redis 为什么这么快,你真的知道吗?
前言
相信大家在面试过程中,都被面试官问到过这样一个问题,缓存中间件大名鼎鼎的 redis 速度为什么这么快呢?
针对于面试过程中的痛点问题,笔者昨晚熬夜收集资料,并且通过走访大量使用者,整理出如下的结论。我敢保证,你看了这篇文章,再问你这个问题,保准把面试官虐哭。

分析原因
这里就不卖关子了,先说结论,我们再对原因进行抽丝剥茧。
redis快的原因
- 纯内存操作(最主要条件)
- 合适的线程模型
- 优秀的数据结构
- 合理的数据编码方式
纯内存操作(最主要条件)
首先最主要的原因一定是:redis 的数据操作是基于内存的。
众所周知,内存的访问速度是远远大于硬盘访问速度的。我们来做个对比,拿数据库(硬盘)和 redis (内存)对比,一个操作对应磁盘,一个操作对应内存。他们两个的的访问速度差了一个数量级。
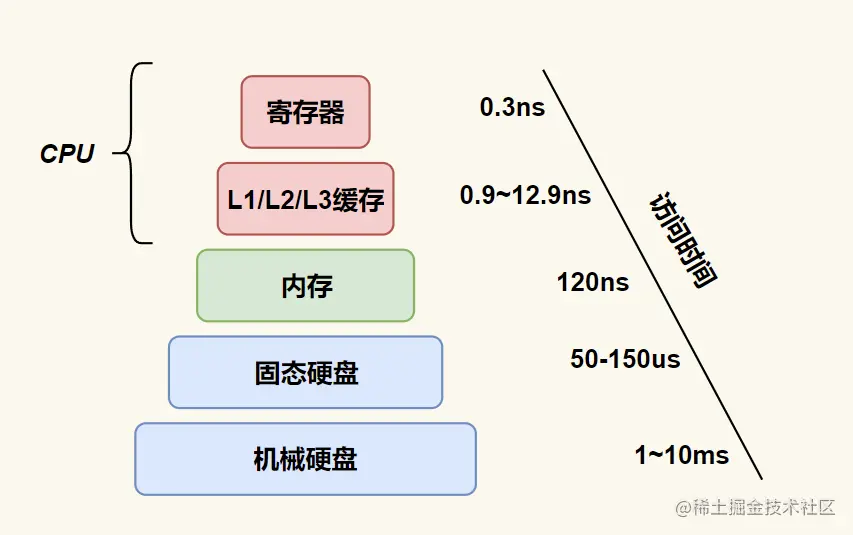
可能大家对数量级没有什么该概念。那可是整整 1000 倍啊!现在大家知道了吧。
下面是我精心为大家准备的访问速度图,已经验证,方便大家食用。
有的小伙伴要问了,redis不是有数据持久化吗?
怎么会是只操作内存呢?
这位同学一看就是对 redis 理解的不够透彻,redis 持久化线程和操作内存数据的线程,并不是一个线程,我们这里说的 redis 快,只是针对操作内存的线程来说的,操作很快。因为操作是直接客户端响应时间息息相关的。
合适的线程模型
🥈单线程误区
先说一个
常见误区,就是大家在其他的文章或者面试题中,通过一段时间的以讹传讹。
大家都认为 redis 速度快,有一个原因是单线程!!!
在这里先反驳一下这个观点,这个结论是个明显的因果颠倒,主次不分的结论!!
为什么这么说呢?
首先单线程 redis 不是纯粹的单线程,我们所知晓的 redis 单线程只有 网络请求模块和 数据操作模块是单线程的。
你要知道多线程的出现,本身就是为了解决多核心 CPU 利用率不足。如果单线程是快的原因的话,那么我们还要多线程干什么,小伙伴你说是吧!
那为什么不用多线程呢?
因为没有必要,我们先来想一下多线程适用场景有哪些?
在这之前,我们先了解一下计算机在运行过程中的主要操作分为以下两种:
CPU 计算操作网络和磁盘 IO 读取操作
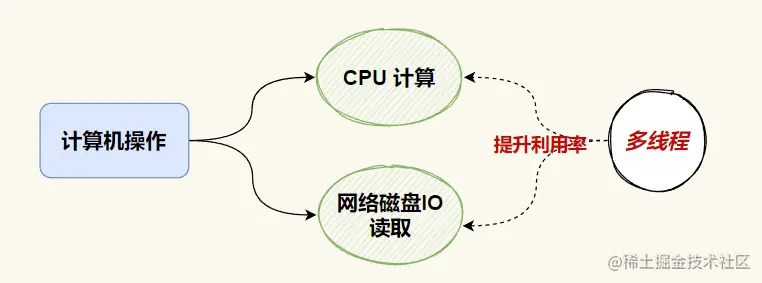
多线程的出现以及适用场景目的就是为了提升单线程在 cpu利用率和io利用率之间的不足
那么redis怎么不需要多线程呢?
我们从上面的计算机操作分类来说
- 从 CPU 计算来说,
redis操作都是基于内存操作,很少有一些耗费CPU 的计算操作,对于 redis 操作来说,CPU 计算不是瓶颈,瓶颈在于 redis 操作内存的速度。 - 从网络 IO 来说,
redis的网络 IO 接收事件,确实是一个很需要去提升的点 因为所有客户端对 redis 的操作 最终都会由redis的网络模块接受 ,所以对于 redis 来说 提升网络 IO 的利用率 很有必要。
结论:redis 在 CPU 计算上不存在瓶颈,性能瓶颈只存在于网络 IO 中
但是~想要提高网络 IO 的利用率,不是只有多线程一条路。
redis由于历史遗留原因最终没有采用多线程处理网络 IO 而是采取了 单线程 + 多路复用器处理。- 在2020年,
redis 6.0版本已经开始做多线程处理网络 IO ,性能提升巨大。
所以说千万不要陷入 redis 是单线程所以快,现在是 CPU 多核心时代,最差的情况 CPU 一个核心绑定一个线程,不同线程之间也不处理竞态资源,也比你只用到一个核心处理快的多了吧!
我这里总结一下我的看法,redis 6.0版本 之前采用单线程处理网络 IO 原因如下:
- redis 为了保持一贯的语义,采用了单线程模型(也许是懒吧)
- 就算是单线程,也完全足够用了,在不需要超大并发的情况下,也不需要上多线程。
那为什么redis 6.0 还是采用了多线程处理网络 IO ?
不是说多路复用技术已经大大的提升了网络 IO 利用率了么,为啥还需要多线程?
主要是因为我们对 Redis 有着更高的要求。
据测算,redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,redis 服务器可以处理 80,000 到 100,000 QPS,这么高的对于 80% 的公司来说,单线程的 redis 已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。
为了提升 QPS,很多公司的做法是部署 redis集群,并且尽可能提升 redis 机器数。但是这种做法的资源消耗是巨大的。
而经过分析,限制 redis 的性能的主要瓶颈出现在网络IO的处理上,虽然之前采用了多路复用技术。但是我们前面也提到过,多路复用的 IO 模型本质上仍然是同步阻塞型 IO 模型。
下图是 redis 网络 IO 多线程和单线程的速度对比图,大家都来看一下
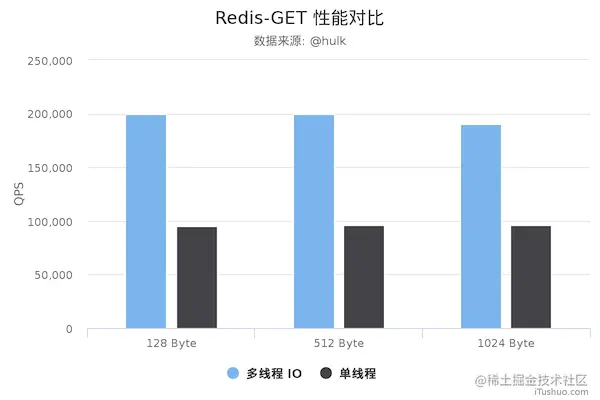
从上面可以看到 `GET/SET` 命令在 4 线程 IO 时性能相比单线程是几乎是翻倍了。
结论:redis 6.0 多线程网络 IO 性能提升巨大,不严谨条件下几乎翻倍
🥈单线程模式下快的原因
说完了对于单线程的误区,下面我们就要说一下在单线程模式下,redis 快的原因
用四个字就可以来形容这个原因,那就是 多路复用
多路复用是啥呢?
简单理解就是 单个线程同时检测若干个网络连接(Socket)是否可以执行IO操作的能力,就是将多个进程的网络 IO Socket注册到同一个管道上。 用最少的资源,干最多的事情。
比较传统的方式是使用多线程模型,每来一个客户端连接,就分配一个线程,然后后续的读写都在对应的进程/线程,这种方式处理 100 个客户端没问题,但是当客户端增大到 10000 个时,10000 个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
为了解决上面这个问题,就出现了 I/O 的多路复用,可以只在一个进程里处理多个文件的 I/O

所有的 io 操作 由这一个管道来和内核进行统一交互 管道中的io请求数据准备好之后 管道会将数据 拷贝到用户空间中。
在 redis 中,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
但是出现的个数不可能有很多,这样我们用一个线程来监听这些消息,然后分派去给操作线程执行就可以。
多路复用模型显而易见的好处:
单线程,省去多个线程创建和上下文切换操作Socket 连接不多的情况,性能甚至比多线程有可能要高
优秀的数据结构
redis 在存储数据结构的设计上还是花了一番心思的 不然这也不会成为它快的一点原因。
它拥有五种常用的数据类型,帮助我们在各种各样的场景上都能灵活应对,并且也能用对应的数据类型做出很多很有意思的事情。
redis的五种数据类型主要有:
- String 整数浮点数或者字符串
- Set 集合
- Zset 有序集合
- Hash 散列表
- List 列表
举个例子,我们都知道redis底层使用c语言写的,但是 String 实现并不是简单的用c语言的字符串实现的,而是采用一个 SDS(简单动态字符串) 的结构体来实现的。
Tips:这里给大家补充一个知识点,C语言的String是以 “\0” 结尾的,并且计算长度是得通过遍历获取,时间复杂度是 O(n) , 而且在数据中不能有 “\0” 出现,会导致计算错误。
redis String 的 SDS 结构体,不仅让长度的获取是 O(1) 操作,而且二进制安全,没有特殊字符的限制,可以存储视频图片的数据。
这里我想让大家知道,redis 数据结构设计考虑还是很优秀的。
数据结构的详细解析,我们在这里就不多赘述了,我们放到我们的下一篇。
欢迎小伙伴们前去围观,也欢迎批评指正。
合理的数据编码方式
怎么理解这个合理的编码方式呢?
我们还是以 redis 中的 string 结构举例子,redis为了存储不同大小的字符串,精心设计了 5 种类型。
sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64
它们的不同就是,本身的数据类型不同,举个例子
sdshdr16中的字段分配大小是uint16 2^16sdshdr32中的字段分配大小是uint32 2^32
结论: 通过这种能够灵活存储不同大小的字符串,有效的节省了内存。字符串大的时候分配大的内存空间,小的时候就分配小的,高效利用内存。
当然,在这里只是举个例子,想了解更多redis 底层细节的小伙伴,我们放到了后续的系列。
欢迎小伙伴们前去围观,也欢迎批评指正。
总结
至此,我们知道了这个 redis 经典面试题的答案了。
原因无他。分别是:
纯内存操作多路复用线程模型优秀的数据结构合理的数据编码方式
不知道大家学会了吗? 学会的小伙伴们,再也不怕那些刁钻的面试官了,我敢保证,你看了这篇文章,再问你这个问题,保准把面试官虐哭。