找出最高位“突变”的那两个格子,就找到了该维度(给了这一比特的那个维度)上的等分面。
Embree实现的LBVH算法分两个步骤,第一个步骤是Morton Code排序:
- 首先计算出所有三角形包围盒的中心坐标,以及所有中心坐标形成的包围盒,即比较出三个维度上的两个最值,得到(xmin,ymin,zmin)及(xmax,ymax,zmax)。
- 将这个盒子在三个维度上1024等分,从而形成 个格子。对于每个三角形,以其包围盒中心所在的格子坐标计算出Morton Code,然后根据Morton Code将所有三角形排序,得到排好序的BVH根节点
第二个步骤是自顶向下,递归地将每个节点分割为两个子节点,直到分出的节点符合构成叶子节点的条件(所含三角形数量少于某个阈值,或者BVH的深度超过某个阈值),对于任意含N个三角形的节点
- 假设第一个和最后一个三角形的Morton Code分别为 ,找出最大的k,两者的第k比特不一致: 。
- (可以用二分法)找出i,满足 ,然后以第i个三角形为边界二分为两个子节点
LBVH的介绍就到这了,其实Morton Order是一个很有趣的东西,它贯穿着光栅化流水线的后半部分,通常为了提高GPU访问texture的locality,光栅化出的Pixel,以及Pixel Shader吃进去的Quad都遵守着Morton Order(有点偏题了,有时间再单独讨论这个问题)。
3.1.2 折中构建算法——Binning SAH
LBVH是一种很简单的分割,不过它并不保证高质量,至少它的算法理念没有考虑质量问题。事实上,最高质量的BVH是能使Traversal取得(在数学期望上)最少计算量的结构。对于大型的场景,这个最优解很难直接求出来,只能利用heuristic的方法近似求之——在自顶向下递归分割每个节点时,使用最优分割。因为光线方向是变化的,这里的最优分割是数学期望意义上的。把一个节点Q分割成L和R后,遍历L和R所需cost的期望值为
上面的SA()表示一个节点包围盒的表面积,即六个面的面积和。 和 分别遍历L和R所需要的Cost,取得最小Cost的分割即最优分割。考虑到 和 可以近似认为与节点中三角形数量成正比,并且父节点的表面积 对所有分割都一样,上面的式子可简化成
其中 和 分别是子节点L和R各自三角形的数量。到这里,所讨论的构建算法已经很清晰了。对于每个节点
- 选择其中一个维度,将节点内三角形的包围盒中心在该维度上排序
- 按顺序遍历排序后的每个三角形,以遍历到的三角形为分割边界,计算该分割的Cost
- 以取得最小Cost的分割作为该维度的分割结果
该算法被称为Surface Area Heuristic (SAH),实际应用中,可以在xyz三个维度上都把上面步骤走一遍取其最优,也可只算节点包围盒(为了方便表示,当提到节点的包围盒时,我指的是该节点内所有三角形包围盒的并集)长度最大的那一维。在下面的例子中,当以x维度上的第七个三角形(即红色三角形)作为分割时,能取得最小Cost。可以看出,SAH的理念是用最小的包围盒圈住最多的三角形,使分割尽可能紧凑。
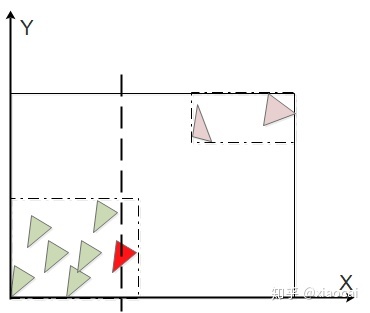
图12 通过SAH分割三角形
SAH给遍历带来的高质量是以提高构建复杂度为代价的——含N个三角形的节点需要计算N次Cost。Binning SAH[8]是一种优化版本的SAH算法,其思想是将节点包围盒在某个维度上K(比如32)等分,然后以这(K-1)个等分点作为分割边界(将两侧的三角形分别分到两个子节点)计算(K-1)个Cost,取Cost最小的分割。分割复杂的场景的BVH节点时,K远小于N。当然,最后的分割可能只是个次优解,比如三等分之前的例子:
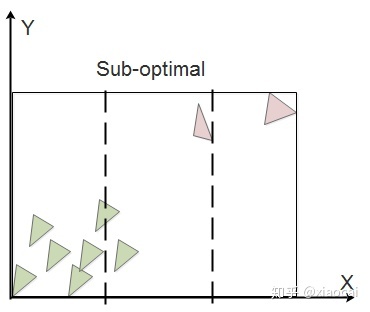
图13 通过Binning SAH分割三角形
尽管如此,相比它所减少的构建代价,Binning SAH所增加Traversal Cost其实并不大,在实际应用中它是更理想的构建算法,更有利于实现实时通畅的Ray Tracing。
3.1.3 高质量构造算法——Spatial-split SAH
当场景中存在大小不均匀的三角形时,经Binning SAH分割后两个子节点的包围盒可能存在重叠,如下图所示中的黄色部分,重叠导致它在两个子节点的Traversal中都消耗Cost。
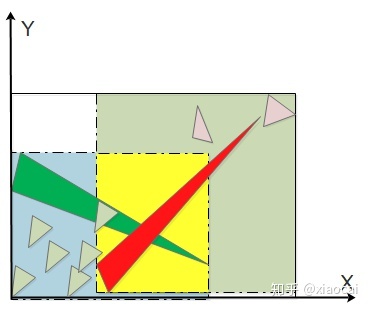
图14 两个子节点包围盒的重叠
Spatial-split SAH[9]是通过消除重叠问题来进一步提高binning SAH质量的算法,其理念是允许同一个三角形进到两个子节点中。对于每个节点,首先用Binning SAH求出最优的分割,如果被Binning SAH分出的两个子节点不存在包围盒重叠,那么分割结束。否则执行Spatial-split,其分割步骤是:
- Spatial-split:将节点包围盒在某个维度上K等分,在(K-1)个分割点上,任意三角形只要包围盒有部分在分割点左侧就分入左节点,只要有部分在分割点右侧就分入右节点。
- 计算出上述的(K-1)个Cost,取Cost最小的分割,如果这个Cost比Binning SAH的还要小,那么就采用Spatial-Split的分割结果
需要注意的是,在spatial-split SAH的分割过程中,需要分别将左/右子节点包围盒在该维度上的Max/Min与分割点的坐标做clamp,使两个子节点不存在包围盒重叠。回到之前的例子,通过spatial-split SAH可能按下图分割,其中绿色和红色的三角形都同时被分到两个子节点中:
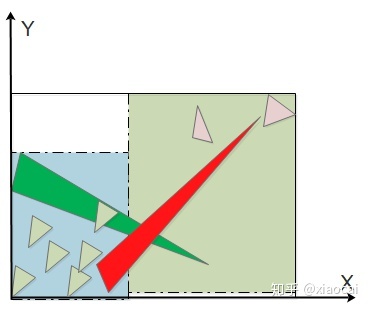
图15 通过spatial split消除子节点包围盒的重叠
Spatial-split SAH的BVH质量至少等于Binning SAH,当然,是以高大约出一倍的构建代价换取的。
3.2 关于多叉树
未完,待续……
参考
- ^https://microsoft.github.io/DirectX-Specs/d3d/Raytracing.html
- ^https://github.com/microsoft/DirectX-Graphics-Samples/blob/master/Samples/Desktop/D3D12Raytracing/src/D3D12RaytracingProceduralGeometry/readme.md
- ^https://devblogs.nvidia.com/nvidia-turing-architecture-in-depth/
- ^Distributed Interactive Ray Tracing of Dynamic Scenes
- ^https://devblogs.nvidia.com/rtx-best-practices/
- ^https://www.embree.org/
- ^Fast BVH Construction on GPUs
- ^On fast Construction of SAH-based Bounding Volume Hierarchies
- ^Spatial Splits in Bounding Volume Hierarchies
编辑于 2019-12-19
实时渲染
光线跟踪
DirectX 光线追踪(DXR)