如何实现500 万量级的单词统计?
目录
1、问题描述:
2、解决方法:
3、编码实现:
4、获取源码:
5、字典树的应用场景
漫画:如何用字典树进行 500 万量级的单词统计?
参考连接:
https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9809551913664287200%22%7D&n_type=0&p_from=1
1、问题描述:
如何进行500W量级单词统计?(字典树实际应用详解)
有500W个单词,请设计一个数据结构来存储,现在有两个需求:
<1>、给一个单词,需要判断是否在这500W个单词中;
<2>、给一个单词前缀,求出500W个单词中有多少个单词是该前缀;
2、解决方法:
字典树(即Trie树)来存储
本质:空间换时间
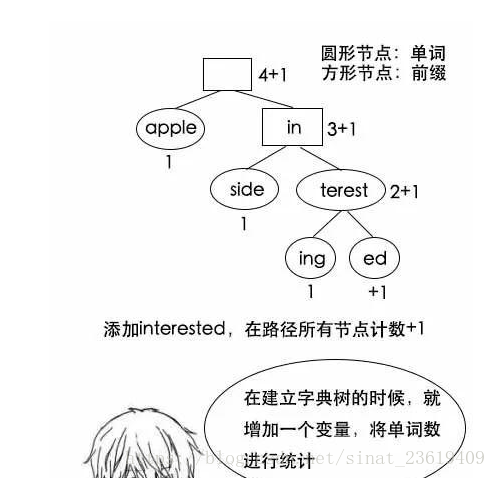
<1>、压缩存储有化后的字典树
eg:


*1、复用前缀,节省大量空间;
*2、有相同前缀,则把前缀进行提取,节点裂变;
*3、增加标记变量区分节点是单词节点还是前缀节点,前缀节点不代表单词;(图中,使用圆形节点代表单词,方形代表前缀)
*4、无重复前缀,则单独成立节点;
*5、增加空的根节点来连接,将森林组成一棵树;
第二问实现方法进行优化:
建立字典树的时候,计算好存在的节点数;
增加一个变量用于计数,在添加节点的时候,把相应的计数+1;
<2>、标准的字典树:
标准的字典树是一个节点对应一个字母;
eg:

*1、优点:编码简单,不会涉及到节点裂变,查找字符串前缀时不用匹配;
*2、缺点:每个字母占用一个节点,可能造成空间浪费;
3、编码实现:
package tree;
import java.util.HashMap;
import java.util.Map;
/*
* 字典树进行500W单词统计
* 压缩优化后的字典树
* 如何进行500W量级单词统计?(字典树实际应用详解)
* 有500W个单词,请设计一个数据结构来存储,现在有两个需求:
* <1>、给一个单词,需要判断是否在这500W个单词中;
* <2>、给一个单词前缀,求出500W个单词中有多少个单词是该前缀;
*/
public class DictionaryTree {
// 字典树的节点,私有内部类
private class Node {
// 是否是单词
private boolean isWord;
// 单词计数
private int count;
// 字串
private String str;
// 子节点,hashmap存储
private Map<String, Node> childs;
// 父节点
private Node parent;
public Node() {
childs = new HashMap<String, Node>();
}
public Node(boolean isWord, int count, String str) {
this();
this.isWord = isWord;
this.count = count;
this.str = str;
}
public void addChild(String key, Node node) {
childs.put(key, node);
node.parent = this;
}
public void removeChild(String key) {
childs.remove(key);
}
public String toString() {
return "str : " + str + ", isWord : " + isWord + ", count : "
+ count;
}
}
// 字典树根节点
private Node root;
DictionaryTree() {
// 初始化root
root = new Node();
}
// 添加字串
private void addStr(String word, Node node) {
// 计数
node.count++;
String str = node.str;
if (null != str) {
// 寻找公共前缀
String commonPrefix = "";
for (int i = 0; i < word.length(); i++) {
if (str.length() > i && word.charAt(i) == str.charAt(i)) {
commonPrefix += word.charAt(i);
} else {
break;
}
}
// 找到公共前缀
if (commonPrefix.length() > 0) {
if (commonPrefix.length() == str.length()
&& commonPrefix.length() == word.length()) {
// 与之前的词重复
} else if (commonPrefix.length() == str.length()
&& commonPrefix.length() < word.length()) {
// 剩余的串
String wordLeft = word.substring(commonPrefix.length());
// 剩余的串去子节点中继续找
searchChild(wordLeft, node);
} else if (commonPrefix.length() < str.length()) {
// 节点裂变
Node splitNode = new Node(true, node.count, commonPrefix);
// 处理裂变节点的父关系
splitNode.parent = node.parent;
splitNode.parent.addChild(commonPrefix, splitNode);
node.parent.removeChild(node.str);
node.count--;
// 节点裂变后的剩余字串
String strLeft = str.substring(commonPrefix.length());
node.str = strLeft;
splitNode.addChild(strLeft, node);
// 单词裂变后的剩余字
if (commonPrefix.length() < word.length()) {
splitNode.isWord = false;
String wordLeft = word.substring(commonPrefix.length());
Node leftNode = new Node(true, 1, wordLeft);
splitNode.addChild(wordLeft, leftNode);
}
}
} else {
// 没有共同前缀,直接添加节点
Node newNode = new Node(true, 1, word);
node.addChild(word, newNode);
}
} else {
// 根结点
if (node.childs.size() > 0) {
searchChild(word, node);
} else {
Node newNode = new Node(true, 1, word);
node.addChild(word, newNode);
}
}
}
// 在子节点中添加字串
public void searchChild(String wordLeft, Node node) {
boolean isFind = false;
if (node.childs.size() > 0) {
// 遍历孩子
for (String childKey : node.childs.keySet()) {
Node childNode = node.childs.get(childKey);
// 首字母相同,则在该子节点继续添加字串
if (wordLeft.charAt(0) == childNode.str.charAt(0)) {
isFind = true;
addStr(wordLeft, childNode);
break;
}
}
}
// 没有首字母相同的孩子,则将其变为子节点
if (!isFind) {
Node newNode = new Node(true, 1, wordLeft);
node.addChild(wordLeft, newNode);
}
}
// 添加单词
public void add(String word) {
addStr(word, root);
}
// 在节点中查找字串
private boolean findStr(String word, Node node) {
boolean isMatch = true;
String wordLeft = word;
String str = node.str;
if (null != str) {
// 字串与单词不匹配
if (word.indexOf(str) != 0) {
isMatch = false;
} else {
// 匹配,则计算剩余单词
wordLeft = word.substring(str.length());
}
}
// 如果匹配
if (isMatch) {
// 如果还有剩余单词长度
if (wordLeft.length() > 0) {
// 遍历孩子继续找
for (String key : node.childs.keySet()) {
Node childNode = node.childs.get(key);
boolean isChildFind = findStr(wordLeft, childNode);
if (isChildFind) {
return true;
}
}
return false;
} else {
// 没有剩余单词长度,说明已经匹配完毕,直接返回节点是否为单词
return node.isWord;
}
}
return false;
}
// 查找单词
public boolean find(String word) {
return findStr(word, root);
}
// 统计子节点字串单词数
private int countChildStr(String prefix, Node node) {
// 遍历孩子
for (String key : node.childs.keySet()) {
Node childNode = node.childs.get(key);
// 匹配子节点
int childCount = countStr(prefix, childNode);
if (childCount != 0) {
return childCount;
}
}
return 0;
}
// 统计字串单词数
private int countStr(String prefix, Node node) {
String str = node.str;
// 非根结点
if (null != str) {
// 前缀与字串不匹配
if (prefix.indexOf(str) != 0 && str.indexOf(prefix) != 0) {
return 0;
// 前缀匹配字串,且前缀较短
} else if (str.indexOf(prefix) == 0) {
// 找到目标节点,返回单词数
return node.count;
// 前缀匹配字串,且字串较短
} else if (prefix.indexOf(str) == 0) {
// 剩余字串继续匹配子节点
String prefixLeft = prefix.substring(str.length());
if (prefixLeft.length() > 0) {
return countChildStr(prefixLeft, node);
}
}
} else {
// 根结点,直接找其子孙
return countChildStr(prefix, node);
}
return 0;
}
// 统计前缀单词数
public int count(String prefix) {
// 处理特殊情况
if (null == prefix || prefix.trim().isEmpty()) {
return root.count;
}
// 从根结点往下匹配
return countStr(prefix, root);
}
// 打印节点
private void printNode(Node node, int layer) {
// 层级递进
for (int i = 0; i < layer; i++) {
System.out.print(" ");
}
// 打印
System.out.println(node);
// 递归打印子节点
for (String str : node.childs.keySet()) {
Node child = node.childs.get(str);
printNode(child, layer + 1);
}
}
// 打印字典树
public void print() {
printNode(root, 0);
}
}package tree;
public class Main {
public static void main(String[] args) {
DictionaryTree dt = new DictionaryTree();
dt.add("interest");
dt.add("interesting");
dt.add("interested");
dt.add("inside");
dt.add("insert");
dt.add("apple");
dt.add("inter");
dt.add("interesting");
dt.print();
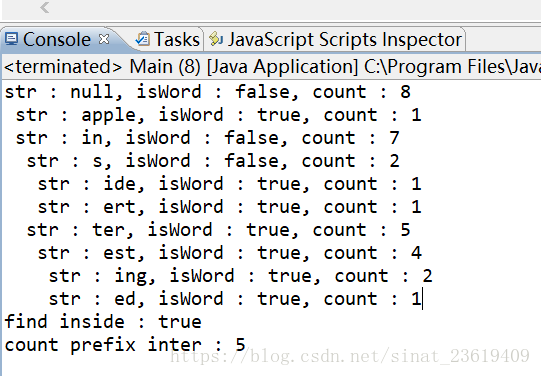
boolean isFind = dt.find("inside");
System.out.println("find inside : " + isFind);
int count = dt.count("inter");
System.out.println("count prefix inter : " + count);
}
}
执行结果:
4、获取源码:
源码地址:https://github.com/JPhei/DataStructureAndAlgorithm
5、字典树的应用场景
*1、大量字符串的统计和查找应该就可以用字典树
*2、字符串前缀的匹配也可以用;
*3、搜索常见的自动控件也可使用;