代码层走进“百万级”分布式ID设计
1. 前言
面对互联网系统的三高(高可用,高性能,高并发),数据库方面我们多会采用分库分表策略,如此必然会面临另一个问题,分库分表策略下如何生成数据库主键?那么今天针对此问题,我们就聊聊如何设计一款“百万级”的分布式ID生成器。
2. 项目背景
由于业务拓展单量剧增,为满足现有业务发展,遂决定对当前业务进行分库分表改造。分库分表形式下如何保证逻辑表在不同库、不同表下主键的唯一性成为了首要解决的问题,之初考虑仍采用数据库方式生成主键,但考虑数据库系统瓶颈、系统性能等问题,故调研后决定开发部署一套可支持百万级的分布式ID生成器,以用来支持现有业务,并逐步为后续其它业务做支撑。
3. 技术选型
明确项目背景之后,就是技术选型了。
之后比对了uuid方式、Redis计数器、数据库号段、雪花算法、美团Leaf 等多种ID生成器的方式。由于uuid的随机无序性,易导致B+Tree索引的分裂,不适合做MySQL的数据索引;Redis计数器需要考虑其持久化方式,宕机情况下可能会导致号段重复等问题,故暂不考虑以上2种方式。之后又对其它的方式如数据库号段、雪花算法等的优缺点、是否引入新的技术依赖、复杂度等进行分析,最终决定采用类似美团Leaf的方式生成分布式主键ID。
4. 架构设计
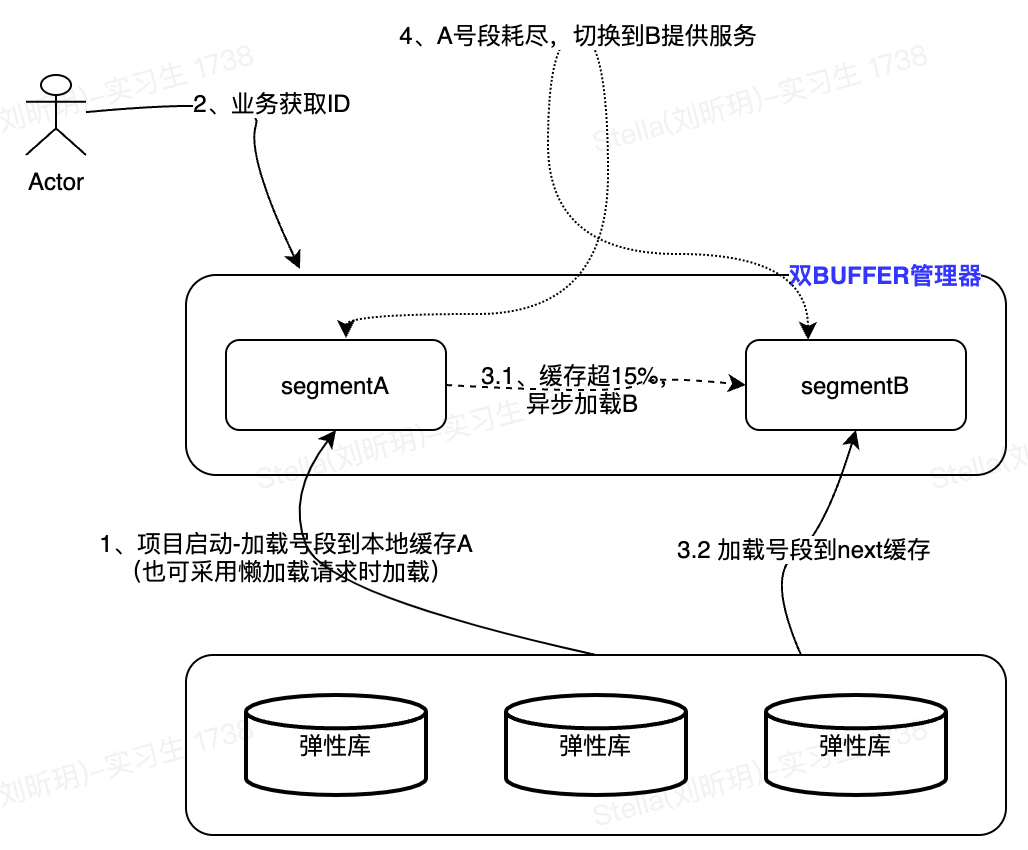
4.1 总体架构
总体上采用双缓存架构,业务key对应的号段持久化在数据库之中,每次从数据库加载指定步长号段保存到本地缓存,业务请求优先从本地缓存获取ID。

执行步骤如下:
-
STEP1:服务启动或首次请求时-从数据库加载当前业务key,根据业务key配置步长,加载号段到本地。
-
STEP2:业务key调用时,优先从本地缓存A获取ID。
-
step 2.1:如当前“本地缓存A”的使用率超过15%(可动态调整),将异步从数据库加载号段到本地缓存B;
-
step 2.2:如当前“本地缓存A”号段已使用完,切换缓存为“本地缓存B”,继续提供服务。
-
-
STEP3:返回请求结果(极端情况缓存A号段耗尽,缓存B号段未加载完成,重试一定次数后失败)。
4.2 详细设计
如何支持百万的QPS,如何保障业务的高可用?为满足高并发、高可用分布式号段的数据结构又该如何设计的呢?接下来我们从表结构、缓存结构两个方面看下分布式号段的详细设计,逐步揭开其神秘的面纱:
4.2.1 表结构设计
表核心字段如下:
-
id:主键
-
biz_key:业务key
-
max_id:当前业务key号段使用的MAX值
-
step:步长(每次加载step步长到本地缓存)
<sql id="id_generator_sql">
id as id,
biz_key as bizKey,
max_id as maxId,
step as step,
create_time as createTime,
update_time as updateTime,
version as version,
app_name as appName,
description as description,
is_del as isDel
</sql>
<insert id="insert" parameterType="com.jd.presell.idgenerator.model.Segment">
insert into id_generator
(biz_key,max_id,step,create_time,update_time,version,app_name,description,isDel)
values
(#{bizKey},#{maxId},#{step},now(),now(),0,#{appName},#{description},#{isDel})
</insert>4.2.2 缓存结构设计
了解完表结构之后,大家肯定还会有疑问,如仅仅采用数据库的方式实现分布式ID,其可支持的QPS、系统的稳定性多数都得不到保障,那又是采用什么样的数据方式保障系统的高并发、高可用呢?接下来我们从“缓存结构”设计中找答案:
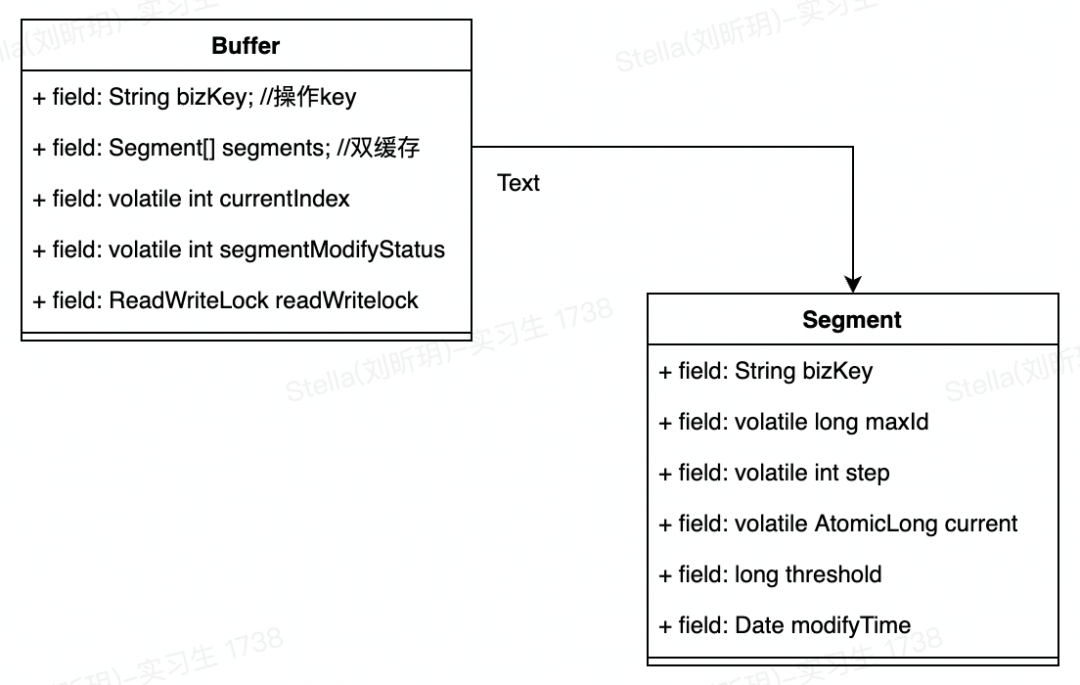
- Buffer(缓存管理器)
bizKey:业务key
segments:数组存储双缓存
currentIndex:游标,指向segments中当前正在使用的缓存
segmentModifyStatus:CAS方式更新此号段状态
readWritelock 读写锁:号段的读取、更新采用加锁方式采用读写锁(此场景读多写少)
ing bizKey; //操作key
private Segment[] segments; //双缓存
private volatile int currentIndex; //当前使用的Segment[]的下标
private volatile int segmentModifyStatus;
private final ReadWriteLock readWritelock = new ReentrantReadWriteLock(); //读写锁- segment(实际操作缓存)
bizKey:业务key
maxId:当前缓存支持最大值
step:数据库加载时业务key的步长
current:当前号段已用值
threshold:更新下一个缓存阀值
private String bizKey; //key
private volatile long maxId; //当前号段最大值
private volatile int step; //步长
private volatile AtomicLong current; //当前号段已用值
private long threshold; //加载下一个缓存阀值
private Date modifyTime; //更新时间,后期用于动态计算step4.3 关键流程链路
当清楚前面提到的“表结构”和“缓存结构”后,接下来我们来看下关键流程链路,更加清晰的了解到以上介绍的“表”和“缓存”在业务中的应用,详细信息如下:
- 服务初始化加载业务bizKey
- 根据业务bizKey获取ID
- 双缓存-预加载(提前加载下一个缓存)
- 双缓存-缓存切换

相信大家可以从上图看出关键信息,充分了解到关键业务及其实现细节,下面是从业务和技术上做简单的概述。
(1)业务概述
- 服务初始化加载号段:为了不影响服务发布后的t,遂采用饿汉式模式,服务启动时加载指定步长的号段到本地缓存;
- 业务key维护:新增或下线的业务key通过JOB定时维护,新增bizKey添加到本地缓存,失效bizKey从本地缓存移除(前期业务key比较少全表扫描,后期bizKey较多时可采用通知或扫描指定时间变更的增量bizKey);
- 预加载:当前缓存使用超阈值后,异步加载另一个缓存;为了尽量保障业务的稳定性,一般设置当前缓存使用到15%左右(可动态调整),开始执行预加载;
- 缓存切换:当前缓存号段耗尽,切换到下一个缓存并继续提供服务;
(2)关键技术
- ReadWriteLock锁应用:此业务场景是典型的读多写少场景,故采用读写锁模式。
读锁:获取分布式ID;
写锁:预加载下一个缓存、缓存切换。
- CAS原子操作:预加载下一个缓存时,为了避免单机多线程同时操作,采用CAS方式更新Buffer的状态标识,更新成功的线程才可以进行异步预加载操作。
- volatile:保障数据的可见性,确保共享变量能被准确和一致地更新保障。
5. 总结&展望
项目完成之后进行压测,在步长设置合理的时候,单机可支持近10万QPS,压测过程中其TP正常,TP99、TP999基本维持在5毫秒以内,整体上已满足现阶段业务需求。
虽然现阶段的设计已满足当前业务需求,但是可以优化的空间还很大,我们还有很长的路要走,比如下面的号段浪费、动态规划步长等。
(1)号段浪费
应用启动时加载号段,如遇服务重启、发版等情况会浪费掉部分号段。
针对此问题可以:
- 服务启动时初始化10%步长的号段,尽量减少首次初始化号段数量
- 服务关闭时添加钩子,保存号段使用情况到Redis,服务启动后可优化从Redis号段池加载到本地缓存。
(2)动态规划步长
目前步长是手工配置,后期可根据号段的更新频率,匹配一定的规则,动态调整业务key对应的号段(可以在申请时配置:步长动态调整规则)。
(3)数据库分库分表
现阶段bizKey较少,后期有需求可根据bizKey分库分表。
(4)持久化方式优化
目前仅采用MySQL持久化号段信息,根据业务可以添加多级缓存,可引入Redis,数据库预加载号段到Redis,本地缓存优先从Redis获取号段加载到本地。
(5)监控告警
结合公司组件,目前对单个接口以及单个bizKey的QPS、可用率、TP进行了监控。可在此基础上增加:号段更新频率、号段单机分布情况(已分布号段、已使用号段)等进行监控。
6. 结语
以上内容简单的总结了该项目的背景、选型、设计等内容,总体方案上或许并不是最优解,还有许多待改进点。也是秉着先有后优,逐步拓展、迭代的思想,选择了分期、分需实现,在满足当前业务的情况下,快速、稳定、持续落地!
感谢大家的支持,希望通过这篇文章可以让你了解到,原来部分百万业务量的设计也并不复杂,原来仅需上十台服务器也可以轻轻松松支撑百万QPS的业务!
文|袁向飞
关注得物技术,做最潮技术人