【深度学习:目标检测】RCNN学习笔记(4):fast rcnn
论文出处见:http://arxiv.org/abs/1504.08083
项目见:https://github.com/rbgirshick/fast-rcnn
包括:
Rol pooling layer(fc)
Multi-task loss(one-stage)
Scale invariance(trade off->single scale(compare with multi-scale for decreasing 1mAP) )
SVD on fc layers(speed up training)
问题:
Which layers to finetune?
Data augment
Are more proposals always better?
缺点:
R-CNN:
1. 训练时要经过多个阶段,首先要提取特征微调ConvNet,再用线性SVM处理proposal,计算得到的ConvNet特征,然后进行用bounding box回归。
2. 训练时间和空间开销大。要从每一张图像上提取大量proposal,还要从每个proposal中提取特征,并存到磁盘中。
3. 测试时间开销大。同样是要从每个测试图像上提取大量proposal,再从每个proposal中提取特征来进行检测过程,可想而知是很慢的。
SPPnet:
SPP已有一定的速度提升,它在ConvNet的最后一个卷积层才提取proposal,但是依然有不足之处。和R-CNN一样,它的训练要经过多个阶段,特征也要存在磁盘中,另外,SPP中的微调只更新spp层后面的全连接层,对很深的网络这样肯定是不行的。
在微调阶段谈及SPP-net只能更新FC层,这是因为卷积特征是线下计算的,从而无法再微调阶段反向传播误差。
而在fast-RCNN中则是通过image-centric sampling提高了卷积层特征抽取的速度,从而保证了梯度可以通过SPP层(即ROI pooling层)反向传播。
Fast-Rcnn 改进:
1. 比R-CNN更高的检测质量(mAP);
2. 把多个任务的损失函数写到一起,实现单级的训练过程;
3. 在训练时可更新所有的层;
4. 不需要在磁盘中存储特征。
解决方式具体即以下几点:
1.训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。FRCN实现了end-to-end的joint training(提proposal阶段除外)。
2.训练时间和空间开销大。RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了。
3.测试时间开销大。依然是因为ROI-centric的原因(whole image as input->ss region映射),这点SPP-Net已经改进,然后FRCN进一步通过single scale(pooling->spp just for one scale) testing和SVD(降维)分解全连接来提速。
整体框架
整体框架如Figure 1,如果以AlexNet(5个卷积和3个全连接)为例,大致的训练过程可以理解为:
1.selective search在一张图片中得到约2k个object proposal(这里称为RoI)
2.缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔。
3.对于每个scale的每个ROI,求取映射关系,在conv5中crop出对应的patch。并用一个单层的SPP layer(这里称为Rol pooling layer)来统一到一样的尺度(对于AlexNet是6x6)。
4.继续经过两个全连接得到特征,这特征有分别share到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个smooth的L1-loss.
(除了1,上面的2-4是joint training的。测试时候,在4之后做一个NMS即可。)
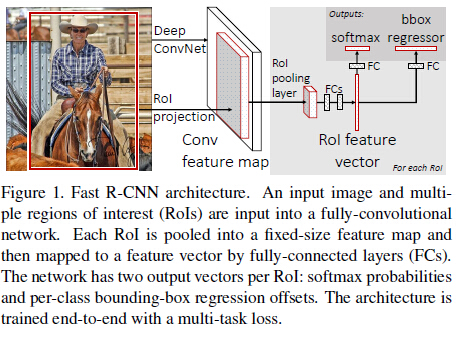
整体框架大致如上述所示
再次几句话总结:
1.用selective search在一张图片中生成约2000个object proposal,即RoI。
2.把它们整体输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
3.继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:
第一个是分类,使用softmax,第二个是每一类的bounding box回归。
按照论文所述即:
one that produces softmax probability estimates overKobject classes plus a catch-all “background” class and
another layer that outputs four real-valued numbers for each of theKobject classes
对比回来SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:
1.改进了SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。
只能更新fc层的原因->按照论文所描述:
the root cause is that back-propagation through the SPPlayer is highly inefficient when each training sample (i.e.RoI) comes from a different image, which is exactly howR-CNN and SPPnet networks are trained.
The inefficiency stems from the fact that each RoI mayhave a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
2.SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor。
接下来会介绍FRCN里面的一些细节的motivation和效果。
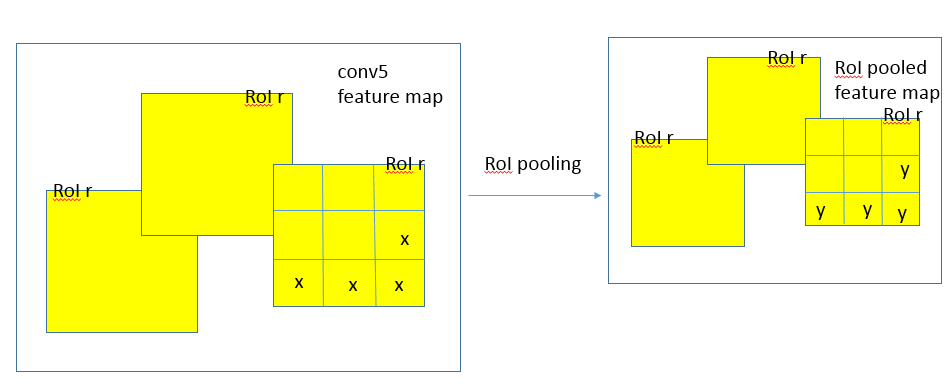
RoI pooling layer
这是SPP pooling层的一个简化版,只有一级“金字塔”,输入是N个特征映射和一组R个RoI,R>>N。N个特征映射来自于最后一个卷积层,每个特征映射都是H x W x C的大小。每个RoI是一个元组(n, r, c, h, w),n是特征映射的索引,n∈{0, ... ,N-1},(r, c)是RoI左上角的坐标,(h, w)是高与宽。输出是max-pool过的特征映射,H' x W' x C的大小,H'≤H,W'≤W。对于RoI,bin-size ~ h/H' x w/W',这样就有H'W'个输出bin,bin的大小是自适应的,取决于RoI的大小。
Rol pooling layer的作用主要有两个:
1.是将image中的rol定位到feature map中对应patch
2.是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。即
RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
这里有几个细节:
1.对于某个rol,怎么求取对应的feature map patch?这个论文没有提及,笔者也觉得应该与spp-net的映射关系一致
2.为何只是一层的SPP layer?多层的SPP layer不会更好吗?对于这个问题,笔者认为是因为需要读取pretrain model来finetuning的原因,比如VGG就release了一个19层的model,如果是使用多层的SPP layer就不能够直接使用这个model的parameters,而需要重新训练了。
Roi_pool层的测试(forward)
roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
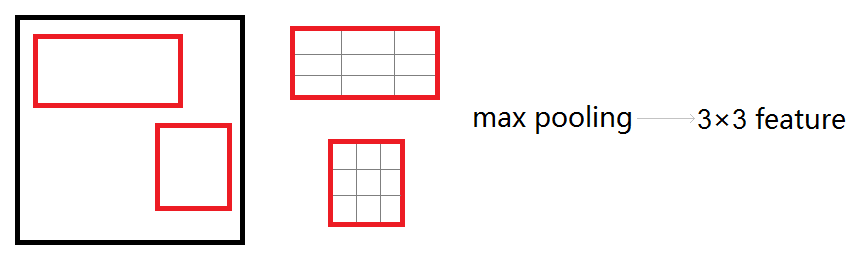
Roi_pool层的训练(backward)
首先考虑普通max pooling层。设xi为输入层的节点,yj为输出层的节点。
其中判决函数δ(i,j)表示i节点是否被j节点选为最大值输出。不被选中有两种可能:xi不在yj范围内,或者xi不是最大值。
对于roi max pooling,一个输入节点可能和多个输出节点相连。设xi为输入层的节点,yrj为第r个候选区域的第j个输出节点。 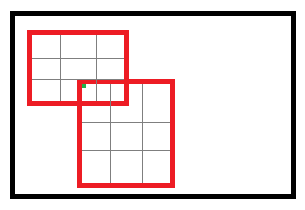
判决函数δ(i,r,j)表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于xi的梯度等于所有相关的后一层梯度之和。
Pre-trained networks
用了3个预训练的ImageNet网络(CaffeNet/VGG_CNN_M_1024/VGG16)。
预训练的网络初始化Fast RCNN要经过三次变形:
1. 最后一个max pooling层替换为RoI pooling层,设置H’和W’与第一个全连接层兼容。
(SPPnet for one scale -> arbitrary input image size )
2. 最后一个全连接层和softmax(原本是1000个类)-> 替换为softmax的对K+1个类别的分类层,和bounding box 回归层。
(Cls and Det at same time)
3. 输入修改为两种数据:一组N个图形,R个RoI,batch size和ROI数、图像分辨率都是可变的。
Fine-tuning
前面说过SPPnet有一个缺点是只能微调spp层后面的全连接层,所以SPPnet就可以采用随机梯度下降(SGD)来训练。
RCNN:无法同时tuning在SPP layer两边的卷积层和全连接层
RoI-centric sampling:从所有图片的所有RoI中均匀取样,这样每个SGD的mini-batch中包含了不同图像中的样本。(SPPnet采用)
FRCN想要解决微调的限制,就要反向传播到spp层之前的层->(reason)反向传播需要计算每一个RoI感受野的卷积层,通常会覆盖整个图像,如果一个一个用RoI-centric sampling的话就又慢又耗内存。
Fast RCNN:->改进了SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层
image-centric sampling: (solution)mini-batch采用层次取样,先对图像取样,再对RoI取样,同一图像的RoI共享计算和内存。
另外,FRCN在一次微调中联合优化softmax分类器和bbox回归。
看似一步,实际包含了:
多任务损失(multi-task loss)、小批量取样(mini-batch sampling)、RoI pooling层的反向传播(backpropagation through RoI pooling layers)、SGD超参数(SGD hyperparameters)。
Multi-task loss
两个输出层,一个对每个RoI输出离散概率分布: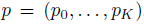
一个输出bounding box回归的位移: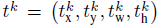
k表示类别的索引,前两个参数是指相对于object proposal尺度不变的平移,后两个参数是指对数空间中相对于object proposal的高与宽。把这两个输出的损失写到一起:
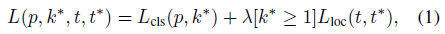
k*是真实类别,式中第一项是分类损失,第二项是定位损失,L由R个输出取均值而来.
以下具体介绍:
1.对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景。为何不用SVM做分类器了?在5.4作者讨论了softmax效果比SVM好,因为它引入了类间竞争。(笔者觉得这个理由略牵强,估计还是实验效果验证了softmax的performance好吧 ^_^)
2.对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,比较有意思的是,这里regressor的loss不是L2的,而是一个平滑的L1,形式如下:
作者这样设置的目的是想让loss对于离群点更加鲁棒,控制梯度的量级使得训练时不容易跑飞。
最后在5.1的讨论中,作者说明了Multitask loss是有助于网络的performance的。
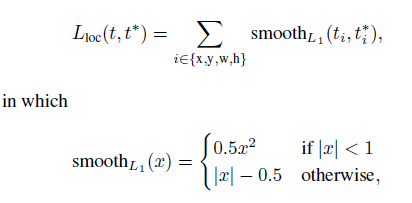
---------------------------------------------------------------------------------------------------------------------------------------------------------
Mini-batch sampling
在微调时,每个SGD的mini-batch是随机找两个图片,R为128,因此每个图上取样64个RoI。从object proposal中选25%的RoI,就是和ground-truth交叠至少为0.5的。剩下的作为背景。
分层数据
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征。
实际选择N=2, R=128-> 每一个mini-batch中首先加入2张完整图片,而后加入从2张图片中选取的128个候选框。这128个候选框可以复用2张图片前5个阶段的网络特征。
训练数据构成
N张完整图片以50%概率水平翻转。
R个候选框的构成方式如下:
| 类别 | 比例 | 方式 |
|---|---|---|
| 前景 | 25% | 与某个真值重叠在[0.5,1]的候选框 |
| 背景 | 75% | 与真值重叠的最大值在[0.1,0.5)的候选框 |
Backpropagation through RoI pooling layers
RoI pooling层计算损失函数对每个输入变量x的偏导数,如下:
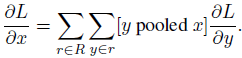
y是pooling后的输出单元,x是pooling前的输入单元,如果y由x pooling而来,则将损失L对y的偏导计入累加值,最后累加完R个RoI中的所有输出单元。下面是我理解的x、y、r的关系:
Scale invariance
SPPnet用了两种实现尺度不变的方法:
1. brute force (single scale),直接将image设置为某种scale,直接输入网络训练,期望网络自己适应这个scale。
2. image pyramids (multi scale),生成一个图像金字塔,在multi-scale训练时,对于要用的RoI,在金字塔上找到一个最接近227x227的尺寸,然后用这个尺寸训练网络。
虽然看起来2比较好,但是非常耗时,而且性能提高也不对,大约只有%1,所以这篇论文在实现中还是用了1。
Which layers to finetune?
对应文中4.5,作者的观察有2点
- 对于较深的网络,比如VGG,卷积层和全连接层是否一起tuning有很大的差别(66.9 vs 61.4)
- 有没有必要tuning所有的卷积层?
答案是没有。如果留着浅层的卷积层不tuning,可以减少训练时间,而且mAP基本没有差别。
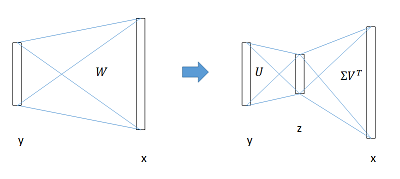
Truncated SVD for faster detection
在分类中,计算全连接层比卷积层快,而在检测中由于一个图中要提取2000个RoI,所以大部分时间都用在计算全连接层了。文中采用奇异值分解的方法来减少计算fc层的时间.
具体来说,作者对全连接层的矩阵做了一个SVD分解,mAP几乎不怎么降(0.3%),但速度提速30%
全连接层提速
分类和位置调整都是通过全连接层(fc)实现的,设前一级数据为x后一级为y,全连接层参数为W,尺寸u×v。一次前向传播(forward)即为:
计算复杂度为u×v。
将W进行SVD分解,并用前t个特征值近似:
原来的前向传播分解成两步:
计算复杂度变为u×t+v×t。
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
Data augment
在训练期间,作者做过的唯一一个数据增量的方式是水平翻转。
作者也试过将VOC12的数据也作为拓展数据加入到finetune的数据中,结果VOC07的mAP从66.9到了70.0,说明对于网络来说,数据越多就是越好的。
实验与结论
实验过程不再详述,只记录结论
- 网络末端同步训练的分类和位置调整,提升准确度
- 使用多尺度的图像金字塔,性能几乎没有提高
- 倍增训练数据,能够有2%-3%的准确度提升
- 网络直接输出各类概率(softmax),比SVM分类器性能略好
- 更多候选窗不能提升性能
results
for VOC2007
| method | mAP S M L | train time(h) S M L | test rate (s/im) S M L |
|---|---|---|---|
| SPPnet BB | — — 63.1 | — — 25 | — — 2.3 |
| R-CNN BB | 58.5 60.2 66.0 | 22 28 84 | 9.8 12.1 47.0 |
| FRCN | 57.1 59.2 66.9 | 1.2 2.0 9.5 | 0.10 0.15 0.32 |
顶
0