遍历list 分组求和_LeetCode刷题实战49:字母异位词分组
算法的重要性,我就不多说了吧,想去大厂,就必须要经过基础知识和业务逻辑面试+算法面试。所以,为了提高大家的算法能力,这个公众号后续每天带大家做一道算法题,题目就从LeetCode上面选 !
今天和大家聊的问题叫做 字母异位词分组,我们先来看题面:
https://leetcode-cn.com/problems/group-anagrams/
Given an array of strings strs, group the anagrams together. You can return the answer in any order.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
题意
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。 举个例子,比如给定的数组是[eat, ate, tea, tan, nat, bat]。 其中eat,ate,tea这三个单词用到的字母都是e,t和a各一个。 tan和nat用到的都是a,n和 t,最后剩下bat,所以分组结果就是: [eat, ate, tea],[tan, nat]和[bat]。样例
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
说明:
所有输入均为小写字母。
不考虑答案输出的顺序。解题
https://www.cnblogs.com/techflow/p/12693828.html
暴力
我们依然从最简单的思路开始想起,我们分组的依据是 每一个字符串当中用到的字母的情况。所以我们可以把每一个字符串当中所有的元素拆解出来,放到一个dict当中,然后我们用这个dict来作为分组的标准,将dict相同的字符串放在同一组。比如eat我们把它变成{'e': 1, 'a': 1, 't': 1},由于一个字母可能出现多个,所以我们也要记录出现的次数。但有一个问题是,dict是动态数据, 在Python当中我们不能用它作为另一个dict的key。这个问题比较简单的方法是我们写一个方法 将这个dict拼接成字符串,比如'e1a1t1'。我们用这个作为key。但是这又有了一个问题,dict当中的key并不一定是有序的,所以我们需要对dict进行排序,可以看下下图中的流程。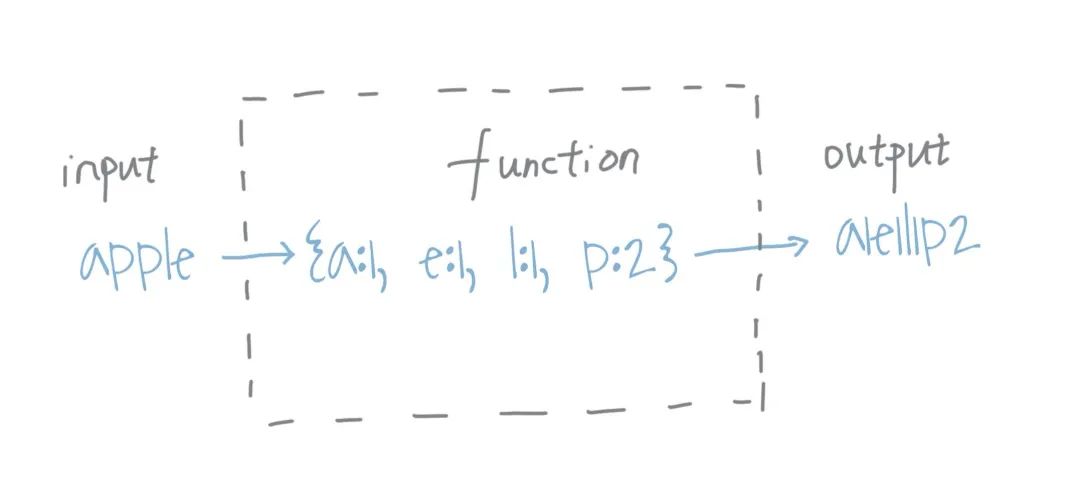
def splitStr(s):
d = defaultdict(int)for c in s:
d[c] += 1
ret = ''# 将dict中内容排序 for k,v in sorted(d.items()): ret += (str(k) + str(v)) return retfrom collections import defaultdictclass Solution:def splitStr(self, s):
d = defaultdict(int)# 拆分字符串中元素for c in s:
d[c] += 1
ret = ''# 将dict中内容排序for k,v in sorted(d.items()):
ret += (str(k) + str(v))return retdef groupAnagrams(self, strs: List[str]) -> List[List[str]]:
groups = defaultdict(list)for s in strs:# 拿到拆分之后的字符串作为key进行分组
key = self.splitStr(s)
groups[key].append(s)
ret = []for _, v in groups.items():
ret.append(v)return rethash
接下来就到了我们的正主出场了,大家从标题当中应该就已经看出来了,这道题和 hash算法有关。讲道理,hash算法的名称如雷贯耳,我们经常听到,但是很多人并不知道hash算法是干嘛的,或者我们究竟什么地方要用到它。大家听得比较多的可能是hashMap。其实hash算法的内容很简单,可以 简单理解成映射。我们的输入可以是任何内容,可以是一个数字,也可以是个数组或者是一个对象,但是我们的输出是一个 固定若干个字节组成的信息。比如下图当中对4取模就是一个hash函数,我们可以根据对4取模之后的结果将数归类到不同的分桶当中。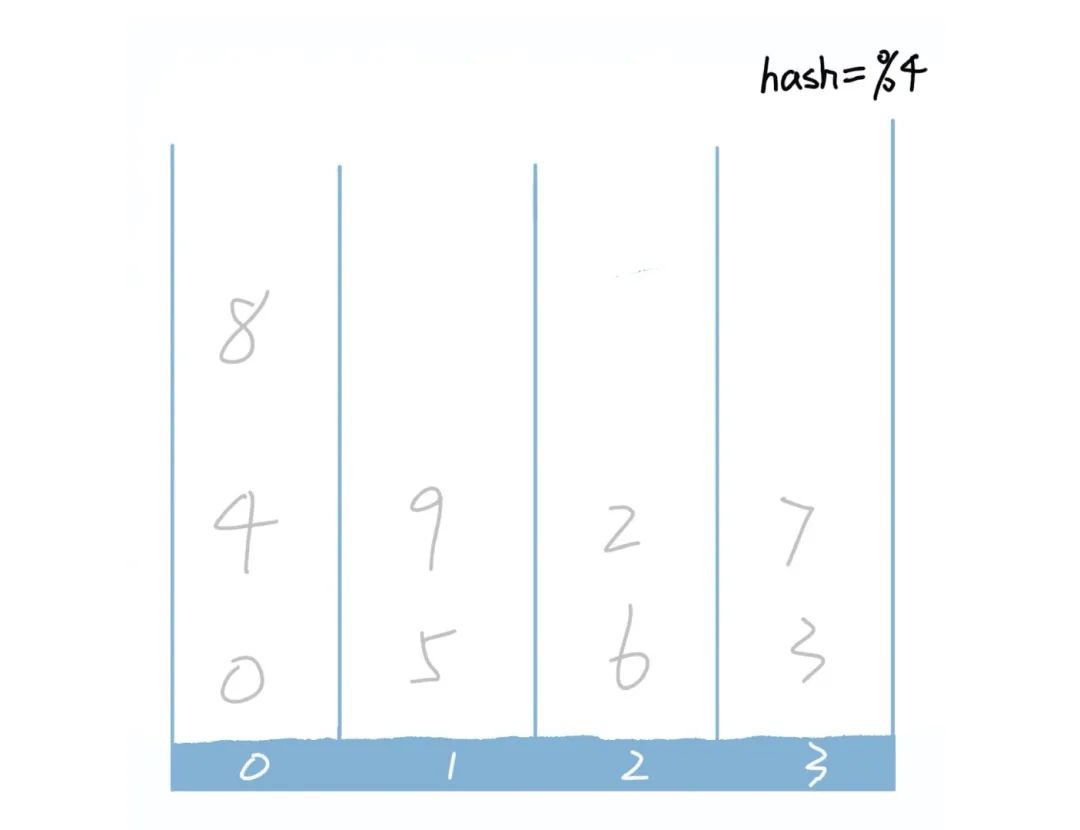
def hash(dict):
ret = 0
prime = 23# k代表字符,v表示出现次数for k, v in dict:
ret += v * pow(23, ord(k) - ord('a'))# 对2^32取模,控制返回值在32个bit内
ret %= (1 <32)return ret ,单个b的hash值也很好算,是23。请问23个a的hash值是多少?算一下就知道,也是23。因为虽然我们用的幂不同,但是它们的底数是一样的,我们
可以用前面的系数来弥补指数的差。这种不同的对象hash结果一样的情况叫做
hash碰撞,这种是不符合我们预期的。但是可以肯定的是,大多数情况下hash碰撞几乎是不可避免的。因为我们hash的目的就是为了用一个简单的数字或者字符串代替原本复杂庞大的数据,就好像拍照一样,两个不同的人,也可能拍出来看起来很像。我们在这个过程当中存在
大量的信息压缩或者信息丢失,比如说我们用10个bit的数字代表了原本2000个bit的数据。不管我们用什么样的策略,10个bit能表达的数据就是有限的。根据鸽笼原理,只要我们hash的数据足够多,总有两个不一样的数据hash的结果碰撞。
,单个b的hash值也很好算,是23。请问23个a的hash值是多少?算一下就知道,也是23。因为虽然我们用的幂不同,但是它们的底数是一样的,我们
可以用前面的系数来弥补指数的差。这种不同的对象hash结果一样的情况叫做
hash碰撞,这种是不符合我们预期的。但是可以肯定的是,大多数情况下hash碰撞几乎是不可避免的。因为我们hash的目的就是为了用一个简单的数字或者字符串代替原本复杂庞大的数据,就好像拍照一样,两个不同的人,也可能拍出来看起来很像。我们在这个过程当中存在
大量的信息压缩或者信息丢失,比如说我们用10个bit的数字代表了原本2000个bit的数据。不管我们用什么样的策略,10个bit能表达的数据就是有限的。根据鸽笼原理,只要我们hash的数据足够多,总有两个不一样的数据hash的结果碰撞。
from collections import defaultdictimport mathclass Solution:def splitStr(self, s):
hashtable = [0 for _ in range(30)]
ret = 0for c in s:
hashtable[ord(c) - ord('a')] += 1# hash算法for i in range(26):
ret = ret * 23 + hashtable[i]# 控制返回值在32个bit内
ret %= (1 <32)return retdef groupAnagrams(self, strs: List[str]) -> List[List[str]]:
groups = defaultdict(list)for s in strs:
key = self.splitStr(s)
groups[key].append(s)
ret = []for _, v in groups.items():
ret.append(v)return ret上期推文:
LeetCode1-20题汇总,速度收藏!LeetCode21-40题汇总,速度收藏!LeetCode刷题实战40:组合总和 IILeetCode刷题实战41:缺失的第一个正数LeetCode刷题实战42:接雨水LeetCode刷题实战43:字符串相乘LeetCode刷题实战44:通配符匹配LeetCode刷题实战45:跳跃游戏 IILeetCode刷题实战46:全排列LeetCode刷题实战47:全排列 IILeetCode刷题实战48:旋转图像