一、MySQL操作补充
cur = coon.cursor(cursor=pymysql.cursors.DictCursor)
建立游标的时候指定了游标类型,返回的就是一个字典了。
fetchall() #获取到这个sql执行的全部结果,它把数据库表里面的每一行数据放到一个list里面
[ ['1','2','3'] ] [{},{},{}]
fetchone() #获取到这个sql执行的一条结果,它返回就只是一条数据
如果sql语句执行的结果是多条数据的时候,那就用fetchall()
如果你能确定sql执行的结果就只有一条,那么就用fetchone()
enumerate([list,list2]) #循环的时候,直接获取到下标,和值
for index,value in enumerate([list,list2]):#list2里面是什么?
print(index,vlaue)
fileds = ['id','name','sex','addr','gold','score'] for index,filed in enumerate(fileds): print(index,filed)
运行结果:
0 id 1 name 2 sex 3 addr 4 gold 5 score
一个返回数据库表头字段的函数:
import pymysql def my_db(sql,port=3306,charset='utf8'): import pymysql host, user, passwd, db = '118.24.3.40','jxz','123456','jxz' coon = pymysql.connect(user=user,host=host,port=port,passwd=passwd,db=db,charset=charset) cur = coon.cursor(cursor=pymysql.cursors.DictCursor) #建立游标,指定cursor类型返回的是字典 cur.execute(sql)#执行sql if sql.strip()[:6].upper()=='SELECT': # res = cur.fetchall() fileds = [] # for filed in cur.description:#cur.description可直接获取到建表时的字段描述信息,如('id', 253, None, 40, 40, 0, True) # fileds.append(filed[0]) fileds = [ filed[0] for filed in cur.description ] #和上面3行代码的意思是一样 print(fileds) # cur.fetchmany() #能传入一个数,返回多少条数据 res= 'xx' else: coon.commit() res = 'ok' cur.close() coon.close() return res res = my_db('select * from users_info limit 10;')#limit用于指定返回的数据条数 print(res)
运行结果:
['id', 'username', 'passwd'] xx
enumerate函数:同时获取到list的下表和值
fileds = ['id','name','sex','addr','gold','score'] for index,filed in enumerate(fileds): print(index,filed)
运行结果:
0 id 1 name 2 sex 3 addr 4 gold 5 score
练习:通用数据库导出到EXCEL函数
import pymysql,xlwt def export_excel(table_name): host, user, passwd, db = '118.24.3.40', 'jxz', '123456', 'jxz' coon = pymysql.connect(user=user, host=host, port=3306, passwd=passwd, db=db, charset='utf8') cur = coon.cursor() # 建立游标,指定cursor类型返回的是字典 sql = 'select * from %s ;'%table_name cur.execute(sql) # 执行sql fileds = [filed[0] for filed in cur.description] #所有的字段 all_data = cur.fetchall()#所有的数据 book = xlwt.Workbook() sheet= book.add_sheet('sheet1') for col,filed in enumerate(fileds): #写表头的 sheet.write(0,col,filed) row = 1 #行数 for data in all_data: #data为每一行数据 for col, filed in enumerate(data): # 控制列写入 sheet.write(row, col, filed) row+=1#每次写完一行,行就加1 book.save('%s.xls'%table_name) export_excel('app_student')
二、操作Excel
修改Excel:
import xlrd from xlutils import copy book = xlrd.open_workbook('app_student.xls') #先用xlrd模块,打开一个excel new_book = copy.copy(book) #通过xlutils这个模块里面copy方法,复制一份excel sheet = new_book.get_sheet(0) #获取sheet页 lis = ['编号','名字','性别','年龄','地址','班级','手机号','金币'] for col,filed in enumerate(lis): sheet.write(0,col,filed) new_book.save('app_student.xls')
读取Excel:
import xlrd book = xlrd.open_workbook('app_student.xls') sheet = book.sheet_by_index(0)#根据索引获取sheet页 # sheet2 = book.sheet_by_name('sheet1')#根据名称获取sheet页 print(sheet.cell(0,0).value) #指定sheet页里面第一行和第一列获取数据 print(sheet.cell(1,0).value) #指定sheet页里面第2行和第1列获取数据 print(sheet.row_values(0)) #获取到第1行的内容 print(sheet.row_values(1)) #获取到第2行的内容 print(sheet.nrows) #获取到excel里面总共有多少行 for i in range(sheet.nrows): #知道行数后,循环获取到每行数据 print(sheet.row_values(i)) print(sheet.ncols) #总共多少列 print(sheet.col_values(0)) #取第几列的数据
三、操作Redis
redis是一个nosql类型的数据库,数据都存在内存中,有很快的读写速度,python操作redis使用redis模块,pip安装即可
redis数据全部都是存在内存里面。
redis本身性能是非常好的,每秒支持30w次的读写。
import redis r = redis.Redis(host='118.24.3.40',password='HK139bc&*',db=1,port=6379)#连接redis #增删改查 r.set('niuhanyang','帅!') #数据库里面新增一个值 # hwt = r.get('niuhanyang')#查,根据key获取对应的值 # print(hwt.decode()) #修改也是set r.delete('niuhanyang') r.setex('python_123','哈哈哈',20) #设置key的失效时间,最后这个参数是秒,时间过后,即删掉这个KEY hwt = r.get('mei')#获取到的是二进制 为bytes类型 print(hwt.decode())#将bytes类型转换为字符串类型,encode将字符串转换为bytes print(hwt) print(r.keys('*xxx*'))#获取到所有含xxx的key print(r.keys())#获取到所有的KEY print(r.get('sdfsdf')) r.set('今天是2018年6月9日:mpp','呵呵呵')#Key中有的冒号的,冒号前面为文件夹的名称,同一个文件夹的内容都可以这样存入 r.set('今天是2018年6月9日:dict','今天是星期六') for k in r.keys(): #删除所有的key r.delete(k) # 上面操作都是针对 string类型 # 哈希类型 hash 类似嵌套字典 r.hset('stu_info','刘伟','1m8 100w存款') r.hset('stu_info','张流量','浪,为了不交作业,故意让狗咬他') r.hset('stu_info','董春光','为了不交作业,找了一条狗咬张流量,然后陪张流量去医院') # print(r.type('stu_info'))#查看key的类型 # print(r.hget('stu_info','张流量').decode()) #指定大key和小key获取对应的数据 # print(r.hgetall('stu_info')) #获取里面所有的k和-v stu_info = r.hgetall('stu_info')#获取到stu_info下的所有k-v print(stu_info) stu_dic={} for k,v in stu_info.items():#stu_info.items()获取到所有的k-v # print(k.decode(),v.decode()) stu_dic[k.decode()]=v.decode() print(stu_dic) r.hdel('stu_info','gyx') #删除指定key r.delete('stu_info') #删除整个key r.expire('aaa',100) #设置失效时间 print(r.type('stu_info')) #查看key是什么类型的 print(r.type('zll')) s='呵呵' s.encode() #把字符串转成二进制 hwt = b'sdfsdfsdf' hwt.decode() #把bytes类型转成字符串 #pymysql、json、redis #1、连数据库,查到数据库里面所有的数据,游标类型要用pymysql.curosrs.DictCour #2、查到所有数据 [ {"id":1,"passwd":"49487dd4f94008a6110275e48ad09448","username":"niuhayang","is_admin":1}] #3、循环这个list,取到usernamer,把username当做key #4、再把这个小字典转成json,存进去就ok import pymysql,json,redis r = redis.Redis(host='118.24.3.40',password='HK139bc&*',db=1,port=6379) conn = pymysql.connect(host='118.24.3.40',user='jxz',passwd='123456',db='jxz',charset='utf8') cur = conn.cursor(cursor=pymysql.cursors.DictCursor) cur.execute('select * from my_user;') all_data = cur.fetchall() for data in all_data: k = data.get('username') r.hset('stu_info_nhy',k,json.dumps(data)) cur.close() conn.close() #下面这个是我自己写的 import pymysql,redis,json r=redis.Redis(host='118.24.3.40',password='HK139bc&*',db=1,port=6379) coon=pymysql.connect(host='118.24.3.40',user='jxz',passwd='123456',db='jxz',charset='utf8') cur=coon.cursor(cursor=pymysql.cursors.DictCursor) cur.execute('select * from my_user;') res=cur.fetchall() for data in res: username=data.get('username') data_json=json.dumps(data)#此处代码可参考上面老师写的进行精简 r.hset('my_user',username,data_json) cur.close() coon.close()
四、接口开发
import flask,json #轻量级的web开发框架 #作为服务端,来开发接口供别人调用,需先启动一个服务 server=flask.Flask(__name__)#__name__代表当前这个python文件, # 这句代码的意思就是把咱们当前的python文件当做一个服务,下面要在这个服务上开发一个接口 #*******get请求可以在浏览器直接访问,post请求需通过第三方工具调用***** # ****操作数据库**** def my_db(sql): import pymysql coon = pymysql.connect( host='118.24.3.40', user='jxz', passwd='123456', port=3306, db='jxz', charset='utf8') cur = coon.cursor() #建立游标 cur.execute(sql)#执行sql if sql.strip()[:6].upper()=='SELECT': res = cur.fetchall() else: coon.commit() res = 'ok' cur.close() coon.close() return res # ****操作数据库****
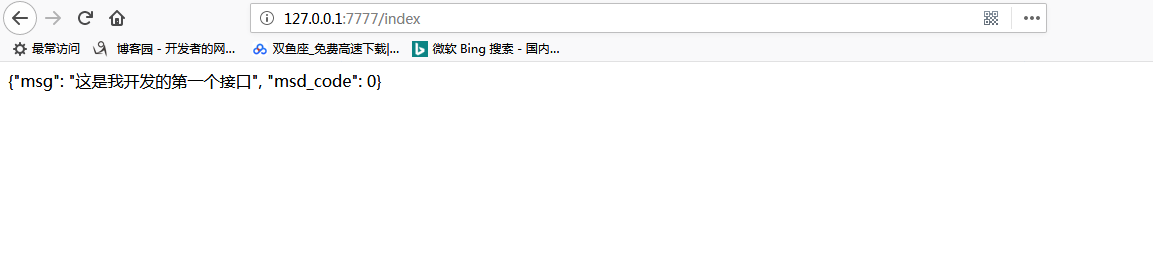
# *******第一个接口******* #ip:8080/index?uge @server.route('/index',methods=['get','post'])#这句代码的意思是下面这个函数将作为服务里的一个接口, # 不再是一个普通的函数;调用这个接口时,就调用index这个路径,methonds为支持调用的方法, # 可以post或get,也可以都写,也可以不写,不写默认为get方法 def index(): res={'msg':'这是我开发的第一个接口','msd_code':0}#这是一个字典,下面调用时要转换成json串 return json.dumps(res,ensure_ascii=False) # server.run(port=7777,debug=True)#启动服务,可以指定端口号,不写时默认为5000,debug=True,改了代码之后,不用重启它会自动帮你重启 #这时就可以直接在浏览器访问这个接口:http://127.0.0.1:7777/index
# *******第一个接口*******
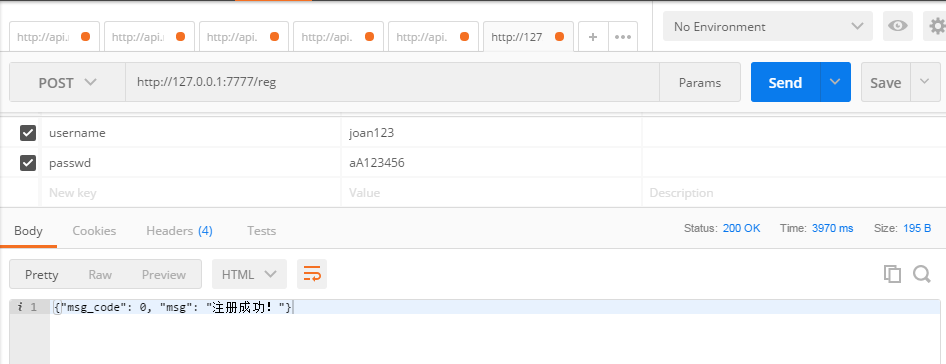
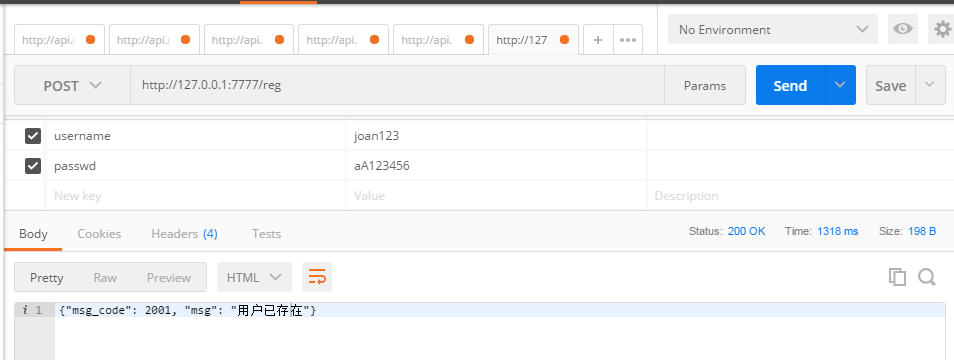
# *******注册用户接口******* @server.route('/reg',methods=['post'])#post请求不能直接在浏览器访问 def reg(): username=flask.request.values.get('username')#接收用户输入 pwd=flask.request.values.get('passwd')#接收用户输入 if username and pwd: sql='select * from my_user where username="%s";'%username #这里因为%s未加双引号导致sql执行失败,sql一定要写正确,切记切记 if my_db(sql): res={'msg':'用户已存在','msg_code':2001} else: insert_sql='insert into my_user (username,passwd,is_admin) values ("%s","%s",0);'%(username,pwd) my_db(insert_sql) res={'msg':'注册成功!','msg_code':0} else: res={'msg':'必填字段未填,请查看接口文档!','msg_code':1001}#1001 必填字段未填 return json.dumps(res,ensure_ascii=False)
# *******注册用户接口*******
server.run(port=7777,debug=True,host='0.0.0.0')#启动服务,可以指定端口号,不写时默认为5000,debug=True,改了代码之后,不用重启它会自动帮你重启 #在postman中输入参数调用该注册接口,可正确返回结果
浏览器调用结果:
postman调用注册接口执行情况:
注册成功:
用户已存在:
五、项目开发文件逻辑
单独的一个python文件不叫程序,叫脚本;复杂的程序通常都会分目录存储,方便修改和查阅,提高代码的可读性。例如:bin目录下放置启动文件,启动程序时直接执行该目录下的文件即可;config目录下放置配置文件,主要是一些端口或IP地址等;lib目录下放置接口文件及自己开发的一些工具程序;log下存放日志;data下放置初始化数据等;还应包含readme文件。
下面PS一片Linux下的目录层级说明:
1.首先来介绍下根目录下的一些重要目录含义 注:其中被标记的比较重要。
| 目录 | 说明 |
| /bin | 常用的二进制命令目录。比如ls cp mkdir 等;和/usr/bin类似。 |
| /boot | linux内核及引导系统程序所需的文件目录。安装系统分区的时候一般要分一个boot分区。常见分区为:/boot 200M swap内存的1.5倍,其余的都给/。 |
| /dev | 设备文件目录,比如声卡,磁盘,光驱等。 |
| /etc | 二进制安装包的配置文件默认路径和服务启动命令存放的目录。 |
| /home | 普通用户的家目录默认数据存放目录。 |
| /lib | 库文件存放目录 |
| /lost+found | 在ext3文件系统中,当系统意外崩溃或机器意外关机,会产生一些文件碎片在这里。当系统在开机启动的过程中fsck工具会检查这里,并修复已经损坏的文件系统。当系统发生问题,可能会有文件被移到这个目录中,可能需要用手工的方式来修复,或移到文件到原来的位置上。 |
| /mnt | 一般是用于临时挂载存储设备的挂载目录,比如有cdrom,U盘等目录,直接插入光驱无法使用,要先挂载后使用。 |
| /opt | 表示的是可选择的意思,有些软件包也会被安装在这里,也就是自定义软件包,我们自己编译的软件包,就可以安装在这个目录中;通过源码包安装的软件,可以通过./configure --prefix=/opt/目录,非必须这样,视习惯或规范而定。 |
| /proc | 操作系统运行时,进程信息及内核信息(比如CPU,硬盘分区,内存信息等)存放在这里。/proc目录是伪装的文件系统proc的挂载目录,proc并不是真正的文件系统,它的定义可以参见/etc/fstab。 |
| /root | linux超级权限用户root的家目录。 |
| /sbin | 大多涉及系统管理的命令的存放,是超级权限用户root可执行命令存放地,这个目录和/usr/sbin,/usr/X11R6/sbin或/usr/local/sbin目录是相似的。 |
| /tmp | 临时文件目录,有时用户运行程序的时候,会产生临时文件。/tmp就用来存放临时文件的,权限比较特殊。 |
| /usr | 这个是系统存放程序的目录,比如命令,帮助文件等。这个目录下有很多的文件和目录。当我们安装一个linux发行版官方提供的软件包时,大多安装在这里。如果有涉及服务器配置文件的,会把配置文件安装在/etc/目录中。/usr目录下包括涉及字体目录/usr/share/fonts,帮助目录/usr/share/man或者/usr/share/doc,普通用户可执行文件目录/usr/bin/或/usr/local/bin或/usr/X11R6/bin ,比如/usr/sbin,/usr/X11R6/sbin,/usr/local/sbin等,还有程序的头文件存放目录/usr/include。 |
| /var | 这个目录的内容是经常变动的,看名字就知道,我们可以理解为vary的缩写,/var下有/var/log这是用来存放系统日志的目录,系统日志路径/var/log/messages。/var/www目录是定义apache服务器站点存放目录;/var/lib用来存放一些库文件,比如mysql的,已经mysql数据库的存放地。 |
2. /etc目录下一些重要的目录及文件说明
| 目录 | 说明 |
| /etc/sysconfig/network-scripts/ifcfg-eth0 | 配置网络地址及GW等。 |
| /etc/resolv.conf | 设置本机的客户端DNS |
| /etc/hosts | 设定用户IP与名字(或域名)的对应表,相当于本地LAN内DNS。 注:WIN的hosts文件地址:C:\windows\system32\drivers\etc\hosts |
| /etc/sysconfig/network | 可修改机器名及网卡启动等配置。 |
| /etc/fstab | 记录开机要mount的文件系统 |
| /etc/inittab | 设定系统启动时 init进程将系统设置成什么样的runlevel及加载相关的启动文件设置。 |
| /etc/exports | 设定NFS系统用的配置文件路径。 |
| /etc/init.d | 这个子目录是用来存放系统或服务器以system V 模式启动的脚本,这在以system V模式启动或初始化的系统中常见。比如CentOS/RedHat。 |
| /etc/xinit.d | 如果服务器时通过xinetd模式运行的,它的脚本要放在这个目录下。有些系统没有这个目录,比如slackware,有些老版本也没有。在redhat/fedora中比较新的版本中存在。 |
| /etc/profile | 系统全局变量配置路径。 |
| /etc/issue | 记录用户登录前显示的信息 |
| /etc/motd | 每次用户登录时,/etc/motd文件的内容会显示在用户的终端。 |
| /etc/group | 设定用户的组名与相关信息 |
| /etc/passwd | 账号信息 |
| /etc/shadow | 密码信息 |
| /etc/sudoers | sudo命令的配置文件 |
| /etc/securetty | 设定哪些终端可以让root登录 |
| /etc/login.defs | 所有用户登录时的缺省配置 |
| /etc/modprobe.conf | 内核模块额外参数设定 |
| /etc/rsyslog.conf(5系列为syslog.conf) | 日志设置文件 |
| /etc/DIR_COLORS | 设定颜色 |
| /etc/host.conf | 文件说明用户的系统如何查询节点名,默认order hosts,bind |
| /etc/hosts.allow | 设置允许使用inetd的机器使用 |
| /etc/hosts.deny | 设置不允许使用inetd的机器使用 |
| /etc/protocols | 系统支持的协议文件 |
| /etc/X11 | X Window 的配置文件 |
3. /var目录下一些重要的目录及文件说明
| 目录 | 说明 |
| /var | 日志文件 |
| /var/log | 各种系统日志存放地 |
| /var/log/messages | 系统信息默认日志文件,非常重要,按周自动轮询 |
| /var/log/secure | 记录登入系统存放信息的文件,按周自动轮询,例如pop3,ssh,telnet,ftp等都会记录在此。 |
| /var/log/wtmp | 记录登陆者信息的文件,last |
| /var/spool/cron | 定时任务crontab默认目录,按用户名命名的文件。 |
| /var/spool/mail | 系统用户邮件存放目录 |
| /var/spool/clientmqueue | 临时邮件文件目录,有很多原因会导致这个目录碎文件很多,比如crontab定时任务命令不加>/dev/null等,工作中偶尔会因为该目录文件太多,导致/var/所在的分区inode数量被消耗尽,无法写入文件的情况。 |
| /var/lib/rpm | rpm套件安装处 |
4. /usr目录下一些重要的目录及文件说明
| 目录
| 说明
|
| /usr/bin
| 这个目录是可执行程序的目录,当我们从系统自带的软件包安装一个程序时,他的可执行文件大多会放在这个目录。相似的目录是/usr/local/sbin
|
| /usr/sbin
| 这个目录也是可执行程序的目录,但大多存放涉及系统管理的命令;相似目录是/usr/local/sbin或/usr/X11R6/sbin等。
|
| /usr/local
| 这个目录一般是用来存放用户自编译安装软件的存放目录,一般是通过源码包安装的软件,如果没有特别指定安装目录的话,一般是安装在这个目录中。相当于C:\Program files
|
| /usr/local/bin
| 用户安装的小的应用程序,和一些在/usr/local目录下大应用程序的符号链接。
|
| /usr/local/sbin
| 系统全局环境目录,可放置一些不需要加路径执行的脚本等。
|
| /usr/share
| 系统共用的东西存放地,比如/usr/share/doc和/usr/share/man帮助文件。
|
| /usr/src
| 内核源码存放目录,比如下面有内核源码目录,比如linux,linux-2.XXX.XX目录等。
|
| /usr/bin
| 使用者可执行的binary file 的目录。
|
| /usr/lib &&/usr/local/lib
| 系统会使用到的函数库。 |
5. /proc目录下一些重要的目录及文件说明
| 目录 | 说明 |
| /proc | 虚拟目录,是内存的映射 |
| /proc/version | 内核版本 |
| /proc/sys/kernel | 系统内核功能 |
| /proc/cpuinfo | 关于处理器的信息,如类型,厂家,型号,性能等。 |
| /proc/meminfo | 系统内存信息 |
| /proc/devices | 当前运行内核所配置的所有设备清单。 |
| /proc/dma | 当前正在使用的DMA通道 |
| /proc/filesystems | 当前运行内核所配置的文件系统 |
| /proc/initerrupts | 正在使用的中断,和曾经有多少个中断。 |
| /proc/ioports | 当前正在使用的I/O端口。 |
| /proc/loadavg | 系统负载信息,uptime的结果。 |